Novel Antiviral Interferon Sensitive Genes Unveiled by Correlation-Driven Gene Selection and Integrated Systems Biology Approaches
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Anti-ARL4A Antibody (ARG41291)
Product datasheet [email protected] ARG41291 Package: 100 μl anti-ARL4A antibody Store at: -20°C Summary Product Description Rabbit Polyclonal antibody recognizes ARL4A Tested Reactivity Hu, Ms, Rat Tested Application ICC/IF, IHC-P Host Rabbit Clonality Polyclonal Isotype IgG Target Name ARL4A Antigen Species Human Immunogen Recombinant fusion protein corresponding to aa. 121-200 of Human ARL4A (NP_001032241.1). Conjugation Un-conjugated Alternate Names ARL4; ADP-ribosylation factor-like protein 4A Application Instructions Application table Application Dilution ICC/IF 1:50 - 1:200 IHC-P 1:50 - 1:200 Application Note * The dilutions indicate recommended starting dilutions and the optimal dilutions or concentrations should be determined by the scientist. Calculated Mw 23 kDa Properties Form Liquid Purification Affinity purified. Buffer PBS (pH 7.3), 0.02% Sodium azide and 50% Glycerol. Preservative 0.02% Sodium azide Stabilizer 50% Glycerol Storage instruction For continuous use, store undiluted antibody at 2-8°C for up to a week. For long-term storage, aliquot and store at -20°C. Storage in frost free freezers is not recommended. Avoid repeated freeze/thaw cycles. Suggest spin the vial prior to opening. The antibody solution should be gently mixed before use. Note For laboratory research only, not for drug, diagnostic or other use. www.arigobio.com 1/2 Bioinformation Gene Symbol ARL4A Gene Full Name ADP-ribosylation factor-like 4A Background ADP-ribosylation factor-like 4A is a member of the ADP-ribosylation factor family of GTP-binding proteins. ARL4A is similar to ARL4C and ARL4D and each has a nuclear localization signal and an unusually high guaninine nucleotide exchange rate. -
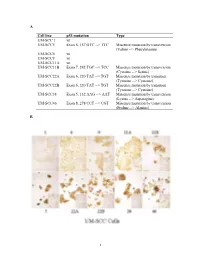
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Regulation of Neuronal Gene Expression and Survival by Basal NMDA Receptor Activity: a Role for Histone Deacetylase 4
The Journal of Neuroscience, November 12, 2014 • 34(46):15327–15339 • 15327 Cellular/Molecular Regulation of Neuronal Gene Expression and Survival by Basal NMDA Receptor Activity: A Role for Histone Deacetylase 4 Yelin Chen,1 Yuanyuan Wang,1 Zora Modrusan,3 Morgan Sheng,1 and Joshua S. Kaminker1,2 Departments of 1Neuroscience, 2Bioinformatics and Computational Biology, and 3Molecular Biology, Genentech Inc., South San Francisco, California 94080 Neuronal gene expression is modulated by activity via calcium-permeable receptors such as NMDA receptors (NMDARs). While gene expression changes downstream of evoked NMDAR activity have been well studied, much less is known about gene expression changes that occur under conditions of basal neuronal activity. In mouse dissociated hippocampal neuronal cultures, we found that a broad NMDAR antagonist, AP5, induced robust gene expression changes under basal activity, but subtype-specific antagonists did not. While some of the gene expression changes are also known to be downstream of stimulated NMDAR activity, others appear specific to basal NMDARactivity.ThegenesalteredbyAP5treatmentofbasalcultureswereenrichedforpathwaysrelatedtoclassIIahistonedeacetylases (HDACs), apoptosis, and synapse-related signaling. Specifically, AP5 altered the expression of all three class IIa HDACs that are highly expressed in the brain, HDAC4, HDAC5, and HDAC9, and also induced nuclear accumulation of HDAC4. HDAC4 knockdown abolished a subset of the gene expression changes induced by AP5, and led to neuronal death under -

Glucose-Induced Changes in Gene Expression in Human Pancreatic Islets: Causes Or Consequences of Chronic Hyperglycemia
Diabetes Volume 66, December 2017 3013 Glucose-Induced Changes in Gene Expression in Human Pancreatic Islets: Causes or Consequences of Chronic Hyperglycemia Emilia Ottosson-Laakso,1 Ulrika Krus,1 Petter Storm,1 Rashmi B. Prasad,1 Nikolay Oskolkov,1 Emma Ahlqvist,1 João Fadista,2 Ola Hansson,1 Leif Groop,1,3 and Petter Vikman1 Diabetes 2017;66:3013–3028 | https://doi.org/10.2337/db17-0311 Dysregulation of gene expression in islets from patients In patients with type 2 diabetes (T2D), islet function de- with type 2 diabetes (T2D) might be causally involved clines progressively. Although the initial pathogenic trigger in the development of hyperglycemia, or it could develop of impaired b-cell function is still unknown, elevated glu- as a consequence of hyperglycemia (i.e., glucotoxicity). cose levels are known to further aggravate b-cell function, a To separate the genes that could be causally involved condition referred to as glucotoxicity, which can stimulate in pathogenesis from those likely to be secondary to hy- apoptosis and lead to reduced b-cell mass (1–5). Prolonged perglycemia, we exposed islets from human donors to exposure to hyperglycemia also can induce endoplasmic re- ISLET STUDIES normal or high glucose concentrations for 24 h and ana- ticulum (ER) stress and production of reactive oxygen spe- fi lyzed gene expression. We compared these ndings with cies (6), which can further impair islet function and thereby gene expression in islets from donors with normal glucose the ability of islets to secrete the insulin needed to meet the tolerance and hyperglycemia (including T2D). The genes increased demands imposed by insulin resistance and obe- whose expression changed in the same direction after sity (7). -

