WSQ/DSQ: a Practical Approach for Combined Querying of Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SIGOPS Annual Report 2012
SIGOPS Annual Report 2012 Fiscal Year July 2012-June 2013 Submitted by Jeanna Matthews, SIGOPS Chair Overview SIGOPS is a vibrant community of people with interests in “operatinG systems” in the broadest sense, includinG topics such as distributed computing, storaGe systems, security, concurrency, middleware, mobility, virtualization, networkinG, cloud computinG, datacenter software, and Internet services. We sponsor a number of top conferences, provide travel Grants to students, present yearly awards, disseminate information to members electronically, and collaborate with other SIGs on important programs for computing professionals. Officers It was the second year for officers: Jeanna Matthews (Clarkson University) as Chair, GeorGe Candea (EPFL) as Vice Chair, Dilma da Silva (Qualcomm) as Treasurer and Muli Ben-Yehuda (Technion) as Information Director. As has been typical, elected officers agreed to continue for a second and final two- year term beginning July 2013. Shan Lu (University of Wisconsin) will replace Muli Ben-Yehuda as Information Director as of AuGust 2013. Awards We have an excitinG new award to announce – the SIGOPS Dennis M. Ritchie Doctoral Dissertation Award. SIGOPS has lonG been lackinG a doctoral dissertation award, such as those offered by SIGCOMM, Eurosys, SIGPLAN, and SIGMOD. This new award fills this Gap and also honors the contributions to computer science that Dennis Ritchie made durinG his life. With this award, ACM SIGOPS will encouraGe the creativity that Ritchie embodied and provide a reminder of Ritchie's leGacy and what a difference a person can make in the field of software systems research. The award is funded by AT&T Research and Alcatel-Lucent Bell Labs, companies that both have a strong connection to AT&T Bell Laboratories where Dennis Ritchie did his seminal work. -

Polynomial Transformations of Tschirnhaus, Bring and Jerrard
ACM SIGSAM Bulletin, Vol 37, No. 3, September 2003 Polynomial Transformations of Tschirnhaus, Bring and Jerrard Victor S. Adamchik Department of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA [email protected] David J. Jeffrey Department of Applied Mathematics, The University of Western Ontario, London, Ontario, Canada [email protected] Abstract Tschirnhaus gave transformations for the elimination of some of the intermediate terms in a polynomial. His transformations were developed further by Bring and Jerrard, and here we describe all these transformations in modern notation. We also discuss their possible utility for polynomial solving, particularly with respect to the Mathematica poster on the solution of the quintic. 1 Introduction A recent issue of the BULLETIN contained a translation of the 1683 paper by Tschirnhaus [10], in which he proposed a method for solving a polynomial equation Pn(x) of degree n by transforming it into a polynomial Qn(y) which has a simpler form (meaning that it has fewer terms). Specifically, he extended the idea (which he attributed to Decartes) in which a polynomial of degree n is reduced or depressed (lovely word!) by removing its term in degree n ¡ 1. Tschirnhaus’s transformation is a polynomial substitution y = Tk(x), in which the degree of the transformation k < n can be selected. Tschirnhaus demonstrated the utility of his transformation by apparently solving the cubic equation in a way different from Cardano. Although Tschirnhaus’s work is described in modern books [9], later works by Bring [2, 3] and Jerrard [7, 6] have been largely forgotten. Here, we present the transformations in modern notation and make some comments on their utility. -
![Arxiv:1611.04369V1 [Cs.AI] 14 Nov 2016 Computer Science Conferences Are Selected As Target Conferences, to Rank [8]](https://docslib.b-cdn.net/cover/0959/arxiv-1611-04369v1-cs-ai-14-nov-2016-computer-science-conferences-are-selected-as-target-conferences-to-rank-8-560959.webp)
Arxiv:1611.04369V1 [Cs.AI] 14 Nov 2016 Computer Science Conferences Are Selected As Target Conferences, to Rank [8]
Feature Engineering and Ensemble Modeling for Paper Acceptance Rank Prediction Yujie Qian∗, Yinpeng Dong∗, Ye Ma∗, Hailong Jin, and Juanzi Li Department of Computer Science and Technology, Tsinghua University {qyj13, dongyp13, y-ma13}@mails.tsinghua.edu.cn, [email protected], [email protected] ABSTRACT MAG is a large and heterogeneous academic graph provided by Mi- Measuring research impact and ranking academic achievement are crosoft, containing scientific publication records, citation relation- important and challenging problems. Having an objective picture ships between publications, as well as authors, institutions, jour- of research institution is particularly valuable for students, parents nal and conference venues, and fields of study. The latest version and funding agencies, and also attracts attention from government of MAG includes 19,843 institutions, 114,698,044 authors, and and industry. KDD Cup 2016 proposes the paper acceptance rank 126,909,021 publications. prediction task, in which the participants are asked to rank the im- The evaluation is performed after the conferences announce their portance of institutions based on predicting how many of their pa- decisions of paper acceptance. For every conference, the compe- pers will be accepted at the 8 top conferences in computer science. tition organizers collect the full list of accepted papers, calculate In our work, we adopt a three-step feature engineering method, ground truth ranking, and evaluate the participants’ submissions. including basic features definition, finding similar conferences to Ground truth ranking is generated following a simple policy to de- enhance the feature set, and dimension reduction using PCA. We termine the Institution Ranking Score: propose three ranking models and the ensemble methods for com- 1. -

Llista Congressos Notables
Llistat de congressos notables per la UPC (Ordenat pel nom del congrés) Servei d'Informació RDI (Per dubtes: [email protected]). 5 de febrer de 2018 Nom del congrés Acrònim AAAI Conference on Artificial Intelligence AAAI ACM Conference on Computer and Communications Security CCS ACM Conference on Human Factors in Computing Systems CHI ACM European Conference on Computer Systems EuroSys ACM Great Lakes Symposium on VLSI GLSVLSI ACM International Conference on Information and Knowledge Management CIKM ACM International Conference on Measurement and Modelling of Computer Systems SIGMETRICS ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems MSWiN ACM International Conference on Multimedia ACMMM ACM International Symposium on Mobile AdHoc Networking and Computing ACM MOBIHOC ACM International Symposium on Modeling, Analysis and Simulation of Wireless and Mobile Systems MSWiM ACM International Symposium on Physical Design ISPD ACM Object-Oriented Programming, Systems, Languages & Applications OOPSLA ACM Principles of Programming Languages POPL ACM SIGCOMM Special Interest Group on Data Communications SIGCOMM ACM SIGMOD Conference ACM SIGMOD ACM SIGPLAN 2005 Conference on Programming Language Design and Implementation PLDI ACM Symposium on Applied Computing SAC ACM Symposium on Operating Systems Principles SOSP ACM Symposium on Parallel Algorithms and Architectures SPAA ACM Symposium on Principles of Database Systems PODS ACM Symposium on Principles of Distributed Computing PODC ACM Symposium on -

Curriculum Vitae
CURRICULUM VITAE Name: Robert J. Robbins Birth Date: 10 May 1944 Birthplace: Niles, Michigan Citizenship: United States Address: Vice President, Information Technology Fred Hutchinson Cancer Research Center 1100 Fairview Avenue North, J4-300 Seattle, WASHINGTON 98109 (206) 667–4778 (206) 667–7733 (FAX) [email protected] Home: 21454 NE 143rd Street Woodinville, WASHINGTON 98072 (425) 556–9386 (home) (425) 556–0970 (home FAX) Education: Ph.D. 1977 Zoology Michigan State University East Lansing, Michigan M.S. 1974 Biological Michigan State University Science East Lansing, Michigan B.S. 1973 Zoology Michigan State University East Lansing, Michigan A.B. 1966 History Stanford University Palo Alto, California Research Interests: Computer applications in biology; information systems design; database theory and design; software engineering; history of science; intellectual history of genetics; concept of the gene. Professional Affiliations: American Association for the Advancement of Science American Society for Microbiology Association for Computing Machinery SIGMOD, SIGIR, SIGSOFT Genetics Society of America IEEE Computer Society Honors and Awards: Listed in American Men and Women of Science Listed in Who’s Who in the Midwest Listed in Who’s Who of Emerging Leaders in America Listed in Who’s Who in Frontier Science and Technology Outstanding Performance Award, NSF (1991) Outstanding Performance Award, NSF (1989) National Science Foundation National Needs Postdoctoral Fellowship (1978– 1979) Sigma Xi Award for Meritorious Research (1977) National -

SIGLOG: Special Interest Group on Logic and Computation a Proposal
SIGLOG: Special Interest Group on Logic and Computation A Proposal Natarajan Shankar Computer Science Laboratory SRI International Menlo Park, CA Mar 21, 2014 SIGLOG: Executive Summary Logic is, and will continue to be, a central topic in computing. ACM has a core constituency with an interest in Logic and Computation (L&C), witnessed by 1 The many Turing Awards for work centrally in L&C 2 The ACM journal Transactions on Computational Logic 3 Several long-running conferences like LICS, CADE, CAV, ICLP, RTA, CSL, TACAS, and MFPS, and super-conferences like FLoC and ETAPS SIGLOG explores the connections between logic and computing covering theory, semantics, analysis, and synthesis. SIGLOG delivers value to its membership through the coordination of conferences, journals, newsletters, awards, and educational programs. SIGLOG enjoys significant synergies with several existing SIGs. Natarajan Shankar SIGLOG 2/9 Logic and Computation: Early Foundations Logicians like Alonzo Church, Kurt G¨odel, Alan Turing, John von Neumann, and Stephen Kleene have played a pioneering role in laying the foundation of computing. In the last 65 years, logic has become the calculus of computing underpinning the foundations of many diverse sub-fields. Natarajan Shankar SIGLOG 3/9 Logic and Computation: Turing Awardees Turing awardees for logic-related work include John McCarthy, Edsger Dijkstra, Dana Scott Michael Rabin, Tony Hoare Steve Cook, Robin Milner Amir Pnueli, Ed Clarke Allen Emerson Joseph Sifakis Leslie Lamport Natarajan Shankar SIGLOG 4/9 Interaction between SIGLOG and other SIGs Logic interacts in a significant way with AI (SIGAI), theory of computation (SIGACT), databases (SIGMOD) and knowledge bases (SIGKDD), programming languages (SIGPLAN), software engineering (SIGSOFT), computational biology (SIGBio), symbolic computing (SIGSAM), semantic web (SIGWEB), and hardware design (SIGDA and SIGARCH). -

© in This Web Service Cambridge University Press
Cambridge University Press 978-1-107-03903-2 - Modern Computer Algebra: Third Edition Joachim Von Zur Gathen and Jürgen Gerhard Index More information Index A page number is underlined (for example: 667) when it represents the definition or the main source of information about the index entry. For several key words that appear frequently only ranges of pages or the most important occurrences are indexed. AAECC ......................................... 21 analytic number theory . 508, 523, 532, 533, 652 Abbott,John .............................. 465, 734 AnalyticalEngine ............................... 312 Abel,NielsHenrik .............................. 373 Andrews, George Eyre . 644, 697, 729, 735 Abeliangroup ................................... 704 QueenAnne .................................... 219 Abramov, Serge˘ı Aleksandrovich (Abramov annihilating polynomial ......................... 341 SergeiAleksandroviq) 7, 641, 671, 675, annihilator, Ann( ) .............................. 343 734, 735 annusconfusionis· ................................ 83 Abramson, Michael . 738 Antoniou,Andreas ........................ 353, 735 Achilles ......................................... 162 Antoniszoon, Adrian (Metius) .................... 82 ACM . see Association for Computing Machinery Aoki,Kazumaro .......................... 542, 751 active attack . 580 Apéry, Roger . 671, 684, 697, 761 Adam,Charles .................................. 729 number ....................................... 684 Adams,DouglasNoël ..................... 729, 796 Apollonius of -

Analysing Scholarly Communication Metadata of Computer Science Events
Analysing Scholarly Communication Metadata of Computer Science Events Said Fathalla1;3, Sahar Vahdati1, Christoph Lange1;2, and Sören Auer4;5 1 Enterprise Information Systems (EIS), University of Bonn, Germany {fathalla,vahdati,langec}@cs.uni-bonn.de 2 Fraunhofer IAIS, Germany 3 Faculty of Science, University of Alexandria, Egypt 4 Computer Science, Leibniz University of Hannover, Germany 5 TIB Leibniz Information Center for Science and Technology, Hannover, Germany [email protected] Abstract Over the past 30 years we have observed the impact of the ubiquitous availability of the Internet, email, and web-based services on scholarly communication. The preparation of manuscripts as well as the organisation of conferences, from submission to peer review to publica- tion, have become considerably easier and efficient. A key question now is what were the measurable effects on scholarly communication in com- puter science? Of particular interest are the following questions: Did the number of submissions to conferences increase? How did the selection processes change? Is there a proliferation of publications? We shed light on some of these questions by analysing comprehensive scholarly commu- nication metadata from a large number of computer science conferences of the last 30 years. Our transferable analysis methodology is based on descriptive statistics analysis as well as exploratory data analysis and uses crowd-sourced, semantically represented scholarly communication metadata from OpenResearch.org. Keywords: Scientific Events, Scholarly Communication, Semantic Publishing, Metadata Analysis 1 Introduction The mega-trend of digitisation affects all areas of society, including business and science. Digitisation is accelerated by ubiquitous access to the Internet, the global, distributed information network. -

Central Library: IIT GUWAHATI
Central Library, IIT GUWAHATI BACK VOLUME LIST DEPARTMENTWISE (as on 20/04/2012) COMPUTER SCIENCE & ENGINEERING S.N. Jl. Title Vol.(Year) 1. ACM Jl.: Computer Documentation 20(1996)-26(2002) 2. ACM Jl.: Computing Surveys 30(1998)-35(2003) 3. ACM Jl.: Jl. of ACM 8(1961)-34(1987); 43(1996);45(1998)-50 (2003) 4. ACM Magazine: Communications of 39(1996)-46#3-12(2003) ACM 5. ACM Magazine: Intelligence 10(1999)-11(2000) 6. ACM Magazine: netWorker 2(1998)-6(2002) 7. ACM Magazine: Standard View 6(1998) 8. ACM Newsletters: SIGACT News 27(1996);29(1998)-31(2000) 9. ACM Newsletters: SIGAda Ada 16(1996);18(1998)-21(2001) Letters 10. ACM Newsletters: SIGAPL APL 28(1998)-31(2000) Quote Quad 11. ACM Newsletters: SIGAPP Applied 4(1996);6(1998)-8(2000) Computing Review 12. ACM Newsletters: SIGARCH 24(1996);26(1998)-28(2000) Computer Architecture News 13. ACM Newsletters: SIGART Bulletin 7(1996);9(1998) 14. ACM Newsletters: SIGBIO 18(1998)-20(2000) Newsletters 15. ACM Newsletters: SIGCAS 26(1996);28(1998)-30(2000) Computers & Society 16. ACM Newsletters: SIGCHI Bulletin 28(1996);30(1998)-32(2000) 17. ACM Newsletters: SIGCOMM 26(1996);28(1998)-30(2000) Computer Communication Review 1 Central Library, IIT GUWAHATI BACK VOLUME LIST DEPARTMENTWISE (as on 20/04/2012) COMPUTER SCIENCE & ENGINEERING S.N. Jl. Title Vol.(Year) 18. ACM Newsletters: SIGCPR 17(1996);19(1998)-20(1999) Computer Personnel 19. ACM Newsletters: SIGCSE Bulletin 28(1996);30(1998)-32(2000) 20. ACM Newsletters: SIGCUE Outlook 26(1998)-27(2001) 21. -
