A Transactional Model for Automatic Exception Handling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Actors at Work Issue Date: 2016-12-15 Actors at Work Behrooz Nobakht
Cover Page The handle http://hdl.handle.net/1887/45620 holds various files of this Leiden University dissertation Author: Nobakht, Behrooz Title: Actors at work Issue Date: 2016-12-15 actors at work behrooz nobakht 2016 Leiden University Faculty of Science Leiden Institute of Advanced Computer Science Actors at Work Actors at Work Behrooz Nobakht ACTORS AT WORK PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit Leiden op gezag van de Rector Magnificus prof. dr. C. J. J. M. Stolker, volgens besluit van het College voor Promoties te verdedigen op donderdag 15 december 2016 klokke 11.15 uur door Behrooz Nobakht geboren te Tehran, Iran, in 1981 Promotion Committee Promotor: Prof. Dr. F.S. de Boer Co-promotor: Dr. C. P. T. de Gouw Other members: Prof. Dr. F. Arbab Dr. M.M. Bonsangue Prof. Dr. E. B. Johnsen University of Oslo, Norway Prof. Dr. M. Sirjani Reykjavik University, Iceland The work reported in this thesis has been carried out at the Center for Mathematics and Computer Science (CWI) in Amsterdam and Leiden Institute of Advanced Computer Science at Leiden University. This research was supported by the European FP7-231620 project ENVISAGE on Engineering Virtualized Resources. Copyright © 2016 by Behrooz Nobakht. All rights reserved. October, 2016 Behrooz Nobakht Actors at Work Actors at Work, October, 2016 ISBN: 978-94-028-0436-2 Promotor: Prof. Dr. Frank S. de Boer Cover Design: Ehsan Khakbaz <[email protected]> Built on 2016-11-02 17:00:24 +0100 from 397717ec11adfadec33e150b0264b0df83bdf37d at https://github.com/nobeh/thesis using: This is pdfTeX, Version 3.14159265-2.6-1.40.16 (TeX Live 2015/Debian) kpathsea version 6.2.1 Leiden University Leiden Institute of Advanced Computer Science Faculty of Science Niels Bohrweg 1 2333 CA and Leiden Contents I Introduction1 1 Introduction 3 1.1 Objectives and Architecture . -

Java Optimizations Using Bytecode Templates
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Java Optimizations Using Bytecode Templates Rubén Ramos Horta Mestrado Integrado em Engenharia Informática e Computação Supervisor: Professor Doutor João Manuel Paiva Cardoso July 28, 2016 c Rubén Ramos Horta, 2016 Java Optimizations Using Bytecode Templates Rubén Ramos Horta Mestrado Integrado em Engenharia Informática e Computação July 28, 2016 Resumo Aplicações móveis e embebidas funcionam em ambientes com poucos recursos e que estão sujeitos a constantes mudanças no seu contexto operacional. Estas características dificultam o desenvolvi- mento deste tipo de aplicações pois a volatilidade e as limitações de recursos levam muitas vezes a uma diminuição do rendimento e a um potencial aumento do custo computacional. Além disso, as aplicações que têm como alvo ambientes móveis e embebidos (por exemplo, Android) necessitam de adaptações e otimizações para fiabilidade, manutenção, disponibilidade, segurança, execução em tempo real, tamanho de código, eficiência de execução e também consumo de energia. Esta dissertação foca-se na otimização, em tempo de execução, de programas Java, com base na aplicação de otimizações de código baseadas na geração de bytecodes em tempo de execução, usando templates. Estes templates, fornecem geração de bytecodes usando informação apenas disponível em tempo de execução. Este artigo propõe uma estratégia para o desenvolvimento desses templates e estuda o seu impacto em diferentes plataformas. i ii Resumen Las aplicaciones móviles y embedded trabajan en entornos limitados de recursos y están sujetas a constantes cambios de escenario. Este tipo de características desafían el desarrollo de este tipo de aplicaciones en términos de volatibilidad y limitación de recursos que acostumbran a afec- tar al rendimiento y también producen un incremento significativo en el coste computacional. -

