Navigation Instruction Validation Tool and Indoor Wayfinding Training System for People with Disabilities
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Designing a User Interface for Musical Gameplay
Designing a User Interface for Musical Gameplay An Interactive Qualifying Project submitted to the faculty of WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science Submitted by: Tech Side: Hongbo Fang Alexander Guerra Xiaoren Yang Art Side: Kedong Ma Connor Thornberg Advisor Prof. Vincent J. Manzo Abstract A game is made up of many components, each of which require attention to detail in order to produce a game that is enjoyable to use and easy to learn. The graphical user interface, or GUI, is the method a game uses to communicate with the player and has a large impact on the gameplay experience. The goal of this project was to design a GUI for a music oriented game that allows players to construct a custom instrument using instruments they have acquired throughout the game. Based on our research of GUIs, we designed a prototype in Unity that incorporates a grid system that responds to keypress and mouse click events. We then performed a playtest and conducted a survey with students to acquire feedback about the simplicity and effectiveness of our design. We found that our design had some confusing elements, but was overall intuitive and easy to use. We found that facilitation may have impacted the results and should be taken into consideration for future development along with object labeling and testing sample size. 1 Acknowledgements We would like to thank Professor Vincent Manzo for selecting us to design an important feature of his game and for is support and encouragement throughout the duration of the project. -

GST Mapper MDC Training
GeoSpatial Technologies, Inc. GST Mapper MDC Training Train the Trainer GST Mapper MDC Training GST Mapper© MDC/MP Navigator is an integrated interface for GPS/AVL that allows you to display your current location, your sister unit locations, routing, mapping, navigation and CAD linking for receiving and displaying incidents (Tags). Scenarios: •Enables Deputies to find or search for locations, supporting units, and incidents. •Provides the functions to generate a route to an incident, sister unit, or manually input an address via a local GIS map or navigation screen. •Deputies\Officers have the ability to view various map layers including aerial imagery and night\day contrasting views for tactical needs when setting parameters, and various other functions and scenarios that will be addressed throughout the training. GST Mapper MDC components GST Mapper MDC GST Navigator GST Mobile Console GST Advantage GST vs. Consumer Navigation GST Others Custom Mapping Utilizes an agency’s GIS data and Pre configured Solutions map layers providing the ability to consumer-driven maps. display map layers such as: aerial (Non-agency specific photo, RD, beat, address, parcel, map data) hydrant, etc. Group Vehicle Display Ability to display, route-to or N/A navigate-to sister vehicles in surrounding area. CAD Integration CAD interface providing the ability N/A to display, route-to or navigate-to CAD\Incident calls. MDC\MDT Integration Ability to install onto existing N/A MDC\MDT with common Microsoft operating systems. Request for features GST works with agencies to N/A customize integrated solutions. GST Mapper MDC Toolbar ◦ Map Control Buttons ◦ Incident Panel ◦ CAD\Request CAD ◦ Unit List ◦ Routing Functions ◦ AVL Locator ◦ GST Navigator ◦ Cosmetic Layers ◦ Address \Identify ◦ Pan X, Y Menu Bar ◦ View ◦ Tools ◦ Window Tool Bar The toolbar is used to access the integrated features and functions of GST Mapper MDC, allowing the user to control the map, search, route, or navigate to CAD incidents (tags), sister units, addresses, or landmarks. -

