Hierarchical Fish Species Detection in Real-Time Video Using YOLO
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fishmonger Practice Display and Merchandising
Fishmonger Practice DISPLAY AND MERCHANDISING Draft Materials This is a typescript from the 1989 Training Manual developed by Seafish. The manual will be updated later in 2018, and until then this typescript will be made available to potential users. The contents of this file remain the intellectual property of the Sae Fish Industry Authority. General Objective: On completion of this training programme trainees will be able to apply basic display and merchandising principles in order to create effective displays of fish and fish products. Session Outline Session Title Time Indicator 1. Scope and purpose of display 1.0 hour 2. Display communication 1.0 hour 3. Product display properties 2.0 hours 4. Display equipment and accessories 3.5 hours 5. Product arrangement 5.0 hours 6. Display maintenance 1.5 hours Total Time Indicator 14.0 hours Contents Page TRAINER’S GUIDE Benefits of systematic training 1 Guide to the manual 2 How to design a training session 7 Setting objectives 9 Use of questions in training 10 Correction coaching 12 SESSION OUTLINES 1. Scope and purpose of display 14 Information sheets 23 2. Display communication 41 Information sheets 49 3. Product display properties 68 Information sheets 87 4. Display equipment and accessories 117 Information sheets 186 5. Product arrangement 224 Information sheets 255 6. Display maintenance 304 Information sheets 331 VISUAL AIDS ADDITIONAL TRAINING RESOURCES 338 Benefits of systematic training This instructor’s manual has been designed to assist the on-the-job training of staff employed in fish retail establishments. Below are listed some of the benefits which can be obtained by following a programme of systematic training. -

Fish Bulletin 161. California Marine Fish Landings for 1972 and Designated Common Names of Certain Marine Organisms of California
UC San Diego Fish Bulletin Title Fish Bulletin 161. California Marine Fish Landings For 1972 and Designated Common Names of Certain Marine Organisms of California Permalink https://escholarship.org/uc/item/93g734v0 Authors Pinkas, Leo Gates, Doyle E Frey, Herbert W Publication Date 1974 eScholarship.org Powered by the California Digital Library University of California STATE OF CALIFORNIA THE RESOURCES AGENCY OF CALIFORNIA DEPARTMENT OF FISH AND GAME FISH BULLETIN 161 California Marine Fish Landings For 1972 and Designated Common Names of Certain Marine Organisms of California By Leo Pinkas Marine Resources Region and By Doyle E. Gates and Herbert W. Frey > Marine Resources Region 1974 1 Figure 1. Geographical areas used to summarize California Fisheries statistics. 2 3 1. CALIFORNIA MARINE FISH LANDINGS FOR 1972 LEO PINKAS Marine Resources Region 1.1. INTRODUCTION The protection, propagation, and wise utilization of California's living marine resources (established as common property by statute, Section 1600, Fish and Game Code) is dependent upon the welding of biological, environment- al, economic, and sociological factors. Fundamental to each of these factors, as well as the entire management pro- cess, are harvest records. The California Department of Fish and Game began gathering commercial fisheries land- ing data in 1916. Commercial fish catches were first published in 1929 for the years 1926 and 1927. This report, the 32nd in the landing series, is for the calendar year 1972. It summarizes commercial fishing activities in marine as well as fresh waters and includes the catches of the sportfishing partyboat fleet. Preliminary landing data are published annually in the circular series which also enumerates certain fishery products produced from the catch. -