The Basics of Exception Handling
The Basics of Exception Handling MIPS uses two coprocessors: C0 and C1 for additional help. C0 primarily helps with exception handling, and C1 helps with floating point arithmetic. Each coprocessor has a few registers. Interrupts Initiated outside the instruction stream Arrive asynchronously (at no specific time), Example: o I/O device status change o I/O device error condition Traps Occur due to something in instruction stream. Examples: o Unaligned address error o Arithmetic overflow o System call MIPS coprocessor C0 has a cause register (Register 13) that contains a 4-bit code to identify the cause of an exception Cause register pending exception code interrupt Bits 15-10 Bits 5-2 [Exception Code = 0 means I/O interrupt = 12 means arithmetic overflow etc] MIPS instructions that cause overflow (or some other violation) lead to an exception, which sets the exception code. It then switches to the kernel mode (designated by a bit in the status register of C0, register 12) and transfers control to a predefined address to invoke a routine (exception handler) for handling the exception. Interrupt Enable Status register Interrupt Mask 15-8 1 0 Kernel/User (EPC = Exception Program Counter, Reg 14 of C0) Memory L: add $t0, $t1, $t2 overflow! Return address (L+4) Exception handler routine is saved in EPC Next instruction Overflow ra ! EPC; jr ra Invalid instruction ra ! EPC; jr ra System Call ra ! EPC; jr ra The Exception Handler determines the cause of the exception by looking at the exception code bits. Then it jumps to the appropriate exception handling routine. -
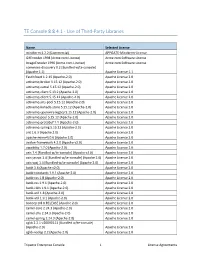
TE Console 8.8.4.1 - Use of Third-Party Libraries
TE Console 8.8.4.1 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] (Apache 1.1) Apache License 1.1 FastInfoset 1.2.15 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.12 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 apache-mime4j 0.6 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants 1.9.1 (Apache-2.0) Apache License 2.0 batik-css 1.8 (Apache-2.0) Apache License 2.0 batik-css 1.9.1 (Apache-2.0) Apache License 2.0 batik-i18n 1.9.1 (Apache-2.0) -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

A Framework for the Development of Multi-Level Reflective Applications
A Framework for the Development of Multi-Level Reflective Applications Federico Valentino, Andrés Ramos, Claudia Marcos and Jane Pryor ISISTAN Research Institute Fac. de Ciencias Exactas, UNICEN Pje. Arroyo Seco, B7001BBO Tandil, Bs. As., Argentina Tel/Fax: +54-2293-440362/3 E-mail: {fvalenti,aramos,cmarcos,jpryor}@exa.unicen.edu.ar URL: http://www.exa.unicen.edu.ar/~isistan Abstract. Computational reflection has become a useful technique for developing applications that are able to observe and modify their behaviour. Reflection has evolved to the point where it is being used to address a variety of application domains. This paper presents a reflective architecture that has been developed as a framework that provides a flexible reflective mechanism for the development of a wide range of applications. This architecture supports many meta-levels, where each one may contain one or more planes. A plane groups components that deal with the same functionality, and so enhances the separation of concerns in the system. The reflective mechanism permits different types of reflection, and also incorporates the runtime handling of potential conflicts between competing system components. The design and implementation of this framework are described, and an example illustrates its characteristics. 1. Introduction Reflective architectures provide a degree of flexibility that allows designers to adapt and add functionality to software systems in a transparent fashion. Since its onset, computational reflection has been proposed and used for the solving of many different problem domains in software engineering: aspect-oriented programming [PDF99, PBC00], multi-agent systems [Zun00], concurrency programming [WY88, MMY93], distributed systems [Str93, OI94, OIT92], and others. -

Support for Understanding and Writing Exception Handling Code
Moonstone: Support for Understanding and Writing Exception Handling Code Florian Kistner,y Mary Beth Kery,z Michael Puskas,x Steven Moore,z and Brad A. Myersz fl[email protected], [email protected], [email protected], [email protected], [email protected] y Department of Informatics, Technical University of Munich, Germany z Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, PA, USA x School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, AZ, USA Abstract—Moonstone is a new plugin for Eclipse that supports developers in understanding exception flow and in writing excep- tion handlers in Java. Understanding exception control flow is paramount for writing robust exception handlers, a task many de- velopers struggle with. To help with this understanding, we present two new kinds of information: ghost comments, which are transient overlays that reveal potential sources of exceptions directly in code, and annotated highlights of skipped code and associated handlers. To help developers write better handlers, Moonstone additionally provides project-specific recommendations, detects common bad practices, such as empty or inadequate handlers, and provides automatic resolutions, introducing programmers to advanced Java exception handling features, such as try-with- resources. We present findings from two formative studies that informed the design of Moonstone. We then show with a user study that Moonstone improves users’ understanding in certain Fig. 1. Overview of Moonstone’s features. areas and enables developers to amend exception handling code more quickly and correctly. it difficult to assess the behavior of the software system [1]. While novices particularly struggle with exception handling I. -

