Travel Time and Incident Risk Assessment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
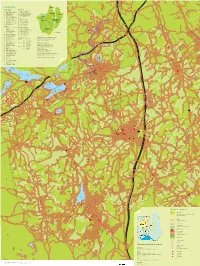
Nurmijärven Matkailu Ja Ulkoilukartta
NURMIJÄRVI NÄHTÄVYYDET RATSASTUS 1 Aleksis Kiven patsas 39 Islanninhevostalli Dynur 2 Aleksis Kiven syntymäkoti 55 Mintzun issikkatalli 3 Aleksis Kivi -huone 42 Nurmijärven Ratsastuskoulu 4 Klaukkalan kirkko 41 Perttulan Ratsastuskeskus 5 Museokahvila 44 Ratsastuskoulu Solbacka 6 Nukarin koulumuseo 53 Vuonotalli Solsikke 3 Nurmijärven Kirjastogalleria 7 Nurmijärven kirkko UINTI 2 Puupiirtäjän työhuone 45 Herusten uimapaikka 8 Pyhän Nektarioksen kirkko 46 Röykän uimapaikka 9 Rajamäen kirkko 35 Sääksjärven uimaranta 10 Taaborinvuoren museoalue 47 Tiiran uimaranta 11 Vanha hautausmaa 48 Vaaksin uimapaikka 49 Rajamäen uimahalli PALVELUT 12 Nurmijärven kunnanvirasto MAJOITUSPAIKKOJA Kirjastot 32 Holman kurssikeskus 13 Klaukkalan kirjasto 50 Hyvinvointikeskus Haukilampi 3 Nurmijärven pääkirjasto 34 Ketolan strutsitila 14 Rajamäen kirjasto 15 Hotelli Kiljavanranta 51 Lomakoti Kotoranta ELÄMYKSIÄ JA LUONTOA 54 Nukarin lomamökit 18 Alhonniitun ulkoilualue 53 Vuonotalli Solsikke 52 Ali-Ollin Alpakkatila 56 Bowling House TYÖPAIKKA-ALUEET MITEN MERKATAAN KUNTORADAT? 25 Maaniitun-Ihantolan Klaukkala A Järvihaka Kuntoratakartan värikoodit ei toimi tässä. liikuntapuisto B Pietarinmäki Numeroinnilla pelkästään?... 30 Frisbeegolfrata C Ristipakka Rajamäen liikuntapuisto Nurmijärvi D Alhonniittu 19 Isokallion ulkoilualue E Ilvesvuori Rajamäki – Kehityksen maja 20 Klaukkalan jäähalli F Karhunkorpi Kehityksen Majan kilpalatu 21 Klaukkalan urheilualue G Kuusimäki Märkiön lenkki (Kehityksen majalta) 22 Tarinakoru Rajamäki H Ketunpesä Matkun lenkki (Kehityksen -

Space to Live and to Grow in the Helsinki Region Welcome to Nurmijärvi
In English Space to live and to grow in the Helsinki region Welcome to Nurmijärvi Hämeenlinna 40 min Choose the kind of environment that you prefer to live in: an urban area close Tampere 1 h 20 min to services, or a rural environment close to nature. Hanko 2 h 10 min Kehä III Nurmijärvi centre Enjoy the recreational facilities on offer: there are cultural and other events – (Outer ring road) 12 min also for tourists, and there are possibilities to exercise and enjoy nature almost Hyvinkää 20 min outside your own front door. Services from the Helsinki Metropolitan Area add to Helsinki 30 min the offering. Estimated times from the E12 junction near the centre of Nurmijärvi Benefit from a wide range of services that take into account your life situation: from early childhood to basic education and further training, and later on, elderly General facts Main population people are offered a high standard of care. • Surface area: 367 km2 centres • Inhabitants: over 40 000 • Klaukkala: 40 % Your business will be ideally located, making logistics easy to arrange: a short • Under 15-yearsElinvoimaa old: 25 % ja• Nurmijärvielämisen centre: 20 % distance from the ports and airport, you’ll benefit from good road communications tilaa Helsingin• Rajamäki: seudulla 18 % in both east-west and north-south directions, while being away from the rush. Choose your workplace and your journey to work: apart from your own munici- HYVINKÄÄ pality, the Helsinki Metropolitan Area and the municipalities to the north are near Lahteen neighbours. Tampereelle MÄNTSÄLÄ 25 POR- Klaukkala Rajamäki NAI- Nurmijärvi offers all this – a large enough municipality to be able to provide the nec- JÄRVENPÄÄ NEN essary services and infrastructure for modern life, as well as to grow and develop E 12 Kirkonkylä continuously, but still small enough to provide a living space at a competitive cost. -

Horace Alan Seibert
Petteri Elo CURRICULUM VITAE Mailing Address: Prinssintie 5, 01260 Vantaa, Finland Electronic Mail: [email protected] Telephone: +358405506020 Date of Birth: February 28, 1974 Wife: Anna-Helena Elo, Master of Education, Special Education Teacher, Vice-Principle Children: Paavo Elo Samuel Elo EDUCATION Emerging Educational Leadership, April 2013, Helsinki Board of Education Educational Leadership, August 2012, Finnish National Board of Education Supervising Teacher for Student Teachers, November 2011, University of Helsinki Master of Education, Educational Science and Pedagogy, June 2007, University of Helsinki Bachelor of Education, June 2006, University of Helsinki Bachelor of Science, Economics, June 1997, University of Kent at Canterbury, United Kingdom WORK EXPERIENCE PedaNow – Educational Consulting and Training Founder, CEO and Consultant January 2015-present Education First (EF) – Professional Learning Tours January 2015-present Member of concept development team. University of Helsinki Center for Continuing Education HY+ Network Trainer January 2017 – present Polar Partners Member of the Expert Pool August 2017 - present xEdu – Business Accelerator January 2017-present Pedagogical mentor for start-ups. FulBright Scholar September 2015 – December 2015 Responsible for developing the education system in Virginia with the local educators. Consulting Teacher for the Helsinki Educational Department on Metacognitions and Higher Order Thinking Skills, August 2013 – July 2016 Responsible for consulting the curriculum process, writing the curriculum and providing in-service training for teachers, principals and administrators. Class Teacher, Hiidenkivi Comprehensive School, Helsinki, Finland August 2015 – present Head Teacher, Class Teacher, Hiidenkivi Comprehensive School, Helsinki, Finland August 2011 –July 2015 Together with the management group responsible for designing pedagogical development in Hiidenkivi Comprehensive School. Emphasis is on developing the teaching of metacognitive skills, knowledge and experience to every single student in our school. -

Lisämuutoksia Nurmijärven Linja-Autoliikenteessä 1.1.2015 Alkaen
TIEDOTE 18.12.2014 Lisämuutoksia Nurmijärven linja-autoliikenteessä 1.1.2015 alkaen Nurmijärven linja-autoliikenteeseen on tehty lisämuutoksia 1.1.2015 alkaen. Linjan 934 (Klaukkala-Myyrmäki) jat- kamisesta uudella linjatunnuksella 954 on tiedotettu jo aiemmin. Yhteydet Hyrylään Jotta Keudan opiskelijoiden kulkeminen joukkoliikennettä käyttäen olisi jatkossakin mahdollista, on rakennettu vaihdolliset yhteydet Rajamäeltä ja Nurmijärven Kirkonkylästä Hyrylään ja takaisin. Vaihdot tapahtuvat Palojoen koululla tai Nahkelassa Seutulantien risteyksen kohdalla. Vaihdollisten yhteyksien aikataulut ovat tiedotteen liittee- nä. Nykyiseen palvelutasoon ei päästä, mutta kokonaisuutta tarkastellaan vielä vuoden 2015 puolella. Nykyisellään klo 6.40 Nahkelasta Helsinkiin lähtevä vuoro lähtee jatkossa Palojoelta klo 6.45 Helsinkiin, ja siihen on vaihtoyhteys sekä Rajamäeltä että Kirkonkylältä. Paluuvuoroa Helsingistä samalla tavalla ei toistaiseksi ole pystytty järjestämään. Lahnuksen suunta Nykyisen linjan 339 (vuoden 2015 alusta 355) vuorot harvenevat ja sunnuntailiikenne lakkaa 1.1.2015 lukien. Linjan aikataulut on suunniteltu siten, että nurmijärveläisten työmatkakulkeminen Lahnuksen kautta on yhä mahdollista, ja yhteyksiä vesipuisto Serenaan on säilytetty. Kustannussyistä palvelutason parannukset on suunnattu ruuhkai- semmille yhteysväleille eli Hämeenlinnanväylälle Nurmijärven eri osista. Liput Nurmijärven nuorisolipun uusia vyöhykkeitä (Nurmijärveltä Espooseen/Vantaalle tai Helsinkiin) myydään kunnan alueella sekä Kampissa sijaitsevissa Matkahuollon -

Helsingin Poikittaislinjaston Kehittämissuunnitelma Luonnos 16.4.2019
Helsingin poikittaislinjaston kehittämissuunnitelma luonnos 16.4.2019 HSL Helsingin seudun liikenne HSL Helsingin seudun liikenne Opastinsilta 6 A PL 100, 00077 HSL00520 Helsinki puhelin (09) 4766 4444 www.hsl.fi Lisätietoja: Harri Vuorinen [email protected] Copyright: Kartat, graafit, ja muut kuvat Kansikuva: HSL / kuvaajan nimi Helsinki 2019 Esipuhe Työ on käynnistynyt syyskuussa 2018 ja ensimmäinen linjastosuunnitelmaluonnos on valmistunut marraskuussa 2018. Lopullisesti työ on valmistunut huhtikuussa 2019. Työtä on ohjannut ohjausryhmä, johon ovat kuuluneet: Jonne Virtanen, pj. HSL Harri Vuorinen HSL Markku Granholm Helsingin kaupunki Suunnittelutyön aikana on ollut avoinna blogi, joka on toiminut asukasvuorovaikutuksen pääkana- vana ja jossa on kerrottu suunnittelutyön etenemisestä. Blogissa asukkaat ovat voineet esittää näkemyksiään suunnittelutyöstä ja antaa palautetta linjastoluonnoksista. Työn yhteydessä on tee- tetty liikkumiskysely, jolla kartoitettiin asukkaiden ja suunnittelualueella liikkuvien liikkumistottumuk- sia ja mielipiteitä joukkoliikenteestä. Lisäksi työn aikana järjestettiin kolme asukastilaisuutta suunni- telmien esittelemiseksi ja palautteen saamiseksi. Työn tekemisestä HSL:ssä ovat vastanneet Harri Vuorinen projektipäällikkönä, Miska Peura, Riikka Sorsa ja Petteri Kantokari. Vaikutusarvioinnit on tehnyt WSP Finland Oy, jossa työstä ovat vastan- neet Samuli Kyytsönen ja Atte Supponen. Tiivistelmäsivu Julkaisija: HSL Helsingin seudun liikenne Tekijät: Harri Vuorinen, Miska Peura, Riikka Sorsa, Petteri Kantokari -

How the City Plan Is Drawn up and How You Can Participate?
HELSINKI CITY PLAN Statement of Community Participation and Involvement in the City Plan process How the City Plan is drawn up and how you can participate? Helsinki City Planning department, Strategic Urban Planning Division reports 2012:1 City of Helsinki City Planning Department HELSINKI CITY PLAN Statement of Community Participation and Involvement in the City Plan process 13 November 2012 How the City Plan is drawn up and how you can participate? © Helsinki City Planning Department 2012 Graphic design: Tsto Lay-out: Juhapekka Väre Photos: Teina Ryynänen Printed by Kirjapaino Uusimaa 2012 ISSN 1458-9664 Helsinki City Plan — Report 2012:1 3 Contents Introduction ...................................................................................................5 1. Why does Helsinki need a new City plan? Helsinki is growing, new housing is needed ............................................................6 The city structure needs to be more spatially balanced ............................................6 Businesses need diversity of premises ....................................................................7 Functional international transport connections must be ensured ...............................7 2. Master plan structure Vision, the City plan map and the implementation plan ............................................8 3. Important considerations and plans that affect the City plan Helsinki City plan as a part of the action plan ..........................................................9 Land Use and Building Act .....................................................................................9 -

