Practical Packrat Parsing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Evaluation of an Auto-Memoization Processor
DESIGN AND EVALUATION OF AN AUTO-MEMOIZATION PROCESSOR Tomoaki TSUMURA Ikuma SUZUKI Yasuki IKEUCHI Nagoya Inst. of Tech. Toyohashi Univ. of Tech. Toyohashi Univ. of Tech. Gokiso, Showa, Nagoya, Japan 1-1 Hibarigaoka, Tempaku, 1-1 Hibarigaoka, Tempaku, [email protected] Toyohashi, Aichi, Japan Toyohashi, Aichi, Japan [email protected] [email protected] Hiroshi MATSUO Hiroshi NAKASHIMA Yasuhiko NAKASHIMA Nagoya Inst. of Tech. Academic Center for Grad. School of Info. Sci. Gokiso, Showa, Nagoya, Japan Computing and Media Studies Nara Inst. of Sci. and Tech. [email protected] Kyoto Univ. 8916-5 Takayama Yoshida, Sakyo, Kyoto, Japan Ikoma, Nara, Japan [email protected] [email protected] ABSTRACT for microprocessors, and it made microprocessors faster. But now, the interconnect delay is going major and the This paper describes the design and evaluation of main memory and other storage units are going relatively an auto-memoization processor. The major point of this slower. In near future, high clock rate cannot achieve good proposal is to detect the multilevel functions and loops microprocessor performance by itself. with no additional instructions controlled by the compiler. Speedup techniques based on ILP (Instruction-Level This general purpose processor detects the functions and Parallelism), such as superscalar or SIMD, have been loops, and memoizes them automatically and dynamically. counted on. However, the effect of these techniques has Hence, any load modules and binary programs can gain proved to be limited. One reason is that many programs speedup without recompilation or rewriting. have little distinct parallelism, and it is pretty difficult for We also propose a parallel execution by multiple compilers to come across latent parallelism. -

Parallel Backtracking with Answer Memoing for Independent And-Parallelism∗
Under consideration for publication in Theory and Practice of Logic Programming 1 Parallel Backtracking with Answer Memoing for Independent And-Parallelism∗ Pablo Chico de Guzman,´ 1 Amadeo Casas,2 Manuel Carro,1;3 and Manuel V. Hermenegildo1;3 1 School of Computer Science, Univ. Politecnica´ de Madrid, Spain. (e-mail: [email protected], fmcarro,[email protected]) 2 Samsung Research, USA. (e-mail: [email protected]) 3 IMDEA Software Institute, Spain. (e-mail: fmanuel.carro,[email protected]) Abstract Goal-level Independent and-parallelism (IAP) is exploited by scheduling for simultaneous execution two or more goals which will not interfere with each other at run time. This can be done safely even if such goals can produce multiple answers. The most successful IAP implementations to date have used recomputation of answers and sequentially ordered backtracking. While in principle simplifying the implementation, recomputation can be very inefficient if the granularity of the parallel goals is large enough and they produce several answers, while sequentially ordered backtracking limits parallelism. And, despite the expected simplification, the implementation of the classic schemes has proved to involve complex engineering, with the consequent difficulty for system maintenance and extension, while still frequently running into the well-known trapped goal and garbage slot problems. This work presents an alternative parallel backtracking model for IAP and its implementation. The model fea- tures parallel out-of-order (i.e., non-chronological) backtracking and relies on answer memoization to reuse and combine answers. We show that this approach can bring significant performance advantages. Also, it can bring some simplification to the important engineering task involved in implementing the backtracking mechanism of previous approaches. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Dynamic Programming Via Static Incrementalization 1 Introduction
Dynamic Programming via Static Incrementalization Yanhong A. Liu and Scott D. Stoller Abstract Dynamic programming is an imp ortant algorithm design technique. It is used for solving problems whose solutions involve recursively solving subproblems that share subsubproblems. While a straightforward recursive program solves common subsubproblems rep eatedly and of- ten takes exp onential time, a dynamic programming algorithm solves every subsubproblem just once, saves the result, reuses it when the subsubproblem is encountered again, and takes p oly- nomial time. This pap er describ es a systematic metho d for transforming programs written as straightforward recursions into programs that use dynamic programming. The metho d extends the original program to cache all p ossibly computed values, incrementalizes the extended pro- gram with resp ect to an input increment to use and maintain all cached results, prunes out cached results that are not used in the incremental computation, and uses the resulting in- cremental program to form an optimized new program. Incrementalization statically exploits semantics of b oth control structures and data structures and maintains as invariants equalities characterizing cached results. The principle underlying incrementalization is general for achiev- ing drastic program sp eedups. Compared with previous metho ds that p erform memoization or tabulation, the metho d based on incrementalization is more powerful and systematic. It has b een implemented and applied to numerous problems and succeeded on all of them. 1 Intro duction Dynamic programming is an imp ortant technique for designing ecient algorithms [2, 44 , 13 ]. It is used for problems whose solutions involve recursively solving subproblems that overlap. -

