11-411 Natural Language Processing Overview
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Protein Interaction Extraction Systemusing a Link Grammar Parser from Biomedical Abstracts
World Academy of Science, Engineering and Technology International Journal of Biomedical and Biological Engineering Vol:1, No:5, 2007 PIELG: A Protein Interaction Extraction System using a Link Grammar Parser from Biomedical Abstracts Rania A. Abul Seoud, Nahed H. Solouma, Abou-Baker M. Youssef, and Yasser M. Kadah, Senior Member, IEEE failure. Applications that repair or replace portions of or Abstract—Due to the ever growing amount of publications about whole living tissues (e.g., bone, dentine, or bladder) using protein-protein interactions, information extraction from text is living cells is named Tissue Engineering (TE). For example, increasingly recognized as one of crucial technologies in dentine formation is the process of regenerating dental tissues bioinformatics. This paper presents a Protein Interaction Extraction by tissue engineering principles and technology. Dentine System using a Link Grammar Parser from biomedical abstracts formation is governed by biological mediators or growth (PIELG). PIELG uses linkage given by the Link Grammar Parser to start a case based analysis of contents of various syntactic roles as factors (protein) and interactions amongst different proteins. well as their linguistically significant and meaningful combinations. Dentine formation needs the support of continuous updated The system uses phrasal-prepositional verbs patterns to overcome information about protein-protein interactions. preposition combinations problems. The recall and precision are Researches in the last decade have resulted in the 74.4% and 62.65%, respectively. Experimental evaluations with two production of a large amount of information about protein other state-of-the-art extraction systems indicate that PIELG system functions involved in dentine formation process. That achieves better performance. -

Aviation Classics Magazine
Avro Vulcan B2 XH558 taxies towards the camera in impressive style with a haze of hot exhaust fumes trailing behind it. Luigino Caliaro Contents 6 Delta delight! 8 Vulcan – the Roman god of fire and destruction! 10 Delta Design 12 Delta Aerodynamics 20 Virtues of the Avro Vulcan 62 Virtues of the Avro Vulcan No.6 Nos.1 and 2 64 RAF Scampton – The Vulcan Years 22 The ‘Baby Vulcans’ 70 Delta over the Ocean 26 The True Delta Ladies 72 Rolling! 32 Fifty years of ’558 74 Inside the Vulcan 40 Virtues of the Avro Vulcan No.3 78 XM594 delivery diary 42 Vulcan display 86 National Cold War Exhibition 49 Virtues of the Avro Vulcan No.4 88 Virtues of the Avro Vulcan No.7 52 Virtues of the Avro Vulcan No.5 90 The Council Skip! 53 Skybolt 94 Vulcan Furnace 54 From wood and fabric to the V-bomber 98 Virtues of the Avro Vulcan No.8 4 aviationclassics.co.uk Left: Avro Vulcan B2 XH558 caught in some atmospheric lighting. Cover: XH558 banked to starboard above the clouds. Both John M Dibbs/Plane Picture Company Editor: Jarrod Cotter [email protected] Publisher: Dan Savage Contributors: Gary R Brown, Rick Coney, Luigino Caliaro, Martyn Chorlton, Juanita Franzi, Howard Heeley, Robert Owen, François Prins, JA ‘Robby’ Robinson, Clive Rowley. Designers: Charlotte Pearson, Justin Blackamore Reprographics: Michael Baumber Production manager: Craig Lamb [email protected] Divisional advertising manager: Tracey Glover-Brown [email protected] Advertising sales executive: Jamie Moulson [email protected] 01507 529465 Magazine sales manager: -

Implementing a Portable Clinical NLP System with a Common Data Model: a Lisp Perspective
Implementing a portable clinical NLP system with a common data model: a Lisp perspective The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Luo, Yuan, and Peter Szolovits, "Implementing a portable clinical NLP system with a common data model: a Lisp perspective." Proceedings, 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM 2018), December 3-6, 2018, Madrid, Spain (Piscataway, N.J.: IEEE, 2018): doi 10.1109/BIBM.2018.8621521 ©2018 Author(s) As Published 10.1109/BIBM.2018.8621521 Publisher Institute of Electrical and Electronics Engineers (IEEE) Version Original manuscript Citable link https://hdl.handle.net/1721.1/124439 Terms of Use Creative Commons Attribution-Noncommercial-Share Alike Detailed Terms http://creativecommons.org/licenses/by-nc-sa/4.0/ Implementing a Portable Clinical NLP System with a Common Data Model – a Lisp Perspective Yuan Luo* Peter Szolovits* Dept. of Preventive Medicine CSAIL Northwestern University MIT Chicago, USA Cambridge, USA [email protected] [email protected] Abstract— This paper presents a Lisp architecture for a annotations, often in idiosyncratic representations. This makes portable NLP system, termed LAPNLP, for processing clinical it quite difficult to chain together sequences of operations. Alt- notes. LAPNLP integrates multiple standard, customized and hough several recent projects have achieved reasonable in-house developed NLP tools. Our system facilitates portability success in analyzing certain types of clinical narratives [3-6], across different institutions and data systems by incorporating an enriched Common Data Model (CDM) to standardize neces- efforts towards a common data model (CDM) to ensure port- sary data elements. -

