Supp Material.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Approach to Identify Risk Factors for Therapy-Related Myeloid Leukemia
Leukemia (2006) 20, 239–246 & 2006 Nature Publishing Group All rights reserved 0887-6924/06 $30.00 www.nature.com/leu ORIGINAL ARTICLE Genome-wide approach to identify risk factors for therapy-related myeloid leukemia A Bogni1, C Cheng2, W Liu2, W Yang1, J Pfeffer1, S Mukatira3, D French1, JR Downing4, C-H Pui4,5,6 and MV Relling1,6 1Department of Pharmaceutical Sciences, The University of Tennessee, Memphis, TN, USA; 2Department of Biostatistics, The University of Tennessee, Memphis, TN, USA; 3Hartwell Center, The University of Tennessee, Memphis, TN, USA; 4Department of Pathology, The University of Tennessee, Memphis, TN, USA; 5Department of Hematology/Oncology St Jude Children’s Research Hospital, The University of Tennessee, Memphis, TN, USA; and 6Colleges of Medicine and Pharmacy, The University of Tennessee, Memphis, TN, USA Using a target gene approach, only a few host genetic risk therapy increases, the importance of identifying host factors for factors for treatment-related myeloid leukemia (t-ML) have been secondary neoplasms increases. defined. Gene expression microarrays allow for a more 4 genome-wide approach to assess possible genetic risk factors Because DNA microarrays interrogate multiple ( 10 000) for t-ML. We assessed gene expression profiles (n ¼ 12 625 genes in one experiment, they allow for a ‘genome-wide’ probe sets) in diagnostic acute lymphoblastic leukemic cells assessment of genes that may predispose to leukemogenesis. from 228 children treated on protocols that included leukemo- DNA microarray analysis of gene expression has been used to genic agents such as etoposide, 13 of whom developed t-ML. identify distinct expression profiles that are characteristic of Expression of 68 probes, corresponding to 63 genes, was different leukemia subtypes.13,14 Studies using this method have significantly related to risk of t-ML. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

The Middle Temporal Gyrus Is Transcriptionally Altered in Patients with Alzheimer’S Disease
1 The middle temporal gyrus is transcriptionally altered in patients with Alzheimer’s Disease. 2 1 3 Shahan Mamoor 1Thomas Jefferson School of Law 4 East Islip, NY 11730 [email protected] 5 6 We sought to understand, at the systems level and in an unbiased fashion, how gene 7 expression was most different in the brains of patients with Alzheimer’s Disease (AD) by mining published microarray datasets (1, 2). Comparing global gene expression profiles between 8 patient and control revealed that a set of 84 genes were expressed at significantly different levels in the middle temporal gyrus (MTG) of patients with Alzheimer’s Disease (1, 2). We used 9 computational analyses to classify these genes into known pathways and existing gene sets, 10 and to describe the major differences in the epigenetic marks at the genomic loci of these genes. While a portion of these genes is computationally cognizable as part of a set of genes 11 up-regulated in the brains of patients with AD (3), many other genes in the gene set identified here have not previously been studied in association with AD. Transcriptional repression, both 12 pre- and post-transcription appears to be affected; nearly 40% of these genes are transcriptional 13 targets of MicroRNA-19A/B (miR-19A/B), the zinc finger protein 10 (ZNF10), or of the AP-1 repressor jun dimerization protein 2 (JDP2). 14 15 16 17 18 19 20 21 22 23 24 25 26 Keywords: Alzheimer’s Disease, systems biology of Alzheimer’s Disease, differential gene 27 expression, middle temporal gyrus. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Bioinformatic Evaluation of Transcriptional Regulation of WNT Pathway Genes with Reference to Diabetic Nephropathy
Bioinformatic evaluation of transcriptional regulation of WNT pathway genes with reference to diabetic nephropathy McKay, G. J., Kavanagh, D. H., Crean, J. K., & Maxwell, A. P. (2015). Bioinformatic evaluation of transcriptional regulation of WNT pathway genes with reference to diabetic nephropathy. Journal of Diabetes Research, [608691]. https://doi.org/10.1155/2016/7684038 Published in: Journal of Diabetes Research Document Version: Publisher's PDF, also known as Version of record Queen's University Belfast - Research Portal: Link to publication record in Queen's University Belfast Research Portal Publisher rights Copyright © 2015 Gareth J. McKay et al.This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. General rights Copyright for the publications made accessible via the Queen's University Belfast Research Portal is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy The Research Portal is Queen's institutional repository that provides access to Queen's research output. Every effort has been made to ensure that content in the Research Portal does not infringe any person's rights, or applicable UK laws. If you discover content in the Research Portal that you believe breaches copyright or violates any law, please contact [email protected]. Download date:27. Sep. 2021 Hindawi Publishing Corporation Journal of Diabetes Research Article ID 608691 Research Article Bioinformatic Evaluation of Transcriptional Regulation of WNT Pathway Genes with reference to Diabetic Nephropathy Gareth J. -
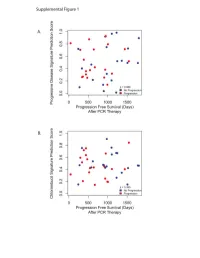
Supplementary Data
Progressive Disease Signature Upregulated probes with progressive disease U133Plus2 ID Gene Symbol Gene Name 239673_at NR3C2 nuclear receptor subfamily 3, group C, member 2 228994_at CCDC24 coiled-coil domain containing 24 1562245_a_at ZNF578 zinc finger protein 578 234224_at PTPRG protein tyrosine phosphatase, receptor type, G 219173_at NA NA 218613_at PSD3 pleckstrin and Sec7 domain containing 3 236167_at TNS3 tensin 3 1562244_at ZNF578 zinc finger protein 578 221909_at RNFT2 ring finger protein, transmembrane 2 1552732_at ABRA actin-binding Rho activating protein 59375_at MYO15B myosin XVB pseudogene 203633_at CPT1A carnitine palmitoyltransferase 1A (liver) 1563120_at NA NA 1560098_at AKR1C2 aldo-keto reductase family 1, member C2 (dihydrodiol dehydrogenase 2; bile acid binding pro 238576_at NA NA 202283_at SERPINF1 serpin peptidase inhibitor, clade F (alpha-2 antiplasmin, pigment epithelium derived factor), m 214248_s_at TRIM2 tripartite motif-containing 2 204766_s_at NUDT1 nudix (nucleoside diphosphate linked moiety X)-type motif 1 242308_at MCOLN3 mucolipin 3 1569154_a_at NA NA 228171_s_at PLEKHG4 pleckstrin homology domain containing, family G (with RhoGef domain) member 4 1552587_at CNBD1 cyclic nucleotide binding domain containing 1 220705_s_at ADAMTS7 ADAM metallopeptidase with thrombospondin type 1 motif, 7 232332_at RP13-347D8.3 KIAA1210 protein 1553618_at TRIM43 tripartite motif-containing 43 209369_at ANXA3 annexin A3 243143_at FAM24A family with sequence similarity 24, member A 234742_at SIRPG signal-regulatory protein gamma -

