Identification of Recurring Tumor-Specific Somatic Mutations In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2007-05 TLE1 Synovial Sarcoma
TLE1 Immunostains in the Diagnosis of Synovial Sarcoma May 2007 by Rodney T. Miller, M.D., Director of Immunohistochemistry The diagnosis of synovial sarcoma can be a chal- lenging task, particularly on small biopsy specimens, as the morphologic features of this tumor can be mimicked by a variety of other neoplasms. This month we call attention to a paper published in the February 2007 edition of the American Journal of Surgical Pathology describing the utility of immu- nostains for TLE1 in the diagnosis of this tumor. TLE immunostains are now available at ProPath. Synovial sarcoma occurs in three morphologic varie- ties: monophasic, biphasic, and poorly differentiated. It has been known for some time that synovial sar- coma is associated with a specific chromosomal H&E (left) and TLE1 immunostain (right) on a monophasic translocation, t(X;18), that results in the fusion of the synovial sarcoma. Note the numerous strongly positive nuclei SYT gene on chromosome 18 to either the SSX1 or on the TLE1 immunostain, a typical feature of this tumor. SSX2 gene on the X chromosome, resulting in the production of a SYT-SSX fusion protein. Identifica- In their study, the authors performed TLE1 immu- tion of this translocation in the appropriate setting is nostains on multiple tissue microarrays using two dif- regarded by many to be diagnostic of synovial sar- ferent antibodies (monoclonal and polyclonal), both coma. However, the methodologies used for this performing in a similar fashion. A total of 693 adult purpose (cytogenetics, fluorescent in situ hybridiza- soft tissue tumors were examined, including 94 cases tion, and reverse-transcriptase polymerase chain re- of synovial sarcoma that had documentation of the t action) are not readily available in many diagnostic (X;18) translocation. -

Palmitic Acid Effects on Hypothalamic Neurons
bioRxiv preprint doi: https://doi.org/10.1101/2021.08.03.454666; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Running title: Oleic and palmitic acid effects on hypothalamic neurons Concentration-dependent change in hypothalamic neuronal transcriptome by the dietary fatty acids: oleic and palmitic acids Fabiola Pacheco Valencia1^, Amanda F. Marino1^, Christos Noutsos1, Kinning Poon1* 1Department of Biological Sciences, SUNY Old Westbury, Old Westbury NY, United States ^Authors contributed equally to this work *Corresponding Author: Kinning Poon 223 Store Hill Rd Old Westbury, NY 11568, USA 1-516-876-2735 [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2021.08.03.454666; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Abstract Prenatal high-fat diet exposure increases hypothalamic neurogenesis events in embryos and programs offspring to be obesity-prone. The molecular mechanism involved in these dietary effects of neurogenesis are unknown. This study investigated the effects of oleic and palmitic acids, which are abundant in a high-fat diet, on the hypothalamic neuronal transcriptome and how these changes impact neurogenesis events. The results show differential effects of low and high concentrations of oleic or palmitic acid treatment on differential gene transcription. -

Characterizing Novel Interactions of Transcriptional Repressor Proteins BCL6 & BCL6B
Characterizing Novel Interactions of Transcriptional Repressor Proteins BCL6 & BCL6B by Geoffrey Graham Lundell-Smith A thesis submitted in conformity with the requirements for the degree of Master of Science Department of Biochemistry University of Toronto © Copyright by Geoffrey Lundell-Smith, 2017 Characterizing Novel Interactions of Transcriptional Repression Proteins BCL6 and BCL6B Geoffrey Graham Lundell-Smith Masters of Science Department of Biochemistry University of Toronto 2016 Abstract B-cell Lymphoma 6 (BCL6) and its close homolog BCL6B encode proteins that are members of the BTB-Zinc Finger family of transcription factors. BCL6 plays an important role in regulating the differentiation and proliferation of B-cells during the adaptive immune response, and is also involved in T cell development and inflammation. BCL6 acts by repressing genes involved in DNA damage response during the affinity maturation of immunoglobulins, and the mis- expression of BCL6 can lead to diffuse large B-cell lymphoma. Although BCL6B shares high sequence similarity with BCL6, the functions of BCL6B are not well-characterized. I used BioID, an in vivo proximity-dependent labeling method, to identify novel BCL6 and BCL6B protein interactors and validated a number of these interactions with co-purification experiments. I also examined the evolutionary relationship between BCL6 and BCL6B and identified conserved residues in an important interaction interface that mediates corepressor binding and gene repression. ii Acknowledgments Thank you to my supervisor, Gil Privé for his mentorship, guidance, and advice, and for giving me the opportunity to work in his lab. Thanks to my committee members, Dr. John Rubinstein and Dr. Jeff Lee for their ideas, thoughts, and feedback during my Masters. -

