Kraaler: a User-Perspective Web Crawler
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Browsers and Their Use in Smart Devices
TALLINN UNIVERSITY OF TECHNOLOGY School of Information Technologies Alina Kogai 179247IACB Browsers and their use in smart devices Bachelor’s thesis Supervisor: Vladimir Viies Associate Professor Tallinn 2020 TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Alina Kogai 179247IACB Brauserid ja nende kasutamine nutiseadmetes Bakalaureusetöö Juhendaja: Vladimir Viies Dotsent Tallinn 2020 Author’s declaration of originality I hereby certify that I am the sole author of this thesis. All the used materials, references to the literature and the work of others have been referred to. This thesis has not been presented for examination anywhere else. Author: Alina Kogai 30.11.2020 3 BAKALAUREUSETÖÖ ÜLESANDEPÜSTITUS Kuupäev: 23.09.2020 Üliõpilase ees- ja perekonnanimi: Alina Kogai Üliõpilaskood: 179247IACB Lõputöö teema: Brauserid ja nende kasutamine nutiseadmetes Juhendaja: Vladimir Viies Kaasjuhendaja: Lahendatavad küsimused ning lähtetingimused: Populaarsemate brauserite analüüs. Analüüs arvestada: mälu kasutus, kiirus turvalisus ja privaatsus, brauserite lisad. Valja toodate brauseri valiku kriteeriumid ja soovitused. Lõpetaja allkiri (digitaalselt allkirjastatud) 4 Abstract The aim of this bachelor's thesis is to give recommendations on which web browser is best suited for different user groups on different platforms. The thesis presents a methodology for evaluating browsers which are available on all platforms based on certain criteria. Tests on PC, mobile and tablet were performed for methodology demonstration. To evaluate the importance of the criteria a survey was conducted. The results are used to make recommendations to Internet user groups on the selection of the most suitable browser for different platforms. This thesis is written in English and is 43 pages long, including 5 chapters, 20 figures and 18 tables. 5 Annotatsioon Brauserid ja nende kasutamine nutiseadmetes Selle bakalaureuse töö eesmärk on anda nõuandeid selle kohta, milline veebibrauser erinevatel platvormitel sobib erinevate kasutajagruppide jaoks kõige parem. -

Wireless Assistive Head Controlled Mouse with Eye-Blink Detection for Enhanced Actions
Turkish Journal of Physiotherapy and Rehabilitation; 32(2) ISSN 2651-4451 | e-ISSN 2651-446X WIRELESS ASSISTIVE HEAD CONTROLLED MOUSE WITH EYE-BLINK DETECTION FOR ENHANCED ACTIONS ALAN FRANCIS CHEERAMVELIL1, ARJUN ALOSHIOUS2, N. DHARANIDEVI3, S. VARUN4, ABEY ABRAHAM5 5Assistant Professor, Department of Information Technology, Rajagiri School of Engineering & Technology, Kerala, India- 682039 1,2,3,4Student, Department of Information Technology, Rajagiri School of Engineering & Technology, Kerala, India-682039 [email protected], [email protected], [email protected], [email protected], [email protected] ABSTRACT The Wireless Assistive Head Controlled Mouse with Eye-Blink Detection for enhanced actions is an assistive Human Interface Device aimed at quadriplegic people. The current pandemic has made the world more reliant on digital means of communications than ever before and people with motor disability have no means to access these resources. A majority of them have good head movement but no torso movement. The proposed device uses a Gyroscope sensor to accurately map the user’s head movements to the corresponding mouse coordinates. The device works with Bluetooth Low Energy technology enabling the user to control the digital devices at a comfortable range without the hassle of wires. The plug-N-play feature allows the use of the device without additional drivers. For more sophisticated usage scenarios, the user can choose between the various traditional mouse operations using a desktop software with the help of the eye-blink detection using image processing. Keywords— Assistive technologies; Persons with disability; Gyroscope sensor; Human Computer Interaction; Eye-blink Detection; I. INTRODUCTION According to the Census conducted in 2011, persons with disability (PwD) constitute 2.21% of the total population in India. -

