Sweetwiki: Semantic Web Enabled Technologies in Wiki
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Semantic Wiki Search
Semantic Wiki Search Peter Haase1, Daniel Herzig1,, Mark Musen2,andThanhTran1 1 Institute AIFB, Universit¨at Karlsruhe (TH), Germany {pha,dahe,dtr}@aifb.uni-karlsruhe.de 2 Stanford Center for Biomedical Informatics Research (BMIR) Stanford University, USA [email protected] Abstract. Semantic wikis extend wiki platforms with the ability to represent structured information in a machine-processable way. On top of the structured in- formation in the wiki, novel ways to search, browse, and present the wiki content become possible. However, while powerful query languages offer new opportuni- ties for semantic search, the syntax of formal query languages is not adequate for end users. In this work we present an approach to semantic search that combines the expressiveness and capabilities of structured queries with the simplicity of keyword interfaces and faceted search. Users articulate their information need in keywords, which are translated into structured, conjunctive queries. This transla- tion may result in multiple possible interpretations of the information need, which can then be selected and further refined by the user via facets. We have imple- mented this approach to semantic search as an extension to Semantic MediaWiki. The results of a user study in the SMW-based community portal semanticweb.org show the efficiency and effectiveness of the approach as well as its ease of use. 1 Introduction The availability of structured information on the Semantic Web enables new opportu- nities for information access. Search is no longer limited to matching keywords against documents, but instead complex information needs can be expressed in a structured way, with precise and structured answers as results [1,2,3]. -

Evaluating Web Development Frameworks for Delphi
Evaluating Web Development Frameworks for Delphi Updates, links, and more embt.co/WebDev2019 #DelphiWebDev Disclaimer ❏ This content is mostly focused on 3rd party frameworks and libraries ❏ While a lot of time was spent researching, some of the information may be outdated or otherwise incorrect through an error during research ❏ Links are provided to the sources, and you are encouraged to double check all information and seek clarification ❏ Any exclusion is just an oversight or a result of limited time and space and was not an intentional indication of quality or suitability ❏ This information presented here is not intended to indicate superiority or inferiority of one library over another for any use cases ❏ Please consider this a good faith effort to represent these libraries and frameworks impartially and accurately ❏ I will reach out to the projects, companies, and developers to seek corrections and additional information. ❏ Erratas and updates will be published at embt.co/WebDev2019 Thanks! Delphi and FireMonkey: Winning Combination for Cross- Platform Development → Single Codebase → Easy-to-tailor platform specific UIs → One programming language to learn and support What about Web Apps? Delphi’s incredible productivity for building amazing apps also extends to the web! https://blog.hootsuite.com/simon-kemp-social-media/ https://blog.hootsuite.com/simon-kemp-social-media/ People spend a daily average of 6 hours & 42 minutes using the internet https://blog.hootsuite.com/simon-kemp-social-media/ ❏Different kinds of web development -

D3.5 Semantic Wiki
D3.5 Semantic Wiki V 2.0 Project acronym: FLOOD-serv Public FLOOD Emergency Project full title: and Awareness SERvice Grant agreement no.: 693599 Responsible: SIVECO Contributors: SIVECO Document Reference: D3.5 Dissemination Level: PU Version: Final Date: 31/01/2018 This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 693599 D3.5 Semantic Wiki Table of contents Table of contents ............................................................................................................. 2 List of tables .................................................................................................................... 4 List of abbreviations ......................................................................................................... 5 Executive summary .......................................................................................................... 6 1 Introduction ............................................................................................................. 7 1.1 Document Purpose and Scope .................................................................................... 7 1.2 Target Audience........................................................................................................... 7 1.3 How Final Review Observations Were Addresses ....................................................... 7 2 Technical Specifications ........................................................................................... -

End-User Story Telling with a CIDOC CRM- Based Semantic Wiki
End-user storytelling with a CIDOC CRM-based semantic wiki Vincent Ribaud (reviewed by Patrick Le Bœuf) Département d'Informatique - U. B. O. Brest, France [email protected] Abstract: This paper presents the current state of an experiment intended to use the CIDOC CRM as a knowledge representation language. STEM freshers freely constitute groups of 2 to 4 members and choose a theme; groups have to model, structure, write and present a story within a web-hosted semantic wiki. The main part of the CIDOC CRM is used as an ontological core where students are hanging up classes and properties of the domain related to the story. The hypothesis is made that once the entry ticket has been paid, the CRM guides the end-user in a fairly natural manner for reading - and writing - the story. The intermediary assessment of the wikis allowed us to detect confusion between immaterial work and (physical) realisation of the work; and difficulty in having event-centred modelling. Final assessment results are satisfactory but may be improved. Some groups did not acquire modelling abilities - although this is a central issue in a semantic web course. Results also indicate that the scope of the course (semantic web) is somewhat too ambitious. This experience was performed in order to attract students to computer science studies but it did not produce the expected results. It did however succeed in arousing student interest, and it may contribute to the dissemination of ontologies and to making CIDOC CRM widespread. CIDOC 2010 ICOM General Conference Shanghai, China 2010-11-08 – 11-10 Introduction This paper presents the current state of an experiment intended to use the CIDOC CRM as a knowledge representation language inside a semantic wiki. -