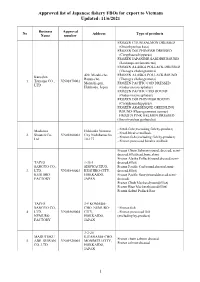
Approved List of Japanese Fishery Fbos for Export to Vietnam Updated: 11/6/2021
Approved list of Japanese fishery FBOs for export to Vietnam Updated: 11/6/2021 Business Approval No Address Type of products Name number FROZEN CHUM SALMON DRESSED (Oncorhynchus keta) FROZEN DOLPHINFISH DRESSED (Coryphaena hippurus) FROZEN JAPANESE SARDINE ROUND (Sardinops melanostictus) FROZEN ALASKA POLLACK DRESSED (Theragra chalcogramma) 420, Misaki-cho, FROZEN ALASKA POLLACK ROUND Kaneshin Rausu-cho, (Theragra chalcogramma) 1. Tsuyama CO., VN01870001 Menashi-gun, FROZEN PACIFIC COD DRESSED LTD Hokkaido, Japan (Gadus macrocephalus) FROZEN PACIFIC COD ROUND (Gadus macrocephalus) FROZEN DOLPHIN FISH ROUND (Coryphaena hippurus) FROZEN ARABESQUE GREENLING ROUND (Pleurogrammus azonus) FROZEN PINK SALMON DRESSED (Oncorhynchus gorbuscha) - Fresh fish (excluding fish by-product) Maekawa Hokkaido Nemuro - Fresh bivalve mollusk. 2. Shouten Co., VN01860002 City Nishihamacho - Frozen fish (excluding fish by-product) Ltd 10-177 - Frozen processed bivalve mollusk Frozen Chum Salmon (round, dressed, semi- dressed,fillet,head,bone,skin) Frozen Alaska Pollack(round,dressed,semi- TAIYO 1-35-1 dressed,fillet) SANGYO CO., SHOWACHUO, Frozen Pacific Cod(round,dressed,semi- 3. LTD. VN01840003 KUSHIRO-CITY, dressed,fillet) KUSHIRO HOKKAIDO, Frozen Pacific Saury(round,dressed,semi- FACTORY JAPAN dressed) Frozen Chub Mackerel(round,fillet) Frozen Blue Mackerel(round,fillet) Frozen Salted Pollack Roe TAIYO 3-9 KOMABA- SANGYO CO., CHO, NEMURO- - Frozen fish 4. LTD. VN01860004 CITY, - Frozen processed fish NEMURO HOKKAIDO, (excluding by-product) FACTORY JAPAN -

Distribution and Habits of Marine Fish and Invertebrates in Katlian Bay
Alaska Fisheries Science Center National Marine Fisheries Service U.S DEPARTMENT OF COMMERCE AFSC PROCESSED REPORT 2006-04 Distribution and Habitats of Marine Fish and Invertebrates in Katlian Bay, Southeastern Alaska, 1967 and 1968 February 2006 This report does not constitute a publication and is for information only. All data herein are to be considered provisional. DISTRIBUTION AND HABITATS OF MARINE FISH AND INVERTEBRATES IN KATLIAN BAY, SOUTHEASTERN ALASKA, 1967 AND 1968. By Richard E. Haight, Gerald M. Reid, and Noele Weemes Auke Bay Laboratory Alaska Fisheries Science Center National Marine Fisheries Service National Oceanic and Atmospheric Administration 11305 Glacier Highway Juneau, Alaska 99801-8626 February 2006 iii ABSTRACT In 1967 and 1968, scientists from the National Marine Fisheries Service’s Auke Bay Laboratory carried out four surveys of marine fauna in Katlian Bay, near Sitka, Alaska as part of an impact study associated with plans to build a wood pulp processing plant in the bay. Here we report the results of our surveys and also provide a broad literature review on several of the species that were captured in the bay. Fifty-nine fish species and more than 44 invertebrate species (32 identified to species level (see page 8) were captured. Habitats examined were intertidal, the steep sides of the bay, and the bay’s deep central basin. Many species occupied a single habitat type but others overlapped into adjacent habitats. Five fish species were collected in the intertidal zone and major invertebrate fauna included the sunflower star (Pycnopodia helianthoides) and numerous members of Gastropoda. Thirty-nine fish and 23 invertebrate species were collected on the bay’s sides below 5 m. -

Electronic Supplementary Material