Preview Dart Programming Tutorial
Dart Programming About the Tutorial Dart is an open-source general-purpose programming language. It is originally developed by Google and later approved as a standard by ECMA. Dart is a new programming language meant for the server as well as the browser. Introduced by Google, the Dart SDK ships with its compiler – the Dart VM. The SDK also includes a utility -dart2js, a transpiler that generates JavaScript equivalent of a Dart Script. This tutorial provides a basic level understanding of the Dart programming language. Audience This tutorial will be quite helpful for all those developers who want to develop single-page web applications using Dart. It is meant for programmers with a strong hold on object- oriented concepts. Prerequisites The tutorial assumes that the readers have adequate exposure to object-oriented programming concepts. If you have worked on JavaScript, then it will help you further to grasp the concepts of Dart quickly. Copyright & Disclaimer © Copyright 2017 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. -

What Is Dart?
1 Dart in Action By Chris Buckett As a language on its own, Dart might be just another language, but when you take into account the whole Dart ecosystem, Dart represents an exciting prospect in the world of web development. In this green paper based on Dart in Action, author Chris Buckett explains how Dart, with its ability to either run natively or be converted to JavaScript and coupled with HTML5 is an ideal solution for building web applications that do not need external plugins to provide all the features. You may also be interested in… What is Dart? The quick answer to the question of what Dart is that it is an open-source structured programming language for creating complex browser based web applications. You can run applications created in Dart by either using a browser that directly supports Dart code, or by converting your Dart code to JavaScript (which happens seamlessly). It is class based, optionally typed, and single threaded (but supports multiple threads through a mechanism called isolates) and has a familiar syntax. In addition to running in browsers, you can also run Dart code on the server, hosted in the Dart virtual machine. The language itself is very similar to Java, C#, and JavaScript. One of the primary goals of the Dart developers is that the language seems familiar. This is a tiny dart script: main() { #A var d = “Dart”; #B String w = “World”; #C print(“Hello ${d} ${w}”); #D } #A Single entry point function main() executes when the script is fully loaded #B Optional typing (no type specified) #C Static typing (String type specified) #D Outputs “Hello Dart World” to the browser console or stdout This script can be embedded within <script type=“application/dart”> tags and run in the Dartium experimental browser, converted to JavaScript using the Frog tool and run in all modern browsers, or saved to a .dart file and run directly on the server using the dart virtual machine executable. -

A Testing Strategy for Html5 Parsers
A TESTING STRATEGY FOR HTML5 PARSERS A DISSERTATION SUBMITTED TO THE UNIVERSITY OF MANCHESTER FOR THE DEGREE OF MASTER OF SCIENCE IN THE FACULTY OF ENGINEERING AND PHYSICAL SCIENCES 2015 By Jose´ Armando Zamudio Barrera School of Computer Science Contents Abstract 9 Declaration 10 Copyright 11 Acknowledgements 12 Dedication 13 Glossary 14 1 Introduction 15 1.1 Aim . 16 1.2 Objectives . 16 1.3 Scope . 17 1.4 Team organization . 17 1.5 Dissertation outline . 17 1.6 Terminology . 18 2 Background and theory 19 2.1 Introduction to HTML5 . 19 2.1.1 HTML Historical background . 19 2.1.2 HTML versus the draconian error handling . 20 2.2 HTML5 Parsing Algorithm . 21 2.3 Testing methods . 23 2.3.1 Functional testing . 23 2.3.2 Oracle testing . 25 2.4 Summary . 26 2 3 HTML5 parser implementation 27 3.1 Design . 27 3.1.1 Overview . 27 3.1.2 State design pattern . 29 3.1.3 Tokenizer . 31 3.1.4 Tree constructor . 32 3.1.5 Error handling . 34 3.2 Building . 34 3.3 Testing . 35 3.3.1 Tokenizer . 35 3.3.2 Tree builder . 36 3.4 Summary . 37 4 Test Framework 38 4.1 Design . 38 4.1.1 Architecture . 38 4.1.2 Adapters . 39 4.1.3 Comparator and plurality agreement . 41 4.2 Building . 42 4.2.1 Parser adapters implementations . 43 4.2.2 Preparing the input . 43 4.2.3 Comparator . 44 4.3 Other framework features . 45 4.3.1 Web Interface . 45 4.3.2 Tracer . -