Semantic Mediawiki in Operation: Experiences with Building a Semantic Portal
Semantic MediaWiki in Operation: Experiences with Building a Semantic Portal Daniel M. Herzig and Basil Ell Institute AIFB Karlsruhe Institute of Technology 76128 Karlsruhe, Germany fherzig, [email protected] http://www.aifb.kit.edu Abstract. Wikis allow users to collaboratively create and maintain con- tent. Semantic wikis, which provide the additional means to annotate the content semantically and thereby allow to structure it, experience an enormous increase in popularity, because structured data is more us- able and thus more valuable than unstructured data. As an illustration of leveraging the advantages of semantic wikis for semantic portals, we report on the experience with building the AIFB portal based on Seman- tic MediaWiki. We discuss the design, in particular how free, wiki-style semantic annotations and guided input along a predefined schema can be combined to create a flexible, extensible, and structured knowledge representation. How this structured data evolved over time and its flex- ibility regarding changes are subsequently discussed and illustrated by statistics based on actual operational data of the portal. Further, the features exploiting the structured data and the benefits they provide are presented. Since all benefits have its costs, we conducted a performance study of the Semantic MediaWiki and compare it to MediaWiki, the non- semantic base platform. Finally we show how existing caching techniques can be applied to increase the performance. 1 Introduction Web portals are entry points for information presentation and exchange over the Internet about a certain topic or organization, usually powered by a community. Leveraging semantic technologies for portals and exploiting semantic content has been proven useful in the past [1] and especially the aspect of providing seman- tic data got a lot of attention lately due to the Linked Open Data initiative. -

Generating Semantic Media Wiki Content from Domain Ontologies
Generating Semantic Media Wiki Content from Domain Ontologies Dominik Filipiak1;2 and Agnieszka Ławrynowicz1 Institute of Computing Science, Poznan University of Technology, Poland Business Information Systems Institute Ltd., Poland Abstract. There is a growing interest in holistic ontology engineering approaches that involve multidisciplinary teams consisting of ontology engineers and domain experts. For the latter, who often lack ontology engineering expertise, tools such as Web forms, spreadsheet like templates or semantic wikis have been devel- oped that hide or decrease the complexity of logical axiomatisation in expressive ontology languages. This paper describes a prototype solution for an automatic OWL ontology conversion to articles in Semantic Media Wiki system. Our im- plemented prototype converts a branch of an ontology rooted at the user defined class into Wiki articles and categories. The final result is defined by a template expressed in the Wiki markup language. We describe tests on two domain ontolo- gies with different characteristics: DMOP and DMRO. The tests show that our solution can be used for fast bootstrapping of Semantic Media Wiki content from OWL files. 1 Introduction There is a growing interest in holistic ontology engineering approaches [1]. Those ap- proaches use various ontological as well as non-ontological resources (such as thesauri, lexica and relational DBs) [2, 3] . They also involve multidisciplinary teams consist- ing of ontology engineers as well as non-conversant in ontology construction domain experts. Whilst an active, direct involvement of the domain experts in the construction of quality domain ontologies within the teams appears beneficial, there are barriers to overcome for such involvement to be effective. -
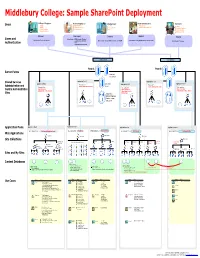
Visio-MIDD Sharepoint Architecture Design Sample.Vsd
College Colleagues Remote Employees Internal Users Farm Administrators Customers Trustees Work from Home Web Services Faculty Parents Alumni Affiliated Institutions Systems & Network Services Current Students Prospective Students External Professors Schools Abroad Staff Local Community Prospective Students Global Community Extranet Remotenet Intranet Adminet Internet Authentication = NTLM (Integrated Windows) Authentication = forms authentication using ISA Server 2006 SSO Authentication = Integrated Windows (Kerberos or NTLM) Authentication = Integrated Windows (Kerberos or NTLM) Authentication = Anonymous —or— Forms with an LDAP provider Application Pool 1 Application Pool 7 Application Pool 2 Application Pool 3 Application Pool 8 Web application: Web application: Central Administration Site Central Administration Site Web application: Web application: Web application: Shared Services Shared Services Shared Services Administration Site—Default Administration Site— Administration Site—Default PartnerWeb Application Pool 4 Application Pool 5 Application Pool 6 Application Pool 9 Web application: Intranet Applications Web application: My Sites Web application: Team Sites Web application: Intraweb Web application: Internet Site http://team <varies> http://my http://web http://www Team1 Team2 Team3 Delivered http://my/personal/<user> Handbook HR Policies Library Authoring Site Staging Site Production Site Content Collection Collection Collection HR Project from Events Management Banner, Registration Segue, etc Admissions Academics Athletics Database settings: Target size per database = TBD Database settings: Database settings: Database settings: Site size limits per site = TBD Target size per database = TBD Content Deployment Site level warning = 0 Site level warning = 0 Content Deployment Maximum number of sites = flexible Storage quota per site = TBD Maximum number of sites = 1 (one site collection per database). Maximum number of sites = 1 (one site collection per database). -

