The XML Revolution Revised Basic Research in Computer Science
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
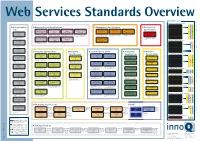
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

Toward the Discovery and Extraction of Money Laundering Evidence from Arbitrary Data Formats Using Combinatory Reductions
Toward the Discovery and Extraction of Money Laundering Evidence from Arbitrary Data Formats using Combinatory Reductions Alonza Mumford, Duminda Wijesekera George Mason University [email protected], [email protected] Abstract—The evidence of money laundering schemes exist undetected in the electronic files of banks and insurance firms scattered around the world. Intelligence and law enforcement analysts, impelled by the duty to discover connections to drug cartels and other participants in these criminal activities, require the information to be searchable and extractable from all types of data formats. In this overview paper, we articulate an approach — a capability that uses a data description language called Data Format Description Language (DFDL) extended with higher- order functions as a host language to XML Linking (XLink) and XML Pointer (XPointer) languages in order to link, discover and extract financial data fragments from raw-data stores not co- located with each other —see figure 1. The strength of the ap- Fig. 1. An illustration of an anti-money laundering application that connects proach is grounded in the specification of a declarative compiler to multiple data storage sites. In this case, the native data format at each site for our concrete language using a higher-order rewriting system differs, and a data description language extended with higher-order functions with binders called Combinatory Reduction Systems Extended and linking/pointing abstractions are used to extract data fragments based on (CRSX). By leveraging CRSX, we anticipate formal operational their ontological meaning. semantics of our language and significant optimization of the compiler. Index Terms—Semantic Web, Data models, Functional pro- II. -

O'reilly Xpath and Xpointer.Pdf
XPath and XPointer John E. Simpson Publisher: O'Reilly First Edition August 2002 ISBN: 0-596-00291-2, 224 pages Referring to specific information inside an XML document is a little like finding a needle in a haystack. XPath and XPointer are two closely related Table of Contents languages that play a key role in XML processing by allowing developers Index to find these needles and manipulate embedded information. By the time Full Description you've finished XPath and XPointer, you'll know how to construct a full Reviews XPointer (one that uses an XPath location path to address document Reader reviews content) and completely understand both the XPath and XPointer features it Errata uses. 1 Table of Content Table of Content ............................................................................................................. 2 Preface............................................................................................................................. 4 Who Should Read This Book?.................................................................................... 4 Who Should Not Read This Book?............................................................................. 4 Organization of the Book............................................................................................ 5 Conventions Used in This Book ................................................................................. 5 Comments and Questions ........................................................................................... 6 Acknowledgments...................................................................................................... -

Annotea: an Open RDF Infrastructure for Shared Web Annotations
Proceedings of the WWW 10th International Conference, Hong Kong, May 2001. Annotea: An Open RDF Infrastructure for Shared Web Annotations Jos´eKahan,1 Marja-Riitta Koivunen,2 Eric Prud’Hommeaux2 and Ralph R. Swick2 1 W3C INRIA Rhone-Alpes 2 W3C MIT Laboratory for Computer Science {kahan, marja, eric, swick}@w3.org Abstract. Annotea is a Web-based shared annotation system based on a general-purpose open RDF infrastructure, where annotations are modeled as a class of metadata.Annotations are viewed as statements made by an author about a Web doc- ument. Annotations are external to the documents and can be stored in one or more annotation servers.One of the goals of this project has been to re-use as much existing W3C technol- ogy as possible. We have reacheditmostlybycombining RDF with XPointer, XLink, and HTTP. We have also implemented an instance of our system using the Amaya editor/browser and ageneric RDF database, accessible through an Apache HTTP server. In this implementation, the merging of annotations with documents takes place within the client. The paper presents the overall design of Annotea and describes some of the issues we have faced and how we have solved them. 1Introduction One of the basic milestones in the road to a Semantic Web [22] is the as- sociation of metadata to content. Metadata allows the Web to describe properties about some given content, even if the medium of this content does not directly provide the necessary means to do so. For example, ametadata schema for digital photos [15] allows the Web to describe, among other properties, the camera model used to take a photo, shut- ter speed, date, and location. -