Supplement 1 Microarray Studies
EASE Categories Significantly Enriched in vs MG vs vs MGC4-2 Pt1-C vs C4-2 Pt1-C UP-Regulated Genes MG System Gene Category EASE Global MGRWV Pt1-N RWV Pt1-N Score FDR GO Molecular Extracellular matrix cellular construction 0.0008 0 110 genes up- Function Interpro EGF-like domain 0.0009 0 regulated GO Molecular Oxidoreductase activity\ acting on single dono 0.0015 0 Function GO Molecular Calcium ion binding 0.0018 0 Function Interpro Laminin-G domain 0.0025 0 GO Biological Process Cell Adhesion 0.0045 0 Interpro Collagen Triple helix repeat 0.0047 0 KEGG pathway Complement and coagulation cascades 0.0053 0 KEGG pathway Immune System – Homo sapiens 0.0053 0 Interpro Fibrillar collagen C-terminal domain 0.0062 0 Interpro Calcium-binding EGF-like domain 0.0077 0 GO Molecular Cell adhesion molecule activity 0.0105 0 Function EASE Categories Significantly Enriched in Down-Regulated Genes System Gene Category EASE Global Score FDR GO Biological Process Copper ion homeostasis 2.5E-09 0 Interpro Metallothionein 6.1E-08 0 Interpro Vertebrate metallothionein, Family 1 6.1E-08 0 GO Biological Process Transition metal ion homeostasis 8.5E-08 0 GO Biological Process Heavy metal sensitivity/resistance 1.9E-07 0 GO Biological Process Di-, tri-valent inorganic cation homeostasis 6.3E-07 0 GO Biological Process Metal ion homeostasis 6.3E-07 0 GO Biological Process Cation homeostasis 2.1E-06 0 GO Biological Process Cell ion homeostasis 2.1E-06 0 GO Biological Process Ion homeostasis 2.1E-06 0 GO Molecular Helicase activity 2.3E-06 0 Function GO Biological -

Secretion and LPS-Induced Endotoxin Shock Α Lipopolysaccharide
IFIT2 Is an Effector Protein of Type I IFN− Mediated Amplification of Lipopolysaccharide (LPS)-Induced TNF- α Secretion and LPS-Induced Endotoxin Shock This information is current as of September 27, 2021. Alexandra Siegfried, Susanne Berchtold, Birgit Manncke, Eva Deuschle, Julia Reber, Thomas Ott, Michaela Weber, Ulrich Kalinke, Markus J. Hofer, Bastian Hatesuer, Klaus Schughart, Valérie Gailus-Durner, Helmut Fuchs, Martin Hrabe de Angelis, Friedemann Weber, Mathias W. Hornef, Ingo B. Autenrieth and Erwin Bohn Downloaded from J Immunol published online 6 September 2013 http://www.jimmunol.org/content/early/2013/09/06/jimmun ol.1203305 http://www.jimmunol.org/ Supplementary http://www.jimmunol.org/content/suppl/2013/09/06/jimmunol.120330 Material 5.DC1 Why The JI? Submit online. by guest on September 27, 2021 • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. Published September 6, 2013, doi:10.4049/jimmunol.1203305 The Journal of Immunology IFIT2 Is an Effector Protein of Type I IFN–Mediated Amplification of Lipopolysaccharide (LPS)-Induced TNF-a Secretion and LPS-Induced Endotoxin Shock Alexandra Siegfried,*,1 Susanne Berchtold,*,1 Birgit Manncke,* Eva Deuschle,* Julia Reber,* Thomas Ott,† Michaela Weber,‡ Ulrich Kalinke,x Markus J. -