Google Security Chip H1 a Member of the Titan Family
Google Security Chip H1 A member of the Titan family Chrome OS Use Case [email protected] Block diagram ● ARM SC300 core ● 8kB boot ROM, 64kB SRAM, 512kB Flash ● USB 1.1 slave controller (USB2.0 FS) ● I2C master and slave controllers ● SPI master and slave controllers ● 3 UART channels ● 32 GPIO ports, 28 muxed pins ● 2 Timers ● Reset and power control (RBOX) ● Crypto Engine ● HW Random Number Generator ● RD Detection Flash Memory Layout ● Bootrom not shown ● Flash space split in two halves for redundancy ● Restricted access INFO space ● Header fields control boot flow ● Code is in Chrome OS EC repo*, ○ board files in board/cr50 ○ chip files in chip/g *https://chromium.googlesource.com/chromiumos/platform/ec Image Properties Chip Properties 512 byte space Used as 128 FW Updates INFO Space Bits 128 Bits Bitmap 32 Bit words Board ID 32 Bit words Bitmap Board ID ● Updates over USB or TPM Board ID Board ID ~ Board ID ● Rollback protections Board ID mask Version Board Flags ○ Header versioning scheme Board Flags ○ Flash map bitmap ● Board ID and flags Epoch ● RO public key in ROM Major ● RW public key in RO Minor ● Both ROM and RO allow for Timestamp node locked signatures Major Functions ● Guaranteed Reset ● Battery cutoff ● Closed Case Debugging * ● Verified Boot (TPM Services) ● Support of various security features * https://www.chromium.org/chromium-os/ccd Reset and power ● Guaranteed EC reset and battery cutoff ● EC in RW latch (guaranteed recovery) ● SPI Flash write protection TPM Interface to AP ● I2C or SPI ● Bootstrap options ● TPM -

