An Empirical Study Into COBOL Type Inferencing*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

By Kumari Priyadarshani 22-04-2020 BBM 3Rd Year Variables in C a Variable Is a Name of the Memory Location. It Is Used to Store Data
By Kumari priyadarshani 22-04-2020 BBM 3rd year Variables in C A variable is a name of the memory location. It is used to store data. Its value can be changed, and it can be reused many times. It is a way to represent memory location through symbol so that it can be easily identified. Let's see the syntax to declare a variable: type variable_list; The example of declaring the variable is given below: int a; float b; char c; Here, a, b, c are variables. The int, float, char are the data types. We can also provide values while declaring the variables as given below: int a=10,b=20;//declaring 2 variable of integer type float f=20.8; char c='A'; Rules for defining variables A variable can have alphabets, digits, and underscore. A variable name can start with the alphabet, and underscore only. It can't start with a digit. No whitespace is allowed within the variable name. A variable name must not be any reserved word or keyword, e.g. int, float, etc. Valid variable names: int a; int _ab; int a30; Invalid variable names: int 2; int a b; int long; Types of Variables in C There are many types of variables in c: local variable global variable static variable automatic variable external variable 1)Local Variable A variable that is declared inside the function or block is called a local variable. It must be declared at the start of the block. void function1(){ int x=10;//local variable } You must have to initialize the local variable before it is used. -

XL C/C++: Language Reference About This Document
IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 Note Before using this information and the product it supports, read the information in “Notices” on page 63. First edition This edition applies to IBM XL C/C++ for Linux, V16.1.1 (Program 5765-J13, 5725-C73) and to all subsequent releases and modifications until otherwise indicated in new editions. Make sure you are using the correct edition for the level of the product. © Copyright IBM Corporation 1998, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document ......... v Chapter 4. IBM extension features ... 11 Who should read this document........ v IBM extension features for both C and C++.... 11 How to use this document.......... v General IBM extensions ......... 11 How this document is organized ....... v Extensions for GNU C compatibility ..... 15 Conventions .............. v Extensions for vector processing support ... 47 Related information ........... viii IBM extension features for C only ....... 56 Available help information ........ ix Extensions for GNU C compatibility ..... 56 Standards and specifications ........ x Extensions for vector processing support ... 58 Technical support ............ xi IBM extension features for C++ only ...... 59 How to send your comments ........ xi Extensions for C99 compatibility ...... 59 Extensions for C11 compatibility ...... 59 Chapter 1. Standards and specifications 1 Extensions for GNU C++ compatibility .... 60 Chapter 2. Language levels and Notices .............. 63 language extensions ......... 3 Trademarks ............. -

Language Reference
Enterprise PL/I for z/OS Version 5 Release 3 Language Reference IBM SC27-8940-02 Note Before using this information and the product it supports, be sure to read the general information under “Notices” on page 613. Third Edition (September 2019) This edition applies to Enterprise PL/I for z/OS Version 5 Release 3 (5655-PL5), and IBM Developer for z/OS PL/I for Windows (former Rational Developer for System z PL/I for Windows), Version 9.1, and to any subsequent releases of any of these products until otherwise indicated in new editions or technical newsletters. Make sure you are using the correct edition for the level of the product. Order publications through your IBM® representative or the IBM branch office serving your locality. Publications are not stocked at the address below. A form for readers' comments is provided at the back of this publication. If the form has been removed, address your comments to: IBM Corporation, Department H150/090 555 Bailey Ave. San Jose, CA, 95141-1099 United States of America When you send information to IBM, you grant IBM a nonexclusive right to use or distribute the information in any way it believes appropriate without incurring any obligation to you. Because IBM Enterprise PL/I for z/OS supports the continuous delivery (CD) model and publications are updated to document the features delivered under the CD model, it is a good idea to check for updates once every three months. © Copyright International Business Machines Corporation 1999, 2019. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. -