Analysis of the Indacaterol-Regulated Transcriptome in Human Airway
Supplemental material to this article can be found at: http://jpet.aspetjournals.org/content/suppl/2018/04/13/jpet.118.249292.DC1 1521-0103/366/1/220–236$35.00 https://doi.org/10.1124/jpet.118.249292 THE JOURNAL OF PHARMACOLOGY AND EXPERIMENTAL THERAPEUTICS J Pharmacol Exp Ther 366:220–236, July 2018 Copyright ª 2018 by The American Society for Pharmacology and Experimental Therapeutics Analysis of the Indacaterol-Regulated Transcriptome in Human Airway Epithelial Cells Implicates Gene Expression Changes in the s Adverse and Therapeutic Effects of b2-Adrenoceptor Agonists Dong Yan, Omar Hamed, Taruna Joshi,1 Mahmoud M. Mostafa, Kyla C. Jamieson, Radhika Joshi, Robert Newton, and Mark A. Giembycz Departments of Physiology and Pharmacology (D.Y., O.H., T.J., K.C.J., R.J., M.A.G.) and Cell Biology and Anatomy (M.M.M., R.N.), Snyder Institute for Chronic Diseases, Cumming School of Medicine, University of Calgary, Calgary, Alberta, Canada Received March 22, 2018; accepted April 11, 2018 Downloaded from ABSTRACT The contribution of gene expression changes to the adverse and activity, and positive regulation of neutrophil chemotaxis. The therapeutic effects of b2-adrenoceptor agonists in asthma was general enriched GO term extracellular space was also associ- investigated using human airway epithelial cells as a therapeu- ated with indacaterol-induced genes, and many of those, in- tically relevant target. Operational model-fitting established that cluding CRISPLD2, DMBT1, GAS1, and SOCS3, have putative jpet.aspetjournals.org the long-acting b2-adrenoceptor agonists (LABA) indacaterol, anti-inflammatory, antibacterial, and/or antiviral activity. Numer- salmeterol, formoterol, and picumeterol were full agonists on ous indacaterol-regulated genes were also induced or repressed BEAS-2B cells transfected with a cAMP-response element in BEAS-2B cells and human primary bronchial epithelial cells by reporter but differed in efficacy (indacaterol $ formoterol . -

EBF1 Drives Hallmark B Cell Gene Expression by Enabling the Interaction of PAX5 with the MLL H3K4 Methyltransferase Complex Charles E
www.nature.com/scientificreports OPEN EBF1 drives hallmark B cell gene expression by enabling the interaction of PAX5 with the MLL H3K4 methyltransferase complex Charles E. Bullerwell1, Philippe Pierre Robichaud1,2, Pierre M. L. Deprez1, Andrew P. Joy1, Gabriel Wajnberg1, Darwin D’Souza1,3, Simi Chacko1, Sébastien Fournier1, Nicolas Crapoulet1, David A. Barnett1,2, Stephen M. Lewis1,2 & Rodney J. Ouellette1,2* PAX5 and EBF1 work synergistically to regulate genes that are involved in B lymphocyte diferentiation. We used the KIS-1 difuse large B cell lymphoma cell line, which is reported to have elevated levels of PAX5 expression, to investigate the mechanism of EBF1- and PAX5-regulated gene expression. We demonstrate the lack of expression of hallmark B cell genes, including CD19, CD79b, and EBF1, in the KIS-1 cell line. Upon restoration of EBF1 expression we observed activation of CD19, CD79b and other genes with critical roles in B cell diferentiation. Mass spectrometry analyses of proteins co-immunoprecipitated with PAX5 in KIS-1 identifed components of the MLL H3K4 methylation complex, which drives histone modifcations associated with transcription activation. Immunoblotting showed a stronger association of this complex with PAX5 in the presence of EBF1. Silencing of KMT2A, the catalytic component of MLL, repressed the ability of exogenous EBF1 to activate transcription of both CD19 and CD79b in KIS-1 cells. We also fnd association of PAX5 with the MLL complex and decreased CD19 expression following silencing of KMT2A in other human B cell lines. These data support an important role for the MLL complex in PAX5-mediated transcription regulation. -

