Implementation and Performance Analysis of Graphql Schema Delegation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Autonomous Surfer
Renée Ridgway The Autonomous Surfer CAIS Report Fellowship Mai bis Oktober 2018 GEFÖRDERT DURCH RIDGWAY The Autonomous Surfer Research Questions The Autonomous Surfer endeavoured to discover the unknown unknowns of alternative search through the following research questions: What are the alternatives to Google search? What are their hidden revenue models, even if they do not collect user data? How do they deliver divergent (and qualitative) results or knowledge? What are the criteria that determine ranking and relevance? How do p2p search engines such as YaCy work? Does it deliver alternative results compared to other search engines? Is there still a movement for a larger, public index? Can there be serendipitous search, which is the ability to come across books, articles, images, information, objects, and so forth, by chance? Aims and Projected Results My PhD research investigates Google search – its early development, its technological innovation, its business model of the past 20 years and how it works now. Furthermore, I have experimented with Tor (The Onion Router) in order to find out if I could be anonymous online, and if so, would I receive diver- gent results from Google with the same keywords. For my fellowship at CAIS I decided to first research search engines that were incorporated into the Tor browser as default (Startpage, Disconnect) or are the default browser now (DuckDuckGo). I then researched search engines in my original CAIS proposal that I had come across in my PhD but hadn’t had the time to research; some are from the Society of the Query Reader (2014) and others I found en route or on colleagues’ suggestions. -

About Garlic and Onions a Little Journey…
About Garlic and Onions A little journey… Tobias Mayer, Technical Solutions Architect BRKSEC-2011 Cisco Webex Teams Questions? Use Cisco Webex Teams to chat with the speaker after the session How 1 Find this session in the Cisco Events Mobile App 2 Click “Join the Discussion” 3 Install Webex Teams or go directly to the team space 4 Enter messages/questions in the team space BRKSEC-2011 © 2020 Cisco and/or its affiliates. All rights reserved. Cisco Public 3 About Garlic and Onions We are all looking for privacy on the internet, for one or the other reason. This Session is about some technologies you can use to anonymise your network traffic, such as Tor (The Onion Router). The first part will give an introduction and explain the underlaying technology of Tor. We will take look at how you can not only use the Tor browser for access but also how the Tor network is working. We will learn how you can establish a Tor session and how we can find hidden websites and give examples of some websites...So we will enter the Darknet together. Beside Tor, we will also take a quick look at other techniques like I2P (Garlic Routing). In the last section we will make a quick sanity check what security technologies we can use to (maybe) detect such traffic in the network. This presentation is aimed at everyone who likes to learn about anonymization techniques and have a little bit of fun in the Darknet. BRKSEC-2011 © 2020 Cisco and/or its affiliates. All rights reserved. -

BRKSEC-2011.Pdf
#CLUS About Garlic and Onions A little journey… Tobias Mayer, Technical Solutions Architect BRKSEC-2011 #CLUS Me… CCIE Security #14390, CISSP & Motorboat driving license… Working in Content Security & TLS Security tmayer{at}cisco.com Writing stuff at “blogs.cisco.com” #CLUS BRKSEC-2011 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 3 Agenda • Why anonymization? • Using Tor (Onion Routing) • How Tor works • Introduction to Onion Routing • Obfuscation within Tor • Domain Fronting • Detect Tor • I2P – Invisible Internet Project • Introduction to Garlic Routing • Conclusion #CLUS BRKSEC-2011 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 4 Cisco Webex Teams Questions? Use Cisco Webex Teams (formerly Cisco Spark) to chat with the speaker after the session How 1 Find this session in the Cisco Events App 2 Click “Join the Discussion” 3 Install Webex Teams or go directly to the team space 4 Enter messages/questions in the team space Webex Teams will be moderated cs.co/ciscolivebot#BRKSEC-2011 by the speaker until June 18, 2018. #CLUS © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 5 Different Intentions Hide me from Government! Hide me from ISP! Hide me from tracking! Bypass Corporate Bypass Country Access Hidden policies restrictions (Videos…) Services #CLUS BRKSEC-2011 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 6 Browser Identity Tracking does not require a “Name” Tracking is done by examining parameters your browser reveals https://panopticlick.eff.org #CLUS BRKSEC-2011 © 2018 Cisco and/or its affiliates. All rights reserved. Cisco Public 7 Proxies EPIC Browser #CLUS BRKSEC-2011 © 2018 Cisco and/or its affiliates. -