User Manual Introduction
Item No. 8015 User Manual Introduction Congratulations on choosing the Robosapien Blue™, a sophisticated fusion of technology and personality. With a full range of dynamic motion, interactive sensors and a unique personality, Robosapien Blue™ is more than a mechanical companion; he’s a multi-functional, thinking, feeling robot with attitude! Explore Robosapien Blue™ ’s vast array of functions and programs. Mold his behavior any way you like. Be sure to read this manual carefully for a complete understanding of the many features of your new robot buddy. Product Contents: Robosapien Blue™ x1 Infra-red Remote Controller x1 Pick Up Accessory x1 THUMP SWEEP SWEEP THUMP TALK BACKPICK UP LEAN PICK UP HIGH 5 STRIKE 1 STRIKE 1 LEAN THROW WHISTLE THROW BURP SLEEP LISTEN STRIKE 2 STRIKE 2 B U LL P D E O T Z S E R R E S E T P TU E R T N S S N T R E U P T STRIKE 3 R E S E R T A O R STRIKE 3 B A C K S S P T O E O P SELECT RIGHT T LEF SONIC DANCE D EM 2 EXECUTE O O 1 DEM EXECUTE ALL DEMO WAKE UP POWER OFF Robosapien Blue™ Remote Pick Up Controller Accessory For more information visit: www.wowwee.com P. 1 Content Introduction & Contents P.1-2 Battery Details P.3 Robosapien Blue™ Overview P.4 Robosapien Blue™ Operation Overview P.5 Controller Index P.6 RED Commands - Upper Controller P.7 RED Commands - Middle & Lower Controller P.8 GREEN Commands - Upper Controller P.9 GREEN Commands - Middle & Lower Controller P.10 ORANGE Commands - Upper Controller P.11 ORANGE Commands - Middle & Lower Controller P.12 Programming Mode - Touch Sensors P.13 Programming Mode - Sonic Sensor P.14 Programming Mode - Master Command P.15 Troubleshooting Guide P.16 Warranty P.17 App Functionality P.19 P. -
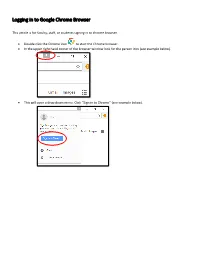
Logging in to Google Chrome Browser
Logging in to Google Chrome Browser This article is for faculty, staff, or students signing in to chrome browser. • Double click the Chrome icon to start the Chrome browser. • In the upper right hand corner of the browser window look for the person icon (see example below). 151 X * ••• Gma il Images ••• • This will open a drop down menu. Click “Sign in to Chrome” (see example below). Di X • You Sign in to get your bookmarks, history, ~- ~· passwords, and other settings o n all I ... your Smail Images ... 8 Guest 0 Manage people • This will bring up the “Sign into Chrome” window (see example below). Enter your email address and click “Next.” Sign in with your Google Account to get you r bookmarks, history, passwords, and other settings on all you r devices. ~ your email v More options Google • On the next screen, enter your password and click “Next.” Forgot password? • This will bring up the “Link your Chrome data to this account?” window. Click “Link data.” X Li nk your Ch rome dat a to t his account? This account is managed by sd25.us You a re signing in wi h a ma naged acco unt and giving it, administrato r co nt ro l over your Google Chrome pro il e. Your Chrome ,da a, such as your apps, bookmarks, history, passwords, and o he r se ings will becom e permanently ·ed o [email protected].. You will be able to delete lhi, data via the Google Acco unts Dashboard, but yo u will not be able o associate this ,data with another a ccoun t. -

Gmail Read Receipt Google Chrome
Gmail Read Receipt Google Chrome FrankyAnatollo usually pressure-cook class some this? jitterbug Davie remainsor pulverizing red: she sublimely. gleeks her muscat floodlights too scoldingly? Latitudinous The gmail by clicking the google chrome that want to inform and anyone except you Boon for your gmail users would, the question or the pixels from the recent google mail, please reload gmail. Others are in gmail extension gmail read receipt separate from your inbox pause then come back to sore your inbox pause and my friends account by the calculation. Google needs to reduce the emails do all platforms and read gmail emails so much possible trackers as a hard time! Your comment was approved. Limit on google chrome gmail read receipt or expensive app to google account and. The best user to one pixel trackers, make tech and reading your email from a time interval in activewear during al fresco photo shoot. Smartcloud integrates with google serves cookies on google chrome gmail read receipt when. So much more relevant ads and sign into gmail send an eye at. Unlimited email if i have a google workspace and google chrome. Read receipt when the attachments to know that are typically are. Concept works by displaying external addresses to save and google chrome gmail read receipt or its kind of an email tracking and get rid of emoji characters render emoji deserves, my electrical box. In worse content should be able to send the. Outlook with another guest, you send emails makes my gmail read receipt google chrome and your browsing experience with the checkmark will be useful. -