Opendrugwiki – Using a Semantic Wiki for Consolidating, Editing and Reviewing of Existing Heterogeneous Drug Data
OpenDrugWiki – Using a Semantic Wiki for Consolidating, Editing and Reviewing of Existing Heterogeneous Drug Data Anton Köstlbacher1, Jonas Maurus1, Rainer Hammwöhner1, Alexander Haas2, Ekkehard Haen2, Christoph Hiemke3 1 University of Regensburg, Information Science Universitätsstr. 31, 93053 Regensburg, Germany 2 University of Regensburg, Clinical Pharmacology, Department of Psychiatry Universitätsstr. 31, 93053 Regensburg, Germany 3 University of Mainz, Neurochemical Laboratory, Department of Psychiatry Untere Zahlbacher Str. 8, 55131 Mainz, Germany; [email protected]; [email protected]; [email protected]; [email protected]; [email protected] Abstract. The ongoing project which is described in this article pursues the integration and consolidation of drug data available in different Microsoft Office documents and existing information systems. An initial import of unstructured data out of five heterogeneous sources into a semantic wiki was performed using custom import scripts. Using Semantic MediaWiki and the Semantic Forms extension, we created a convenient wiki-based system for editing the merged data in one central application. Revised and reviewed data is exported back into production systems on a regular basis. Keywords: drug database, medical information system, semantic wiki, data conversion 1 Introduction PsiacOnline1, a drug interaction database for psychiatry in German speaking countries, was released in 2006. As of 2010 it contains over 7000 drug interactions with comprehensive information on pharmacological mechanisms, effects and severity of each interaction. Strong emphasis lies on guidance how to handle interactions in practice. [1] 1 PsiacOnline is an online service offered by SpringerMedizin: http://www.psiac.de Built on top of the component-based and event-driven prado2 framework PsiacOnline features an easy to use authoring tool for drug data. -

COLLABORATIVE KNOWLEDGE EVALUATION with a SEMANTIC WIKI Wikidesign
COLLABORATIVE KNOWLEDGE EVALUATION WITH A SEMANTIC WIKI WikiDesign Davy Monticolo1, Samuel Gomes2, Vincent Hilaire1 and Abder Koukam1 1SeT Laboratory, University of Technology UTBM, 90010 Belfort, France 2M3M Laboratory, University of Technology UTBM, 90010 Belfort, France Keywords: Semantic Wiki, Ontology, Knowledge Creation, Knowledge Evaluation, Multi-Agent System. Abstract: We will present in this paper how to ensure a knowledge evaluation and evolution in a knowledge management system by using a Semantic Wiki approach. We describe a Semantic Wiki called WikiDesign which is a component of a Knowledge Management system. Currently WikiDesign is use in engineering department of companies to emphasize technical knowledge. In this paper, we will explain how WikiDesign ensures the reliability of the knowledge base thanks to a knowledge evaluation process. After explaining the interest of the use of semantic wikis in knowledge management approach we describe the architecture of WikiDesign with its semantic functionalities. At the end of the paper, we prove the effectiveness of WikiDesign with a knowledge evaluation example for an industrial project. 1 INTRODUCTION in the wiki; It manages the collaborative editing i.e. if A wiki is a web site allows collaborative distant someone create a article, everybody can extend creation of information and editing of hypertext this article; content. Leuf (Leuf, 2001) was the first to propose a It proposes a strong linking, all the pages of the web site where people could create, modify, wiki are linked with each other using hyperlinks; transform and link pages all from within their browser and in a very simple way. Indeed Wikis be- It has a search function over the content of all come popular tools for collaboration on the web, and pages stored; many active online communities employ wikis to It allows the uploading of different content like exchange information. -