Small Nucleolar Rnas Determine Resistance to Doxorubicin in Human Osteosarcoma
International Journal of Molecular Sciences Article Small Nucleolar RNAs Determine Resistance to Doxorubicin in Human Osteosarcoma Martina Godel 1, Deborah Morena 1, Preeta Ananthanarayanan 1, Ilaria Buondonno 1, Giulio Ferrero 2,3 , Claudia M. Hattinger 4, Federica Di Nicolantonio 1,5 , Massimo Serra 4 , 1 2 1, , 1, , Riccardo Taulli , Francesca Cordero , Chiara Riganti * y and Joanna Kopecka * y 1 Department of Oncology, University of Torino, 1026 Torino, Italy; [email protected] (M.G.); [email protected] (D.M.); [email protected] (P.A.); [email protected] (I.B.); [email protected] (F.D.N.); [email protected] (R.T.) 2 Department of Computer Science, University of Torino, 10149 Torino, Italy; [email protected] (G.F.); [email protected] (F.C.) 3 Department of Clinical and Biological Sciences, University of Torino, 10043 Orbassano, Italy 4 Laboratory of Experimental Oncology, Pharmacogenomics and Pharmacogenetics Research Unit, IRCCS Istituto Ortopedico Rizzoli, 40136 Bologna, Italy; [email protected] (C.M.H.); [email protected] (M.S.) 5 Candiolo Cancer Institute, FPO–IRCCS, 10060 Candiolo, Italy * Correspondence: [email protected] (C.R.); [email protected] (J.K.); Tel.: +39-0116705857 (C.R.); +39-0116705849 (J.K.) These authors equally contributed to this work. y Received: 31 May 2020; Accepted: 21 June 2020; Published: 24 June 2020 Abstract: Doxorubicin (Dox) is one of the most important first-line drugs used in osteosarcoma therapy. Multiple and not fully clarified mechanisms, however, determine resistance to Dox. With the aim of identifying new markers associated with Dox-resistance, we found a global up-regulation of small nucleolar RNAs (snoRNAs) in human Dox-resistant osteosarcoma cells. -

Gain-Of-Function Genetic Alterations of G9a Drive Oncogenesis
Published OnlineFirst April 8, 2020; DOI: 10.1158/2159-8290.CD-19-0532 RESEARCH ARTICLE Gain-of-Function Genetic Alterations of G9a Drive Oncogenesis Shinichiro Kato 1 , Qing Yu Weng 1 , Megan L. Insco 2 , 3 , 4 , Kevin Y. Chen 2 , 3 , 4 , Sathya Muralidhar 5 , Joanna Pozniak 5 , Joey Mark S. Diaz5 , Yotam Drier 6 , 7 , 8 , Nhu Nguyen 1 , Jennifer A. Lo 1 , Ellen van Rooijen 2 , 3 , Lajos V. Kemeny 1 , Yao Zhan1 , Yang Feng 1 , Whitney Silkworth 1 , C. Thomas Powell 1 , Brian B. Liau 9 , Yan Xiong 10 , Jian Jin 10 , Julia Newton-Bishop5 , Leonard I. Zon 2 , 3 , Bradley E. Bernstein 6 , 7 , 8 , and David E. Fisher 1 . Downloaded from cancerdiscovery.aacrjournals.org on September 25, 2021. © 2020 American Association for Cancer Research. Published OnlineFirst April 8, 2020; DOI: 10.1158/2159-8290.CD-19-0532 ABSTRACT Epigenetic regulators, when genomically altered, may become driver oncogenes that mediate otherwise unexplained pro-oncogenic changes lacking a clear genetic stimulus, such as activation of the WNT/β -catenin pathway in melanoma. This study identifi es previ- ously unrecognized recurrent activating mutations in the G9a histone methyltransferase gene, as well as G9a genomic copy gains in approximately 26% of human melanomas, which collectively drive tumor growth and an immunologically sterile microenvironment beyond melanoma. Furthermore, the WNT pathway is identifi ed as a key tumorigenic target of G9a gain-of-function, via suppression of the WNT antagonist DKK1. Importantly, genetic or pharmacologic suppression of mutated or amplifi ed G9a using multiple in vitro and in vivo models demonstrates that G9a is a druggable target for therapeutic intervention in melanoma and other cancers harboring G9a genomic aberrations. -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. -

Targeting PH Domain Proteins for Cancer Therapy
The Texas Medical Center Library DigitalCommons@TMC The University of Texas MD Anderson Cancer Center UTHealth Graduate School of The University of Texas MD Anderson Cancer Biomedical Sciences Dissertations and Theses Center UTHealth Graduate School of (Open Access) Biomedical Sciences 12-2018 Targeting PH domain proteins for cancer therapy Zhi Tan Follow this and additional works at: https://digitalcommons.library.tmc.edu/utgsbs_dissertations Part of the Bioinformatics Commons, Medicinal Chemistry and Pharmaceutics Commons, Neoplasms Commons, and the Pharmacology Commons Recommended Citation Tan, Zhi, "Targeting PH domain proteins for cancer therapy" (2018). The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access). 910. https://digitalcommons.library.tmc.edu/utgsbs_dissertations/910 This Dissertation (PhD) is brought to you for free and open access by the The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences at DigitalCommons@TMC. It has been accepted for inclusion in The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access) by an authorized administrator of DigitalCommons@TMC. For more information, please contact [email protected]. TARGETING PH DOMAIN PROTEINS FOR CANCER THERAPY by Zhi Tan Approval page APPROVED: _____________________________________________ Advisory Professor, Shuxing Zhang, Ph.D. _____________________________________________