Integration of Large-Scale Data Processing Systems and Traditional Parallel Database Technology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Java Linksammlung
JAVA LINKSAMMLUNG LerneProgrammieren.de - 2020 Java einfach lernen (klicke hier) JAVA LINKSAMMLUNG INHALTSVERZEICHNIS Build ........................................................................................................................................................... 4 Caching ....................................................................................................................................................... 4 CLI ............................................................................................................................................................... 4 Cluster-Verwaltung .................................................................................................................................... 5 Code-Analyse ............................................................................................................................................. 5 Code-Generators ........................................................................................................................................ 5 Compiler ..................................................................................................................................................... 6 Konfiguration ............................................................................................................................................. 6 CSV ............................................................................................................................................................. 6 Daten-Strukturen -
Voodoo - a Vector Algebra for Portable Database Performance on Modern Hardware
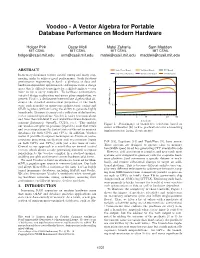
Voodoo - A Vector Algebra for Portable Database Performance on Modern Hardware Holger Pirk Oscar Moll Matei Zaharia Sam Madden MIT CSAIL MIT CSAIL MIT CSAIL MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT Single Thread Branch Multithread Branch GPU Branch In-memory databases require careful tuning and many engi- Single Thread No Branch Multithread No Branch GPU No Branch neering tricks to achieve good performance. Such database performance engineering is hard: a plethora of data and 10 hardware-dependent optimization techniques form a design space that is difficult to navigate for a skilled engineer { even more so for a query compiler. To facilitate performance- 1 oriented design exploration and query plan compilation, we present Voodoo, a declarative intermediate algebra that ab- stracts the detailed architectural properties of the hard- ware, such as multi- or many-core architectures, caches and Absolute time in s 0.1 SIMD registers, without losing the ability to generate highly tuned code. Because it consists of a collection of declarative, vector-oriented operations, Voodoo is easier to reason about 1 5 10 50 100 and tune than low-level C and related hardware-focused ex- Selectivity tensions (Intrinsics, OpenCL, CUDA, etc.). This enables Figure 1: Performance of branch-free selections based on our Voodoo compiler to produce (OpenCL) code that rivals cursor arithmetics [28] (a.k.a. predication) over a branching and even outperforms the fastest state-of-the-art in memory implementation (using if statements) databases for both GPUs and CPUs. In addition, Voodoo makes it possible to express techniques as diverse as cache- conscious processing, predication and vectorization (again PeR [18], Legobase [14] and TupleWare [9], have arisen. -

A Survey on Parallel Database Systems from a Storage Perspective: Rows Versus Columns
A Survey on Parallel Database Systems from a Storage Perspective: Rows versus Columns Carlos Ordonez1 ? and Ladjel Bellatreche2 1 University of Houston, USA 2 LIAS/ISAE-ENSMA, France Abstract. Big data requirements have revolutionized database technol- ogy, bringing many innovative and revamped DBMSs to process transac- tional (OLTP) or demanding query workloads (cubes, exploration, pre- processing). Parallel and main memory processing have become impor- tant features to exploit new hardware and cope with data volume. With such landscape in mind, we present a survey comparing modern row and columnar DBMSs, contrasting their ability to write data (storage mecha- nisms, transaction processing, batch loading, enforcing ACID) and their ability to read data (query processing, physical operators, sequential vs parallel). We provide a unifying view of alternative storage mecha- nisms, database algorithms and query optimizations used across diverse DBMSs. We contrast the architecture and processing of a parallel DBMS with an HPC system. We cover the full spectrum of subsystems going from storage to query processing. We consider parallel processing and the impact of much larger RAM, which brings back main-memory databases. We then discuss important parallel aspects including speedup, sequential bottlenecks, data redistribution, high speed networks, main memory pro- cessing with larger RAM and fault-tolerance at query processing time. We outline an agenda for future research. 1 Introduction Parallel processing is central in big data due to large data volume and the need to process data faster. Parallel DBMSs [15, 13] and the Hadoop eco-system [30] are currently two competing technologies to analyze big data, both based on au- tomatic data-based parallelism on a shared-nothing architecture. -

