Techniques to Mitigate Refresh Penalties in High Density Memory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ASIC Implementation of DDR SDRAM Memory Controller
© 2016 IJEDR | Volume 4, Issue 4 | ISSN: 2321-9939 ASIC Implementation of DDR SDRAM Memory Controller Ramagiri Ramya, Naganaik M.Tech Scholar, ASST.PROF, HOD of ECE BRIG-IC, Hyderabad ________________________________________________________________________________________________________ Abstract - A Dedicated Memory Controller is of prime importance in applications that do not contain microprocessors (high-end applications). The Memory Controller provides command signals for memory refresh, read and write operation and initialization of SDRAM. Our work will focus on ASIC Design methodology of Double Data Rate (DDR) SDRAM Controller that is located between the DDR SDRAM and Bus Master. The Controller simplifies the SDRAM command interface to standard system read/write interface and also optimizes the access time of read/write cycle. Keywords - DDR SDRAM Controller, Read/Write Data path, Cadence RTL Compiler. ________________________________________________________________________________________________________ I. INTRODUCTION Memory devices are almost found in all systems and nowadays high speed and high performance memories are in great demand. For better throughput and speed, the controllers are to be designed with clock frequency in the range of megahertz. As the clock speed of the controller is increasing, the design challenges are also becoming complex. Therefore the next generation memory devices require very high speed controllers like double data rate and quad data rate memory controllers. In this paper, the double data rate SDRAM Controller is implemented using ASIC methodology. Synchronous DRAM (SDRAM) is preferred in embedded system memory design because of its speed and pipelining capability. In high-end applications, like microprocessors there will be specific built in peripherals to provide the interface to the SDRAM. But for other applications, the system designer must design a specific memory controller to provide command signals for memory refresh, read and write operation and initialization of SDRAM. -

A Modern Primer on Processing in Memory
A Modern Primer on Processing in Memory Onur Mutlua,b, Saugata Ghoseb,c, Juan Gomez-Luna´ a, Rachata Ausavarungnirund SAFARI Research Group aETH Z¨urich bCarnegie Mellon University cUniversity of Illinois at Urbana-Champaign dKing Mongkut’s University of Technology North Bangkok Abstract Modern computing systems are overwhelmingly designed to move data to computation. This design choice goes directly against at least three key trends in computing that cause performance, scalability and energy bottlenecks: (1) data access is a key bottleneck as many important applications are increasingly data-intensive, and memory bandwidth and energy do not scale well, (2) energy consumption is a key limiter in almost all computing platforms, especially server and mobile systems, (3) data movement, especially off-chip to on-chip, is very expensive in terms of bandwidth, energy and latency, much more so than computation. These trends are especially severely-felt in the data-intensive server and energy-constrained mobile systems of today. At the same time, conventional memory technology is facing many technology scaling challenges in terms of reliability, energy, and performance. As a result, memory system architects are open to organizing memory in different ways and making it more intelligent, at the expense of higher cost. The emergence of 3D-stacked memory plus logic, the adoption of error correcting codes inside the latest DRAM chips, proliferation of different main memory standards and chips, specialized for different purposes (e.g., graphics, low-power, high bandwidth, low latency), and the necessity of designing new solutions to serious reliability and security issues, such as the RowHammer phenomenon, are an evidence of this trend. -

Machxo2 LPDDR SDRAM Controller IP Core User's Guide
MachXO2™ LPDDR SDRAM Controller IP Core User’s Guide February 2014 IPUG92_01.3 Table of Contents Chapter 1. Introduction .......................................................................................................................... 4 Introduction ........................................................................................................................................................... 4 Quick Facts ........................................................................................................................................................... 4 Features ................................................................................................................................................................ 4 Chapter 2. Functional Description ........................................................................................................ 5 Overview ............................................................................................................................................................... 5 Initialization Block......................................................................................................................................... 5 Read Training Block..................................................................................................................................... 6 Data Control Block ....................................................................................................................................... 6 LPDDR I/Os ................................................................................................................................................ -