Unveiling the I2P Web Structure: a Connectivity Analysis
Unveiling the I2P web structure: a connectivity analysis Roberto Magan-Carri´ on,´ Alberto Abellan-Galera,´ Gabriel Macia-Fern´ andez´ and Pedro Garc´ıa-Teodoro Network Engineering & Security Group Dpt. of Signal Theory, Telematics and Communications - CITIC University of Granada - Spain Email: [email protected], [email protected], [email protected], [email protected] Abstract—Web is a primary and essential service to share the literature have analyzed the content and services offered information among users and organizations at present all over through this kind of technologies [6], [7], [2], as well as the world. Despite the current significance of such a kind of other relevant aspects like site popularity [8], topology and traffic on the Internet, the so-called Surface Web traffic has been estimated in just about 5% of the total. The rest of the dimensions [9], or classifying network traffic and darknet volume of this type of traffic corresponds to the portion of applications [10], [11], [12], [13], [14]. Web known as Deep Web. These contents are not accessible Two of the most popular darknets at present are The Onion by search engines because they are authentication protected Router (TOR; https://www.torproject.org/) and The Invisible contents or pages that are only reachable through the well Internet Project (I2P;https://geti2p.net/en/). This paper is fo- known as darknets. To browse through darknets websites special authorization or specific software and configurations are needed. cused on exploring and investigating the contents and structure Despite TOR is the most used darknet nowadays, there are of the websites in I2P, the so-called eepsites. -

The Onion Crate - Tor Hidden Service Index Protected Onions Add New
onion.to does not host this content; we are simply a conduit connecting Internet users to content hosted inside the Tor network.. onion.to does not provide any anonymity. You are strongly advised to download the Tor Browser Bundle and access this content over Tor. For more information see our website for more details and send us your feedback. hide Tor2web header Online onions The Onion Crate - Tor Hidden Service Index Protected onions Add new nethack3dzllmbmo.onion A public nethack server. j4ko5c2kacr3pu6x.onion/wordpress Paste or blog anonymously, no registration required. redditor3a2spgd6.onion/r/all Redditor. Sponsored links 5168 online onions. (Ctrl-f is your friend) A AUTOMATED PAYPAL AND CREDIT CARD MARKET 2222bbbeonn2zyyb.onion A Beginner Friendly Comprehensive Guide to Installing and Using A Safer yuxv6qujajqvmypv.onion A Coca Growlog rdkhliwzee2hetev.onion ==> https://freenet7cul5qsz6.onion.to/freenet:USK@yP9U5NBQd~h5X55i4vjB0JFOX P97TAtJTOSgquP11Ag,6cN87XSAkuYzFSq-jyN- 3bmJlMPjje5uAt~gQz7SOsU,AQACAAE/cocagrowlog/3/ A Constitution for the Few: Looking Back to the Beginning ::: Internati 5hmkgujuz24lnq2z.onion ==> https://freenet7cul5qsz6.onion.to/freenet:USK@kpFWyV- 5d9ZmWZPEIatjWHEsrftyq5m0fe5IybK3fg4,6IhxxQwot1yeowkHTNbGZiNz7HpsqVKOjY 1aZQrH8TQ,AQACAAE/acftw/0/ A Declaration of the Independence of Cyberspace ufbvplpvnr3tzakk.onion ==> https://freenet7cul5qsz6.onion.to/freenet:CHK@9NuTb9oavt6KdyrF7~lG1J3CS g8KVez0hggrfmPA0Cw,WJ~w18hKJlkdsgM~Q2LW5wDX8LgKo3U8iqnSnCAzGG0,AAIC-- 8/Declaration-Final%5b1%5d.html A Dumps Market -

