Assessing Asset Pricing Models Using Revealed Preference∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Cost of Equity Capital for Reits: an Examination of Three Asset-Pricing Models
MIT Center for Real Estate September, 2000 The Cost of Equity Capital for REITs: An Examination of Three Asset-Pricing Models David N. Connors Matthew L. Jackman Thesis, 2000 © Massachusetts Institute of Technology, 2000. This paper, in whole or in part, may not be cited, reproduced, or used in any other way without the written permission of the authors. Comments are welcome and should be directed to the attention of the authors. MIT Center for Real Estate, 77 Massachusetts Avenue, Building W31-310, Cambridge, MA, 02139-4307 (617-253-4373). THE COST OF EQUITY CAPITAL FOR REITS: AN EXAMINATION OF THREE ASSET-PRICING MODELS by David Neil Connors B.S. Finance, 1991 Bentley College and Matthew Laurence Jackman B.S.B.A. Finance, 1996 University of North Carolinaat Charlotte Submitted to the Department of Urban Studies and Planning in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN REAL ESTATE DEVELOPMENT at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 2000 © 2000 David N. Connors & Matthew L. Jackman. All Rights Reserved. The authors hereby grant to MIT permission to reproduce and to distribute publicly paper and electronic (\aopies of this thesis in whole or in part. Signature of Author: - T L- . v Department of Urban Studies and Planning August 1, 2000 Signature of Author: IN Department of Urban Studies and Planning August 1, 2000 Certified by: Blake Eagle Chairman, MIT Center for Real Estate Thesis Supervisor Certified by: / Jonathan Lewellen Professor of Finance, Sloan School of Management Thesis Supervisor -

The Continuing Evolution of NAV Facilities
The continuing evolution of NAV facilities Meyer C. Dworkin & Samantha Hait Davis Polk & Wardwell LLP Background In recent years, credit facilities provided to private equity funds have been dominated by two forms: “Subscription Facilities” and “NAV Facilities”. Subscription Facilities – sometimes referred to as “capital call” credit facilities – have become increasingly common for newer funds with significant unfunded capital commitments, with the loans thereunder secured by the fund’s right to call such capital commitments from its investors. Availability under Subscription Facilities is subject to a “borrowing base”, calculated as an agreed advance percentage of unfunded commitments of certain “included” investors in the fund (with the inclusion and “advance rates” dependent on the creditworthiness of each such investor). Subscription Facilities are generally intended to serve a fund borrower’s short- term capital needs by bridging the time between the issuance of capital calls to investors and the time such capital is actually contributed. For many funds, however, Subscription Facilities are not a viable option, either because the fund’s organisational documents do not permit such facilities or, in the case of a mature fund, the fund has already called a significant portion of its commitments, leaving it with minimal unfunded commitments against which to borrow. These private equity funds have sought instead to raise capital through “asset backed” or net asset value facilities: “NAV Facilities”. NAV Facilities are credit facilities backed by the fund’s investment portfolio. For a “fund- of-funds”, these assets will typically be the limited partnership and other equity interests in hedge funds and private equity funds, consisting of both primary investments as well as those purchased in the secondary market. -

Net Asset Value Purchase Application Attach To: Account Application Or IRA Application
Net Asset Value Purchase Application Attach to: Account Application or IRA Application Net Asset Value Purchase is Available Because Account Owner is: All future purchases will be at NAV: Account should be coded NAV Account (a) Purchases by qualified retirement and benefit plans. (b) Non-dealer assisted (or assisted only by the Distributor) purchases by bank or trust company in a single account where such bank or trust company is named as the trustee. (c) Non-dealer assisted (or assisted only by the Distributor) purchase by banks, insurance companies, insurance company separate accounts and other institutional purchasers. (d) A registered investment adviser purchasing shares on behalf of a client or on his or her own behalf through an intermediary service institution offering a separate and established program for registered investment advisers and notifying the Funds and Distributor of such arrangement. (e) Fee-based account clients of registered investment advisers. (f) Sales through a broker-dealer to its customer under an arrangement in which the customer pays the broker-dealer a fee based on the value of the account, in lieu of transaction based brokerage. (g) Sales to broker-dealers who conduct their business with their customers principally through the Internet and do not have registered representatives who actively solicit those customers to purchase securities, including shares of the Funds. (h) Any current or retired Officer, Director or employee of the Funds, Adviser, Distributor or any affiliated company thereof. This shall also apply to their immediate family members. (i) Registered representatives, their spouses and minor children, and employees of dealer firms that have a distribution agreement with the Distributor. -