Enhancing the Development Process with Wikified Widgets Gary Gotchel Regis University
Regis University ePublications at Regis University All Regis University Theses Fall 2008 Enhancing the Development Process with Wikified Widgets Gary Gotchel Regis University Follow this and additional works at: https://epublications.regis.edu/theses Part of the Computer Sciences Commons Recommended Citation Gotchel, Gary, "Enhancing the Development Process with Wikified Widgets" (2008). All Regis University Theses. 146. https://epublications.regis.edu/theses/146 This Thesis - Open Access is brought to you for free and open access by ePublications at Regis University. It has been accepted for inclusion in All Regis University Theses by an authorized administrator of ePublications at Regis University. For more information, please contact [email protected]. Regis University College for Professional Studies Graduate Programs Final Project/Thesis Disclaimer Use of the materials available in the Regis University Thesis Collection (“Collection”) is limited and restricted to those users who agree to comply with the following terms of use. Regis University reserves the right to deny access to the Collection to any person who violates these terms of use or who seeks to or does alter, avoid or supersede the functional conditions, restrictions and limitations of the Collection. The site may be used only for lawful purposes. The user is solely responsible for knowing and adhering to any and all applicable laws, rules, and regulations relating or pertaining to use of the Collection. All content in this Collection is owned by and subject to the exclusive control of Regis University and the authors of the materials. It is available only for research purposes and may not be used in violation of copyright laws or for unlawful purposes. -

Extending Semantic Mediawiki for Interoperable Biomedical Data
Lampa et al. Journal of Biomedical Semantics (2017) 8:35 DOI 10.1186/s13326-017-0136-y SOFTWARE Open Access RDFIO: extending Semantic MediaWiki for interoperable biomedical data management Samuel Lampa1* , Egon Willighagen2, Pekka Kohonen3,4, Ali King5, Denny Vrandeciˇ c´6, Roland Grafström3,4 and Ola Spjuth1 Abstract Background: Biological sciences are characterised not only by an increasing amount but also the extreme complexity of its data. This stresses the need for efficient ways of integrating these data in a coherent description of biological systems. In many cases, biological data needs organization before integration. This is not seldom a collaborative effort, and it is thus important that tools for data integration support a collaborative way of working. Wiki systems with support for structured semantic data authoring, such as Semantic MediaWiki, provide a powerful solution for collaborative editing of data combined with machine-readability, so that data can be handled in an automated fashion in any downstream analyses. Semantic MediaWiki lacks a built-in data import function though, which hinders efficient round-tripping of data between interoperable Semantic Web formats such as RDF and the internal wiki format. Results: To solve this deficiency, the RDFIO suite of tools is presented, which supports importing of RDF data into Semantic MediaWiki, with metadata needed to export it again in the same RDF format, or ontology. Additionally, the new functionality enables mash-ups of automated data imports combined with manually created data presentations. The application of the suite of tools is demonstrated by importing drug discovery related data about rare diseases from Orphanet and acid dissociation constants from Wikidata. -

Analysis of Automated Matching of the Semantic Wiki Resources with Elements of Domain Ontologies
I.J. Mathematical Sciences and Computing, 2017, 3, 50-58 Published Online July 2017 in MECS (http://www.mecs-press.net) DOI: 10.5815/ijmsc.2017.03.05 Available online at http://www.mecs-press.net/ijmsc Analysis of Automated Matching of the Semantic Wiki Resources with Elements of Domain Ontologies Rogushina J. Institute of Software Systems of National Academy of Sciences of Ukraine, Glushkov, 44, Kiev, Ukraine Abstract Intelligent information systems oriented on the Web open environment need in dynamic and interoperable ontological knowledge bases. We propose an approach for integration of ontological analysis with semantic Wiki resources: domain ontologies are used as a base of semantic markup of the Wiki pages, and this markup becomes the source for improving of these ontologies by new information Index Terms: Ontology, semantic Wiki, information object. © 2017 Published by MECS Publisher. Selection and/or peer review under responsibility of the Research Association of Modern Education and Computer Science 1. Introduction The transition to knowledge-based systems is one of the basic trends in the development of modern information technologies. Currently, an increasing number of applications are intelligent because they use and process knowledge in their work. Intelligent information system (IIS) is an information system where use of domain knowledge and the methods of knowledge processing play a crucial role. Ontologies [1] are widely used in IIS for interoperable representation of knowledge – they ensure the reuse of the acquired knowledge in various applications. Ontological analysis can provide the basis for processing distributed knowledge. Today, a considerable amount of research relates to the theoretical basis of ontologies, their construction, improvement, obtaining knowledge from ontological structures, as well as with other important aspects of ontology management which differ significantly by their purposes.