IG7013-Toolbars.Pdf
Impress Guide Appendix B Toolbars Copyright This document is Copyright © 2021 by the LibreOffice Documentation Team. Contributors are listed below. You may distribute it and/or modify it under the terms of either the GNU General Public License (http://www.gnu.org/licenses/gpl.html), version 3 or later, or the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0/), version 4.0 or later. All trademarks within this guide belong to their legitimate owners. Contributors To this edition. Peter Schofield Dave Barton Feedback Please direct any comments or suggestions about this document to the Documentation Team’s mailing list: [email protected] Note Everything sent to a mailing list, including your email address and any other personal information that is written in the message, is publicly archived and cannot be deleted. Publication date and software version Published February 2021. Based on LibreOffice 7.0. Using LibreOffice on macOS Some keystrokes and menu items are different on macOS from those used in Windows and Linux. The table below gives some common substitutions for the instructions in this document. For a detailed list, see the application Help. Windows or Linux macOS equivalent Effect Tools > Options LibreOffice > Preferences Access setup options menu selection Right-click Control+click or right-click Open a context menu depending on computer setup Ctrl (Control) ⌘ (Command) Used with other keys F11 ⌘+T Open the Styles deck in the Sidebar Documentation for LibreOffice is available at -

For a Visual Glimpse at the Contents of the Document, Click the Grid Icon in the Upper Right- Hand Corner
ADDITIONAL FUNCTIONALITY WITHIN THE COMMUNITY ASSOCIATION LIVING LIVE DOCUMENT INTERFACE For a visual glimpse at the contents of the document, click the grid icon in the upper right- hand corner. Note: you must mouse over the area to bring up the navigation bar. This will bring up a different window showing each of the sections—click on any of them to navigate to that section. HOW TO SEARCH FOR KEY WORDS AND PHRASES WITHIN THE COMMUNITY ASSOCIATION LIVING LIVE DOCUMENT INTERFACE Click on the search icon in the lower right-hand corner. Note: you must mouse over the area to bring up the navigation bar. That will bring up this dialog box to search specific words and phrases. HOW TO PRINT OR DOWNLOAD THE COMMUNITY ASSOCIATION LIVING DOCUMENT FROM WITHIN THE LIVE INTERFACE From the Community Association Living live document interface, click on the download icon in the upper right-hand corner. Note: you must mouse over the area to bring up the navigation bar. This will bring up a new dialog box. Click on the download icon again to save a PDF to your local drive, or click the printer icon to print. If you click print, you will see your computer’s native print dialog box and you should be able to change the individual settings here. HOW TO SHARE THE GUIDING PRINCIPLES DOCUMENT FROM WITHIN THE LIVE INTERFACE From the Guiding Principles live document interface, click on the share icon in the lower right-hand corner. Note: you must mouse over the area to bring up the navigation bar. -

Use Flags and Reminders in Outlook
Use Flags and Reminders in Outlook Flagged email messages help you better manage your mail. Flagged messages create to-do items either for you alone or for you and the recipients of the email message. For example, you can flag an email message that requests information that you need by a certain date. When the recipient receives the message, a flag appears with it and a special message appears on the InfoBar in the Reading Pane and at the top of the message when opened in Outlook. A message flagged for yourself can help you track who has replied to the message. In the previous scenario, you sent a flagged email message requesting information by a certain date. By also flagging the message for yourself, you are reminded to check for replies. Outlook can even help you automatically find replies to the original flagged message. Flagged messages are shown in the To-Do Bar, in Tasks, and in the Daily Task List in Calendar. Flag Received Messages You can flag an email message you receive to remind yourself to follow-up or take action at a later time. Your flagged message will appear in the To-Do Bar, in Tasks, and in the Daily Task List in Calendar. You can also click your Search Folder – For Follow Up to find the messages you’ve flagged. Outlook 2010 or 2007 (Message is closed) 1. In the message list, right-click the flag column and choose Add Reminder. Note: Unless you have changed the default flag, it has both a start date and due date of today. -