Mutual Funds: Understanding NAV, Yield, and Total Return
Mutual Funds: Understanding NAV, Yield, and Total Return Mutual fund investors will commonly encounter three key metrics: the NAV, the yield, and the total return. Comprehending the differences and inter-relationships of these metrics is critical to understanding how well (or poorly) you have done with your mutual fund selection. Calculating the NAV A mutual fund's net asset value (NAV) represents its per-share price and is calculated by dividing a fund's total net assets by its number of shares outstanding. Because shares in regular open-end mutual funds are bought and sold at NAV, NAVs may seem similar to stock prices; after all, both represent the price of one share of an investment. Both appear in newspapers and on financial websites. But that's where the similarities between NAVs and stock prices end. A mutual fund calculates its NAV by adding up the current value of all the stocks, bonds, and other securities (including cash) in its portfolio, subtracting the manager's salary and other operating expenses, and then dividing that figure by the fund's total number of shares. For example, a fund with 500,000 shares that owns $9 million in stocks and $1 million in cash has an NAV of $20. So Alike but So Very Different NAVs and stock prices differ in five important ways. 1. Stock prices change throughout the trading day, but mutual fund NAVs are calculated only once each day, based on the value of their stocks or bonds at the time the market closes. When you purchase a mutual fund, you buy shares at the NAV as of that day's close. -

Efficiently Inefficient Markets for Assets and Asset Management
NBER WORKING PAPER SERIES EFFICIENTLY INEFFICIENT MARKETS FOR ASSETS AND ASSET MANAGEMENT Nicolae B. Gârleanu Lasse H. Pedersen Working Paper 21563 http://www.nber.org/papers/w21563 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 September 2015 We are grateful for helpful comments from Jules van Binsbergen, Ronen Israel, Stephen Mellas, Jim Riccobono, Andrei Shleifer, and Morten Sorensen, as well as from seminar participants at Harvard University, New York University, UC Berkeley-Haas, CEMFI, IESE, Toulouse School of Economics, MIT Sloan, Copenhagen Business School, and the conferences at Queen Mary University of London, the Cowles Foundation at Yale University, the European Financial Management Association Conference, the 7th Erasmus Liquidity Conference, the IF2015 Annual Conference in International Finance, the FRIC'15 Conference, and the Karl Borch Lecture. Pedersen gratefully acknowledges support from the European Research Council (ERC grant no. 312417) and the FRIC Center for Financial Frictions (grant no. DNRF102) The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. At least one co-author has disclosed a financial relationship of potential relevance for this research. Further information is available online at http://www.nber.org/papers/w21563.ack NBER working papers are circulated for discussion and comment purposes. They have not been peer- reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2015 by Nicolae B. Gârleanu and Lasse H. Pedersen. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source. -
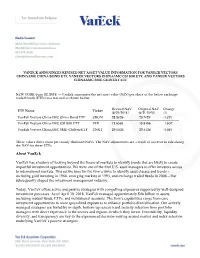
Nav-Error-Cbon-Cnxt-Pek-6-22-18.Pdf
VANECK ANNOUNCES REVISED NET ASSET VALUE INFORMATION FOR VANECK VECTORS CHINAAMC CHINA BOND ETF, VANECK VECTORS CHINAAMC CSI 300 ETF, AND VANECK VECTORS CHINAAMC SME-CHINEXT ETF NEW YORK (June 22, 2018) — VanEck announces the net asset value (NAV) per share of the below exchange traded funds (ETFs) was restated as shown below: Revised NAV Original NAV Change ETF Name Ticker (6/21/2018 ) (6/21/2018) (%) VanEck Vectors ChinaAMC China Bond ETF CBON 23.3826 23.7429 -1.52% VanEck Vectors ChinaAMC CSI 300 ETF PEK 42.6568 43.3496 -1.60% VanEck Vectors ChinaAMC SME-ChiNextETF CNXT 29.0834 29.5436 -1.56% These values differ from previously disclosed NAVs. The NAV adjustments are a result of an error in calculating the NAV for these ETFs. About VanEck VanEck has a history of looking beyond the financial markets to identify trends that are likely to create impactful investment opportunities. We were one of the first U.S. asset managers to offer investors access to international markets. This set the tone for the firm’s drive to identify asset classes and trends – including gold investing in 1968, emerging markets in 1993, and exchange traded funds in 2006 – that subsequently shaped the investment management industry. Today, VanEck offers active and passive strategies with compelling exposures supported by well-designed investment processes. As of April 30, 2018, VanEck managed approximately $46 billion in assets, including mutual funds, ETFs, and institutional accounts. The firm’s capabilities range from core investment opportunities to more specialized exposures to enhance portfolio diversification. Our actively managed strategies are fueled by in-depth, bottom-up research and security selection from portfolio managers with direct experience in the sectors and regions in which they invest. -