Hes6 Inhibits Astrocyte Differentiation and Promotes Neurogenesis Through Different Mechanisms
The Journal of Neuroscience, October 25, 2006 • 26(43):11061–11071 • 11061 Cellular/Molecular Hes6 Inhibits Astrocyte Differentiation and Promotes Neurogenesis through Different Mechanisms Sumit Jhas, Sorana Ciura,* Stephanie Belanger-Jasmin,* Zhifeng Dong, Estelle Llamosas, Francesca M. Theriault, Kerline Joachim, Yeman Tang, Lauren Liu, Jisheng Liu, and Stefano Stifani Center for Neuronal Survival, Montreal Neurological Institute, McGill University, Montreal, Quebec, Canada H3A 2B4 The mechanisms regulating the generation of cell diversity in the mammalian cerebral cortex are beginning to be elucidated. In that regard, Hairy/Enhancer of split (Hes) 1 and 5 are basic helix-loop-helix (bHLH) factors that inhibit the differentiation of pluripotent cortical progenitors into neurons. In contrast, a related Hes family member termed Hes6 promotes neurogenesis. It is shown here that knockdown of endogenous Hes6 causes supernumerary cortical progenitors to differentiate into cells that exhibit an astrocytic morphol- ogy and express the astrocyte marker protein GFAP. Conversely, exogenous Hes6 expression in cortical progenitors inhibits astrocyte differentiation. The negative effect of Hes6 on astrocyte differentiation is independent of its ability to promote neuronal differentiation. We also show that neither its proneuronal nor its anti-gliogenic functions appear to depend on Hes6 ability to bind to DNA via the basic arm of its bHLH domain. Both of these activities require Hes6 to be localized to nuclei, but only its anti-gliogenic function depends on two short peptides, LNHLL and WRPW, that are conserved in all Hes6 proteins. These findings suggest that Hes6 is an important regulator of the neurogenic phase of cortical development by promoting the neuronal fate while suppressing astrocyte differentiation. -

Variability in the Degree of Expression of Phosphorylated I B in Chronic
6796 Vol. 10, 6796–6806, October 15, 2004 Clinical Cancer Research Featured Article Variability in the Degree of Expression of Phosphorylated IB␣ in Chronic Lymphocytic Leukemia Cases With Nodal Involvement Antonia Rodrı´guez,1 Nerea Martı´nez,1 changes in the expression profile (mRNA and protein ex- Francisca I. Camacho,1 Elena Ruı´z-Ballesteros,2 pression) and clinical outcome in a series of CLL cases with 2 1 lymph node involvement. Activation of NF-B, as deter- Patrocinio Algara, Juan-Fernando Garcı´a, ␣ 3 5 mined by the expression of p-I B , was associated with the Javier Mena´rguez, Toma´s Alvaro, expression of a set of genes comprising key genes involved in 6 4 Manuel F. Fresno, Fernando Solano, the control of B-cell receptor signaling, signal transduction, Manuela Mollejo,2 Carmen Martin,1 and and apoptosis, including SYK, LYN, BCL2, CCR7, BTK, Miguel A. Piris1 PIK3CD, and others. Cases with increased expression of ␣ 1Molecular Pathology Program, Centro Nacional de Investigaciones p-I B showed longer overall survival than cases with lower Oncolo´gicas, Madrid, Spain; 2Department of Genetics and Pathology, expression. A Cox regression model was derived to estimate 3 Hospital Virgen de la Salud, Toledo, Spain; Department of some parameters of prognostic interest: IgVH mutational Pathology, Hospital General Universitario Gregorio Maran˜o´n, ␣ 4 status, ZAP-70, and p-I B expression. The multivariate Madrid, Spain; Department of Hematology, Hospital Nuestra Sen˜ora analysis disclosed p-IB␣ and ZAP-70 expression as inde- del Prado, Talavera de la Reina, Toledo, Spain; 5Department of Pathology, Hospital Verge de la Cinta, Tortosa, Spain; pendent prognostic factors of survival. -