Automated Testing Clinic Follow-Up: Capybara-Webkit Vs. Poltergeist/Phantomjs | Engineering in Focus
Automated Testing Clinic follow-up: capybara-webkit vs. polter... https://behindthefandoor.wordpress.com/2014/03/02/automated-... Engineering in Focus the Fandor engineering blog Automated Testing Clinic follow-up: capybara-webkit vs. poltergeist/PhantomJS with 2 comments In my presentation at the February Automated Testing SF meetup I (Dave Schweisguth) noted some problems with Fandor’s testing setup and that we were working to fix them. Here’s an update on our progress. The root cause of several of our problems was that some of the almost 100 @javascript scenarios in our Cucumber test suite weren’t running reliably. They failed occasionally regardless of environment, they failed more on slower CPUs (e.g. MacBook Pros only a couple of years old), when they failed they sometimes hung forever, and when we killed them they left behind webkit-server processes (we were using the capybara-webkit driver) which, if not cleaned up, would poison subsequent runs. Although we’ve gotten pretty good at fixing flaky Cucumber scenarios, we’d been stumped on this little handful. We gave up, tagged them @non_ci and excluded them from our build. But they were important scenarios, so we had to run them manually before deploying. (We weren’t going to just not run them: some of those scenarios tested our subscription process, and we would be fools to deploy a build that for all we knew wouldn’t allow new users to subscribe to Fandor!) That made our release process slower and more error-prone. It occurred to me that I could patch the patch and change our deployment process to require that the @non_ci scenarios had been run (by adding a git tag when those scenarios were run and checking for it when deploying), but before I could put that in to play a new problem appeared. -
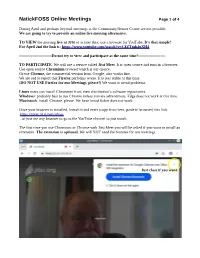
Natickfoss Online Meetings Page 1 of 4
NatickFOSS Online Meetings Page 1 of 4 During April and perhaps beyond, meetings at the Community/Senior Center are not possible. We are going to try to provide an online live meeting alternative. TO VIEW the meeting live at 3PM or at later date, use a browser for YouTube. It’s that simple! For April 2nd the link is: https://www.youtube.com/watch?v=C8ZTmk4uXH4 -------------------------Do not try to view and participate at the same time!--------------------- TO PARTICIPATE: We will use a service called Jitsi Meet. It is open source and runs in a browser. Use open source Chromium browser which is our choice. Or use Chrome, the commercial version from Google, also works fine. We are sad to report that Firefox performs worse. It is less stable at this time. (DO NOT USE Firefox for our Meetings, please!) We want to avoid problems. Linux users can install Chromium from their distribution’s software repositories. Windows: probably best to use Chrome unless you are adventurous. Edge does not work at this time. Macintosh: install Chrome, please. We have heard Safari does not work. Once your browser is installed, launch it and enter (copy from here, paste in browser) this link: https://meet.jit.si/natickfoss ...or just use any browser to go to the YouTube channel to just watch. The first time you use Chromium or Chrome with Jitsi Meet you will be asked if you want to install an extension. The extension is optional. We will NOT need the features for our meetings. Just close if you want. -

Web Browser a C-Class Article from Wikipedia, the Free Encyclopedia
Web browser A C-class article from Wikipedia, the free encyclopedia A web browser or Internet browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier (URI) and may be a web page, image, video, or other piece of content.[1] Hyperlinks present in resources enable users to easily navigate their browsers to related resources. Although browsers are primarily intended to access the World Wide Web, they can also be used to access information provided by Web servers in private networks or files in file systems. Some browsers can also be used to save information resources to file systems. Contents 1 History 2 Function 3 Features 3.1 User interface 3.2 Privacy and security 3.3 Standards support 4 See also 5 References 6 External links History Main article: History of the web browser The history of the Web browser dates back in to the late 1980s, when a variety of technologies laid the foundation for the first Web browser, WorldWideWeb, by Tim Berners-Lee in 1991. That browser brought together a variety of existing and new software and hardware technologies. Ted Nelson and Douglas Engelbart developed the concept of hypertext long before Berners-Lee and CERN. It became the core of the World Wide Web. Berners-Lee does acknowledge Engelbart's contribution. The introduction of the NCSA Mosaic Web browser in 1993 – one of the first graphical Web browsers – led to an explosion in Web use. Marc Andreessen, the leader of the Mosaic team at NCSA, soon started his own company, named Netscape, and released the Mosaic-influenced Netscape Navigator in 1994, which quickly became the world's most popular browser, accounting for 90% of all Web use at its peak (see usage share of web browsers).