Fundamentals of Programming Session 12
Fundamentals of Programming Session 12 Instructor: Maryam Asadi Email: [email protected] 1 Fall 2018 These slides have been created using Deitel’s slides Sharif University of Technology Outlines Random Number Generation … Storage Classes Scope Rules 2 Random Number Generation … The values produced directly by rand are always in the range: 0 rand() RAND_MAX As you know, the following statement simulates rolling a six- sided die: face = 1 + rand() % 6; This statement always assigns an integer value (at random) to the variable face in the range 1 face 6. The width of this range (i.e., the number of consecutive integers in the range) is 6 and the starting number in the range is 1. 3 Random Number Generation … Referring to the preceding statement, we see that the width of the range is determined by the number used to scale rand with the remainder operator (i.e., 6), and the starting number of the range is equal to the number (i.e., 1) that is added to rand % 6. We can generalize this result as follows n = a + rand() % b; where a is the shifting value (which is equal to the first number in the desired range of consecutive integers) and b is the scaling factor (which is equal to the width of the desired range of consecutive integers). 4 Random Number Generation … 5 Random Number Generation … 6 Random Number Generation … Notice that a different sequence of random numbers is obtained each time the program is run, provided that a different seed is supplied. To randomize without entering a seed each time, use a statement like srand( time( NULL ) ); This causes the computer to read its clock to obtain the value for the seed automatically. -

PRU Optimizing C/C++ Compiler User's Guide
PRU Optimizing C/C++ Compiler v2.3 User's Guide Literature Number: SPRUHV7C July 2014–Revised July 2018 Contents Preface ........................................................................................................................................ 8 1 Introduction to the Software Development Tools.................................................................... 11 1.1 Software Development Tools Overview ................................................................................. 12 1.2 Compiler Interface.......................................................................................................... 13 1.3 ANSI/ISO Standard ........................................................................................................ 14 1.4 Output Files ................................................................................................................. 14 1.5 Utilities ....................................................................................................................... 14 2 Using the C/C++ Compiler ................................................................................................... 15 2.1 About the Compiler......................................................................................................... 16 2.2 Invoking the C/C++ Compiler ............................................................................................. 16 2.3 Changing the Compiler's Behavior with Options ....................................................................... 17 2.3.1 Linker -
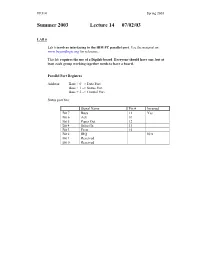
Lecture 14 07/02/03
EE314 Spring 2003 Summer 2003 Lecture 14 07/02/03 LAB 6 Lab 6 involves interfacing to the IBM PC parallel port. Use the material on www.beyondlogic.org for reference. This lab requires the use of a Digilab board. Everyone should have one, but at least each group working together needs to have a board. Parallel Port Registers Address: Base + 0 => Data Port Base + 1 => Status Port Base + 2 => Control Port Status port bits: Signal Name Pin # Inverted Bit 7 Busy 11 Yes Bit 6 Ack 10 Bit 5 Paper Out 12 Bit 4 Select In 13 Bit 3 Error 15 Bit 2 IRQ N/A Bit 1 Reserved Bit 0 Reserved EE314 Spring 2003 Control Port Bits Signal Name Pin # Inverted Bit 7 Unused Bit 6 Unused Bit 5 Enable bi-directional port N/A Bit 4 Enable IRQ via ACK line N/A Bit 3 Select Printer 17 Yes Bit 2 Initialize Printer (Reset) 16 No Bit 1 Auto Linefeed 14 Yes Bit 0 Strobe 1 Yes Digilab Board Initialization: A program will be provided on the lab machines that is used to initialize the Digilab boards. It is called cfglab6.exe, and will be placed in a directory on the path, so that it can be executed simply by typing its name anywhere from a DOS prompt. C Programming Language Semantics Parameter passing to procedures: C is ‘call by value’ for scalar variables, ‘call by reference’ for vector variables. ‘Call by value’ means that the value of the parameter is pushed onto the stack and passed to the procedure as the parameter. -

Automatic Transformation of Iterative Loops Into Recursive Methods$ (Extended Version)
Automatic Transformation of Iterative Loops into Recursive MethodsI (extended version) David Insa, Josep Silva∗ Departament de Sistemes Inform`aticsi Computaci´o Universitat Polit`ecnica de Val`encia Camino de Vera s/n E-46022 Valencia, Spain. Abstract Context: In software engineering, taking a good election between recursion and iteration is essential because their efficiency and maintenance are different. In fact, developers often need to transform iteration into recursion (e.g., in debugging, to decompose the call graph into iterations); thus, it is quite surprising that there does not exist a public transformation from loops to recursion that can be used in industrial projects (i.e., it is automatic, it handles all kinds of loops, it considers exceptions, etc.). Objective: This article describes an industrial algorithm implemented as a Java library able to automatically transform iterative loops into equivalent recursive methods. The transformation is described for the programming language Java, but it is general enough as to be adapted to many other languages that allow iteration and recursion. Method: We describe the changes needed to transform loops of types while/do/for/foreach into recursion. We provide a transformation schema for each kind of loop. Results: Our algorithm is the first public transformation that can be used in industrial projects and faces the whole Java language (i.e., it is fully automatic, it handles all kinds of loops, it considers exceptions, it treats the control statements break and continue, it handles loop labels, it is able to transform any number of nested loops, etc.). This is particularly interesting because some of these features are missing in all previous work, probably, due to the complexity that their mixture introduce in the transformation. -