RUNX3 Is Multifunctional in Carcinogenesis of Multiple Solid Tumors
Oncogene (2010) 29, 2605–2615 & 2010 Macmillan Publishers Limited All rights reserved 0950-9232/10 $32.00 www.nature.com/onc REVIEW RUNX3 is multifunctional in carcinogenesis of multiple solid tumors LSH Chuang1 and Y Ito1,2,3 1Cancer Biology Program, Cancer Science Institute of Singapore, National University of Singapore, Singapore; 2Department of Medicine, Yong Loo Lin School of Medicine, National University of Singapore, Singapore and 3Institute of Molecular and Cell Biology, Singapore The study of RUNX3 in tumor pathogenesis is a rapidly Sgpp1, Ncam1, p21WAF1) (Wotton et al., 2008), the expanding area of cancer research. Functional inactiva- RUNX proteins have been shown to perform distinct tion of RUNX3—through mutation, epigenetic silencing, functions that are dependent on tissue type (Brady and or cytoplasmic mislocalization—is frequently observed in Farrell, 2009). This review explores the dualistic solid tumors of diverse origins. This alone indicates that associations of RUNX3 with cancer with emphasis on RUNX3 inactivation is a major risk factor in tumorigen- the emerging concept of RUNX3 as a multifunctional esis and that it occurs early during progression to suppressor of solid tumors. malignancy. Conversely, RUNX3 has also been described to have an oncogenic function in a subset of tumors. Although the mechanism of how RUNX3 switches from RUNX3 inactivation is prevalent in solid tumors tumor suppressive to oncogenic activity is unclear, this is of clinical relevance with implications for cancer detection Hemizygous deletion of RUNX3 gene and prognosis. Recent developments have significantly The location of RUNX3 at chromosome 1p36, a deletion contributed to our understanding of the pleiotropic tumor hotspot in diverse cancers of epithelial, hematopoietic, suppressive properties of RUNX3 that regulate major and neural origins (Bagchi and Mills, 2008), prompts signaling pathways. -

TLE1 Corepressor Complex Mediates a Camkinase II␦-Dependent Neurogenic Gene Activation Pathway
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Cell, Vol. 119, 815–829, December 17, 2004, Copyright ©2004 by Cell Press ActivatingthePARP-1SensorComponentoftheGroucho/ TLE1 Corepressor Complex Mediates a CaMKinase II␦-Dependent Neurogenic Gene Activation Pathway Bong-Gun Ju,1 Derek Solum,1 Eun Joo Song,4 entiate into neurons in response to both extrinsic and Kong-Joo Lee,4 David W. Rose,2 intrinsic cues (reviewed in Bally-Cuif and Hammer- Christopher K. Glass,3 and Michael G. Rosenfeld1,* schmidt [2003]). The commitment of neural stem cells 1Howard Hughes Medical Institute to the neuronal fate and their subsequent differentiation 2 Department of Medicine into neurons are controlled, in part, by mechanisms in- Division of Endocrinology volving the opposing activities of transcription factor 3 Department of Cellular and Molecular Medicine families containing the basic helix-loop-helix (bHLH) do- University of California, San Diego main, the Hairy/Enhancer of split (HES) family proteins Department and School of Medicine that negatively regulate neural differentiation, and other La Jolla, California 92093 bHLH family proteins belonging to the Neurogenin, Ash, 4 Center for Cell Signaling Research and NeuroD subgroups, collectively referred to as Division of Molecular Life Sciences and College proneural proteins (reviewed in Bertrand et al. [2002]; of Pharmacy Ross et al. [2003]). Ewha Womans University The inhibitory bHLH protein, HES1, interacts with Seoul 120-750 groucho (Gro)/transducin like enhancer of split (TLE) Korea corepressor in a manner dependent on its C-terminal WRPW motif and serves in a well-described repressor of MASH1 transcription preventing neuronal differentiation Summary (reviewed in Chen and Courey [2000]). -
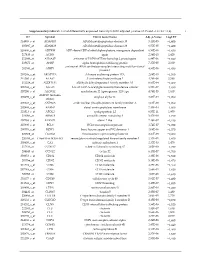
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at -