Analysis of Big Data Storage Tools for Data Lakes Based on Apache Hadoop Platform
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 12, No. 8, 2021 Analysis of Big Data Storage Tools for Data Lakes based on Apache Hadoop Platform Vladimir Belov, Evgeny Nikulchev MIREA—Russian Technological University, Moscow, Russia Abstract—When developing large data processing systems, determined the emergence and use of various data storage the question of data storage arises. One of the modern tools for formats in HDFS. solving this problem is the so-called data lakes. Many implementations of data lakes use Apache Hadoop as a basic Among the most widely known formats used in the Hadoop platform. Hadoop does not have a default data storage format, system are JSON [12], CSV [13], SequenceFile [14], Apache which leads to the task of choosing a data format when designing Parquet [15], ORC [16], Apache Avro [17], PBF [18]. a data processing system. To solve this problem, it is necessary to However, this list is not exhaustive. Recently, new formats of proceed from the results of the assessment according to several data storage are gaining popularity, such as Apache Hudi [19], criteria. In turn, experimental evaluation does not always give a Apache Iceberg [20], Delta Lake [21]. complete understanding of the possibilities for working with a particular data storage format. In this case, it is necessary to Each of these file formats has own features in file structure. study the features of the format, its internal structure, In addition, differences are observed at the level of practical recommendations for use, etc. The article describes the features application. Thus, row-oriented formats ensure high writing of both widely used data storage formats and the currently speed, but column-oriented formats are better for data reading. -

Oracle Metadata Management V12.2.1.3.0 New Features Overview
An Oracle White Paper October 12 th , 2018 Oracle Metadata Management v12.2.1.3.0 New Features Overview Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Disclaimer This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described in this document remains at the sole discretion of Oracle. This document in any form, software or printed matter, contains proprietary information that is the exclusive property of Oracle. This document and information contained herein may not be disclosed, copied, reproduced, or distributed to anyone outside Oracle without prior written consent of Oracle. This document is not part of your license agreement nor can it be incorporated into any contractual agreement with Oracle or its subsidiaries or affiliates. 1 Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Table of Contents Executive Overview ............................................................................ 3 Oracle Metadata Management 12.2.1.3.0 .......................................... 4 METADATA MANAGER VS METADATA EXPLORER UI .............. 4 METADATA HOME PAGES ........................................................... 5 METADATA QUICK ACCESS ........................................................ 6 METADATA REPORTING ............................................................. -

A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem
Noname manuscript No. (will be inserted by the editor) A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem César Soto-Valero · Nicolas Harrand · Martin Monperrus · Benoit Baudry Received: date / Accepted: date Abstract Build automation tools and package managers have a profound influence on software development. They facilitate the reuse of third-party libraries, support a clear separation between the application’s code and its ex- ternal dependencies, and automate several software development tasks. How- ever, the wide adoption of these tools introduces new challenges related to dependency management. In this paper, we propose an original study of one such challenge: the emergence of bloated dependencies. Bloated dependencies are libraries that the build tool packages with the application’s compiled code but that are actually not necessary to build and run the application. This phenomenon artificially grows the size of the built binary and increases maintenance effort. We propose a tool, called DepClean, to analyze the presence of bloated dependencies in Maven artifacts. We ana- lyze 9; 639 Java artifacts hosted on Maven Central, which include a total of 723; 444 dependency relationships. Our key result is that 75:1% of the analyzed dependency relationships are bloated. In other words, it is feasible to reduce the number of dependencies of Maven artifacts up to 1=4 of its current count. We also perform a qualitative study with 30 notable open-source projects. Our results indicate that developers pay attention to their dependencies and are willing to remove bloated dependencies: 18/21 answered pull requests were accepted and merged by developers, removing 131 dependencies in total. -

Developer Tool Guide
Informatica® 10.2.1 Developer Tool Guide Informatica Developer Tool Guide 10.2.1 May 2018 © Copyright Informatica LLC 2009, 2019 This software and documentation are provided only under a separate license agreement containing restrictions on use and disclosure. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without prior consent of Informatica LLC. Informatica, the Informatica logo, PowerCenter, and PowerExchange are trademarks or registered trademarks of Informatica LLC in the United States and many jurisdictions throughout the world. A current list of Informatica trademarks is available on the web at https://www.informatica.com/trademarks.html. Other company and product names may be trade names or trademarks of their respective owners. U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation is subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License. Portions of this software and/or documentation are subject to copyright held by third parties. Required third party notices are included with the product. The information in this documentation is subject to change without notice. If you find any problems in this documentation, report them to us at [email protected]. -