– Ngi – the People Building the Internet of Tomorrow
– NGI – THE PEOPLE BUILDING THE INTERNET OF TOMORROW April 2020 NGI.eu The Next Generation Internet community is an incredibly talented group of people whose combined efforts are creating a human- centric Internet. With NGI, researchers and innovators run projects throughout Europe in a diverse array of subject areas from cryptography to federated identity and from search technology to secure operating systems. NGI comprises an ambitious research and innovation programme with more than €250 million EC funding between 2018-2020. Too often top Internet innovators are not associated with European funding because of perceived high barriers to entry. NGI has put in place the mechanisms to ensure that it attracts top talent by offering funding opportunities for accessible, small, focused and agile projects. €75 million directly support top Internet researchers and innovators through ‘cascade funding’ with simplified administrative procedures and a light, start-up and SME friendly application scheme. Read more about NGI’s expertise to select, fund mentor and coordinate next generation Internet projects. NGI equity-free funding offers innovators such as SMEs and start-ups a buffering opportunity, with vital resources to develop their innovative solutions. Each project receives an NGI grant, typically €50,000 – 200,000, which can significantly shorten the research cycle and time to market. Moreover, the NGI initiative bestows bridging opportunities facilitating inter-organizational networks, collaborations and the flow of knowledge and resources across organisations. NGI.eu 1 BLOCKCHAIN NGI funds projects on blockchain, peer-to-peer technology and decentralised ledger technology (DLT) through a Research and Innovation Action named LEDGER. Focus is on a variety of areas including health, economy, mobility, public services, energy and sustainability and open innovation. -
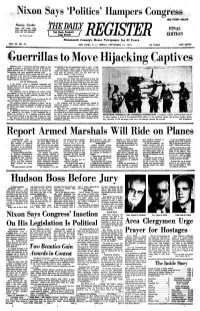
Hijacking Captives
ess. SEE STORY BELOW Sunny, Cooler Sunny and cooler today. Clear and quite cool tonight. THE FINAL Sunny and cool tomorrow. Bed Bank, Freehold , Loaf Branch (be DeUlU, Pi» ft EDITION Monmouth County's Home Newspaper for 92 Years VOt. 93, NO. 54 RED BANK, N. J., FRIDAY, SEPTEMBER 11, 1970 24 PAGES TEN CENTS Hijacking Captives GENEVA (AP) — Palestinian guerrillas appear to have unacceptable from the humanitarian point of view," it said. agreed to transfer all passengers and crew of the three hi- Meanwhile, the Popular Front called together the 147 jacked" jetliners from the Jordanian desert to Amman, the wqmen and children it had brought to Amman earlier in the International Bed Cross committee reported today. week from the hijacked planes and told them they all Committee President Marcel Navffle said he is "not 100 could leave Amman if they wanted to. per cent sure" of the news, but a message just received from ARAB. STATES JOIN its delegation on the spot indicates that agreement has been readied with the Palestinians. Earlier today the leftists Arab governments of Iraq and Syria joined the West in the campaign to secure the release SET UP DETONATOItS of the approximately 280 airline passengers and crew mem- A few minutes earlier a committee spokesman said bers. Four Western governments and Israel meanwhile re- tile'guerrillas had set up detonators to set off dynamite jected the Palestinians' plans to trade the Israelis among charges attached to the planes, with all the passengers and the hostages for Arab commandos held in Israel. The five crew still aboard. -