Mutations in PAX2 Associate with Adult-Onset FSGS
BASIC RESEARCH www.jasn.org Mutations in PAX2 Associate with Adult-Onset FSGS † ‡ | Moumita Barua,* Emilia Stellacci, Lorenzo Stella, Astrid Weins,§ Giulio Genovese,* ¶** † †† ‡‡ Valentina Muto, Viviana Caputo, Hakan R. Toka,* Victoria T. Charoonratana,* † Marco Tartaglia, and Martin R. Pollak* *Division of Nephrology, Department of Medicine, Beth Israel Deaconess Medical Center, Boston, Massachusetts; †Department of Hematology, Oncology and Molecular Medicine, National Institute of Health, Rome, Italy; ‡Department of Chemical Science and Technology, University of Rome Tor Vergata, Rome, Italy; §Department of Pathology, and ‡‡Division of Nephrology, Department of Medicine, Brigham and Women’s Hospital, Boston, Massachusetts; |Stanley Center for Psychiatric Research, Cambridge, Massachusetts; ¶Program in Medical and Population Genetics, Broad Institute of MIT and Harvard, Cambridge, Massachusetts; **Department of Genetics, Harvard Medical School, Boston, Massachusetts; and ††Department of Experimental Medicine, University “La Sapienza,” Rome, Italy ABSTRACT FSGS is characterized by the presence of partial sclerosis of some but not all glomeruli. Studies of familial FSGS have been instrumental in identifying podocytes as critical elements in maintaining glomerular function, but underlying mutations have not been identified for all forms of this genetically heterogeneous condition. Here, exome sequencing in members of an index family with dominant FSGS revealed a nonconservative, disease-segregating variant in the PAX2 transcription factor -

Transcriptional Repression by FEZF2 Restricts Alternative Identities of Cortical Projection Neurons
HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Cell Rep Manuscript Author . Author manuscript; Manuscript Author available in PMC 2021 August 02. Published in final edited form as: Cell Rep. 2021 June 22; 35(12): 109269. doi:10.1016/j.celrep.2021.109269. Transcriptional repression by FEZF2 restricts alternative identities of cortical projection neurons Jeremiah Tsyporin1,7, David Tastad1,7, Xiaokuang Ma2, Antoine Nehme2, Thomas Finn1, Liora Huebner1, Guoping Liu3, Daisy Gallardo1, Amr Makhamreh1, Jacqueline M. Roberts1, Solomon Katzman4, Nenad Sestan5, Susan K. McConnell6, Zhengang Yang3, Shenfeng Qiu2, Bin Chen1,8,* 1Department of Molecular, Cell, and Developmental Biology, University of California, Santa Cruz, 1156 High Street, Santa Cruz, CA 95064, USA 2Department of Basic Medical Sciences, University of Arizona College of Medicine – Phoenix, Phoenix, AZ 85004, USA 3State Key Laboratory of Medical Neurobiology and MOE Frontiers Center for Brain Science, Institute for Translational Brain Research, Institutes of Brain Science, Department of Neurology, Zhongshan Hospital, Fudan University, Shanghai 200032, China 4Genomics Institute, University of California, Santa Cruz, Santa Cruz, CA 95064, USA 5Department of Neuroscience, Yale School of Medicine, New Haven, CT 06520, USA 6Department of Biology, Stanford University, Stanford, CA 94305, USA 7These authors contributed equally 8Lead contact SUMMARY Projection neuron subtype identities in the cerebral cortex are established by expressing pan- cortical and subtype-specific effector genes that execute terminal differentiation programs bestowing neurons with a glutamatergic neuron phenotype and subtype-specific morphology, physiology, and axonal projections. Whether pan-cortical glutamatergic and subtype-specific characteristics are regulated by the same genes or controlled by distinct programs remains largely unknown.