Social Media Identity Deception Detection: a Survey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Web Hacking 101 How to Make Money Hacking Ethically
Web Hacking 101 How to Make Money Hacking Ethically Peter Yaworski © 2015 - 2016 Peter Yaworski Tweet This Book! Please help Peter Yaworski by spreading the word about this book on Twitter! The suggested tweet for this book is: Can’t wait to read Web Hacking 101: How to Make Money Hacking Ethically by @yaworsk #bugbounty The suggested hashtag for this book is #bugbounty. Find out what other people are saying about the book by clicking on this link to search for this hashtag on Twitter: https://twitter.com/search?q=#bugbounty For Andrea and Ellie. Thanks for supporting my constant roller coaster of motivation and confidence. This book wouldn’t be what it is if it were not for the HackerOne Team, thank you for all the support, feedback and work that you contributed to make this book more than just an analysis of 30 disclosures. Contents 1. Foreword ....................................... 1 2. Attention Hackers! .................................. 3 3. Introduction ..................................... 4 How It All Started ................................. 4 Just 30 Examples and My First Sale ........................ 5 Who This Book Is Written For ........................... 7 Chapter Overview ................................. 8 Word of Warning and a Favour .......................... 10 4. Background ...................................... 11 5. HTML Injection .................................... 14 Description ....................................... 14 Examples ........................................ 14 1. Coinbase Comments ............................. -

Declaration of Jason Bartlett in Support of 86 MOTION For
Apple Inc. v. Samsung Electronics Co. Ltd. et al Doc. 88 Att. 34 Exhibit 34 Dockets.Justia.com Apple iPad review -- Engadget Page 1 of 14 Watch Gadling TV's "Travel Talk" and get all the latest travel news! MAIL You might also like: Engadget HD, Engadget Mobile and More MANGO PREVIEW WWDC 2011 E3 2011 COMPUTEX 2011 ASUS PADFONE GALAXY S II Handhelds, Tablet PCs Apple iPad review By Joshua Topolsky posted April 3rd 2010 9:00AM iPad Apple $499-$799 4/3/10 8/10 Finally, the Apple iPad review. The name iPad is a killing word -- more than a product -- it's a statement, an idea, and potentially a prime mover in the world of consumer electronics. Before iPad it was called the Best-in-class touchscreen Apple Tablet, the Slate, Canvas, and a handful of other guesses -- but what was little more than rumor Plugged into Apple's ecosystems and speculation for nearly ten years is now very much a reality. Announced on January 27th to a Tremendous battery life middling response, Apple has been readying itself for what could be the most significant product launch in its history; the making (or breaking) of an entirely new class of computer for the company. The iPad is No multitasking something in between its monumental iPhone and wildly successful MacBook line -- a usurper to the Web experience hampered by lack of Flash Can't stand-in for dedicated laptop netbook throne, and possibly a sign of things to come for the entire personal computer market... if Apple delivers on its promises. -

Bostonbarjournal
January/February 2009 BostonBarA Publication of the Boston Bar Association Journal Web 2.0 and the Lost Generation Web 2.0: What’s Evidence Between “Friends”? Q W The New E-Discovery Frontier — Seeking Facts in the Web 2.0 World (and Other Miscellany) do you E Twitter? Massachusetts Adopts Comprehensive Information Security Regulations updated 3 minutes ago Law Firm Added You as a Friend What Happens When the College Rumor Mill Goes Online? R 77º The Future of Online THIS AGREE- Networking MENT (hereinafter referred to as the “Agreement”) made and entered into this ____________ day of Y tweet! T Boston Bar Journal • January/February 2009 1 Boston Bar Journal Volume 53, Number 1 January/February 2009 Contents President’s Page 2 Officers of the Boston Bar Association President, Kathy B. Weinman President-Elect, John J. Regan BBJ Editorial Policy 3 Vice President, Donald R. Frederico Treasurer, Lisa C. Goodheart Secretary, James D. Smeallie Departments Members of the Council Opening Statement 4 Lisa M. Cukier Damon P. Hart Edward Notis-McConarty Paul T. Dacier Christine Hughes Maureen A. O’Rourke Web 2.0 and the Lost Generation Anthony M. Doniger Julia Huston Laura S. Peabody Bruce E. Falby Kimberly Y. Jones Mala M. Rafik By Donald R. Frederico George P. Field Wayne M. Kennard Rebecca B. Ransom Laurie Flynn Grace H. Lee Douglas B. Rosner First Principles 5 Lawrence M. Friedman James D. Masterman Charles E. Walker, Jr. Elizabeth Shea Fries Wm. Shaw McDermott Mark J. Warner Web 2.0: What’s Evidence Randy M. Gioia Between “Friends”? Past Presidents By Seth P. -
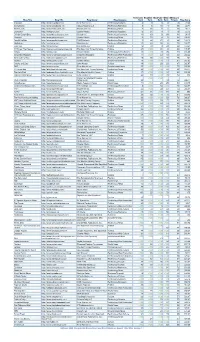
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -

Revista Comunicação E Sociedade, Vol. 25
Comunicação e Sociedade, vol. 25, 2014, pp. 252 – 266 The (non)regulation of the blogosphere: the ethics of online debate Elsa Costa e Silva [email protected] Centro de Estudos de Comunicação e Sociedade, Universidade do Minho, Instituto de Ciências Sociais, 4710-057 Braga, Portugal Abstract New technologies have enabled innovative possibilities of communication, but have also imposed new upon matters of ethics, particularly in regards to platforms such as blogs. This ar- ticle builds upon the reflections and experiences on this issue, in an attempt to map and analyse the ethical questions underlying the Portuguese blogosphere. In order to reflect on the possibil- ity and opportunity to create a code of ethics for bloggers, attention is permanently paid to the political blogosphere. Keywords Code of conduct; values; political blogs; freedom of expression 1. Introduction The debate about ethics in communication (a theme that is perhaps as old as the first reflections on the human ability to interact with others) remains extremely dynamic in contemporary societies, fuelled by innovative technological capabilities that bring new challenges to this endless questioning. Ethics is a construction whose pillars oscillate between different perspectives (Fidalgo, 2007), ranging from a greater primacy of the freedom of the ‘I’, to a primacy of the collective responsibility, from the justification by the norms (to do that which is correct) to the justification by the purposes (the good to be achieved). Values and rules underlie ethics, providing a standard for human behaviour and forms of procedure. It is never a finished process, but the result of ongoing tensions and negotiations between interested members of the community (Christofoletti, 2011). -

Flickr: a Case Study of Web2.0, Aslib Proceedings, 60 (5), Pp
promoting access to White Rose research papers Universities of Leeds, Sheffield and York http://eprints.whiterose.ac.uk/ This is an author produced version of a paper published in Aslib Proceedings. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/9043 Published paper Cox, A.M. (2008) Flickr: A case study of Web2.0, Aslib Proceedings, 60 (5), pp. 493-516 http://dx.doi.org/10.1108/00012530810908210 White Rose Research Online [email protected] Flickr: A case study of Web2.0 Andrew M. Cox University of Sheffield, UK [email protected] Abstract The “photosharing” site Flickr is one of the most commonly cited examples used to define Web2.0. This paper explores where Flickr’s real novelty lies, examining its functionality and its place in the world of amateur photography. The paper draws on a wide range of sources including published interviews with its developers, user opinions expressed in forums, telephone interviews and content analysis of user profiles and activity. Flickr’s development path passes from an innovative social game to a relatively familiar model of a website, itself developed through intense user participation but later stabilising with the reassertion of a commercial relationship to the membership. The broader context of the impact of Flickr is examined by looking at the institutions of amateur photography and particularly the code of pictorialism promoted by the clubs and industry during the C20th. The nature of Flickr as a benign space is premised on the way the democratic potential of photography is controlled by such institutions. -

3.3.5.Haulath.Pdf
CONTENTS SL. PAGE NO. ARTICLE NO 1 DATA PRE-PROCESSING FOR EFFECTIVE INTRUSION DETECTION RIYAD AM 5 2. AN ENHANCED AUTHENTICATION SYSTEM USING MULTIMODAL BIOMETRICS MOHAMED BASHEER. K.P DR.T. ABDUL RAZAK 9 6. GRADIENT FEATURE EXTRACTION USING FOR MALAYALAM PALM LEAF DOCUMENT IMAGEGEENA K.P 19 7. INTERNET ADDICTION JESNA K 23 8. VANETS AND ITS APPLICATION: PRESENT AND FUTURE.JISHA K 26 9. DISTRIBUTED OPERATING SYSTEM AND AMOEBAKHAIRUNNISA K 30 5. INDIVIDUAL SOCIAL MEDIA USAGE POLICY: ORGANIZATION INFORMATION SECURITY THROUGH DATA MINING REJEESH.E1, MOHAMED JAMSHAD K2, ANUPAMA M3 34 3. APPLICATION OF DATA MINING TECHNIQUES ON NETWORK SECURITY O.JAMSHEELA 38 4. SECURITY PRIVACY AND TRUST IN SOCIAL MEDIAMS HAULATH K 43 10. SECURITY AND PRIVACY ISSUES AND SOLUTIONS FOR WIRELESS SYSTEM NETWORKS (WSN) AND RFID RESHMA M SHABEER THIRUVAKALATHIL 45 11. ARTIFICIAL INTELLIGENCE IN CYBER DEFENSESHAMEE AKTHAR. K. ASKARALI. K.T 51 SECURITY PRIVACY AND TRUST IN SOCIAL MEDIA Haulath K, Assistant professor, Department of Computer Science, EMEA College, Kondotty. [email protected] Abstract— Channels social interactions using 2. Social Blogs extremely accessible and scalable publishing A blog (a truncation of the expression weblog) is a methods over the internet. Connecting individuals, discussion or informational site published on communities, organization. Exchange of idea Sharing the World Wide Web consisting of discrete entries message and collaboration through security privacy (“posts”) typically displayed in reverse chronological and trust. order (the most recent post appears first). Until 2009, Classification of Social Media blogs were usually the work of a single individual, occasionally of a small group, and often covered a 1. -

Handbook for Bloggers and Cyber-Dissidents
HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS REPORTERS WITHOUT BORDERS MARCH 2008 Файл загружен с http://www.ifap.ru HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS CONTENTS © 2008 Reporters Without Borders 04 BLOGGERS, A NEW SOURCE OF NEWS Clothilde Le Coz 07 WHAT’S A BLOG ? LeMondedublog.com 08 THE LANGUAGE OF BLOGGING LeMondedublog.com 10 CHOOSING THE BEST TOOL Cyril Fiévet, Marc-Olivier Peyer and LeMondedublog.com 16 HOW TO SET UP AND RUN A BLOG The Wordpress system 22 WHAT ETHICS SHOULD BLOGUEURS HAVE ? Dan Gillmor 26 GETTING YOUR BLOG PICKED UP BY SEARCH-ENGINES Olivier Andrieu 32 WHAT REALLY MAKES A BLOG SHINE ? Mark Glaser 36 P ERSONAL ACCOUNTS • SWITZERLAND: “” Picidae 40 • EGYPT: “When the line between journalist and activist disappears” Wael Abbas 43 • THAILAND : “The Web was not designed for bloggers” Jotman 46 HOW TO BLOG ANONYMOUSLY WITH WORDPRESS AND TOR Ethan Zuckerman 54 TECHNICAL WAYS TO GET ROUND CENSORSHIP Nart Villeneuve 71 ENS URING YOUR E-MAIL IS TRULY PRIVATE Ludovic Pierrat 75 TH E 2008 GOLDEN SCISSORS OF CYBER-CENSORSHIP Clothilde Le Coz 3 I REPORTERS WITHOUT BORDERS INTRODUCTION BLOGGERS, A NEW SOURCE OF NEWS By Clothilde Le Coz B loggers cause anxiety. Governments are wary of these men and women, who are posting news, without being professional journalists. Worse, bloggers sometimes raise sensitive issues which the media, now known as "tradition- al", do not dare cover. Blogs have in some countries become a source of news in their own right. Nearly 120,000 blogs are created every day. Certainly the blogosphere is not just adorned by gems of courage and truth. -

UPDATED Activate Outlook 2021 FINAL DISTRIBUTION Dec
ACTIVATE TECHNOLOGY & MEDIA OUTLOOK 2021 www.activate.com Activate growth. Own the future. Technology. Internet. Media. Entertainment. These are the industries we’ve shaped, but the future is where we live. Activate Consulting helps technology and media companies drive revenue growth, identify new strategic opportunities, and position their businesses for the future. As the leading management consulting firm for these industries, we know what success looks like because we’ve helped our clients achieve it in the key areas that will impact their top and bottom lines: • Strategy • Go-to-market • Digital strategy • Marketing optimization • Strategic due diligence • Salesforce activation • M&A-led growth • Pricing Together, we can help you grow faster than the market and smarter than the competition. GET IN TOUCH: www.activate.com Michael J. Wolf Seref Turkmenoglu New York [email protected] [email protected] 212 316 4444 12 Takeaways from the Activate Technology & Media Outlook 2021 Time and Attention: The entire growth curve for consumer time spent with technology and media has shifted upwards and will be sustained at a higher level than ever before, opening up new opportunities. Video Games: Gaming is the new technology paradigm as most digital activities (e.g. search, social, shopping, live events) will increasingly take place inside of gaming. All of the major technology platforms will expand their presence in the gaming stack, leading to a new wave of mergers and technology investments. AR/VR: Augmented reality and virtual reality are on the verge of widespread adoption as headset sales take off and use cases expand beyond gaming into other consumer digital activities and enterprise functionality. -