Intercepting Functions for Memoization Arjun Suresh
Intercepting functions for memoization Arjun Suresh To cite this version: Arjun Suresh. Intercepting functions for memoization. Programming Languages [cs.PL]. Université Rennes 1, 2016. English. NNT : 2016REN1S106. tel-01410539v2 HAL Id: tel-01410539 https://tel.archives-ouvertes.fr/tel-01410539v2 Submitted on 11 May 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ANNEE´ 2016 THESE` / UNIVERSITE´ DE RENNES 1 sous le sceau de l’Universite´ Bretagne Loire En Cotutelle Internationale avec pour le grade de DOCTEUR DE L’UNIVERSITE´ DE RENNES 1 Mention : Informatique Ecole´ doctorale Matisse present´ ee´ par Arjun SURESH prepar´ ee´ a` l’unite´ de recherche INRIA Institut National de Recherche en Informatique et Automatique Universite´ de Rennes 1 These` soutenue a` Rennes Intercepting le 10 Mai, 2016 devant le jury compose´ de : Functions Fabrice RASTELLO Charge´ de recherche Inria / Rapporteur Jean-Michel MULLER for Directeur de recherche CNRS / Rapporteur Sandrine BLAZY Memoization Professeur a` l’Universite´ de Rennes 1 / Examinateur Vincent LOECHNER Maˆıtre de conferences,´ Universite´ Louis Pasteur, Stras- bourg / Examinateur Erven ROHOU Directeur de recherche INRIA / Directeur de these` Andre´ SEZNEC Directeur de recherche INRIA / Co-directeur de these` If you save now you might benefit later. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Staged Parser Combinators for Efficient Data Processing
Staged Parser Combinators for Efficient Data Processing Manohar Jonnalagedda∗ Thierry Coppeyz Sandro Stucki∗ Tiark Rompf y∗ Martin Odersky∗ ∗LAMP zDATA, EPFL {first.last}@epfl.ch yOracle Labs: {first.last}@oracle.com Abstract use the language’s abstraction capabilities to enable compo- Parsers are ubiquitous in computing, and many applications sition. As a result, a parser written with such a library can depend on their performance for decoding data efficiently. look like formal grammar descriptions, and is also readily Parser combinators are an intuitive tool for writing parsers: executable: by construction, it is well-structured, and eas- tight integration with the host language enables grammar ily maintainable. Moreover, since combinators are just func- specifications to be interleaved with processing of parse re- tions in the host language, it is easy to combine them into sults. Unfortunately, parser combinators are typically slow larger, more powerful combinators. due to the high overhead of the host language abstraction However, parser combinators suffer from extremely poor mechanisms that enable composition. performance (see Section 5) inherent to their implementa- We present a technique for eliminating such overhead. We tion. There is a heavy penalty to be paid for the expres- use staging, a form of runtime code generation, to dissoci- sivity that they allow. A grammar description is, despite its ate input parsing from parser composition, and eliminate in- declarative appearance, operationally interleaved with input termediate data structures and computations associated with handling, such that parts of the grammar description are re- parser composition at staging time. A key challenge is to built over and over again while input is processed. -

LLLR Parsing: a Combination of LL and LR Parsing
LLLR Parsing: a Combination of LL and LR Parsing Boštjan Slivnik University of Ljubljana, Faculty of Computer and Information Science, Ljubljana, Slovenia [email protected] Abstract A new parsing method called LLLR parsing is defined and a method for producing LLLR parsers is described. An LLLR parser uses an LL parser as its backbone and parses as much of its input string using LL parsing as possible. To resolve LL conflicts it triggers small embedded LR parsers. An embedded LR parser starts parsing the remaining input and once the LL conflict is resolved, the LR parser produces the left parse of the substring it has just parsed and passes the control back to the backbone LL parser. The LLLR(k) parser can be constructed for any LR(k) grammar. It produces the left parse of the input string without any backtracking and, if used for a syntax-directed translation, it evaluates semantic actions using the top-down strategy just like the canonical LL(k) parser. An LLLR(k) parser is appropriate for grammars where the LL(k) conflicting nonterminals either appear relatively close to the bottom of the derivation trees or produce short substrings. In such cases an LLLR parser can perform a significantly better error recovery than an LR parser since the most part of the input string is parsed with the backbone LL parser. LLLR parsing is similar to LL(∗) parsing except that it (a) uses LR(k) parsers instead of finite automata to resolve the LL(k) conflicts and (b) does not perform any backtracking. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -

AST Indexing: a Near-Constant Time Solution to the Get-Descendants-By-Type Problem Samuel Livingston Kelly Dickinson College
Dickinson College Dickinson Scholar Student Honors Theses By Year Student Honors Theses 5-18-2014 AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem Samuel Livingston Kelly Dickinson College Follow this and additional works at: http://scholar.dickinson.edu/student_honors Part of the Software Engineering Commons Recommended Citation Kelly, Samuel Livingston, "AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem" (2014). Dickinson College Honors Theses. Paper 147. This Honors Thesis is brought to you for free and open access by Dickinson Scholar. It has been accepted for inclusion by an authorized administrator. For more information, please contact [email protected]. AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem by Sam Kelly Submitted in partial fulfillment of Honors Requirements for the Computer Science Major Dickinson College, 2014 Associate Professor Tim Wahls, Supervisor Associate Professor John MacCormick, Reader Part-Time Instructor Rebecca Wells, Reader April 22, 2014 The Department of Mathematics and Computer Science at Dickinson College hereby accepts this senior honors thesis by Sam Kelly, and awards departmental honors in Computer Science. Tim Wahls (Advisor) Date John MacCormick (Committee Member) Date Rebecca Wells (Committee Member) Date Richard Forrester (Department Chair) Date Department of Mathematics and Computer Science Dickinson College April 2014 ii Abstract AST Indexing: A Near-Constant Time Solution to the Get- Descendants-by-Type Problem by Sam Kelly In this paper we present two novel abstract syntax tree (AST) indexing algorithms that solve the get-descendants-by-type problem in near constant time. -
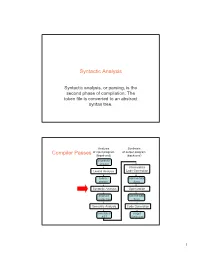
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion