Enosis: Bridging the Semantic Gap Between File-Based and Object
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Daniel D. Garcia
DANIEL D. GARCIA [email protected] http://www.cs.berkeley.edu/~ddgarcia/ 777 Soda Hall #1776 UC Berkeley Berkeley, CA 94720-1776 (510) 517-4041 ______________________________________________________ EDUCATION MASSACHUSETTS INSTITUTE OF TECHNOLOGY Cambridge, MA B.S. in Computer Science, 1990 B.S. in Electrical Engineering, 1990 UNIVERSITY OF CALIFORNIA, BERKELEY Berkeley, CA M.S. in Computer Science, 1995 Ph.D. in Computer Science, 2000. Area: computer graphics and scientific visualization. Brian Barsky, advisor. TEACHING AWARDS • Outstanding Graduate Student Instructor in Computer Science (1992) • Electrical Engineering and Computer Science Outstanding Graduate Student Instructor (1997) • Computer Science Division Diane S. McEntyre Award for Excellence in Teaching (2002) • Computer Science Division IT Faculty Award for Excellence in Undergraduate Teaching (2005) • UC Berkeley “Everyday Hero” Award (2005) • Highest “teaching effectiveness” rating for any EECS lower division instructor, ever (6.7, since tied) (2006) • CS10: The Beauty and Joy of Computing chosen as 1 of 5 national pilots for AP CS: Principles course (2010) • CS10: The Beauty and Joy of Computing chosen as a University of California Online Course Pilot (2011) • Association of Computing Machinery (ACM) Distinguished Educator (2012) • Top 5 Professors to Take Classes with at UC Berkeley, The Black Sheep Online (2013) • CS10 becomes first introductory computing class at UC Berkeley with > 50% women (2013,2014) • Ten Most Popular MOOCs Starting in September 2015 and January 2016, Class Central (2015, 2016) • LPFI's Lux Award for being “Tech Diversity Champion” (2015) • NCWIT’s Undergraduate Research Mentoring (URM) Award (2016) • NCWIT’s Extension Services Transformation Award, Honorable Mention (2016) • CS10 becomes first introductory computing class at UC Berkeley with > 60% women (2017) • SAP Visionary Member Award (2017) • Google CS4HS Ambassador (2017) • CS10 becomes first introductory computing class at UC Berkeley with > 65% women (2018) Updated through 2018-07-01 1 / 28 Daniel D. -

SIGOPS Annual Report 2012
SIGOPS Annual Report 2012 Fiscal Year July 2012-June 2013 Submitted by Jeanna Matthews, SIGOPS Chair Overview SIGOPS is a vibrant community of people with interests in “operatinG systems” in the broadest sense, includinG topics such as distributed computing, storaGe systems, security, concurrency, middleware, mobility, virtualization, networkinG, cloud computinG, datacenter software, and Internet services. We sponsor a number of top conferences, provide travel Grants to students, present yearly awards, disseminate information to members electronically, and collaborate with other SIGs on important programs for computing professionals. Officers It was the second year for officers: Jeanna Matthews (Clarkson University) as Chair, GeorGe Candea (EPFL) as Vice Chair, Dilma da Silva (Qualcomm) as Treasurer and Muli Ben-Yehuda (Technion) as Information Director. As has been typical, elected officers agreed to continue for a second and final two- year term beginning July 2013. Shan Lu (University of Wisconsin) will replace Muli Ben-Yehuda as Information Director as of AuGust 2013. Awards We have an excitinG new award to announce – the SIGOPS Dennis M. Ritchie Doctoral Dissertation Award. SIGOPS has lonG been lackinG a doctoral dissertation award, such as those offered by SIGCOMM, Eurosys, SIGPLAN, and SIGMOD. This new award fills this Gap and also honors the contributions to computer science that Dennis Ritchie made durinG his life. With this award, ACM SIGOPS will encouraGe the creativity that Ritchie embodied and provide a reminder of Ritchie's leGacy and what a difference a person can make in the field of software systems research. The award is funded by AT&T Research and Alcatel-Lucent Bell Labs, companies that both have a strong connection to AT&T Bell Laboratories where Dennis Ritchie did his seminal work. -

ACM Education Board and Education Council FY2017-2018 Executive
ACM Education Board and Education Council FY2017-2018 Executive Summary This report summarizes the activities of the ACM Education Board and the Education Council1 in FY 2017-18 and outlines priorities for the coming year. Major accomplishments for this past year include the following: Curricular Volumes: Joint Taskforce on Cybersecurity Education CC2020 Completed: Computer Engineering Curricular Guidelines 2016 (CE2016) Enterprise Information Technology Body of Knowledge (EITBOK) Information Technology 2017 (IT2017) Masters of Science in Information Systems 2016 (MSIS2016) International Efforts: Educational efforts in China Educational efforts in Europe/Informatics for All Taskforces and Other Projects: Retention taskforce Learning at Scale Informatics for All Committee International Education Taskforce Global Awareness Taskforce Data Science Taskforce Education Policy Committee NDC Study Activities and Engagements with ACM SIGs and Other Groups: CCECC Code.org CSTA 1 The ACM Education Council was re-named in fall 2018 to the ACM Education Advisory Committee. For historical accuracy, the EAC will be called the Education Council for this report. 1 SIGCAS SIGCHI SIGCSE SIGHPC SIGGRAPH SIGITE Other Items: Education Board Rotation Education Council Rotation Future Initiatives Global Awareness Taskforce International Education Framework Highlights This is a very short list of the many accomplishments of the year. For full view of the work to date, please see Section One: Summary of FY 2017-2018 Activities. Diversity Taskforce: The Taskforce expects to complete its work by early 2019. Their goals of Exploring the data challenges Identifying factors contributing to the leaky pipeline Recommending potential interventions to improve retention Learning at Scale: The Fifth Annual ACM Conference on Learning @ Scale (L@S) was held in London, UK on June 26-28, 2018. -

Candidate for Chair Jeffrey K. Hollingsworth University Of
Candidate for Chair Jeffrey K. Hollingsworth University of Maryland, College Park, MD, USA BIOGRAPHY Academic Background: Ph.D., University of Wisconsin, 1994, Computer Sciences. Professional Experience: Professor, University of Maryland, College Park, MD, 2006 – Present; Associate /Assistant Professor, University of Maryland, College Park, MD, 1994 – 2006; Visiting Scientist, IBM, TJ Watson Research Center, 2000 – 2001. Professional Interest: Parallel Computing; Performance Measurement Tools; Auto-tuning; Binary Instrumentation; Computer Security. ACM Activities: Vice Chair, SIGHPC, 2011 – Present; Member, ACM Committee on Future of SIGs, 2014 – 2015; General Chair, SC Conference, 2012; Steering Committee Member (and Chair '13), SC Conference, 2009 – 2014. Membership and Offices in Related Organizations: Editor in Chief, PARCO, 2009 – Present; Program Chair, IPDPS, 2016; Board Member, Computing Research Association (CRA), 2008 – 2010. Awards Received: IPDPS, Best Paper - Software, 2011; SC, Best Paper - Student lead Author, 2005; IPDPS, Best Paper - Software, 2000. STATEMENT There is a critical need for a strong SIGHPC. Until SIGHPC was founded five years ago, the members of the HPC community lacked a home within ACM. While the SC conference provides a nexus for HPC activity in the fall, we needed a full-time community. Now that the initial transition of the SC conference from SIGARCH to SIGHPC is nearly complete, the time is right to start considering what other meetings and activities SIGHPC should undertake. We need to carefully identify meetings to sponsor or co-sponsor. Also, SIGHPC needs to continue and expand its role as a voice for the HPC community. This includes mentoring young professionals, actively identifying and nominating members for society wide awards, and speaking for the HPC community within both the scientific community and society at large. -

2017 ALCF Operational Assessment Report
ANL/ALCF-20/04 2017 Operational Assessment Report ARGONNE LEADERSHIP COMPUTING FACILITY On the cover: This visualization shows a small portion of a cosmology simulation tracing structure formation in the universe. The gold-colored clumps are high-density regions of dark matter that host galaxies in the real universe. This BorgCube simulation was carried out on Argonne National Laboratory’s Theta supercomputer as part of the Theta Early Science Program. Image: Joseph A. Insley, Silvio Rizzi, and the HACC team, Argonne National Laboratory Contents Executive Summary ................................................................................................ ES-1 Section 1. User Support Results .............................................................................. 1-1 ALCF Response ........................................................................................................................... 1-1 Survey Approach ................................................................................................................ 1-2 1.1 User Support Metrics .......................................................................................................... 1-3 1.2 Problem Resolution Metrics ............................................................................................... 1-4 1.3 User Support and Outreach ................................................................................................. 1-5 1.3.1 Tier 1 Support ........................................................................................................ -

Shanlu › About › Cv › CV Shanlu.Pdf Shan Lu
Shan Lu University of Chicago, Dept. of Computer Science Phone: +1-773-702-3184 5730 S. Ellis Ave., Rm 343 E-mail: [email protected] Chicago, IL 60637 USA Homepage: http://people.cs.uchicago.edu/~shanlu RESEARCH INTERESTS Tool support for improving the correctness and efficiency of large scale software systems EMPLOYMENT 2019 – present Professor, Dept. of Computer Science, University of Chicago 2014 – 2019 Associate Professor, Dept. of Computer Sciences, University of Chicago 2009 – 2014 Assistant Professor, Dept. of Computer Sciences, University of Wisconsin – Madison EDUCATION 2008 University of Illinois at Urbana-Champaign, Urbana, IL Ph.D. in Computer Science Thesis: Understanding, Detecting, and Exposing Concurrency Bugs (Advisor: Prof. Yuanyuan Zhou) 2003 University of Science & Technology of China, Hefei, China B.S. in Computer Science HONORS AND AWARDS 2019 ACM Distinguished Member Among 62 members world-wide recognized for outstanding contributions to the computing field 2015 Google Faculty Research Award 2014 Alfred P. Sloan Research Fellow Among 126 “early-career scholars (who) represent the most promising scientific researchers working today” 2013 Distinguished Alumni Educator Award Among 3 awardees selected by Department of Computer Science, University of Illinois 2010 NSF Career Award 2021 Honorable Mention Award @ CHI for paper [C71] (CHI 2021) 2019 Best Paper Award @ SOSP for paper [C62] (SOSP 2019) 2019 ACM SIGSOFT Distinguished Paper Award @ ICSE for paper [C58] (ICSE 2019) 2017 Google Scholar Classic Paper Award for -

Daniel Andresen
Daniel Andresen Professor, Department of Computer Science Director, Institute for Computational Research in Engineering and Science Michelle Munson-Serban Simu Keystone Research Scholar Kansas State University 2174 Engineering Hall Manhattan, KS 66506-2302 Tel: 785–532–6350 Fax: 785–532–7353 Email: [email protected] WWW: http://www.cis.ksu.edu/∼dan EDUCATION Ph.D., Computer Science, University of California, Santa Barbara, CA. September, 1997 Thesis Title: “SWEB++: Distributed Scheduling and Software Support for High Performance WWW Applications.” Advisor: Prof. Tao Yang M.S., Computer Science, California Polytechnic State University, San Luis Obispo, CA. September, 1992. B.S., Computer Science and Mathematics, double major, magna cum laude, honors in major, Westmont College, Santa Barbara, CA. May, 1990. AWARDS Michelle Munson-Serban Simu Keystone Research Scholar September, 2020 NSF CAREER Award 2001 KSU Engineering Student Council Outstanding Leadership Award December, 2004, 2005, 2008 Residencehall’sProfessoroftheYearnominee 2000,2002 Cargill Faculty Fellow 1999, 2000 College of Engg. James L. Hollis Memorial Award for Excellence in Undergrad- uate Teaching nominee 1999, 2006 RESEARCH Parallel and distributed systems, HPC scheduling, Research Cyberinfrastructure, INTERESTS digital libraries/WWW applications, Grid/cloud computing, and scientific mod- eling. TEACHING Graduate-level parallel/distributed computing, scientific computing, networking, INTERESTS operating systems, and computer architectures. Courses taught include operat- ing systems (CIS520), Topics in Distributed Systems (CIS825), Introduction to Computer Architecture (CIS450), Software Engineering (CIS642), Web Interface Design (CIS526), and Advanced World Wide Web Technologies (CIS726). 1 WORK Professor in the Department of Computing and Information Sciences at EXPERIENCE Kansas State University. 2015-present Associate Professor in the Department of Computing and Information SciencesatKansasStateUniversity. -