20200616 Presentations Virtual NWM Website Version
Welcome to the virtual Network Meeting! 28th Network Meeting, May 26th 2020 Please mute your microphone Ask questions via the chat We will start at 10:00 Good morning & welcome Hans Ruijter, NETLIPSE Chairman, Rijkswaterstaat (the Netherlands) Rules during this meeting: . Please mute your microphone to avoid background noise. Only the presenters will have their microphones on. Please use the chat function on the right hand side of your screen for questions and ideas and to answer any questions the presenters ask you. If you are experiencing any problems, contact Geertje van Engen via phone or sms. The presentations will be made available on the website after the meeting. Main topics at this meeting: . Dealing with contractor delays and payment in this crisis situation . Danish government policy; Storstrøm Bridge project (DK) and Oosterweel project (B) . How organisations are using the crisis to speed up projects . Rail projects North of England and the Finnish government perspective . How to guarantee safety on sites during the crisis and organise effective communication . Dutch and German government experiences Managing large projects in a crisis situation Welcome and opening Introduction of the programme and our ‘online rules of engagement’. 10:00 – 10:05 Hans Ruijter, NETLIPSE Chairman (The Netherlands) Pau Lian Staal-Ong, NETLIPSE Director (The Netherlands) Dealing with contractors 10:05 – 10:45 How to deal with your contractors in this crisis situation? How do you cope with delays and penalties? Do you have special pre-payment agreements? Danish perspective (government policy and the Storstrøm Bridge project) 10:05 – 10:20 Helle Lange, Director of Procurement, Vejdirektoratet (Denmark) Vibeke Schiøler Sørensen, Legal Counsellor, Vejdirektoratet (Denmark) Belgium perspective (the Oosterweel project) 10:20 – 10:30 Peter Vanhoegaerden, COO, Lantis (Belgium) 10:30 – 10:45 Interactive discussion. -

Helsinki - Vaalimaa
TUAS data collection: Corridor 1, E18 Finland Turku/Naantali – Helsinki - Vaalimaa [WP3 Technical solutions along the corridors: GoA 2020] Author: Harri Heikkinen, TUAS Published: March, 2020. Figure 1: [Intelligent traffic sign on E18 Turku-Helsinki. (Tieyhtiö ykköstie 2016.)] TUAS data collection: Corridor 1, E18 Finland Turku/Naantali – Helsinki - Vaalimaa WP3 Technical solutions along the corridors By Harri Heikkinen, TUAS Copyright: Reproduction of this publication in whole or in part must include the customary bibliographic citation, including author attribution, report title, etc. Cover photo: MML, Esri Finland Published by: Turku University of Applied Sciences The contents of this publication are the sole responsibility of BALTIC LOOP partnership and do not necessarily reflect the opinion of the European Union. Contents [WP3 Technical solutions along the corridors: GoA 2020] .......................................... 1 1. Introduction .......................................................................................................... 1 2. Corridor description and segments ...................................................................... 2 3. Data collection by type and source .................................................................... 11 4. Conclusions, analysis and recommendations of further research. ..................... 20 References ............................................................................................................ 22 WP3 Technical solutions along the 03/2020 corridors / GoA 2020 -

Transport System Planning in the Helsinki Region Helsinki Regional Transport Authority
Transport system planning in the Helsinki region Helsinki Regional Transport Authority Tuire Valkonen, transport planner Contents 1. Helsinki Regional Transport Authority HRT in general 2. Helsinki Region Transport System Plan (HLJ) • The role of the plan • Background • Preparation process • HLJ 2015 policies • Examples of measures • How we cummunicate with citizens? What does HRT do? • Is responsible for the preparation of the Helsinki Region Transport System Plan (HLJ). • Plans and organizes public transport in the region and works to improve its operating conditions. • Procures bus, tram, Metro, ferry and commuter train services. • Approves the public transport fare and ticketing system as well as public transport fares. • Is responsible for public transport marketing and passenger information. • Organizes ticket sales and is responsible for ticket inspection. HRT’s basic structure (c. 360 persons) The location of the Helsinki Region in Europe HRT area and HLJ planning area Municipalities of the Keski-Uusimaa Region (KUUMA) • Land area approximately 3700 km2 • Population 1.38 million According to its charter, HRT may expand to cover all 14 municipalities in the Helsinki region. HRT Region 1.1.2012 Cities of the Helsinki 6 Metropolitan Area The main networks and terminals Nationally significant public transport terminal International airport Harbor Railway Raiway for freight traffic Metroline High way Main road Regional way In process… Ring Rail Line The west metro Helsinki Region Transport System Planning The role of the Helsinki Region Transport System Plan (HLJ) • A long-term strategic plan that considers the transport system as a whole. • Aligns regional transport policy and guidelines primary measures for the development of the transport system. -