Advanced XHTML Plug-In for Iserver
Advanced XHTML Plug-in for iServer Semester work Stefan Malaer <[email protected]> Prof. Dr. Moira C. Norrie Dr. Beat Signer Global Information Systems Group Institute of Information Systems Department of Computer Science 12th October 2005 Copyright © 2005 Global Information Systems Group. Abstract The iServer architecture is an extensible cross-media information platform enabling links between arbitrary typed objects. It provides some fundamental link concepts and is based on a plug-in mechanism to support various media types. The goal of this semester work was to develop a XHTML plug-in for iServer which enables links from XHTML documents to other XHTML documents as well as parts of them. The resulting iServext is a Firefox extension for iServer which provides visualization and authoring functionality for XHTML links. Furthermore, we investigated research in the area of link augmentation and provide an overview of recent technologies. iii iv Contents 1 Introduction 1 2 Augmented Linking 3 2.1 Need for augmented linking ........................... 3 2.1.1 Current link model ............................ 3 2.1.2 Approaches for link augmentation ................... 5 2.2 Related work .................................... 6 2.2.1 Chimera .................................. 6 2.2.2 Hyper-G/Hyperwave ........................... 6 2.2.3 Distributed Link Service ......................... 6 2.2.4 DHM/WWW and Extend Work ..................... 6 2.2.5 HyperScout ................................. 7 2.2.6 Link Visualization with DHTML ..................... 7 2.2.7 Amaya project ............................... 8 2.3 Link integration and authoring ......................... 9 2.4 Link visualization .................................. 11 2.4.1 Today’s link visualization ......................... 11 2.4.2 Possible presentations of link information .............. 11 2.4.3 Examples of link visualization ..................... -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Dynamic and Interactive R Graphics for the Web: the Gridsvg Package
JSS Journal of Statistical Software MMMMMM YYYY, Volume VV, Issue II. http://www.jstatsoft.org/ Dynamic and Interactive R Graphics for the Web: The gridSVG Package Paul Murrell Simon Potter The Unversity of Auckland The Unversity of Auckland Abstract This article describes the gridSVG package, which provides functions to convert grid- based R graphics to an SVG format. The package also provides a function to associate hyperlinks with components of a plot, a function to animate components of a plot, a function to associate any SVG attribute with a component of a plot, and a function to add JavaScript code to a plot. The last two of these provides a basis for adding interactivity to the SVG version of the plot. Together these tools provide a way to generate dynamic and interactive R graphics for use in web pages. Keywords: world-wide web, graphics, R, SVG. 1. Introduction Interactive and dynamic plots within web pages are becomingly increasingly popular, as part of a general trend towards making data sets more open and accessible on the web, for example, GapMinder (Rosling 2008) and ManyEyes (Viegas, Wattenberg, van Ham, Kriss, and McKeon 2007). The R language and environment for statistical computing and graphics (R Development Core Team 2011) has many facilities for producing plots, and it can produce graphics formats that are suitable for including in web pages, but the core graphics facilities in R are largely focused on static plots. This article describes an R extension package, gridSVG, that is designed to embellish and transform a standard, static R plot and turn it into a dynamic and interactive plot that can be embedded in a web page. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

RDF/XML: RDF Data on the Web
Developing Ontologies • have an idea of the required concepts and relationships (ER, UML, ...), • generate a (draft) n3 or RDF/XML instance, • write a separate file for the metadata, • load it into Jena with activating a reasoner. • If the reasoner complains about an inconsistent ontology, check the metadata file alone. If this is consistent, and it complains only when also data is loaded: – it may be due to populating a class whose definition is inconsistent and that thus must be empty. – often it is due to wrong datatypes. Recall that datatype specification is not interpreted as a constraint (that is violated for a given value), but as additional knowledge. 220 Chapter 6 RDF/XML: RDF Data on the Web • An XML representation of RDF data for providing RDF data on the Web could be done straightforwardly as a “holds” relation mapped according to SQLX (see ⇒ next slide). • would be highly redundant and very different from an XML representation of the same data • search for a more similar way: leads to “striped XML/RDF” – data feels like XML: can be queried by XPath/Query and transformed by XSLT – can be parsed into an RDF graph. • usually: provide RDF/XML data to an agreed RDFS/OWL ontology. 221 A STRAIGHTFORWARD XML REPRESENTATION OF RDF DATA Note: this is not RDF/XML, but just some possible representation. • RDF data are triples, • their components are either URIs or literals (of XML Schema datatypes), • straightforward XML markup in SQLX style, • since N3 has a term structure, it is easy to find an XML markup. <my-n3:rdf-graph xmlns:my-n3="http://simple-silly-rdf-xml.de#"> <my-n3:triple> <my-n3:subject type="uri">foo://bar/persons/john</my-n3:subject> <my-n3:predicate type="uri">foo://bar/meta#name</my-n3:predicate> <my-n3:object type="http://www.w3.org/2001/XMLSchema#string">John</my-n3:object> </my-n3 triple> <my-n3:triple> ..