Electronic supplementary material Trenkel et al. Portfolio composition not width reduces annual variability of fisheries economic returns and energy ratios. Table S1. Functional group membership and energetic content. NA not available. The "scaling method" consists of scaling the energy content E (kilo Calories) of a fillet found in Dorosz (1992) to whole fish live weight (kilo Joules) by multiplying with 6.7*E. English name Latin name Functional group Energy (kJ Data source/Method per kg live weight) Small sandeel Ammodytes tobianus Benthivore 5800 Spitz et al 2010 Imperial scaldfish Arnoglossus Benthivore 5400 Spitz et al 2010 imperialis Red gurnard Aspitrigla cuculus Benthivore 8200 Spitz et al 2010 Triggerfishes, Balistidae Benthivore 6900 Spondyliosoma cantharus durgons nei Spitz et al 2010 Bogue Boops boops Benthivore 8000 Spitz et al 2010 Dragonet Callionymus lyra Benthivore 5200 Spitz et al 2010 Boarfish Capros aper Benthivore 6200 Spitz et al 2010 Red band fish Cepola Benthivore 3900 Spitz et al 2010 macrophthalma Streaked gurnard Chelidonichthys Benthivore 8200 Chelidonichthys cuculus lastoviza Spitz et al 2010 Longfin gurnard Chelidonichthys Benthivore 8200 Chelidonichthys cuculus obscurus Spitz et al 2010 Wedge sole Dicologlossa cuneata Benthivore 6500 Spitz et al 2010 Grey gurnard Eutrigla gurnardus Benthivore 8200 Chelidonichthys cuculus Spitz et al 2010 Silvery pout Gadiculus argenteus Benthivore 5000 Spitz et al 2010 Witch flounder Glyptocephalus Benthivore 5600 Spitz et al 2010 cynoglossus Blackbelly rose fish Helicolenus Benthivore 9200 Spitz et al 2010 dactylopterus Amer. plaice(=Long Hippoglossoides Benthivore 6100 Lepidorhombus whiffiagonis rough dab) platessoides Spitz et al 2010 Ballan wrasse Labrus bergylta Benthivore 5400 Spitz et al 2010 Common dab Limanda limanda Benthivore 5800 Pleuronectes platessa Spitz et al. -

Species Composition, Distribution and Ecology of the Demersal Fish Community Along the Norwegian Coast North of Stad Under Varying Environmental Conditions
Species composition, distribution and ecology of the demersal fish community along the Norwegian coast north of Stad under varying environmental conditions Kristina Dypvik Skants University of Bergen Department of Biological Sciences - Marine Biology The Institute of Marine Research 1 Species composition, distribution and ecology of the demersal fish community along the Norwegian coast north of Stad under varying environmental conditions Kristina Dypvik Skants – Master thesis (M.Sc.) June 2019 Supervisor: |Anne Gro Vea Salvanes University of Bergen, Norway Co-supervisors: Arved Staby Institute of Marine Research, Bergen, Norway Sigbjørn Mehl Institute of Marine Research, Bergen, Norway 2 Acknowledgements First and foremost I want to thank my wonderful supervisors for all their time and commitment in helping me with this thesis. I would like to thank Anne Gro Vea Salvanes for her helpful comments and in making sure I commit to the deadlines set during the last semester of writing. Thank you to Arved Staby for all the help with the data, the (almost) monthly meetings at IMR and for always reviewing all the results I’ve sent (no matter how unfinished they’ve been). Thank you to Sigbjørn Mehl for valuable insight in the survey- design and for detailed feedback on drafts sent to you during this spring. Also, a thank you to Mikko Heino for great comments on the materials and methods and on the last draft. I would also like to thank IMR and their demersal fish research-group for the data provided for this thesis, and to the people on Johan Hjort for allowing me to join in on their annual coastal-survey in October 2018, providing me with great insight in methods used. -

Biodiversity Defrosted : Unveiling Non-Compliant Fish Trade In