Chemical and Physical Characterization of Traffic Particles In
1 Chemical and physical characterization of traffic particles in 2 four different highway environments in the Helsinki 3 metropolitan area 4 5 J. Enroth1,2, S.Saarikoski3, J.V. Niemi4,5, A. Kousa4, I. Ježek6, G. Močnik6,7, S. 6 Carbone3,9, H. Kuuluvainen8, T. Rönkkö8, R. Hillamo3, and L. Pirjola1,2,* 7 8 [1] {Metropolia University of Applied Sciences, Department of Technology, Helsinki, Finland} 9 [2] {University of Helsinki, Department of Physics, Helsinki, Finland} 10 [3] {Finnish Meteorological Institute, Atmospheric Composition Research, Helsinki, Finland} 11 [4] {Helsinki Region Environmental Services Authority HSY, Helsinki, Finland} 12 [5] {University of Helsinki, Department of Environmental Sciences, Helsinki, Finland} 13 [6] {Aerosol d.o.o., Ljubljana, Slovenia} 14 [7] {Jožef Stefan Institute, Ljubljana, Slovenia} 15 [8] {Tampere University of Technology, Department of Physics, Tampere, Finland} 16 [9] {now at University of São Paulo, Department of Applied Physics, São Paulo, Brazil} 17 18 Correspondence to: L. Pirjola ([email protected], [email protected]) 19 20 1 1 Abstract 2 Traffic related pollution is a major concern in urban areas due to its deleterious effects on human 3 health. The characteristics of the traffic emissions on four highway environments in the Helsinki 4 metropolitan area were measured with a mobile laboratory, equipped with state-of-the-art 5 instrumentation. Concentration gradients were observed for all traffic related pollutants, 6 particle number (CN), particulate mass PM1, black carbon (BC), organics and nitrogen oxides 7 (NO and NO2). Flow dynamics in different environments appeared to be an important factor 8 for the dilution of the pollutants. -

D4.1 Baseline Report of Helsinki Demonstration Area WP4, Task 4.1
Ref. Ares(2017)5877929 - 30/11/2017 Deliverable due date: M12 – November 2017 D4.1 Baseline report of Helsinki demonstration area WP4, Task 4.1 Transition of EU cities towards a new concept of Smart Life and Economy D4.1 Baseline report of Helsinki demonstration area Page ii Project Acronym mySMARTLife Project Title Transition of EU cities towards a new concept of Smart Life and Economy st th Project Duration 1 December 2016 – 30 November 2021 (60 Months) Deliverable D4.1 Baseline report of Helsinki demonstration area Diss. Level PU Working Status Verified by other WPs Final version Due date 30/11/2017 Work Package WP4 Lead beneficiary VTT Contributing HEL, FVH, HEN, CAR, TEC beneficiary(ies) Task 4.1: Baseline Assessment [VTT] (HEL, FVH, HEN, CAR, TEC) This task will set and assess baseline for Helsinki demonstration, including calculated and measured values from one year period. An integrated protocol for monitoring the progress of the demonstration will be followed according to WP5. The following subtasks are encompassed in this task: - Subtask 4.1.1: Buildings and district baseline: VTT will coordinate partners in the definition and assessment of the baseline and protocol for building and district energy consumption, share of renewables, CO2 emissions and use of waste energy sources. In addition the base line sets the baseline for control and management systems. - Subtask 4.1.2: Energy supply diagnosis – local resources: The definition and assessment of the energy supply systems and use of local and renewable resources will be led by VTT and HEN. The assessment includes the primary energy use, utilisation of hybrid and smart (two way) energy networks and waste energy resources. -

Analysing Residential Real Estate Investments in Helsinki
Aleksi Tapio Analysing residential real estate investments in Helsinki Metropolia University of Applied Sciences Bachelor of Business Administration European Business Administration Bachelor’s Thesis 29.04.2019 Abstract Author Aleksi Tapio Title Analysing residential real estate investments in Helsinki Number of Pages 35 pages + 2 appendices Date 29 April 2019 Degree Bachelor of Business Administration Degree Programme European Business Administration Instructor/Tutor Daryl Chapman, Senior Lecturer Real estate is a commonly used investment vehicle. However, due to residential real estate’s heterogeneous market, picking a good deal is hard and participating can be scary due to its capital intensiveness. The investor has to understand the market and know how to conduct and analysis. The paper addresses the fundamentals of investing in Helsinki under the Finnish legislation. Helsinki has grown as a city for the past years. Evaluating the city’s growth opportunities wields the investors with confidence on the cyclical real estate market. The market analysis will also show the differences between the locations within Helsinki, opening up potential for investors of many kind. When looking at the process of analysing, the research in this paper focuses the whole spectrum of it: which tools can be used to save time, how to correctly calculate returns and risks and what are the downfalls and benefits of the calculations. The methodology of hedging risks in real estate investing will cover the common fears such as rising interest rate, and will discuss the use of real estate as a hedge against inflation. The paper uses public data sources for comparative data analysis to find variables which affect the price, and draw conclusions according to the data.