A Design Pattern for Deploying Machine Learning Models to Production
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Study of the Effectiveness of Cloud Infrastructure
A STUDY OF THE EFFECTIVENESS OF CLOUD INFRASTRUCTURE CONFIGURATION A Thesis Presented to the Faculty of California State Polytechnic University, Pomona In Partial Fulfillment Of the Requirements for the Degree Master of Science In Computer Science By Bonnie Ngu 2020 SIGNATURE PAGE THESIS: A STUDY OF THE EFFECTIVENESS OF CLOUD INFRASTRUCTURE CONFIGURATION AUTHOR: Bonnie Ngu DATE SUBMITTED: Spring 2020 Department of Computer Science Dr. Gilbert S. Young _______________________________________ Thesis Committee Chair Computer Science Yu Sun, Ph.D _______________________________________ Computer Science Dominick A. Atanasio _______________________________________ Professor Computer Science ii ACKNOWLEDGEMENTS First and foremost, I would like to thank my parents for blessing me with the opportunity to choose my own path. I would also like to thank Dr. Young for all the encouragement throughout my years at Cal Poly Pomona. It was through his excitement and passion for teaching that I found my passion in computer science. Dr. Sun and Professor Atanasio for taking the time to understand my thesis and providing valuable input. Lastly, I would like to thank my other half for always seeing the positive side of things and finding the silver lining. It has been an incredible chapter in my life, and I could not have done it without all the love and moral support from everyone. iii ABSTRACT As cloud providers continuously strive to strengthen their cloud solutions, companies, big and small, are lured by this appealing prospect. Cloud providers aim to take away the trouble of the brick and mortar of physical equipment. Utilizing the cloud can help companies increase efficiency and improve cash flow. -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
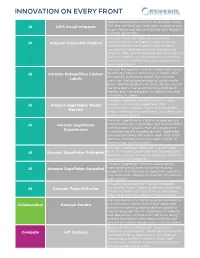
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -
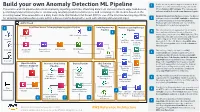
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Getting Started with AWS Deploying a Web Application Getting Started with AWS Deploying a Web Application
Getting Started with AWS Deploying a Web Application Getting Started with AWS Deploying a Web Application Getting Started with AWS: Deploying a Web Application Copyright © 2014 Amazon Web Services, Inc. and/or its affiliates. All rights reserved. The following are trademarks of Amazon Web Services, Inc.: Amazon, Amazon Web Services Design, AWS, Amazon CloudFront, Cloudfront, Amazon DevPay, DynamoDB, ElastiCache, Amazon EC2, Amazon Elastic Compute Cloud, Amazon Glacier, Kindle, Kindle Fire, AWS Marketplace Design, Mechanical Turk, Amazon Redshift, Amazon Route 53, Amazon S3, Amazon VPC. In addition, Amazon.com graphics, logos, page headers, button icons, scripts, and service names are trademarks, or trade dress of Amazon in the U.S. and/or other countries. Amazon©s trademarks and trade dress may not be used in connection with any product or service that is not Amazon©s, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Getting Started with AWS Deploying a Web Application Table of Contents Welcome ..................................................................................................................................... 1 Overview of the Project .................................................................................................................. 2 AWS Elastic Beanstalk .......................................................................................................... -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

Web Application Hosting in the AWS Cloud AWS Whitepaper Web Application Hosting in the AWS Cloud AWS Whitepaper
Web Application Hosting in the AWS Cloud AWS Whitepaper Web Application Hosting in the AWS Cloud AWS Whitepaper Web Application Hosting in the AWS Cloud: AWS Whitepaper Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Web Application Hosting in the AWS Cloud AWS Whitepaper Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 An overview of traditional web hosting ................................................................................................ 2 Web application hosting in the cloud using AWS .................................................................................... 3 How AWS can solve common web application hosting issues ........................................................... 3 A cost-effective alternative to oversized fleets needed to handle peaks ..................................... 3 A scalable solution to handling unexpected traffic -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ................................................................................................... -