VECTORWISE Simply FAST
VECTORWISE Simply FAST A technical whitepaper TABLE OF CONTENTS: Introduction .................................................................................................................... 1 Uniquely fast – Exploiting the CPU ................................................................................ 2 Exploiting Single Instruction, Multiple Data (SIMD) .................................................. 2 Utilizing CPU cache as execution memory ............................................................... 3 Other CPU performance features ............................................................................. 3 Leveraging industry best practices ................................................................................ 4 Optimizing large data scans ...................................................................................... 4 Column-based storage .............................................................................................. 4 VectorWise’s hybrid column store ........................................................................ 5 Positional Delta Trees (PDTs) .............................................................................. 5 Data compression ..................................................................................................... 6 VectorWise’s innovative use of data compression ............................................... 7 Storage indexes ........................................................................................................ 7 Parallel -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Oracle Big Data SQL Release 4.1
ORACLE DATA SHEET Oracle Big Data SQL Release 4.1 The unprecedented explosion in data that can be made useful to enterprises – from the Internet of Things, to the social streams of global customer bases – has created a tremendous opportunity for businesses. However, with the enormous possibilities of Big Data, there can also be enormous complexity. Integrating Big Data systems to leverage these vast new data resources with existing information estates can be challenging. Valuable data may be stored in a system separate from where the majority of business-critical operations take place. Moreover, accessing this data may require significant investment in re-developing code for analysis and reporting - delaying access to data as well as reducing the ultimate value of the data to the business. Oracle Big Data SQL enables organizations to immediately analyze data across Apache Hadoop, Apache Kafka, NoSQL, object stores and Oracle Database leveraging their existing SQL skills, security policies and applications with extreme performance. From simplifying data science efforts to unlocking data lakes, Big Data SQL makes the benefits of Big Data available to the largest group of end users possible. KEY FEATURES Rich SQL Processing on All Data • Seamlessly query data across Oracle Oracle Big Data SQL is a data virtualization innovation from Oracle. It is a new Database, Hadoop, object stores, architecture and solution for SQL and other data APIs (such as REST and Node.js) on Kafka and NoSQL sources disparate data sets, seamlessly integrating data in Apache Hadoop, Apache Kafka, • Runs all Oracle SQL queries without modification – preserving application object stores and a number of NoSQL databases with data stored in Oracle Database. -

Hybrid Transactional/Analytical Processing: a Survey
Hybrid Transactional/Analytical Processing: A Survey Fatma Özcan Yuanyuan Tian Pınar Tözün IBM Resarch - Almaden IBM Research - Almaden IBM Research - Almaden [email protected] [email protected] [email protected] ABSTRACT To understand HTAP, we first need to look into OLTP The popularity of large-scale real-time analytics applications and OLAP systems and how they progressed over the years. (real-time inventory/pricing, recommendations from mobile Relational databases have been used for both transaction apps, fraud detection, risk analysis, IoT, etc.) keeps ris- processing as well as analytics. However, OLTP and OLAP ing. These applications require distributed data manage- systems have very different characteristics. OLTP systems ment systems that can handle fast concurrent transactions are identified by their individual record insert/delete/up- (OLTP) and analytics on the recent data. Some of them date statements, as well as point queries that benefit from even need running analytical queries (OLAP) as part of indexes. One cannot think about OLTP systems without transactions. Efficient processing of individual transactional indexing support. OLAP systems, on the other hand, are and analytical requests, however, leads to different optimiza- updated in batches and usually require scans of the tables. tions and architectural decisions while building a data man- Batch insertion into OLAP systems are an artifact of ETL agement system. (extract transform load) systems that consolidate and trans- For the kind of data processing that requires both ana- form transactional data from OLTP systems into an OLAP lytics and transactions, Gartner recently coined the term environment for analysis. Hybrid Transactional/Analytical Processing (HTAP).