¡ Semiconductor MSM5718C50/Md5764802this Version: Feb
E2G1059-39-21 ¡ Semiconductor MSM5718C50/MD5764802This version: Feb. 1999 ¡ Semiconductor Previous version: Nov. 1998 MSM5718C50/MD5764802 18Mb (2M ´ 9) & 64Mb (8M ´ 8) Concurrent RDRAM DESCRIPTION The 18/64-Megabit Concurrent Rambus™ DRAMs (RDRAM®) are extremely high-speed CMOS DRAMs organized as 2M or 8M words by 8 or 9 bits. They are capable of bursting unlimited lengths of data at 1.67 ns per byte (13.3 ns per eight bytes). The use of Rambus Signaling Level (RSL) technology permits 600 MHz transfer rates while using conventional system and board design methodologies. Low effective latency is attained by operating the two or four 2KB sense amplifiers as high speed caches, and by using random access mode (page mode) to facilitate large block transfers. Concurrent (simultaneous) bank operations permit high effective bandwidth using interleaved transactions. RDRAMs are general purpose high-performance memory devices suitable for use in a broad range of applications including PC and consumer main memory, graphics, video, and any other application where high-performance at low cost is required. FEATURES • Compatible with Base RDRAMs • 600 MB/s peak transfer rate per RDRAM • Rambus Signaling Level (RSL) interface • Synchronous, concurrent protocol for block-oriented, interleaved (overlapped) transfers • 480 MB/s effective bandwidth for random 32 byte transfers from one RDRAM • 13 active signals require just 32 total pins on the controller interface (including power) • 3.3 V operation • Additional/multiple Rambus Channels each provide an additional 600 MB/s bandwidth • Two or four 2KByte sense amplifiers may be operated as caches for low latency access • Random access mode enables any burst order at full bandwidth within a page • Graphics features include write-per-bit and mask-per-bit operations • Available in horizontal surface mount plastic package (SHP32-P-1125-0.65-K) 1/45 ¡ Semiconductor MSM5718C50/MD5764802 PART NUMBERS The 18- and 64-Megabit RDRAMs are available in horizontal surface mount plastic package (SHP), with 533 and 600 MHz clock rate. -

Retention-Aware DRAM Auto-Refresh Scheme for Energy and Performance Efficiency
micromachines Article Retention-Aware DRAM Auto-Refresh Scheme for Energy and Performance Efficiency Wei-Kai Cheng * , Po-Yuan Shen and Xin-Lun Li Department of Information and Computer Engineering, Chung Yuan Christian University, Taoyuan 32023, Taiwan * Correspondence: [email protected]; Tel.: +886-3265-4714 Received: 30 July 2019; Accepted: 6 September 2019; Published: 8 September 2019 Abstract: Dynamic random access memory (DRAM) circuits require periodic refresh operations to prevent data loss. As DRAM density increases, DRAM refresh overhead is even worse due to the increase of the refresh cycle time. However, because of few the cells in memory that have lower retention time, DRAM has to raise the refresh frequency to keep the data integrity, and hence produce unnecessary refreshes for the other normal cells, which results in a large refresh energy and performance delay of memory access. In this paper, we propose an integration scheme for DRAM refresh based on the retention-aware auto-refresh (RAAR) method and 2x granularity auto-refresh simultaneously. We also explain the corresponding modification need on memory controllers to support the proposed integration refresh scheme. With the given profile of weak cells distribution in memory banks, our integration scheme can choose the most appropriate refresh technique in each refresh time. Experimental results on different refresh cycle times show that the retention-aware refresh scheme can properly improve the system performance and have a great reduction in refresh energy. Especially when the number of weak cells increased due to the thermal effect of 3D-stacked architecture, our methodology still keeps the same performance and energy efficiency. -

DRAM Refresh Mechanisms, Penalties, and Trade-Offs
IEEE TRANSACTIONS ON COMPUTERS, VOL. 64, NO. X, XXXXX 2015 1 DRAM Refresh Mechanisms, Penalties, and Trade-Offs Ishwar Bhati, Mu-Tien Chang, Zeshan Chishti, Member, IEEE, Shih-Lien Lu, Senior Member, IEEE, and Bruce Jacob, Member, IEEE Abstract—Ever-growing application data footprints demand faster main memory with larger capacity. DRAM has been the technology choice for main memory due to its low latency and high density. However, DRAM cells must be refreshed periodically to preserve their content. Refresh operations negatively affect performance and power. Traditionally, the performance and power overhead of refresh have been insignificant. But as the size and speed of DRAM chips continue to increase, refresh becomes a dominating factor of DRAM performance and power dissipation. In this paper, we conduct a comprehensive study of the issues related to refresh operations in modern DRAMs. Specifically, we describe the difference in refresh operations between modern synchronous DRAM and traditional asynchronous DRAM; the refresh modes and timings; and variations in data retention time. Moreover, we quantify refresh penalties versus device speed, size, and total memory capacity. We also categorize refresh mechanisms based on command granularity, and summarize refresh techniques proposed in research papers. Finally, based on our experiments and observations, we propose guidelines for mitigating DRAM refresh penalties. Index Terms—Multicore processor, DRAM Refresh, power, performance Ç 1INTRODUCTION ROWING memory footprints, data intensive applica- generation (Fig. 1), the performance and power overheads of Gtions, the increasing number of cores on a single chip, refresh are increasing in significance (Fig. 2). For instance, and higher speed I/O capabilities have all led to higher our study shows that when using high-density 32Gb devices, bandwidth and capacity requirements for main memories. -