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of Salford Institutional Repository Biodiversity defrosted : unveiling non-compliant fish trade in ethnic food stores Di Muri, C, Vandamme, SG, Peace, C, Barnes, W and Mariani, S http://dx.doi.org/10.1016/j.biocon.2017.11.028 Titl e Biodiversity defrosted : unveiling non-compliant fish trade in ethnic food stores Aut h or s Di Muri, C, Vandamme, SG, Peace, C, Barnes, W and M a ria ni, S Typ e Article URL This version is available at: http://usir.salford.ac.uk/id/eprint/44929/ Published Date 2 0 1 8 USIR is a digital collection of the research output of the University of Salford. Where copyright permits, full text material held in the repository is made freely available online and can be read, downloaded and copied for non- commercial private study or research purposes. Please check the manuscript for any further copyright restrictions. For more information, including our policy and submission procedure, please contact the Repository Team at: [email protected] . 1 Revised article 2 Biodiversity defrosted: unveiling non-compliant fish trade in ethnic food 3 stores 4 Cristina Di Muri1,2, Sara Vandamme* 1,3, Ciara Peace1, William Barnes1 & Stefano Mariani1 5 1School of Environment & Life Sciences, University of Salford, Greater Manchester, UK 6 2School of Environmental Sciences, University of Hull, Hull, UK 7 3North Western Waters Advisory Council NWWAC, Dublin, Ireland 8 Corresponding authors: 9 Cristina Di Muri 10 Email address: [email protected] 11 Postal address: School of Biological, Biomedical & Environmental Sciences, 3rd floor, Hardy 12 Building, University of Hull, Cottingham Road, HU6 7RX 13 Stefano Mariani 14 Email address: [email protected] 15 Postal address: School of Environment and Life Sciences, Peel Building, University of Salford, 16 Manchester, M5 4WT 17 Abstract 18 Out of nearly 30,000 teleosts dwelling in our planet’s water bodies, only hundreds of them are 19 commercially exploited and prevail on the global food market. -

Habitat and Fauna of Deep-Water Lophelia Pertusa Coral Reefs Off the Southeastern U.S.: Blake Plateau, Straits of Florida, and Gulf of Mexico
BULLETIN OF MARINE SCIENCE, 78(2): 343–375, 2006 CORAL REEF PAPER Habitat anD Fauna of Deep-Water LOPHELIA PERTUSA CORAL Reefs off the Southeastern U.S.: BlaKE Plateau, Straits of FloriDA, anD Gulf of MEXico John K. Reed, Doug C. Weaver, and Shirley A. Pomponi Abstract Expeditions from 1999 to 2004 for biomedical research explored various deep-sea coral ecosystems (DSCE) off the southeastern U.S. (Blake Plateau, Straits of Florida, and eastern Gulf of Mexico). Habitat and benthos were documented from 57 dives with human occupied submersibles and three with a remotely operated vehicle (ROV), and resulted in ~100 hrs of videotapes, 259 in situ digital images, 621 muse- um specimens, and > 400 microbial isolates. These were the first dives to document the habitat, benthic fauna, and fish diversity of some of these poorly known deep- water reefs. Fifty-eight fish species and 142 benthic invertebrate taxa were identi- fied. High-definition topographic SEABEAM maps and echosounder profiles were also produced. Sites included in this report range from South Carolina on the Blake Plateau to the southwestern Florida slope: 1) Stetson Lophelia reefs along the east- ern Blake Plateau off South Carolina; 2) Savannah Lophelia lithoherms along the western Blake Plateau off Georgia; 3) east Florida Lophelia reefs, 4) Miami Terrace escarpment in the Straits of Florida; 5) Pourtalès Terrace off the Florida Keys; and 6) west Florida Lophelia lithoherms off the southwestern Florida shelf in the Gulf of Mexico. These are contrasted with the azooxanthellate deep-water Oculina reefs at the shelf-edge off central eastern Florida. -