Programming with Exceptions in Jcilk$
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Science of Computer Programming 63 (2006) 147–171 www.elsevier.com/locate/scico Programming with exceptions in JCilk$ John S. Danaher, I.-Ting Angelina Lee∗, Charles E. Leiserson Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA 02139, USA Received 29 December 2005; received in revised form 7 May 2006; accepted 18 May 2006 Available online 25 September 2006 Abstract JCilk extends the serial subset of the Java language by importing the fork-join primitives spawn and sync from the Cilk multithreaded language, thereby providing call-return semantics for multithreaded subcomputations. In addition, JCilk transparently integrates Java’s exception handling with multithreading by extending the semantics of Java’s try and catch constructs, but without adding new keywords. This extension is “faithful” in that it obeys Java’s ordinary serial semantics when executed on a single processor. When executed in parallel, however, an exception thrown by a JCilk computation causes its sibling computations to abort, which yields a clean semantics in which the enclosing cilk try block need only handle a single exception. The exception semantics of JCilk allows programs with speculative computations to be programmed easily. Speculation is essential in order to parallelize programs such as branch-and-bound or heuristic search. We show how JCilk’s linguistic mechanisms can be used to program the “queens” puzzle and a parallel alpha–beta search. We have implemented JCilk’s semantic model in a prototype compiler and runtime system, called JCilk-1. -

CS 6110 S11 Lecture 15 Exceptions and First-Class Continuations 26 February 2010
CS 6110 S11 Lecture 15 Exceptions and First-Class Continuations 26 February 2010 1 CPS and Strong Typing Now let us use CPS semantics to augment our previously defined FL language translation so that it supports runtime type checking. This time our translated expressions will be functions of ρ and k denoting an environment and a continuation, respectively. The term E[[e]]ρk represents a program that evaluates e in the environment ρ and sends the resulting value to the continuation k. As before, assume that we have an encoding of variable names x and a representation of environments ρ along with lookup and update functions lookup ρ x and update ρ x v. In addition, we want to catch type errors that may occur during evaluation. As before, we use integer tags to keep track of types: 4 4 4 Err = 0 Null = 1 Bool = 2 4 4 4 Num = 3 Tuple = 4 Func = 5 A tagged value is a value paired with its type tag; for example, (0; true). Using these tagged values, we can now define a translation that incorporates runtime type checking: 4 E[[x]]ρk = k (lookup ρ x) 4 E[[b]]ρk = k (Bool; b) 4 E[[n]]ρk = k (Num; n) 4 E[[nil]]ρk = k (Null; 0) 4 E[[(e1; : : : ; en)]]ρk = E[[e1 ]]ρ(λv1 :::: E[[e2 ]]ρ(λv2 :::: [[E ]]en ρ(λvn : k (Tuple; n; (v1; : : : ; vn))))) 4 E[[let x = e1 in e2 ]]ρk = E[[e1 ]]ρ(λp: E[[e2 ]] (update ρ x p) k) 4 E[[λx: e]]ρk = k (Func; λxk: E[[e]](update ρ x x)k) 4 E[[error]]ρk = k (Err; error): Now a function application can check that it is actually applying a function: 4 E[[e0 e1 ]]ρk = E[[e0 ]]ρ(λp: let (t; f) = p in if t =6 Func then error else E[[e1 ]]ρ(λv: fvk)) We can simplify this by defining a helper function check-fn: 4 check-fn = λkp: let (t; f) = p in if t =6 Func then error else kf: The helper function takes in a continuation and a tagged value, checks the type, strips off the tag, and passes the raw (untagged) value to the continuation. -

Semantic Fuzzing with Zest
Semantic Fuzzing with Zest Rohan Padhye Caroline Lemieux Koushik Sen University of California, Berkeley University of California, Berkeley University of California, Berkeley USA USA USA [email protected] [email protected] [email protected] Mike Papadakis Yves Le Traon University of Luxembourg University of Luxembourg Luxembourg Luxembourg [email protected] [email protected] ABSTRACT Syntactic Semantic Valid Input Output Programs expecting structured inputs often consist of both a syntac- Stage Stage tic analysis stage, which parses raw input, and a semantic analysis Syntactically Semantically stage, which conducts checks on the parsed input and executes Invalid Invalid the core logic of the program. Generator-based testing tools in the Syntactic Semantic lineage of QuickCheck are a promising way to generate random Error Error syntactically valid test inputs for these programs. We present Zest, a technique which automatically guides QuickCheck-like random- input generators to better explore the semantic analysis stage of test Figure 1: Inputs to a program taking structured inputs can programs. Zest converts random-input generators into determinis- be either syntactically or semantically invalid or just valid. tic parametric generators. We present the key insight that mutations in the untyped parameter domain map to structural mutations in the input domain. Zest leverages program feedback in the form 1 INTRODUCTION of code coverage and input validity to perform feedback-directed parameter search. We evaluate Zest against AFL and QuickCheck Programs expecting complex structured inputs often process their on five Java programs: Maven, Ant, BCEL, Closure, and Rhino. Zest inputs and convert them into suitable data structures before in- covers 1:03×–2:81× as many branches within the benchmarks’ se- voking the actual functionality of the program. -