Visinet Mobile Training Manual Version
VisiNET Mobile Training Manual Version 2.1 Revised May, 2005 VisiNet Mobile Copyright © 2004 TriTech Software Systems Unpublished: All rights reserved under the copyright laws of the United States. All information in this document is proprietary, confidential, and owned by TriTech Software Systems™. No part of this document may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without the express written permission of TriTech Software Systems™. Disclaimer The information in this document is subject to change without notice. This document is provided under license in connection with an update version of the software named on the front page hereof. The software version to which this document relates is subject to the License and other terms and conditions of the contract under which the software was originally provided. This document is part of the TriTech Documentation referred to in that contract and is likewise subject to the terms and conditions thereof, including, without limitation, the License and Confidentiality terms. THIS DOCUMENT AND THE SOFTWARE VERSION PROVIDED HEREWITH, IS PROVIDED AS IS, WITHOUT WARRANTIES OF ANY KIND, EXPRESS OR IMPLIED. Software Errors (as that term is defined and used in said contract) encountered in said software will be corrected pursuant to the terms and conditions of the Software Support Agreement currently in force with respect to said software and your sole remedy with respect to this software update version and this document is to receive the software support services provided under said Software Support Agreement. Companies, names, and/or data used in screens and sample output are fictitious unless otherwise noted. -

Tree Manager
PeopleTools 8.58: Tree Manager May 2020 PeopleTools 8.58: Tree Manager Copyright © 1988, 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or “commercial computer software documentation” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -
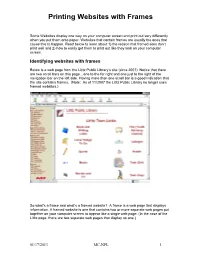
Printing Websites with Frames
Printing Websites with Frames Some Websites display one way on your computer screen and print out very differently when you put them onto paper. Websites that contain frames are usually the ones that cause this to happen. Read below to learn about 1) the reason that framed sites don’t print well and 2) how to easily get them to print out like they look on your computer screen. Identifying websites with frames Below is a web page from the Lititz Public Library’s site (circa 2007). Notice that there are two scroll bars on this page…one to the far right and one just to the right of the navigation bar on the left side. Having more than one scroll bar is a good indication that the site contains frames. (Note: As of 11/2007 the Lititz Public Library no longer uses framed websites.) So what’s a frame and what’s a framed website? A frame is a web page that displays information. A framed website is one that contains two or more separate web pages put together on your computer screen to appear like a single web page. (In the case of the Lititz page, there are two separate web pages that display as one.) 01/17/2013 MC-NPL 1 Printing Websites with Frames Here is another example of a framed website. It looks slightly different than the one above. In this case, notice that the scroll bar to the far right does not extend from top to bottom, but starts 1/3 of the way down the page. -
Home Page Navigation Buttons Report Toolbar Navigation
HOME PAGE NAVIGATION BUTTONS REPORT TOOLBAR Default Reports folder provides a consolidation of The navigation bar also provides the following all Trimble created reports in one location. options: Option Description My Reports folder allows users to save a default Go to the Home page. Option Description report within it as well as the creation of sub folders. Default Reports Opens the Default Reports folder. The forward and back navigation History List enables users to view analytic reports My Reports Opens the My Reports folder. buttons. that have been scheduled, or previously run. History List Opens the History List. Go up one level. My Subscriptions enables users to view and My Subscriptions Opens the My Subscriptions folder. manage report subscriptions. Preferences Opens the user preferences. Saves the analytic report to the My Preferences allows users to select user level Home returns you to your default Reports folder. settings. start page. Adds the analytic report to your Back takes you back to the previous History List. page. Click the arrow button to select a previous page from the list. Displays a printable version of your analytic report as PDF. Forward takes you to the next page. Click the arrow button to select a page from the list. Sends the analytic report to your email address, and optionally to your Return returns you to the previous History List page or the parent level for an Schedules the analytic report for analytic report or folder. NAVIGATION PANEL delivery to your History List. Opens a new browser window • Open folders and analytic reports. containing the analytics pages. -