C for Java Programmers
C for Java Programmers George Ferguson Summer 2016 (Updated Summer 2021) 2 Contents 1 Introduction7 2 Overview of Java and C9 2.1 What’s The Same?.........................9 2.2 What’s Different?.......................... 10 3 Development and Execution 11 3.1 Development and Execution in Java and C............. 11 3.2 Setting Up Your Development Environment............ 14 3.3 Writing Your First C Program................... 16 3.4 Compiling Your First C Program.................. 17 4 Basic Expressions and Statements 21 4.1 Comments.............................. 21 4.2 Primitive Types........................... 22 4.3 Producing Output.......................... 23 4.4 Operators and Expressions..................... 24 4.5 Variables and Assigment...................... 26 4.6 Arrays................................ 27 4.7 Strings................................ 29 3 4 CONTENTS 5 Control Flow 31 5.1 Conditional Statements....................... 31 5.2 Iteration Statements......................... 32 5.3 Other Control Flow Statements................... 33 6 Functions 35 6.1 Function Parameters and Arguments................ 36 6.2 Function Declarations........................ 37 7 Structured Types 39 8 Memory Management 43 8.1 Variables, Addresses, and Pointers................. 43 8.2 Passing Arguments by Reference.................. 46 8.3 Memory Allocation......................... 48 8.4 Dynamic Memory Allocation in Java................ 49 8.5 Dynamic Memory Allocation in C................. 50 8.6 Dynamic Arrays........................... 54 8.7 Dynamic Data Structures...................... 56 8.8 Function Pointers.......................... 64 9 Defining New Types 69 10 Sharing Code: Files and Libraries 73 10.1 The C Preprocessor......................... 73 10.2 Separate Compilation, Libraries, and Linking........... 75 10.3 Standard System Libraries..................... 76 CONTENTS 5 10.4 Project Development........................ 77 10.5 Building Larger C Programs.................... 79 11 Debugging a C Program 83 11.1 Debuggers............................. -

Function Literals and Value Closures Proposal for C23
ISO/IEC JTC 1/SC 22/WG14 N2675 v2 WG 21, SG 22 P2303R1 2021-3-1 Function literals and value closures proposal for C23 Jens Gustedt INRIA and ICube, Universit´ede Strasbourg, France We propose the inclusion of simple lambda expressions into the C standard. We build on a slightly restricted syntax of that feature in C++. In particular, they only have immutable value captures, fully specified pa- rameter types, and, based on N2674, the return type is inferred from return statements. This is part of a series of papers for the improvement of type-generic programming in C that has been introduced in N2638. Follow-up papers N2634 and N2635 will extend this feature with auto parameter types and lvalue captures, respectively. Changes: v.2. this document, integrating feedback from the WG14 reflector | add function literals to the RHS of assignment and cast if the target type is a function pointer | make it clear that lambda objects can only be formed by auto definitions | cleanup of the relationship between lambdas and VM types | be more precise on the sequencing of lambda evaluations and function calls | affect the attributes of a lambda expression to the lambda value | integrate <stdarg.h> and lambdas | integrate <setjmp.h> and lambdas | integrate lambdas with the rest of the library clause I. MOTIVATION In N2638 it is argued that the features presented in this paper are useful in a more general context, namely for the improvement of type-generic programming in C. We will not repeat this argumentation here, but try to motivate the introduction of lambdas as a stand-alone addition to C. -

