Efficient Race Detection in the Presence of Programmatic Event
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Organizace a Vybavení Vojska V 15. Století: Paralelní Vývoj Ve Francii, Burgundsku a St Řední Evrop Ě
UNIVERZITA KARLOVA V PRAZE FILOZOFICKÁ FAKULTA ÚSTAV ČESKÝCH D ĚJIN HISTORICKÉ V ĚDY Jan Biederman Organizace a vybavení vojska v 15. století: paralelní vývoj ve Francii, Burgundsku a st řední Evrop ě Organization and equipment of the army in 15 th century: parallel development in France, Burgundy and in the Central Europe DISERTA ČNÍ PRÁCE VEDOUCÍ DISERTA ČNÍ PRÁCE: doc. PhDr. Martin Nejedlý, Dr. PRAHA 2015 Prohlašuji, že jsem diserta ční práci napsal samostatn ě s využitím uvedených a řádn ě citovaných pramen ů a literatury a že práce nebyla využita v rámci jiného vysokoškolského studia či k získání jiného nebo stejného titulu. V Praze, dne 28. července 2015 ................................................. Klí čová slova ( česky) organizace vojska – zásobování – zbrojní výroba a výzbroj – palné zbran ě – transport Klí čová slova (anglicky) military organization – food supply – weapons production and armament – firearms – transport Abstrakt Organizace a vybavení vojska v 15. století: paralelní vývoj ve Francii, Burgundsku a st řední Evrop ě Tak jako v jiných epochách, i v pozdním st ředov ěku m ěla na kvalitách vojska klí čový podíl forma vojenské organizace, zajišt ění zásobování, technické možnosti a podmínky transportu a samoz řejm ě i povaha výzbroje. V této souvislosti byly d ůležité také dobové technické možnosti zbrojní výroby, obchodu se zbran ěmi a v neposlední řad ě též p řístup k progresivn ě se rozvíjející složce výzbroje, jíž p ředstavovaly palné zbran ě. Zám ěrem této práce je vzhledem ke zmín ěným tematickým okruh ům komparace oblasti st řední Evropy s důrazem na české zem ě a frankofonního západu Evropy, zastoupeného francouzským královstvím spolu s burgundským vévodstvím. -

Introducción a Linux Equivalencias Windows En Linux Ivalencias
No has iniciado sesión Discusión Contribuciones Crear una cuenta Acceder Página discusión Leer Editar Ver historial Buscar Introducción a Linux Equivalencias Windows en Linux Portada < Introducción a Linux Categorías de libros Equivalencias Windows en GNU/Linux es una lista de equivalencias, reemplazos y software Cam bios recientes Libro aleatorio análogo a Windows en GNU/Linux y viceversa. Ayuda Contenido [ocultar] Donaciones 1 Algunas diferencias entre los programas para Windows y GNU/Linux Comunidad 2 Redes y Conectividad Café 3 Trabajando con archivos Portal de la comunidad 4 Software de escritorio Subproyectos 5 Multimedia Recetario 5.1 Audio y reproductores de CD Wikichicos 5.2 Gráficos 5.3 Video y otros Imprimir/exportar 6 Ofimática/negocios Crear un libro 7 Juegos Descargar como PDF Versión para im primir 8 Programación y Desarrollo 9 Software para Servidores Herramientas 10 Científicos y Prog s Especiales 11 Otros Cambios relacionados 12 Enlaces externos Subir archivo 12.1 Notas Páginas especiales Enlace permanente Información de la Algunas diferencias entre los programas para Windows y y página Enlace corto GNU/Linux [ editar ] Citar esta página La mayoría de los programas de Windows son hechos con el principio de "Todo en uno" (cada Idiomas desarrollador agrega todo a su producto). De la misma forma, a este principio le llaman el Añadir enlaces "Estilo-Windows". Redes y Conectividad [ editar ] Descripción del programa, Windows GNU/Linux tareas ejecutadas Firefox (Iceweasel) Opera [NL] Internet Explorer Konqueror Netscape / -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

Download the Index
41_067232945x_index.qxd 10/5/07 1:09 PM Page 667 Index NUMBERS 3D video, 100-101 10BaseT Ethernet NIC (Network Interface Cards), 512 64-bit processors, 14 100BaseT Ethernet NIC (Network Interface Cards), 512 A A (Address) resource record, 555 AbiWord, 171-172 ac command, 414 ac patches, 498 access control, Apache web server file systems, 536 access times, disabling, 648 Accessibility module (GNOME), 116 ACPI (Advanced Configuration and Power Interface), 61-62 active content modules, dynamic website creation, 544 Add a New Local User screen, 44 add command (CVS), 583 address books, KAddressBook, 278 Administrator Mode button (KDE Control Center), 113 Adobe Reader, 133 AFPL Ghostscript, 123 41_067232945x_index.qxd 10/5/07 1:09 PM Page 668 668 aggregators aggregators, 309 antispam tools, 325 aKregator (Kontact), 336-337 KMail, 330-331 Blam!, 337 Procmail, 326, 329-330 Bloglines, 338 action line special characters, 328 Firefox web browser, 335 recipe flags, 326 Liferea, 337 special conditions, 327 Opera web browser, 335 antivirus tools, 331-332 RSSOwl, 338 AP (Access Points), wireless networks, 260, 514 aKregator webfeeder (Kontact), 278, 336-337 Apache web server, 529 album art, downloading to multimedia dynamic websites, creating players, 192 active content modules, 544 aliases, 79 CGI programming, 542-543 bash shell, 80 SSI, 543 CNAME (Canonical Name) resource file systems record, 555 access control, 536 local aliases, email server configuration, 325 authentication, 536-538 allow directive (Apache2/httpd.conf), 536 installing Almquist shells -

Red Hat Enterprise Linux 7 7.8 Release Notes
Red Hat Enterprise Linux 7 7.8 Release Notes Release Notes for Red Hat Enterprise Linux 7.8 Last Updated: 2021-03-02 Red Hat Enterprise Linux 7 7.8 Release Notes Release Notes for Red Hat Enterprise Linux 7.8 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Awoken Icon Theme - Installation & Customizing Instructions 1
Awoken Icon Theme - Installation & Customizing Instructions 1 AWOKEN ICON THEME Installation & Customizing Instructions Alessandro Roncone mail: [email protected] homepage: http://alecive.deviantart.com/ Awoken homepage (GNOME Version): link kAwoken homepage (KDE Version): link Contents 1 Iconset Credits 3 2 Copyright 3 3 Installation 3 3.1 GNOME........................................................3 3.2 KDE..........................................................4 4 Customizing Instructions 4 4.1 GNOME........................................................4 4.2 KDE..........................................................5 5 Overview of the customization script6 5.1 How to customize a single iconset..........................................7 6 Customization options 8 6.1 Folder types......................................................8 6.2 Color-NoColor.................................................... 11 6.3 Distributor Logos................................................... 11 6.4 Trash types...................................................... 11 6.5 Other Options.................................................... 11 6.5.1 Gedit icon................................................... 11 6.5.2 Computer icon................................................ 11 6.5.3 Home icon................................................... 11 6.6 Deprecated...................................................... 12 7 How to colorize the iconset 13 8 Icons that don't want to change (but I've drawed) 14 9 Conclusions 15 9.1 Changelog...................................................... -

Red Hat Enterprise Linux 7 7.9 Release Notes
Red Hat Enterprise Linux 7 7.9 Release Notes Release Notes for Red Hat Enterprise Linux 7.9 Last Updated: 2021-08-17 Red Hat Enterprise Linux 7 7.9 Release Notes Release Notes for Red Hat Enterprise Linux 7.9 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

What Makes Linux Tick As a Programming Stronghold?
DevelopersDevelopers What Makes Linux Tick as a Programming Stronghold? Linux is widely regarded as one of the best programming platforms available today. In this article, we explore the features that make the OS a programmer’s paradise. Acquire the holy weapons of development that all Linux programmers should add to their arsenal of skills! e all know Linux is an excellent platform for application development. In this article, let us take a W formal look at why programmers swear by the programming tools and flexibility that the OS offers. We shall explore the languages, libraries and tools that are available on the Linux platform; and try to discover what exactly is making the, “It’s all about money, Honey,” development companies take note of this open source beauty. Let’s look at all the offerings Linux has in store for programmers. Many of these come pre-installed with most Linux distributions. Wow! You’ve got everything to build a space jet, and you wondered where to begin! The goodies on offer—languages The programming language that you could use may depend on project requirements, or your personal level of comfort. Some major languages that can be used on Linux are C, C++, Java, Ruby, Perl, Python, etc. Let’s take a closer look at these. Some languages are object oriented, some are structural and some are scripting languages. Table 1 summarises this information you could use to make your choice. Please note that most of these languages are both compiled and interpreted. In Table 1, the spotlight is on which method is more popular or generally used. -

Upgrade Issues
Upgrade issues Graph of new conflicts libsiloh5-0 libhdf5-lam-1.8.4 (x 3) xul-ext-dispmua (x 2) liboss4-salsa-asound2 (x 2) why sysklogd console-cyrillic (x 9) libxqilla-dev libxerces-c2-dev iceape xul-ext-adblock-plus gnat-4.4 pcscada-dbg Explanations of conflicts pcscada-dbg libpcscada2-dev gnat-4.6 gnat-4.4 Similar to gnat-4.4: libpolyorb1-dev libapq-postgresql1-dev adacontrol libxmlada3.2-dev libapq1-dev libaws-bin libtexttools2-dev libpolyorb-dbg libnarval1-dev libgnat-4.4-dbg libapq-dbg libncursesada1-dev libtemplates-parser11.5-dev asis-programs libgnadeodbc1-dev libalog-base-dbg liblog4ada1-dev libgnomeada2.14.2-dbg libgnomeada2.14.2-dev adabrowse libgnadecommon1-dev libgnatvsn4.4-dbg libgnatvsn4.4-dev libflorist2009-dev libopentoken2-dev libgnadesqlite3-1-dev libnarval-dbg libalog1-full-dev adacgi0 libalog0.3-base libasis2008-dbg libxmlezout1-dev libasis2008-dev libgnatvsn-dev libalog0.3-full libaws2.7-dev libgmpada2-dev libgtkada2.14.2-dbg libgtkada2.14.2-dev libasis2008 ghdl libgnatprj-dev gnat libgnatprj4.4-dbg libgnatprj4.4-dev libaunit1-dev libadasockets3-dev libalog1-base-dev libapq-postgresql-dbg libalog-full-dbg Weight: 5 Problematic packages: pcscada-dbg hostapd initscripts sysklogd Weight: 993 Problematic packages: hostapd | initscripts initscripts sysklogd Similar to initscripts: conglomerate libnet-akamai-perl erlang-base screenlets xlbiff plasma-widget-yawp-dbg fso-config- general gforge-mta-courier libnet-jifty-perl bind9 libplack-middleware-session-perl libmail-listdetector-perl masqmail libcomedi0 taxbird ukopp -

DVD NOVEMBER 2005 Or Once a Year, the Chances Are That a Are the Chances a Year, Or Once Be Glad You When You'll Time Will Come This Month's Enjoy Hope You We It
LINUX MAGA On this DVD: Knoppix 4 Highlights Linux kernel 2.6.12 ZINE Xfree86 4.3.0 KDE 3.4.1 GNOME 2.8 �� OpenOffice 2.0 pre-release �� GIMP 2.2.8 ISSUE ISSUE Inkscape 0.41 Evolution 2.2.2 Firefox 1.0.4 Mozilla 1.7.10 Thunderbird 1.0.6 60 GCC 4.0.1 Apache 1.3.33 KNOPPIX 4.0. Bind 9.3.1 ���������������������� ���������� ����������������������� ���������������������� �������������� ���������������� ������������������� ������� ��������������� ����������������� �� Samba 3.0.14 �� �� �� �� ■ ■ ■ ■ ■ The Knoppix live distro is fast and full of great tools. Knoppix is the system of choice for developers, admins, and thousands of ordinary users, and best of all: it boots anytime from nearly any Intel-class system with only a single disk. A live distro is the ultimate in portability, and according 2 to users around the world, Knoppix is LIVE DVD the ultimate live distro. We are proud to bring you Knoppix 4 as this month's Linux Magazine DVD. applications like J-Pilot, Kontact, and and Ruby 1.8.2, as well as integrated AbiWord, as well as games, editors, and development environments such as Ec- What's New educational programs. lipse, Mono, and Quanta+, and utilities With the release of Knoppix 4, the Knoppix Useful Internet utilities such as gFTP, such the Umbrello UML Modeller, the treasure chest just got much bigger. After Lynx, GNOME Meeting, and Akgregator Bluefi sh Editor, and the Cervisia CVS years as a leading "live CD" distro, Knoppix come pre-installed. Knoppix also inclu- front-end. appears for the fi rst time as a live DVD. -