Frequently Asked Questions: Nextshares Exchange-Traded Managed Funds
FREQUENTLY ASKED QUESTIONS: NEXTSHARES EXCHANGE-TRADED MANAGED FUNDS Overview 1. What is a NextShares Exchange-Traded Managed Fund? NextShares Exchange Traded Managed Funds are a new type of exchange-traded product designed to bring the performance advantages and tax efficiencies of ETFs to active fund strategies while protecting confidential portfolio trading information. NextShares will be required to disclose their portfolio holdings at least quarterly with no more than a sixty-day lag, like mutual funds. The SEC issued an order granting Eaton Vance approval to offer NextShares on December 2, 2014. Additional information on NextShares can be found at www.nextshares.com. 2. How do NextShares differ from a traditional ETF? Like a mutual fund, NextShares are not required to disclose fund holdings on a daily basis. Rather than requiring market markers to calculate the Intraday Net Asset Value (NAV)in order to make a market, intraday prices will be reflected in a market-determined spread (discount or premium) to next end-of-day NAV. 3. What is the relationship between Nasdaq and NextShares Solutions? NextShares Solutions LLC is a wholly-owned subsidiary of Eaton Vance Corp and is the owner of the NextShares Intellectual Property (IP). Nasdaq will be the primary listing venue for NextShares and Nasdaq has enhanced proprietary trade and data platforms to support both listing and trading of NextShares. 5. When does Nasdaq plan to begin trading NextShares? The first NextShares is expected to launch on February 26, 2016. 6. What are the trading hours for NextShares? NextShares will be available to trade on the Nasdaq Stock Market during regular market hours (9:30 a.m. -

SELLING the FUND's SHARES the Investment Company Industry Has
SELLING THE FUND’S SHARES The investment company industry has developed into a mature industry with more and more funds competing for the same investor dollars. As the mutual fund marketplace becomes increasingly complex and competitive, funds continue to search for different, more effective ways to gain access to customers and ensure that their investors receive high quality services. A number of different arrangements currently offer funds new or enhanced distribution channels and these often encompass the provision of various non-distribution services as well. Each such selling arrangement is designed to enable a product to reach and satisfy a broader range of investors by offering an alternative with respect to the cost and service features applicable to the investment product. I. DISTRIBUTION OPTIONS A. Direct Sales Fund companies using the direct sales channel market their product directly to consumers through retail advertising and other mass media techniques. These firms employ a force of representatives manning the company’s toll-free telephone lines who respond to investor questions and take transaction orders but do not typically provide investment advice. B. Captive Sales Forces In recent years, this sales channel has lost market share, although historically it was quite significant. Fund companies adopting this approach employ a force of registered representatives, typically through an affiliated broker-dealer. These representatives engage primarily or exclusively in the sale of the fund company’s products, allowing them to gain deep familiarity with those products as well as to foster a sense of consumer loyalty for the fund company. C. Fund Supermarkets A fund supermarket is a program run by a broker-dealer or other institution through which investors may buy and sell a variety of funds. -

Noise Training, Costly Arbitrage and Asset Prices
WORKING PAPERS SERIES WP02-09 Noise Training, Costly Arbitrage and Asset Prices: evidence from closed-end funds Gordon Gemmill and Dylan Thomas Noise-Trading, Costly Arbitrage, and Asset Prices: Evidence from Closed End Funds GORDON GEMMILL and DYLAN C. THOMAS* ABSTRACT If arbitrage is costly and noise traders are active, asset prices may deviate from fundamental values for long periods of time. We use a sample of 158 closed-end funds to show that noise-trader sentiment, as proxied by retail-investor flows, leads to fluctuations in the discount. Nevertheless, we reject the hypothesis that noise-trader risk is the cause of the long-run discount. Instead we find that funds which are more difficult to arbitrage have larger discounts, due to: (i) the censoring of the discount by the arbitrage bounds, and (ii) the freedom of managers to increase charges when arbitrage is costly. * Faculty of Finance, City University Business School, London. We would like to thank the editor, Richard Green, and especially the anonymous referee for constructive suggestions in improving the paper. Other helpful comments were made by Meziane Lasfer, Mark Salmon and seminar participants at City University, Maastricht University and the European Financial Management Association (June 2000). 1 DeLong, Shleifer, Summers, and Waldmann (1990) (hereafter DSSW) describe a market as a contest between arbitrageurs, whose expectations are rational, and noise traders, whose expectations are based on sentiment. Not only does an arbitrageur have to manage the fundamental risk on a position, but he (she) also bears “the risk that noise traders’ beliefs will not revert to their mean for a long time and might in the meantime become even more extreme” (DSSW, page 704). -