Supplementary Materials Towards the Introduction of Sustainable Fishery Products
Supplementary Materials Towards the Introduction of Sustainable Fishery Products: The Bid of a Major Italian Retailer Sara Bonanomi1*, Alessandro Colombelli1, Loretta Malvarosa2, Maria Cozzolino2, Antonello Sala1 Affiliations: 1 Italian National Research Council (CNR), Institute of Marine Sciences (ISMAR), Largo Fiera della Pesca 1, 60125 Ancona, Italy 2 NISEA – Fisheries and Aquaculture Economic Research, Via Irno 11, 84135, Salerno, Italy * Corresponding author: Sara Bonanomi Italian National Research Council (CNR) – Institute of Marine Sciences (ISMAR), Largo Fiera della Pesca 1, 60125 Ancona, Italy Email: [email protected], Tel: +39 071 2078830 This PDF file includes: Table S1 Table S1. Fish and seafood products sold by Carrefour Italy listed according to FAO Major Fishing Area, gear type used, and IUCN conservation status and stock status. Species FAO area Gear* IUCN status Stock status Source White sturgeon 2, 5, 61, 67, 77 FIX, GEN, LX, SX, Least Concern Native populations are declining [1-4]. TX (Critically due to a continue extirpation, Acipenser transmontanus Endangered: habitat change and dam Nechako River construction. and Columbia River populations; Endangered: Kootenai River and Upper Fraser River populations; Vulnerable: Fraser population) Queen scallop 27, 34, 37 DRX, TX Not Evaluated Declining in UK. However, [5-8]. management measures such as Aequipecten opercularis seasonal fishing closure has been implemented. Thorny skate 18, 21, 27, 31, LX, SX, TX Vulnerable Often taken as bycatch in trawl [9-12]. 47 fisheries. In the northeast Amblyraja radiata Atlantic region is assessed as Least Concern. Overexploited in the North East of USA. Marbled octopus 51, 57, 61, 71 FIX, LX Not Evaluated Apparently no stock assessment [13-15]. -

Product: 55 - Food - Animal Products and Poultry Products, Beef Bos Sp Recommended Scientific Name Bos Taurus Manufacturers of This Product Antigen Laboratories, Inc
Product: 55 - Food - Animal Products and Poultry Products, Beef Bos sp Recommended Scientific Name Bos taurus Manufacturers of this Product Antigen Laboratories, Inc. - Liberty, MO (Lic. No. 468, STN No. 102223) Greer Laboratories, Inc. - Lenoir, NC (Lic. No. 308, STN No. 101833) Hollister-Stier Labs, LLC - Spokane, WA (Lic. No. 1272, STN No. 103888) ALK-Abello Inc. - Port Washington, NY (Lic. No. 1256, STN No. 103753) Allermed Laboratories, Inc. - San Diego, CA (Lic. No. 467, STN No. 102211) Nelco Laboratories, Inc. - Deer Park, NY (Lic. No. 459, STN No. 102192) Allergy Laboratories, Inc. - Oklahoma City, OK (Lic. No. 103, STN No. 101376) Search Strategy PubMed: Beef allergen; Beef allergy; Beef immunotherapy Google: beef extract; beef extract adverse Nomenclature According to ITIS, there are five species within the genus of Bos. The domestic cow is Bos taurus. According to dictionary.com beef is the correct common name for a processed cow. The Bos genus is found within the Bovinae subfamily and Bovidae family. Parent Product 55 - Food - Animal Products and Poultry Products, Beef Bos sp Published Data There are three papers that use beef extract in skin prick tests to diagnose beef allergy. One clinical study (PubMed ID: 12487201) of 34 patients suggests that both commercial and fresh beef extracts are effective in diagnosing beef allergy. Another clinical study (PubMed ID: 12622743) of 12 patients claims that skin prick tests do not accurately diagnose beef allergy. These two studies used commercial beef extracts from two different companies, which might explain the difference in the study outcomes. Fiocchi (PubMed ID: 12487201) noted that the processing method could influence the extract composition and presentation. -