Weekly Wireless Report September 23, 2016
Week Ending: Weekly Wireless Report September 23, 2016 This Week’s Stories Yahoo Says Information On At Least 500 Million User Accounts Inside This Issue: Was Stolen September 22, 2016 This Week’s Stories Yahoo Says Information On Internet company says it believes the 2014 hack was done by a state-sponsored actor; potentially the At Least 500 Million User biggest data breach on record. Accounts Was Stolen Yahoo Inc. is blaming “state-sponsored” hackers for what may be the largest-ever theft of personal You Can Now Exchange user data. Your Recalled Samsung Galaxy Note 7 The internet company, which has agreed to sell its core business to Verizon Communications Inc., said Products & Services Thursday that hackers penetrated its network in late 2014 and stole personal data on more than 500 million users. The stolen data included names, email addresses, dates of birth, telephone numbers Facebook Messenger Gets and encrypted passwords, Yahoo said. Polls And Now Encourages Peer-To-Peer Payments Yahoo said it believes that the hackers are no longer in its corporate network. The company said it Allo Brings Google’s didn't believe that unprotected passwords, payment-card data or bank-account information had been ‘Assistant’ To Your Phone affected. Today Computer users have grown inured to notices that a tech company, retailer or other company with Emerging Technology which they have done business had been hacked. But the Yahoo disclosure is significant because the iHeartRadio Is Finally company said it was the work of another nation, and because it raises questions about the fate of the Getting Into On-Demand $4.8 billion Verizon deal, which was announced on July 25. -
Sign up Now Or Login with Your Facebook Account'' - Look Familiar? You Can Now Do the Same Thing with Your Pinterest Account
Contact us Visit us Visit our website ''Sign up now or Login with your Facebook Account'' - Look familiar? You can now do the same thing with your Pinterest account. With this, users can easily Pin collections and oer some new ways to pin images. Right now this feature is only avail- able on two apps, but as Pinterest said, its early tests have shown that this integration increases shares to Pinterest boards by 132 percent. We can expect more apps will open up with this feature to nurture our Pinterest ob- session. View More Your Facebook's News Feed is like a billboard of your life and for years, it has been powered by automated software that tracks your actions to show you the posts you will most likely engage with, or as Facbook's FAQ said, ''the posts you will nd interesting''. But now you can say goodbye to guesswork. Facebook has cre- ated a new function called ''See First''. Simply add the Pages, friends or public gures’ proles to your See First list and it will revamp your News Feed Prefer- ences. Getting added to that list guarantees all their posts will appear at the top of a user’s News Feed with a blue star. View More Youku Tudou, which has been de- scribed as China’s answer to YouTube and boasts 185 million unique users per month, will air its rst foreign TV series approved under new rules from China’s media regulator, SAP- PRFT. The Korean romantic comedy entitled "Hyde, Jekyll, and Me'' will be available this weekend. -

Home Reviews Gear Gaming Entertainment Tomorrow Audio Video Deals Buyer's Guide
11/2/2020 MIT tests autonomous 'Roboat' that can carry two passengers | Engadget Login Home Reviews Gear Gaming Entertainment Tomorrow Audio Video Deals Buyer's Guide Log in Sign up 3 related articles Login https://www.engadget.com/mit-autonomous-roboat-ii-carries-passengers-140145138.html 1/10 11/2/2020 MIT tests autonomous 'Roboat' that can carry two passengers | Engadget Latest in Tomorrow Daimler and Volvo team up to make fuel cells for trucks and generators 1h ago Image credit: MIT Csail MIT tests autonomous 'Roboat' that can carry two passengers The half-scale Roboat II is being tested in Amsterdam's canals Nathan Ingraham 'Pristine' October 26, 2020 meteorite 2 255 may provide Comments Shares clues to the origins of our solar system 6h ago 3 related articles Login https://www.engadget.com/mit-autonomous-roboat-ii-carries-passengers-140145138.html 2/10 11/2/2020 MIT tests autonomous 'Roboat' that can carry two passengers | Engadget Disney robot with human- like gaze is equal parts uncanny and horrifying 10.31.20 Modified drones help scientists better predict volcanic eruptions MIT Csail 10.30.20 We’ve heard plenty about the potential of autonomous vehicles in recent years, but MIT is thinking about different forms of self-driving transportation. For the last five years, MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and the Senseable City Lab have been working on a fleet of autonomous boats to deploy in Amsterdam. Last year, we saw the autonomous “roboats” that could assemble themselves into a series of floating structures for various uses, and today CSAIL is unveiling the “Roboat II.” What makes this one particularly notable is that it’s the first that can carry passengers.