Funktionaalisten Kielten Ydinpiirteiden Toteutus Oliokielten Virtuaalikonealustoilla
Funktionaalisten kielten ydinpiirteiden toteutus oliokielten virtuaalikonealustoilla Laura Leppänen Pro gradu -tutkielma HELSINGIN YLIOPISTO Tietojenkäsittelytieteen laitos Helsinki, 30. lokakuuta 2016 HELSINGIN YLIOPISTO — HELSINGFORS UNIVERSITET — UNIVERSITY OF HELSINKI Tiedekunta — Fakultet — Faculty Laitos — Institution — Department Matemaattis-luonnontieteellinen Tietojenkäsittelytieteen laitos Tekijä — Författare — Author Laura Leppänen Työn nimi — Arbetets titel — Title Funktionaalisten kielten ydinpiirteiden toteutus oliokielten virtuaalikonealustoilla Oppiaine — Läroämne — Subject Tietojenkäsittelytiede Työn laji — Arbetets art — Level Aika — Datum — Month and year Sivumäärä — Sidoantal — Number of pages Pro gradu -tutkielma 30. lokakuuta 2016 106 sivua + 25 sivua liitteissä Tiivistelmä — Referat — Abstract Tutkielma käsittelee funktionaalisille kielille tyypillisten piirteiden, ensimmäisen luo- kan funktioarvojen ja häntäkutsujen toteutusta oliokielille suunnatuilla JVM- ja .NET- virtuaalikonealustoilla. Oliokielille suunnattujen virtuaalikonealustojen tarjoamien tavukoodi- rajapintojen rajoitteet verrattuna matalamman tason assembly-kieliin ovat pitkään aiheut- taneet valtavirran oliokielistä poikkeavien kielten toteuttajille päänvaivaa. Tarkasteltavista alustoista .NET-alustan tavoitteena on alusta asti ollut monenlaisten kielten tukeminen. JVM- alustalla erilaisten kielten toteuttajien tarpeisiin on havahduttu vasta viimeisten vuosien aikana. Tutkielma tarkastelee, millaisia mahdollisuuksia alustat nykyisellään tarjoavat ensim- -

T. Wolf: on Exceptions As First-Class Objects in Ada 95
On Exceptions as First-Class Objects in Ada 95 Thomas Wolf Paranor AG, Switzerland e–mail: [email protected] Abstract. This short position paper argues that it might gramming languages that show a much better integration be beneficial to try to bring the exception model of of object orientation and exceptions, most notably Java. Ada 95 more in–line with the object–oriented model of In the remainder of this paper, I’ll try to make a case programming. In particular, it is felt that exceptions — being such an important concept for the development of for better integrating exception into the object–oriented fault–tolerant software — have deserved a promotion to paradigm in Ada 95. Section 2 discusses some problems first–class objects of the language. It is proposed to with the current model of exceptions. Section 3 argues resolve the somewhat awkward dichotomy of exceptions for an improved exception model that would solve these and exception occurrences as it exists now in Ada 95 by problems, and section 4 presents a brief summary. treating exceptions as (tagged) types, and exception occurrences as their instances. 2 Exceptions in Ada 95 Keywords. Object–Oriented Exception Handling, Soft- ware Fault Tolerance Exceptions in Ada 95 are seen as some kind of “special objects”: even their declaration looks more like that of an object than a type declaration: 1 Introduction Some_Exception : exception; The exception model of Ada 95 [ARM95] is still basi- Such exceptions can be raised (or thrown, as other lan- cally the same as it was in the original Ada 83 program- guages call it) through a raise statement: ming language; although some improvements did occur: raise Some_Exception; the introduction of the concept of exception occurrences, and some other, minor improvements concerning excep- or through a procedure that passes a string message tion names and messages.