Research Article Mouse Model Resources for Vision Research
Hindawi Publishing Corporation Journal of Ophthalmology Volume 2011, Article ID 391384, 12 pages doi:10.1155/2011/391384 Research Article Mouse Model Resources for Vision Research Jungyeon Won, Lan Ying Shi, Wanda Hicks, Jieping Wang, Ronald Hurd, Jurgen¨ K. Naggert, Bo Chang, and Patsy M. Nishina The Jackson Laboratory, 600 Main Street, Bar Harbor, ME 04609, USA Correspondence should be addressed to Patsy M. Nishina, [email protected] Received 1 July 2010; Accepted 21 September 2010 Academic Editor: Radha Ayyagari Copyright © 2011 Jungyeon Won et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. The need for mouse models, with their well-developed genetics and similarity to human physiology and anatomy, is clear and their central role in furthering our understanding of human disease is readily apparent in the literature. Mice carrying mutations that alter developmental pathways or cellular function provide model systems for analyzing defects in comparable human disorders and for testing therapeutic strategies. Mutant mice also provide reproducible, experimental systems for elucidating pathways of normal development and function. Two programs, the Eye Mutant Resource and the Translational Vision Research Models, focused on providing such models to the vision research community are described herein. Over 100 mutant lines from the Eye Mutant Resource and 60 mutant lines from the Translational Vision Research Models have been developed. The ocular diseases of the mutant lines include a wide range of phenotypes, including cataracts, retinal dysplasia and degeneration, and abnormal blood vessel formation. -