“Housekeeping”
“Housekeeping” Twitter: #ACMWebinarScaling ’ • Welcome to today s ACM Learning Webinar. The presentation starts at the top of the hour and lasts 60 minutes. Slides will advance automatically throughout the event. You can resize the slide area as well as other windows by dragging the bottom right corner of the slide window, as well as move them around the screen. On the bottom panel you’ll find a number of widgets, including Facebook, Twitter, and Wikipedia. • If you are experiencing any problems/issues, refresh your console by pressing the F5 key on your keyboard in Windows, Command + R if on a Mac, or refresh your browser if you’re on a mobile device; or close and re-launch the presentation. You can also view the Webcast Help Guide, by clicking on the “Help” widget in the bottom dock. • To control volume, adjust the master volume on your computer. If the volume is still too low, use headphones. • If you think of a question during the presentation, please type it into the Q&A box and click on the submit button. You do not need to wait until the end of the presentation to begin submitting questions. • At the end of the presentation, you’ll see a survey open in your browser. Please take a minute to fill it out to help us improve your next webinar experience. • You can download a copy of these slides by clicking on the Resources widget in the bottom dock. • This session is being recorded and will be archived for on-demand viewing in the next 1-2 days. -

Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems Pdfauthor=Jonathan Mace, Ryan Roelke, Rodrigo Fonseca
PivoT Tracing:Dynamic Causal MoniToring for DisTribuTed SysTems JonaThan Mace Ryan Roelke Rodrigo Fonseca Brown UniversiTy AbsTracT MoniToring and TroubleshooTing disTribuTed sysTems is noToriously diõcult; poTenTial prob- lems are complex, varied, and unpredicTable. _e moniToring and diagnosis Tools commonly used Today – logs, counTers, and meTrics – have Two imporTanT limiTaTions: whaT gets recorded is deûned a priori, and The informaTion is recorded in a componenT- or machine-cenTric way, making iT exTremely hard To correlaTe events ThaT cross These boundaries. _is paper presents PivoT Tracing, a moniToring framework for disTribuTed sysTems ThaT addresses boTh limiTaTions by combining dynamic insTrumenTaTion wiTh a novel relaTional operaTor: The happened-before join. PivoT Tracing gives users, aT runTime, The abiliTy To deûne arbiTrary meTrics aT one poinT of The sysTem, while being able To selecT, ûlTer, and group by events mean- ingful aT oTher parts of The sysTem, even when crossing componenT or machine boundaries. We have implemenTed a proToType of PivoT Tracing for Java-based sysTems and evaluaTe iT on a heTerogeneous Hadoop clusTer comprising HDFS, HBase, MapReduce, and YARN. We show ThaT PivoT Tracing can eòecTively idenTify a diverse range of rooT causes such as soware bugs, misconûguraTion, and limping hardware. We show ThaT PivoT Tracing is dynamic, exTensible, and enables cross-Tier analysis beTween inTer-operaTing applicaTions, wiTh low execuTion overhead. Ë. InTroducTion MoniToring and TroubleshooTing disTribuTed sysTems -
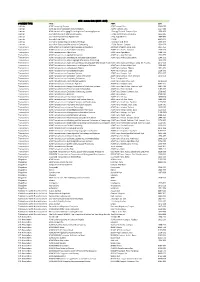
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -

An Oral History of Computer Science Cornell University
An Oral History of Computer Science at Cornell University https://ecommons.cornell.edu/handle/1813/40569 Gates Hall, Cornell University Twelve senior faculty members share their personal journeys and their recollections of the early days of computer science at Cornell University and the leadership role in bringing a new field of study into existence. Birman, Ken Hopcroft, John E Cardie, Claire Kozen, Dexter Constable, Robert Nerode, Anil Conway, Richard W. Schneider, Fred B Gries, David Teitelbaum, Tim Hartmanis, Juris Van Loan, Charlie (Click on a name above to scroll to an abstract and a live link to the associated streaming video.) version: 16Jun16 1. KEN BIRMAN Ken Birman, who joined CS in 1981, exemplifies the successful synergy of research and entrepreneurial activities. His research in distributed systems led to his founding ISIS Distributed Systems, Inc., in 1988, which developed software used by the New York Stock Exchange (NYSE) and Swiss Exchange, the French Air Traffic Control sys- tem, the AEGIS warship, and others. He started two other companies, Reliable Network Solutions and Web Sci- ences LLC. This entrepreneurship has in turn generated new research ideas and has also led to Ken’s advising various organi- zations on distributed systems and cloud computing, including the French Civil Aviation Organization, the north- eastern electric power grid, NATO, the US Treasury, and the US Air Force. Ken has received several awards for his research, among them the IEEE Tsutomu Kanai Award for his work on trustworthy computing, the Cisco “Technology Visionary” award, and the ACM SIGOPS Hall of Fame Award. He also has written two successful texts. -
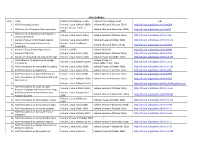
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11.