Henderson Diversified Income Trust Plc
Investment Trust For promotional purposes HENDERSON DIVERSIFIED INCOME TRUST PLC www.hendersondiversifiedincome.com Fund facts at 31 August 2021 Company objective NAV and Share Price Performance (total return) Dividend history (pence/share)* The Trust seeks income and capital 12 growth such that the total return on the 130 net asset value of the Company exceeds 10 the average return on a rolling annual 120 basis of three month sterling LIBOR plus 8 2 per cent. 110 The Trust invests in a diversified portfolio of global assets including secured loans, 6 government bonds, high yield (sub- 100 investment grade) corporate bonds, 4 unrated corporate bonds, investment 90 grade corporate bonds and asset 2 backed securities. The Company may 80 also invest in high yielding equities and 2016 2018 2019 2009 2010 2013 2015 2008 2011 2012 2014 2020 Aug Aug Aug Aug 0 2021 derivatives. 18 19 20 21 The Trust may use derivatives to achieve Price (rebased) its investment objective, to reduce risk or NAV (cum income) Income to be managed more effectively. The Sterling Libor target** Company may also employ financial *In the 2008 financial year, five interim dividends were paid over a 15 month period totalling gearing for efficient portfolio 9.65p. In the 18 month period to 30 April 2018, the payments comprised of two dividends totalling 2.5p from Henderson Diversified Income Limited and four interest distributions management purposes and to enhance totalling 4.55p from Henderson Diversified Income Trust plc. Please note that the chart investment returns. includes payments that have been declared but not yet paid. -

A Review on the Efficient Market Hypothesis And
Indian Journal of Fundamental and Applied Life Sciences ISSN: 2231– 6345 (Online) An Open Access, Online International Journal Available at http:// http://www.cibtech.org/sp.ed/jls/2014/01/jls.htm 2014 Vol. 4 (S1) April-June, pp. 865-872/Hamdi and Mousavi Review Article A REVIEW ON THE EFFICIENT MARKET HYPOTHESIS AND STOCK VALUATION MODELS *Vahid Hamdi1, Seyed Miirbakhsh Kamrani Mousavi2 1 Department of Accounting, Science and Research branch, Islamic Azad University, Ilam, Iran 2 Department of Accounting, Science and Research branch, Islamic Azad University, Kermanshah, Iran *Author for Correspondence ABSTRACT Nowadays, one of the key approaches to reach a stable development in developing countries is privatization of the government-owned firms. This is mainly done by selling the firms’ shares at the stock exchange markets. The stock pricing is central to the privatization process. Many models have been developed for stock price modeling which have had various feedback and functionalities within different economic, political and regional situations. Modern financial theory states that although, there are some exception in the mark, these exceptions are mainly due to inappropriate selection of data or incorrect definition of the systematic risk. In this paper we review the efficient market hypothesis and different models for stock pricing and valuation. This review shows that a fair judgment on market efficiency necessitates using proper standards and modeling and this, in turn, requires a close interaction between the financial market and academia. Keywords: Efficient Market Hypothesis, Stock Pricing, Stock Valuation Models Economic reform leading to privatization is one of the strategic approaches for the economic growth of the world’s countries. -

Victoryshares QQQN Fact Sheet
VictoryShares Nasdaq Next 50 ETF As of June 30, 2021 Offers exposure to the new generation of innovators: FUND CHARACTERISTICS 50 stocks that are next in line for inclusion in the Ticker Symbol QQQN Index Symbol NXTQ ® Nasdaq-100 Index . CUSIP 92647X806 IIV Ticker QQQN.IV Seeks to provide investment results that track the Primary Listing NASDAQ performance of the Nasdaq Q-50 Index® before fees Morningstar Category Mid-Cap Growth Number of Holdings 52 and expenses. Average Market Capitalization $28.1B Average P/E Ratio 278.1 Standard Deviation - About the index Sharpe Ratio - Aligns with the innovation and growth focus behind the time-tested Nasdaq-100 R-Squared - Index, but with an emphasis on the next generation of market leadership. ▪ The Index is a market-capitalization weighted index designed to track the performance of the 50 securities that are next-eligible for inclusion into the Nasdaq-100 Index. Index methodology ▪ Starts with a universe of all companies, both domestic and foreign, that are listed on the Nasdaq Stock Exchange ▪ Removes all companies classified as financials ▪ Selects the largest 50 companies, based in market capitalization, that are not currently in the Nasdaq-100 Index Why QQQN? ▪ Provides a cost-effective opportunity to invest in the next generation of innovators ▪ Offers diversification into forward-thinking, disruptive companies beyond the established, mega-cap and large-cap leaders in the Nasdaq-100 Index SECTOR WEIGHTING (%) QQQN ▪ Deploys the proven methodology behind the time-tested Nasdaq-100 Index, n Communication Services 17.78 with its emphasis on innovation and growth n Consumer Discretionary 18.06 n Consumer Staples — n Energy — n Financials — n Health Care 14.18 ABOUT VICTORYSHARES n Industrials 9.06 n Information Technology 40.69 VictoryShares is a specialist ETF provider that n Materials — offers a broad range of rules-based and active n Real Estate — ETF solutions.