A Baker's Dozen of Tips for Be Er Web Searches
A Baker’s Dozen of Tips for Beer Web Searches Anne Burnett, J.D., M.L.I.S. University of Georgia School of Law Library Athens, Georgia Lawyers use the § ABA Tech Report 2019 web for legal § 90% use free online resources research either regularly or occasionally When to use free resources § If item(s) likely to be freely available § If starting with free & switching to When do subscription for supplemental lawyers use the material will save $$$ web for § If time spent on free doesn’t outweigh research? $$ spent on paid § Recent primary legal information § Government information What is free § Company and directory information web good for? § Information about individuals § Reference information and statistics § Comprehensive sites--collecting all relevant material, from all jurisdictions § High quality, reliable secondary sources What is not § Annotated codes, cases with available? headnotes § Sophisticated citator services, such as Shepard's or KeyCite § Older materials The Tips Use Quotation Marks • Phrase searching • “consumer protection” #1 Can I Quote You? • “John F. Kennedy” • Single word in precise form • “childcare” ≠ “child care” Space = AND Google and Bing recognize OR Minus sign excludes terms • RICO –Puerto #2 • Vikings –football –team Smooth Operators AROUND(x) – proximity operator • John AROUND(2) Kennedy • John F. Kennedy • John Fitzgerald Kennedy • John Kennedy • Kennedy, John F. Limit by • Domain: .edu, .org., .gov, .int, -.com, .de • File type: .pdf, .com, .ppt, .xls • Language #3 • Country Learn Your Limits • Last update -

Motori Di Ricerca E Portali, Dei
2 Repertorio Il testo è un repertorio di oltre 180 motori di ricerca e portali, dei escluse le piattaforme commerciali come Amazon, iTunes, ecc. motori I motori di ricerca sicuri e consigliati, quali SearX, Qwant, Startpage e DuckDuckGo, sono stati omessi, così come Google (analizzato esclusivamente per il carattere quasi monopolistico), in quanto di Repertorio dei trattati nel volume Motori di ricerca, Trovare informazioni in rete. ricer Strumenti per le ricerche sul web. Il catalogo è articolato per macro-aree tematiche relative alle ca. motori di ricerca possibili ricerche: privacy e sicurezza, tipologia di contenuti e T risultati, musica, video, foto, immagini, icone, eBook, documenti. r ovar Il capitolo primo tratta i motori di ricerca sicuri e a tutela della Trovare informazioni in rete privacy. e Il capitolo secondo riporta i motori di ricerca focalizzati sulla infor Strumenti per le ricerche sul web tipologia di contenuti e risultati. Un esempio sono CC Search, per la ricerca di contenuti multimediali non coperti da copyright, mazioni oppure FindSounds per l’individuazione di suoni in fonti aperte. I capitoli successivi hanno come oggetto le risorse per la ricerca di contenuti documentali e multimediali. Flavio Gallucci in Il capitolo terzo raccoglie le risorse per la ricerca di foto, immagini r e icone. TinEye merita attenzione per la tecnica di reverse image ete. search, ovvero la ricerca a partire dal caricamento di una foto. Strumenti Il capitolo quarto elenca strumenti e risorse per la ricerca di brani musicali, l’ascolto di musica in streaming e l’individuazione di eventi. Il capitolo quinto propone i portali dedicati alla ricerca di video. -