Site Survey at Alve NE NCS 6607/12 and 6608/10, PL127C ABP19307
FUGRO Site Survey at Alve NE NCS 6607/12 and 6608/10, PL127C ABP19307 Survey Period: 27 September to 6 October 2019 Fugro Report No.: 133392.V01 AkerBP ASA Volume 3 of 3: Environmental Habitat Report Draft Issue Fugro Document No. 133392.V01 Page 1 of 36 FUGRO Site Survey at Alve NE NCS 6607/12 and 6608/10, PL127C ABP19307 Survey Period: 27 September to 6 October 2019 Fugro Report No.: 133392.V01 Volume 3 of 3: Environmental Habitat Report Draft Issue Draft Issue Prepared by: Fugro GB Marine Limited Trafalgar Wharf, Unit 16, Hamilton Road Portchester, Portsmouth, PO6 4PX United Kingdom T +44 (0)2392 205 500 www.fugro.com Prepared for: AkerBP ASA Jåttåvågveien 10 Hinna Park 4020 Stavanger Norway Client Reference No.: ABP19307 01 Draft Issue R. Cox J. Lusted J. Lusted 22 November 2019 Issue Document Status Prepared Checked Approved Date Fugro GB Marine Limited. Registered in England No. 1135456. VAT No. GB 579 3459 84 A member of the Fugro Group of Companies with offices throughout the world Fugro Document No. 133392.V01 AKERBP ASA SITE SURVEY AT ALVE NE, NCS 6607/12 AND 6608/10, ABP19307 FRONTISPIECE Fugro Report No. 133392.V01 Page i of vi AKERBP ASA SITE SURVEY AT ALVE NE, NCS 6607/12 AND 6608/10, ABP19307 EXECUTIVE SUMMARY Introduction On the instruction of AkerBP ASA, Fugro performed an environmental site survey at the Alve NE survey area in Norwegian Continental Shelf (NCS) Blocks 6607/12 and 6608/10 located in the Norwegian Sea. Table S.1 defines the surface coordinates of the Alve NE proposed well locations. -
Annotated Bibliography of the Genus Sebastes (Family Scorpaenidae)
') February 23, 1988 Annotated Bibliography of the Genus Sebastes (Family Scorpaenidae). by Maureen H. Leet and Carol A. Reilly National Marine Fisheries Service Southwest Fisheries Center Tiburon Laboratory 3150 Paradise Drive ) Tiburon, California 94920 NOG.A lIRRI.RY E/OC43 md~ 3 7c~"" :,nr: i",l:n: 'N?!y NE St,~i':J v;;.. 9ali5 ) Preface ) This bibliography consists of 1,258 references on members of the genus Sebastes (family scorpaenidae). It contains published material on the taxonomy, distribution, abundance, life history, fisheries management, and ecology of North Atlantic redfishes and Pacific rockfishes. References on the technical aspects of the fishery and fish processing industry in regards to Sebastes are ) also included because of the commercial value of redfish and rockfish. In addition, administrative reports, stock assessment reports, doctoral dissertations, and master's thesis are included. Materials dating from the eighteenth century to the end of 1987 are cited. The bibliography is based on records which have been downloaded from literature searches done on a variety of online databases including Aquatic Sciences and Fisheries Abstracts, NTIS, and BIOSIS. References were gathered from sources such as Canada's Fisheries and Oceans, Waves database, Northwest and Alaska Fisheries Center, NWAFC Technical Memorandums and Processed Reports, and G. I. McT Cowan's Author-Subject Index to Fisheries Research Board of Canada Translation Series. World Bibliography of Redfishes and Rockfishes (Sebastinae, scorpaenidae) by D. Clay and T. J. Kenchington, 1986 was the most comprehensive source encountered. English translations of articles appearing in a foreign language are cited in the bibliography whenever possible. Titles of references in foreign languages appear translated into English.