Embedded SQL/COBOL Programmers Guide Company
PUBLIC SDK for SAP Adaptive Server Enterprise 16.0 SP03 PL07 Document Version: 1.0 – 2019-06-06 Embedded SQL/COBOL Programmers Guide company. All rights reserved. All rights company. affiliate THE BEST RUN 2019 SAP SE or an SAP SE or an SAP SAP 2019 © Content 1 Introduction ................................................................7 1.1 Embedded SQL Features........................................................7 1.2 Transact-SQL Support in Embedded SQL ............................................8 1.3 Getting Started.............................................................. 8 Using the Examples.........................................................9 Backward Compatibility ......................................................9 1.4 Creating and Running an Embedded SQL Program.....................................10 1.5 How the Precompiler Processes Your Applications..................................... 11 Multiple Embedded SQL Source Files............................................11 Precompiler-generated Files ..................................................12 Group Element Referencing...................................................12 2 General Information.........................................................13 2.1 Five Tasks of an Embedded SQL Program........................................... 13 Simplified Embedded SQL Program.............................................14 2.2 General Rules for Embedded SQL.................................................14 Statement Placement ......................................................15 -

The C Language Reference Manual
The C Language Reference Manual Stephen A. Edwards Columbia University Fall 2010 Katsushika Hokusai, In the Hollow of a Wave off the Coast at Kanagawa, 1827 Language Design Issues Syntax: how programs look Ï Names and reserved words Ï Instruction formats Ï Grouping Semantics: what programs mean Ï Model of computation: sequential, concurrent Ï Control and data flow Ï Types and data representation Part I The History of C C History Developed between 1969 and 1973 along with Unix Due mostly to Dennis Ritchie Designed for systems programming Ï Operating systems Ï Utility programs Ï Compilers Ï Filters Evolved from B, which evolved from BCPL BCPL Martin Richards, Cambridge, 1967 Typeless Ï Everything a machine word (n-bit integer) Ï Pointers (addresses) and integers identical Memory: undifferentiated array of words Natural model for word-addressed machines Local variables depend on frame-pointer-relative addressing: no dynamically-sized automatic objects Strings awkward: Routines expand and pack bytes to/from word arrays BCPL Example: 8 Queens GET "libhdr" GLOBAL { count:ug; all } LET try(ld, row, rd) BE TEST row=all THEN count := count + 1 ELSE { LET poss = all & ~(ld | row | rd) WHILE poss DO { LET p = poss &-poss poss := poss - p try(ld+p << 1, row+p, rd+p >> 1) } } LET start() = VALOF { all := 1 FOR i = 1 TO 16 DO { count := 0 try(0, 0, 0) writef("Number of solutions to %i2-queens is %i7*n", i, count) all := 2*all + 1 } RESULTIS 0 } C History Original machine, a DEC PDP-11, was very small: 24K bytes of memory, 12K used for operating system Written when computers were big, capital equipment Group would get one, develop new language, OS C History Many language features designed to reduce memory Ï Forward declarations required for everything Ï Designed to work in one pass: must know everything Ï No function nesting PDP-11 was byte-addressed Ï Now standard Ï Meant BCPL’s word-based model was insufficient Euclid’s Algorithm in C int gcd(int m, int n) { “New syle” function int r; declaration lists number and while ((r = m % n) != 0) { type of arguments. -

High Integrity C++ Version
Coding Standard Version 4.0 www.codingstandard.com 3 October 2013 Programming Research Ltd Mark House - 9/11 Queens Road - Hersham - Surrey KT12 5LU - United Kingdom Tel: +44 (0) 1932 888 080 - Fax: +44 (0) 1932 888 081 [email protected] www.programmingresearch.com Registered in England No. 2844401 © 2013 Programming Research Ltd Contents Contents 0 Introduction 7 0.1 Typographical Conventions.........................................7 0.2 Escalation policy...............................................7 0.3 Base Standard and Policy..........................................8 0.3.1 ISO Standard C++..........................................8 0.3.2 Statically detectable restrictions...................................8 0.3.3 Examples...............................................8 0.4 Basis of requirements............................................8 0.5 Rule Enforcement..............................................8 0.6 Deviations...................................................9 0.7 Glossary....................................................9 1 General 10 1.1 Implementation compliance......................................... 10 1.1.1 Ensure that code complies with the 2011 ISO C++ Language Standard............ 10 1.2 Redundancy................................................. 10 1.2.1 Ensure that all statements are reachable............................. 10 1.2.2 Ensure that no expression or sub-expression is redundant.................... 11 1.3 Deprecated features............................................. 12 1.3.1 Do not