Strong Dependencies Between Software Components
Specific Targeted Research Project Contract no.214898 Seventh Framework Programme: FP7-ICT-2007-1 Technical Report 0002 MANCOOSI Managing the Complexity of the Open Source Infrastructure Strong Dependencies between Software Components Pietro Abate ([email protected]) Jaap Boender ([email protected]) Roberto Di Cosmo ([email protected]) Stefano Zacchiroli ([email protected]) Universit`eParis Diderot, PPS UMR 7126, Paris, France May 24, 2009 Web site: www.mancoosi.org Contents 1 Introduction . .2 2 Strong dependencies . .3 3 Strong dependencies in Debian . .7 3.1 Strong vs direct sensitivity: exceptions . .9 3.2 Using strong dominance to cluster data . 11 3.3 Debian is a small world . 11 4 Efficient computation . 12 5 Applications . 13 6 Related works . 16 7 Conclusion and future work . 17 8 Acknowledgements . 18 A Case Study: Evaluation of debian structure . 21 Abstract Component-based systems often describe context requirements in terms of explicit inter-component dependencies. Studying large instances of such systems|such as free and open source software (FOSS) distributions|in terms of declared dependencies between packages is appealing. It is however also misleading when the language to express dependencies is as expressive as boolean formulae, which is often the case. In such settings, a more appropriate notion of component dependency exists: strong dependency. This paper introduces such notion as a first step towards modeling semantic, rather then syntactic, inter-component relationships. Furthermore, a notion of component sensitivity is derived from strong dependencies, with ap- plications to quality assurance and to the evaluation of upgrade risks. An empirical study of strong dependencies and sensitivity is presented, in the context of one of the largest, freely available, component-based system. -
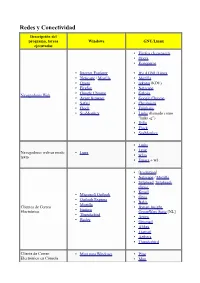
Redes Y Conectividad Descripción Del Programa, Tareas Windows GNU/Linux Ejecutadas • Firefox (Iceweasel) • Opera • Konqueror
Redes y Conectividad Descripción del programa, tareas Windows GNU/Linux ejecutadas • Firefox (Iceweasel) • Opera • Konqueror • Internet Explorer • IEs 4 GNU/Linux • Netscape / Mozilla • Mozilla • Opera • rekonq (KDE) • Firefox • Netscape • Google Chrome • Galeón Navegadores Web • Avant Browser • Google Chrome • Safari • Chromium • Flock • Epiphany • SeaMonkey • Links (llamado como "links -g") • Dillo • Flock • SeaMonkey • Links • • Lynx Navegadores web en modo Lynx • texto w3m • Emacs + w3. • [Evolution] • Netscape / Mozilla • Sylpheed , Sylpheed- claws. • Kmail • Microsoft Outlook • Gnus • Outlook Express • Balsa • Mozilla Clientes de Correo • Bynari Insight • Eudora Electrónico GroupWare Suite [NL] • Thunderbird • Arrow • Becky • Gnumail • Althea • Liamail • Aethera • Thunderbird Cliente de Correo • Mutt para Windows • Pine Electrónico en Cónsola • Mutt • Gnus • de , Pine para Windows • Elm. • Xemacs • Liferea • Knode. • Pan • Xnews , Outlook, • NewsReader Lector de noticias Netscape / Mozilla • Netscape / Mozilla. • Sylpheed / Sylpheed- claws • MultiGet • Orbit Downloader • Downloader para X. • MetaProducts Download • Caitoo (former Kget). Express • Prozilla . • Flashget • wxDownloadFast . • Go!zilla • Kget (KDE). Gestor de Descargas • Reget • Wget (console, standard). • Getright GUI: Kmago, QTget, • Wget para Windows Xget, ... • Download Accelerator Plus • Aria. • Axel. • Httrack. • WWW Offline Explorer. • Wget (consola, estándar). GUI: Kmago, QTget, Extractor de Sitios Web Teleport Pro, Webripper. Xget, ... • Downloader para X. •