AMBA DDR, LPDDR, and SDR Dynamic Memory Controller DMC-340 Technical Reference Manual
AMBA® DDR, LPDDR, and SDR Dynamic Memory Controller DMC-340 Revision: r4p0 Technical Reference Manual Copyright © 2004-2007, 2009 ARM Limited. All rights reserved. ARM DDI 0331G (ID111809) AMBA DDR, LPDDR, and SDR Dynamic Memory Controller DMC-340 Technical Reference Manual Copyright © 2004-2007, 2009 ARM Limited. All rights reserved. Release Information The Change history table lists the changes made to this book. Change history Date Issue Confidentiality Change 22 June 2004 A Non-Confidential First release for r0p0. 31 August 2004 B Non-Confidential Second release for r0p0. 25 August 2005 C Non-Confidential Incorporate erratum. Additional information to Exclusive access on page 2-14. 09 June 2006 D Non-Confidential First release for r1p0. 16 May 2007 E Non-Confidential First release for r2p0. 30 November 2007 F Non-Confidential First release for r3p0. 05 November 2009 G Non-Confidential First release for r4p0. Proprietary Notice Words and logos marked with ® or ™ are registered trademarks or trademarks of ARM® in the EU and other countries, except as otherwise stated below in this proprietary notice. Other brands and names mentioned herein may be the trademarks of their respective owners. Neither the whole nor any part of the information contained in, or the product described in, this document may be adapted or reproduced in any material form except with the prior written permission of the copyright holder. The product described in this document is subject to continuous developments and improvements. All particulars of the product and its use contained in this document are given by ARM in good faith. However, all warranties implied or expressed, including but not limited to implied warranties of merchantability, or fitness for purpose, are excluded. -

External Memory Interface Handbook Volume 3: Reference Material
External Memory Interface Handbook Volume 3: Reference Material Updated for Intel® Quartus® Prime Design Suite: 17.0 Subscribe EMI_RM | 2017.05.08 Send Feedback Latest document on the web: PDF | HTML Contents Contents 1. Functional Description—UniPHY.................................................................................... 13 1.1. I/O Pads............................................................................................................. 14 1.2. Reset and Clock Generation...................................................................................14 1.3. Dedicated Clock Networks.....................................................................................14 1.4. Address and Command Datapath........................................................................... 15 1.5. Write Datapath.................................................................................................... 16 1.5.1. Leveling Circuitry..................................................................................... 17 1.6. Read Datapath.................................................................................................... 18 1.7. Sequencer.......................................................................................................... 19 1.7.1. Nios II-Based Sequencer...........................................................................20 1.7.2. RTL-based Sequencer............................................................................... 25 1.8. Shadow Registers............................................................................................... -

On the Optimal Refresh Power Allocation for Energy-Efficient
On the Optimal Refresh Power Allocation for Energy-Efficient Memories Yongjune Kim∗, Won Ho Choi∗, Cyril Guyot∗, and Yuval Cassuto∗y ∗Western Digital Research, Milpitas, CA, USA Email: fyongjune.kim, won.ho.choi, [email protected] yViterbi Department of Electrical Engineering, Technion – Israel Institute of Technology, Haifa, Israel Email: [email protected] Abstract—Refresh is an important operation to prevent loss of proposed architectural techniques to avoid unnecessary re- data in dynamic random-access memory (DRAM). However, fre- fresh operations. Error control coding (ECC) schemes were quent refresh operations incur considerable power consumption proposed to decrease refresh rates and correct the resulting and degrade system performance. Refresh power cost is especially significant in high-capacity memory devices and battery-powered retention failures [2], [8]–[10]. These ECC schemes suffer edge/mobile applications. In this paper, we propose a principled from storage or bandwidth overheads. RAIDR [4] allocates approach to optimizing the refresh power allocation. Given a different refresh intervals by identifying weak DRAM cells. model for the bit error rate dependence on power, we formulate a Flikker [6] specifies critical and non-critical data and refreshes convex optimization problem to minimize the word mean squared the memory cells storing non-critical data at a lower rate. Cho error for a refresh power constraint; hence we can guarantee the optimality of the obtained refresh power allocations. In addition, et al. [11] proposed tiered-reliability memory (TRM) to allo- we provide an integer programming problem to optimize the cate different refresh intervals depending on the importance discrete refresh interval assignments. -