ARCIVES Genome Sequencing Technology: Improvement of the Electrophoretic Sequencing Process and Analysis of the Sequencing Tool Industry by Kazunori Maruyama Ph.D
Genome Sequencing Technology: Improvement of the Electrophoretic Sequencing Process and Analysis of the Sequencing Tool Industry by Kazunori Maruyama Ph.D. in Material Science, Mie University (2001) M.S. in Macromolecular Science, Osaka University (1993) Submitted to the Alfred P. Sloan School of Management and the Department of Chemical Engineering in Partial Fulfillment of the Requirements for the Degrees of Master of BusinessAdministration and Master of Science in Chemical Engineering In Conjunction with the Leaders for Manufacturing Program at the MASSACHUSETTSINSUE Massachusetts Institute of Technology OF TECHNOLOY June 2005 JUN 01 2005 02005 Massachusetts Institute of Technology. All rights reserved. LIBRARIES Signature of Author Alfred P. Sloan School of Management Department of Chemical Engineering May 6, 2005 Certified by -- Roy E. Welsch Professor of Statistics and Management Science Thesis Advisor Certified by r Patrick S. Doyle Assistant-Professor of Chemical Engineering Thesis Advisor Accepted by · - Margaret Andrews Alfred P. Sloan School of Management Executive Director of Masters Program Accepted by - - Daniel Blankschtein Department of Chemical Engineering Graduate Committee Chairman .ARCIVES Genome Sequencing Technology: Improvement of the Electrophoretic Sequencing Process and Analysis of the Sequencing Tool Industry by Kazunori Maruyama Ph.D. in Material Science, Mie University (2001) M.S. in Macromolecular Science, Osaka University (1993) Submitted to the Alfred P. Sloan School of Management and the Department of Chemical Engineering in Partial Fulfillment of the Requirements for the Degrees of Master of Business Administration and Master of Science in Chemical Engineering ABSTRACT A primary bottleneck in DNA-sequencing operations is the capacity of the detection process. Although today's capillary electrophoresis DNA sequencers are faster, more sensitive, and more reliable than their precursors, high purchasing and running costs still make them a limiting factor in most laboratories like those of the Broad Institute. -

Alterations of the Pro-Survival Bcl-2 Protein Interactome in Breast Cancer
bioRxiv preprint doi: https://doi.org/10.1101/695379; this version posted July 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Alterations of the pro-survival Bcl-2 protein interactome in 2 breast cancer at the transcriptional, mutational and 3 structural level 4 5 Simon Mathis Kønig1, Vendela Rissler1, Thilde Terkelsen1, Matteo Lambrughi1, Elena 6 Papaleo1,2 * 7 1Computational Biology Laboratory, Danish Cancer Society Research Center, 8 Strandboulevarden 49, 2100, Copenhagen 9 10 2Translational Disease Systems Biology, Faculty of Health and Medical Sciences, Novo 11 Nordisk Foundation Center for Protein Research University of Copenhagen, Copenhagen, 12 Denmark 13 14 Abstract 15 16 Apoptosis is an essential defensive mechanism against tumorigenesis. Proteins of the B-cell 17 lymphoma-2 (Bcl-2) family regulates programmed cell death by the mitochondrial apoptosis 18 pathway. In response to intracellular stresses, the apoptotic balance is governed by interactions 19 of three distinct subgroups of proteins; the activator/sensitizer BH3 (Bcl-2 homology 3)-only 20 proteins, the pro-survival, and the pro-apoptotic executioner proteins. Changes in expression 21 levels, stability, and functional impairment of pro-survival proteins can lead to an imbalance 22 in tissue homeostasis. Their overexpression or hyperactivation can result in oncogenic effects. 23 Pro-survival Bcl-2 family members carry out their function by binding the BH3 short linear 24 motif of pro-apoptotic proteins in a modular way, creating a complex network of protein- 25 protein interactions. -

Cataloguing Functionally Relevant Polymorphisms in Gene DNA Ligase I: a Computational Approach
3 Biotech (2011) 1:47–56 DOI 10.1007/s13205-011-0006-8 ORIGINAL ARTICLE Cataloguing functionally relevant polymorphisms in gene DNA ligase I: a computational approach Abhishek A. Singh • Dakshinamurthy Sivakumar • Pallavi Somvanshi Received: 24 February 2011 / Accepted: 1 April 2011 / Published online: 27 April 2011 Ó The Author(s) 2011. This article is published with open access at Springerlink.com Abstract A computational approach for identifying Introduction functionally relevant SNPs in gene LIG1 has been pro- posed. LIG1 is a crucial gene which is involved in excision Single nucleotide polymorphisms, often referred as SNP, repair pathways and mutations in this gene may lead to are the most common DNA variations present throughout increase sensitivity towards DNA damaging agents. A total human genome with a frequency of one in thousand base of 792 SNPs were reported to be associated with gene pairs (Brookes 1999). SNPs present in coding region are LIG1 in dbSNP. Different web server namely SIFT, either synonymous SNP (sSNP) in which any alteration in PolyPhen, CUPSAT, FASTSNP, MAPPER and dbSMR the codon does not result in coding of different amino acid were used to identify potentially functional SNPs in gene or nonsynonymous SNP (nsSNP) where a change in codon LIG1. SIFT, PolyPhen and CUPSAT servers predicted results in coding of different amino acid. The missense eleven nsSNPs to be intolerant, thirteen nsSNP to be mutations (a category of nsSNP) are of importance because damaging and two nsSNPs have the potential to destabilize of their ability to influence protein functions and many of protein structure. The nsSNP rs11666150 was predicted to them are linked to human inheritable diseases (krawczak be damaging by all three servers and its mutant structure et al. -