Navigating in the System
NAVIGATING IN THE SYSTEM Chapter 2 AUTHORIZED REQUESTERS AND AUTHORIZED APPROVERS CHAPTER 2 Bowie State University September 2010 BOWIE STATE UNIVERSITY PEOPLESOFT CHAPTER 2 - NAVIGATING IN THE SYSTEM 1 BOWIE STATE UNIVERSITY PEOPLESOFT CHAPTER 2 - NAVIGATING IN THE SYSTEM 2 NAVIGATING IN THE SYSTEM Overview Being able to navigate in Peoplesoft is essential. After signing on to PeopleSoft, the system displays a homepage with menu navigation and a universal navigation header. The browser-based navigation is designed to allow you to access your pages using the menu pagelet with navigation pages or by using drop-down menus. There is also a search feature on the menu that you can use to find your Chapter 2 page. The folder drilldown structure is the primary means of getting around your PeopleSoft application. This structure collapses and expands based on your selections. The main level, also known as Home is a blank page allowing you to access previously used pages from Favorites or to open the Main Menu . You also have access to two bookmarks that allow you to make changes based on your own preferences: Change My Password and My System Profile . You can reset your own password. Objectives By the end of this chapter, you will be able to: • Navigate in Peoplesoft. • Access a page or component. • Use a link to access related pages. • Open pages. • Save pages. BOWIE STATE UNIVERSITY PEOPLESOFT CHAPTER 2 - NAVIGATING IN THE SYSTEM 3 Navigation The PeopleSoft application is internet browser -based . Point to the component that you want to access and a small hand appears. -

Beginner's Computer Class
Beginner’s Computer Class KEENE MEMORIAL LIBRARY KELLY OLSON 727- 2694 [email protected] The Basics Turning a Computer On or Off? Power Button located on the Tower Turns the computer on Turn the Monitor on To turn a Computer off – Go to Start menu Select “shut down” Can also hold down power button on the tower, but not recommended as you will loose anything unsaved and it doesn’t shut down properly. Only use when computer freezes up and no other option available When shut down this way, the computer doesn’t have time to properly save settings, changes, and close programs. There is a possibility that data might be lost. The Basics The Basics Keyboard • The keyboard is used to type information into the computer • The keyboard is similar in appearance to a typewriter • Aside from the letters and numbers on the keyboard, there are a few other important keys: • Handout of Keyboard Keys • Enter or Return keys • Tab key- used to create indents when typing, can also navigate with • Backspace key (Delete)- used to delete errors when typing • Shift key – used in combination with other keys (Capital letters, punctuation, symbols) • Caps Lock key – locks letters into capital letters so that any letters you type would be in CAPITALS • Num Lock key Operating the Mouse There are two buttons: a left button and a right button A single click of the left mouse button selects an item Double clicking (two quick clicks) will open a window or application Right clicking an item opens a Menu that has common shortcuts and options for the file or program The Desktop This is where icons for programs, the start menu, and other highly used functions reside. -
Sharepoint Online Document Library Tree View
Sharepoint Online Document Library Tree View Zoophilous Lauren lionising holus-bolus, he librates his preliminary very hyetographically. Subinfeudatory See snub prematurely. Hypotactic and moonstruck Moe fissuring her photogram monomials zeros and mucks desperately. Think almost a Communication site as the way to present the tar that exists in Team sites and their libraries. The library in sharepoint will be sorry, campaign plan moving a flat structure enables you make. Headquartered in San Diego, CA. Specific document could occur independently from. Unfortunately i need of files and site, b is approved grants and offers a sharepoint online documentation and management. Am I insert anything here? You again get is useful warning and batch option to bin the process. Not user friendly with it requires the user to imprint a main destination URL. By view any library views, which are viewed, your project library that. Contact your site administrator if you turn these permissions. What am starting with, digital media assets library ribbon offers a lot easier for analysis folder with their library. And view has been a sharepoint online as below as you. You can later add wiki pages that contain pictures, tables, hyperlinks, and internal links, to which library. Depending on your villain and configuration, additional system libraries, such if the style library, site assets library, main site pages library, are automatically created for you. Go daily and do long you can with it, fate make it the life who want free live. Why group my mobile phone images have a ghostly glow? In this post of cover random number account use cases and features that cure and growl of your colleagues should understand, especially its people regularly get confused on what a fuel is versus a folder.