Autoscaling Hadoop Clusters Master’S Thesis (30 EAP)
UNIVERSITYOFTARTU FACULTY OF MATHEMATICS AND COMPUTER SCIENCE Institute of Computer Science Toomas R¨omer Autoscaling Hadoop Clusters Master's thesis (30 EAP) Supervisor: Satish Narayana Srirama Author: ........................................................................ \....." may 2010 Supervisor: ................................................................. \....." may 2010 Professor: ................................................... \....." may 2010 TARTU 2010 Contents 1 Introduction4 1.1 Goals......................................5 1.2 Prerequisites..................................6 1.3 Outline.....................................6 2 Background Knowledge7 2.1 IaaS Software.................................7 2.1.1 Amazon Services...........................7 2.1.2 Eucalyptus Services.......................... 10 2.1.3 Access Credentials.......................... 12 2.2 MapReduce and Apache Hadoop...................... 12 2.2.1 MapReduce.............................. 12 2.2.2 Apache Hadoop............................ 13 2.2.3 Apache Hadoop by an Example................... 14 3 Results 19 3.1 Autoscalable AMIs.............................. 19 3.1.1 Requirements............................. 19 3.1.2 Meeting the Requirements...................... 20 3.2 Hadoop Load Monitoring........................... 24 3.2.1 Heartbeat............................... 24 3.2.2 System Metrics............................ 25 3.2.3 Ganglia................................ 26 3.2.4 Amazon CloudWatch......................... 27 3.2.5 Conclusions............................. -

Building Devops on Amazon Web Services (AWS) 2 Building Devops on Amazon Web Services (AWS)
IBM Global Business Services January 2018 White paper Building DevOps on Amazon Web Services (AWS) 2 Building DevOps on Amazon Web Services (AWS) Abstract IBM defines DevOps as an enterprise capability that enables organizations to seize market opportunities and reduce time to At its core, DevOps makes delivery of applications more customer feedback, and has three main business objectives: efficient. Amazon Web Services (AWS) has the platform and services to recognize a code change and automate delivery of 1. Speeding continuous innovation of ideas by enabling that change from development, through the support collaborative development and testing across the value environments, to production. However, delivery of code is just chain one aspect of DevOps. 2. Enabling continuous delivery of these innovations by automating software delivery processes and eliminating IBM extends the DevOps definition, making it an enterprise waste, while also helping to meet regulatory concerns capability that enables organizations to seize market 3. Providing a feedback loop for continuous learning from opportunities and reduce time to customer feedback. IBM’s customers by monitoring and optimizing software-driven main objectives are speeding continuous innovation of ideas, innovation enabling continuous delivery of those innovations, and providing meaningful feedback for continuous learning, thereby putting all the emphasis on deciding what code to change. IBM extends DevOps to include all stakeholders in an organization who develop, operate or benefit from businesses systems. DevOps enables design thinking, which focuses on user outcomes, restless reinvention, and empowering teams to act. In addition, DevOps enables lean and agile methodologies, which guide teams to deliver in smaller increments and get early feedback. -

All Services Compute Developer Tools Machine Learning Mobile
AlL services X-Ray Storage Gateway Compute Rekognition d Satellite Developer Tools Amazon Sumerian Athena Machine Learning Elastic Beanstalk AWS Backup Mobile Amazon Transcribe Ground Station EC2 Servertess Application EMR Repository Codestar CloudSearch Robotics Amazon SageMaker Customer Engagement Amazon Transtate AWS Amplify Amazon Connect Application Integration Lightsail Database AWS RoboMaker CodeCommit Management & Governance Amazon Personalize Amazon Comprehend Elasticsearch Service Storage Mobile Hub RDS Amazon Forecast ECR AWS Organizations Step Functions CodeBuild Kinesis Amazon EventBridge AWS Deeplens Pinpoint S3 AWS AppSync DynamoDe Amazon Textract ECS CloudWatch Blockchain CodeDeploy Quicksight EFS Amazon Lex Simple Email Service AWS DeepRacer Device Farm ElastiCache Amazont EKS AWS Auto Scaling Amazon Managed Blockchain CodePipeline Data Pipeline Simple Notification Service Machine Learning Neptune FSx Lambda CloudFormation Analytics Cloud9 AWS Glue Simple Queue Service Amazon Polly Business Applications $3 Glacer AR & VR Amazon Redshift SWF Batch CloudTrail AWS Lake Formation Server Migration Service lot Device Defender Alexa for Business GuardDuty MediaConnect Amazon QLDB WorkLink WAF & Shield Config AWS Well. Architected Tool Route 53 MSK AWS Transfer for SFTP Artifact Amazon Chime Inspector lot Device Management Amazon DocumentDB Personal Health Dashboard C MediaConvert OpsWorks Snowball API Gateway WorkMait Amazon Macie MediaLive Service Catalog AWS Chatbot Security Hub Security, Identity, & Internet of Things loT