University of Oklahoma Graduate College
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE RELEVANCE AND PRIVACY IMPROVEMENTS TO THE YACY DECENTRALIZED WEB SEARCH ENGINE A THESIS SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE By JEREMY RAND Norman, Oklahoma 2018 RELEVANCE AND PRIVACY IMPROVEMENTS TO THE YACY DECENTRALIZED WEB SEARCH ENGINE A THESIS APPROVED FOR THE SCHOOL OF COMPUTER SCIENCE BY Dr. Dean Hougen, Chair Dr. Qi Cheng Dr. Sridhar Radhakrishnan © Copyright by JEREMY RAND 2018 This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License. To view a copy of this license, visit https://creativecommons.org/licenses/by-sa/4.0/ or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. \. dedicated to all the people who are out there unfucking the Internet." { Giordano Nanni Historian, Journalist, Founder of The Juice Media, Co-Creator of Juice Rap News. https://www.youtube.com/watch?v=5b5W_U8RBDI Acknowledgements We'd like to thank Ryan Castellucci and midnightmagic for some fascinating and productive discussions regarding anti-Sybil mechanisms. iv Contents Acknowledgements iv Abstract vii 1 Introduction to Decentralized Web Search 1 1.1 Background on Search Engines, Civil Liberties, and Decentralization . 1 1.2 Motivation for Decentralized Web Search ................ 3 1.2.1 Censorship Resistance ...................... 3 1.2.2 Privacy .............................. 3 1.2.3 Decentralization .......................... 4 1.2.4 Transparency ........................... 4 1.2.5 Software Freedom ......................... 5 1.3 Our Contributions to YaCy ....................... 5 2 Related Work 6 2.1 Decentralized Web Search ........................ 6 2.2 Supervised Learning ........................... 7 3 Learning-Related Relevance Improvements 8 3.1 Ranking Transparency ......................... -

Browser En Complete.Pdf
EXPLORE You are tracked through your browser in two main ways: third party trackers (cookies etc), which are embedded in most websites; and through your unique browser fingerprint. See which third party trackers are monitoring your online activity, using Lightbeam (Firefox). Test the uniqueness of your browser, using Panopticlick. Use multiple browsers (Firefox, Chrome, Safari) for different purposes. This makes it a little harder to track you. Consider using the Tor Browser Bundle for increased online anonymity. Please check the legality of using Tor in your country. Choose a search engine that does not track and profile you (DuckDuckGo, startpage, Ixquick or Searx). Block pop-up windows. Set your browser to auto-delete your history on closing. Don't save your passwords in your browser. Restrict permissions for cookies. Check the Do Not Track box, to send websites requests to disable their trackers. Use Private Window (Firefox), or Incognito Mode (Chromium & Chrome). Install a few key privacy-enhancing add-ons/ extensions: HTTPS Everywhere encrypts your communications with many major websites. Privacy Badger stops advertisers and trackers from monitoring your online behaviour. NoScript blocks banners and pop-up windows. Regularly check for browser and add-on/ extension updates. Keep your browser history lean and clean – clear it regularly. Regularly delete cookies. Regularly review your browser settings. Log out from sites before you close your browser. . -

2000-Deep-Web-Dark-Web-Links-2016 On: March 26, 2016 In: Deep Web 5 Comments
Tools4hackers -This You website may uses cookies stop to improve me, your experience. but you We'll assume can't you're ok stop with this, butus you all. can opt-out if you wish. Accept Read More 2000-deep-web-dark-web-links-2016 on: March 26, 2016 In: Deep web 5 Comments 2000 deep web links The Dark Web, Deepj Web or Darknet is a term that refers specifically to a collection of websites that are publicly visible, but hide the IP addresses of the servers that run them. Thus they can be visited by any web user, but it is very difficult to work out who is behind the sites. And you cannot find these sites using search engines. So that’s why we have made this awesome list of links! NEW LIST IS OUT CLICK HERE A warning before you go any further! Once you get into the Dark Web, you *will* be able to access those sites to which the tabloids refer. This means that you could be a click away from sites selling drugs and guns, and – frankly – even worse things. this article is intended as a guide to what is the Dark Web – not an endorsement or encouragement for you to start behaving in illegal or immoral behaviour. 1. Xillia (was legit back in the day on markets) http://cjgxp5lockl6aoyg.onion 2. http://cjgxp5lockl6aoyg.onion/worldwide-cardable-sites-by-alex 3. http://cjgxp5lockl6aoyg.onion/selling-paypal-accounts-with-balance-upto-5000dollars 4. http://cjgxp5lockl6aoyg.onion/cloned-credit-cards-free-shipping 5. 6. ——————————————————————————————- 7.