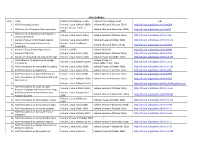
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Robert Grossman Curriculum Vita
Robert Grossman Curriculum Vita Summary Robert Grossman is a faculty member at the University of Chicago, where he is the Director of Informatics at the Institute for Genomics and Systems Biology, a Senior Fellow at the Computation Institute, and a Professor of Medicine in the Section of Genetic Medicine. His research group focuses on bioinformatics, data mining, cloud computing, data intensive computing, and related areas. He is also the Chief Research Informatics Officer of the Biological Sciences Division. From 1998 to 2010, he was the Director of the National Center for Data Mining at the University of Illinois at Chicago (UIC). From 1984 to 1988 he was a faculty member at the University of California at Berkeley. He received a Ph.D. from Princeton in 1985 and a B.A. from Harvard in 1980. He is also the Founder and a Partner of Open Data Group. Open Data provides management consulting and outsourced analytic services for businesses and organizations. At Open Data, he has led the development of analytic systems that are used by millions of people daily all over the world. He has published over 150 papers in refereed journals and proceedings and edited seven books on data intensive computing, bioinformatics, cloud computing, data mining, high performance computing and networking, and Internet technologies. Prior to founding the Open Data Group, he founded Magnify, Inc. in 1996. Magnify provides data mining solutions to the insurance industry. Grossman was Magnify’s CEO until 2001 and its Chairman until it was sold to ChoicePoint in 2005. ChoicePoint was acquired by LexisNexis in 2008. -

FCRC 2011 June 4 - 11, San Jose, CA TIMELINE SCHEDULE
FCRC 2011 June 4 - 11, San Jose, CA TIMELINE SCHEDULE Sponsored by Corporate Support Provided by Gold Silver CONFERENCE/WORKSHOP/EVENT ACRONYMS & DATES Dates Full Name Dates Full Name 3DAPAS 8 A Workshop on Dynamic Distrib. Data-Intensive Applications, Programming Abstractions, & Systs (HPDC) IWQoS 6--7 Int. Workshop on Quality of Service (ACM SIGMETRICS and IEEE Communications Society) A4MMC 4 Applications fo Multi and Many Core Processors: Analysis, Implementation, and Performance (ISCA) LSAP 8 P Workshop on Large-Scale System and Application Performance (HPDC) AdAuct 5 Ad Auction Workshop (EC) MAMA 8 Workshop on Mathematical Performance Modeling and Analysis (METRICS) AMAS-BT 4 P Workship on Architectural and Microarchitectural Support for Binary Translation (ISCA) METRICS 7--11 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems BMD 5 Workshop on Bayesian Mechanism Design (EC) MoBS 5 A Workshop on Modeling, Benchmarking, and Simulation (ISCA) CARD 5 P Workshop on Computer Architecture Research Directions (ISCA) MRA 8 Int. Workshop on MapReduce and its Applications (HPDC) CBP 4 P JILP Workshop on Computer Architecture Competitions: Championship Branch Prediction (ISCA) MSPC 5 Memory Systems Performance and Correctness (PLDI) Complex 8--10 IEEE Conference on Computational Complexity (IEEE TCMFC) NDCA 5 A New Directions in Computer Architecture (ISCA) CRA-W 4--5 CRA-W Career Mentoring Workshop NetEcon 6 Workshop on the Economics of Networks, Systems, and Computation (EC) DIDC 8 P Int. Workshop on Data-Intensive Distributed Computing (HPDC) PLAS 5 Programming Languages and Analysis for Security Workshop (PLDI) EAMA 4 Workshop on Emerging Applications and Manycore Architectures (ISCA) PLDI 4--8 ACM SIGPLAN Conference on Programming Language Design and Implementation EC 5--9 ACM Conference on Electronic Commerce (ACM SIGECOM) PODC 6--8 ACM SIGACT-SIGOPT Symp.