The Mutational Landscape of the Oncogenic MZF1 SCAN Domain in Cancer
The Mutational Landscape of the Oncogenic MZF1 SCAN Domain in Cancer Nygaard, Mads; Terkelsen, Thilde; Vidas Olsen, André; Sora, Valentina; Salamanca Viloria, Juan; Rizza, Fabio; Bergstrand-Poulsen, Sanne; Di Marco, Miriam; Vistesen, Mette; Tiberti, Matteo; Lambrughi, Matteo; Jäättelä, Marja; Kallunki, Tuula; Papaleo, Elena Published in: Frontiers in Molecular Biosciences DOI: 10.3389/fmolb.2016.00078 Publication date: 2016 Document version Publisher's PDF, also known as Version of record Citation for published version (APA): Nygaard, M., Terkelsen, T., Vidas Olsen, A., Sora, V., Salamanca Viloria, J., Rizza, F., Bergstrand-Poulsen, S., Di Marco, M., Vistesen, M., Tiberti, M., Lambrughi, M., Jäättelä, M., Kallunki, T., & Papaleo, E. (2016). The Mutational Landscape of the Oncogenic MZF1 SCAN Domain in Cancer. Frontiers in Molecular Biosciences, 3, 1-18. [78]. https://doi.org/10.3389/fmolb.2016.00078 Download date: 27. sep.. 2021 ORIGINAL RESEARCH published: 15 December 2016 doi: 10.3389/fmolb.2016.00078 The Mutational Landscape of the Oncogenic MZF1 SCAN Domain in Cancer Mads Nygaard 1 †, Thilde Terkelsen 1 †, André Vidas Olsen 1, Valentina Sora 1, Juan Salamanca Viloria 1, Fabio Rizza 2, Sanne Bergstrand-Poulsen 1, Miriam Di Marco 1, Mette Vistesen 3, Matteo Tiberti 4, Matteo Lambrughi 1, Marja Jäättelä 5, Tuula Kallunki 5 and Elena Papaleo 1* 1 Computational Biology Laboratory and Center for Autophagy, Recycling and Disease, Danish Cancer Society Research Center, Copenhagen, Denmark, 2 Department of Biomedical Sciences, University -

The Changing Chromatome As a Driver of Disease: a Panoramic View from Different Methodologies
The changing chromatome as a driver of disease: A panoramic view from different methodologies Isabel Espejo1, Luciano Di Croce,1,2,3 and Sergi Aranda1 1. Centre for Genomic Regulation (CRG), Barcelona Institute of Science and Technology, Dr. Aiguader 88, Barcelona 08003, Spain 2. Universitat Pompeu Fabra (UPF), Barcelona, Spain 3. ICREA, Pg. Lluis Companys 23, Barcelona 08010, Spain *Corresponding authors: Luciano Di Croce ([email protected]) Sergi Aranda ([email protected]) 1 GRAPHICAL ABSTRACT Chromatin-bound proteins regulate gene expression, replicate and repair DNA, and transmit epigenetic information. Several human diseases are highly influenced by alterations in the chromatin- bound proteome. Thus, biochemical approaches for the systematic characterization of the chromatome could contribute to identifying new regulators of cellular functionality, including those that are relevant to human disorders. 2 SUMMARY Chromatin-bound proteins underlie several fundamental cellular functions, such as control of gene expression and the faithful transmission of genetic and epigenetic information. Components of the chromatin proteome (the “chromatome”) are essential in human life, and mutations in chromatin-bound proteins are frequently drivers of human diseases, such as cancer. Proteomic characterization of chromatin and de novo identification of chromatin interactors could thus reveal important and perhaps unexpected players implicated in human physiology and disease. Recently, intensive research efforts have focused on developing strategies to characterize the chromatome composition. In this review, we provide an overview of the dynamic composition of the chromatome, highlight the importance of its alterations as a driving force in human disease (and particularly in cancer), and discuss the different approaches to systematically characterize the chromatin-bound proteome in a global manner.