Flipping Bits in Memory Without Accessing Them: an Experimental Study of DRAM Disturbance Errors
Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors 1 1 1 Yoongu Kim Ross Daly Jeremie Kim Chris Fallin Ji Hye Lee Donghyuk Lee1 Chris Wilkerson2 Konrad Lai Onur Mutlu1 1Carnegie Mellon University 2Intel Labs Abstract. Memory isolation is a key property of a reliable disturbance errors, DRAM manufacturers have been employ- and secure computing system — an access to one memory ad- ing a two-pronged approach: (i) improving inter-cell isola- dress should not have unintended side effects on data stored tion through circuit-level techniques [22, 32, 49, 61, 73] and in other addresses. However, as DRAM process technology (ii) screening for disturbance errors during post-production scales down to smaller dimensions, it becomes more difficult testing [3, 4, 64]. We demonstrate that their efforts to contain to prevent DRAM cells from electrically interacting with each disturbance errors have not always been successful, and that 1 other. In this paper, we expose the vulnerability of commodity erroneous DRAM chips have been slipping into the field. DRAM chips to disturbance errors. By reading from the same In this paper, we expose the existence and the widespread address in DRAM, we show that it is possible to corrupt data nature of disturbance errors in commodity DRAM chips sold in nearby addresses. More specifically, activating the same and used today. Among 129 DRAM modules we analyzed row in DRAM corrupts data in nearby rows. We demonstrate (comprising 972 DRAM chips), we discovered disturbance this phenomenon on Intel and AMD systems using a malicious errors in 110 modules (836 chips). -

Rowhammer: a Retrospective
RowHammer: A Retrospective Onur Mutluxz Jeremie S. Kimzx xETH Zurich¨ zCarnegie Mellon University Abstract—This retrospective paper describes the RowHammer they can not only degrade system reliability and availability problem in Dynamic Random Access Memory (DRAM), which but also, perhaps even more importantly, open up new security was initially introduced by Kim et al. at the ISCA 2014 con- vulnerabilities: a malicious attacker can exploit the exposed ference [133]. RowHammer is a prime (and perhaps the first) example of how a circuit-level failure mechanism can cause a failure mechanism to take over the entire system. As such, practical and widespread system security vulnerability. It is the new failure mechanisms in memory can become practical and phenomenon that repeatedly accessing a row in a modern DRAM significant threats to system security. chip causes bit flips in physically-adjacent rows at consistently In this article, we provide a retrospective of one such predictable bit locations. RowHammer is caused by a hardware example failure mechanism in DRAM, which was initially failure mechanism called DRAM disturbance errors, which is a manifestation of circuit-level cell-to-cell interference in a scaled introduced by Kim et al. at the ISCA 2014 conference [133]. memory technology. We provide a description of the RowHammer problem and its Researchers from Google Project Zero demonstrated in 2015 implications by summarizing our ISCA 2014 paper [133], de- that this hardware failure mechanism can be effectively exploited scribe solutions proposed by our original work [133], compre- by user-level programs to gain kernel privileges on real systems. hensively examine the many works that build on our original Many other follow-up works demonstrated other practical at- tacks exploiting RowHammer. -
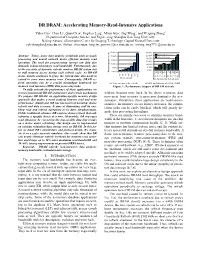
DR DRAM: Accelerating Memory-Read-Intensive Applications
DR DRAM: Accelerating Memory-Read-Intensive Applications Yuhai Cao1, Chao Li1, Quan Chen1, Jingwen Leng1, Minyi Guo1, Jing Wang2, and Weigong Zhang2 Department of Computer Science and Engineering, Shanghai Jiao Tong University Beijing Advanced Innovation Center for Imaging Technology, Capital Normal University [email protected], {lichao, chen-quan, leng-jw, guo-my}@cs.sjtu.edu.cn, {jwang, zwg771}@cnu.edu.cn 25.00% 30.00% 25.00% Bandwidth decrease Abstract—Today, many data analytic workloads such as graph 20.00% Latency increase 20.00% processing and neural network desire efficient memory read 15.00% operation. The need for preprocessing various raw data also 15.00% 10.00% 10.00% demands enhanced memory read bandwidth. Unfortunately, due 5.00% 5.00% to the necessity of dynamic refresh, modern DRAM system has 0.00% to stall memory access during each refresh cycle. As DRAM Occupy by refresh Time 0.00% 1X 2X 4X 1X 2X 4X 1Gb 2Gb 4Gb 8Gb 32Gb 64Gb device density continues to grow, the refresh time also needs to 16Gb 0℃<T<85℃ 85℃<T<95℃ Device density extend to cover more memory rows. Consequently, DRAM re- Fine Granularity Refresh mode fresh operation can be a crucial throughput bottleneck for (a) Time occupied by refresh (b) BW and latency of a 8Gb DDR4 memory read intensive (MRI) data processing tasks. Figure 1: Performance impact of DRAM refresh To fully unleash the performance of these applications, we revisit conventional DRAM architecture and refresh mechanism. without frequent write back. In the above scenarios, data We propose DR DRAM, an application-specific memory design movement from memory to processor dominates the per- approach that makes a novel tradeoff between read and write formance.