Chapter 14: Dependency Parsing
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright © 2021. All rights reserved. Draft of September 21, 2021. CHAPTER 14 Dependency Parsing The focus of the two previous chapters has been on context-free grammars and constituent-based representations. Here we present another important family of dependency grammars grammar formalisms called dependency grammars. In dependency formalisms, phrasal constituents and phrase-structure rules do not play a direct role. Instead, the syntactic structure of a sentence is described solely in terms of directed binary grammatical relations between the words, as in the following dependency parse: root dobj det nmod (14.1) nsubj nmod case I prefer the morning flight through Denver Relations among the words are illustrated above the sentence with directed, labeled typed dependency arcs from heads to dependents. We call this a typed dependency structure because the labels are drawn from a fixed inventory of grammatical relations. A root node explicitly marks the root of the tree, the head of the entire structure. Figure 14.1 shows the same dependency analysis as a tree alongside its corre- sponding phrase-structure analysis of the kind given in Chapter 12. Note the ab- sence of nodes corresponding to phrasal constituents or lexical categories in the dependency parse; the internal structure of the dependency parse consists solely of directed relations between lexical items in the sentence. These head-dependent re- lationships directly encode important information that is often buried in the more complex phrase-structure parses. For example, the arguments to the verb prefer are directly linked to it in the dependency structure, while their connection to the main verb is more distant in the phrase-structure tree. -

Development of a Persian Syntactic Dependency Treebank
Development of a Persian Syntactic Dependency Treebank Mohammad Sadegh Rasooli Manouchehr Kouhestani Amirsaeid Moloodi Department of Computer Science Department of Linguistics Department of Linguistics Columbia University Tarbiat Modares University University of Tehran New York, NY Tehran, Iran Tehran, Iran [email protected] [email protected] [email protected] Abstract tions in tasks such as machine translation. Depen- dency treebanks are collections of sentences with This paper describes the annotation process their corresponding dependency trees. In the last and linguistic properties of the Persian syn- decade, many dependency treebanks have been de- tactic dependency treebank. The treebank veloped for a large number of languages. There are consists of approximately 30,000 sentences at least 29 languages for which at least one depen- annotated with syntactic roles in addition to morpho-syntactic features. One of the unique dency treebank is available (Zeman et al., 2012). features of this treebank is that there are al- Dependency trees are much more similar to the hu- most 4800 distinct verb lemmas in its sen- man understanding of language and can easily rep- tences making it a valuable resource for ed- resent the free word-order nature of syntactic roles ucational goals. The treebank is constructed in sentences (Kubler¨ et al., 2009). with a bootstrapping approach by means of available tagging and parsing tools and man- Persian is a language with about 110 million ually correcting the annotations. The data is speakers all over the world (Windfuhr, 2009), yet in splitted into standard train, development and terms of the availability of teaching materials and test set in the CoNLL dependency format and annotated data for text processing, it is undoubt- is freely available to researchers. -

Downloads." the Open Information Security Foundation
Performance Testing Suricata The Effect of Configuration Variables On Offline Suricata Performance A Project Completed for CS 6266 Under Jonathon T. Giffin, Assistant Professor, Georgia Institute of Technology by Winston H Messer Project Advisor: Matt Jonkman, President, Open Information Security Foundation December 2011 Messer ii Abstract The Suricata IDS/IPS engine, a viable alternative to Snort, has a multitude of potential configurations. A simplified automated testing system was devised for the purpose of performance testing Suricata in an offline environment. Of the available configuration variables, seventeen were analyzed independently by testing in fifty-six configurations. Of these, three variables were found to have a statistically significant effect on performance: Detect Engine Profile, Multi Pattern Algorithm, and CPU affinity. Acknowledgements In writing the final report on this endeavor, I would like to start by thanking four people who made this project possible: Matt Jonkman, President, Open Information Security Foundation: For allowing me the opportunity to carry out this project under his supervision. Victor Julien, Lead Programmer, Open Information Security Foundation and Anne-Fleur Koolstra, Documentation Specialist, Open Information Security Foundation: For their willingness to share their wisdom and experience of Suricata via email for the past four months. John M. Weathersby, Jr., Executive Director, Open Source Software Institute: For allowing me the use of Institute equipment for the creation of a suitable testing -

Lexicalization and Grammar Development
University of Pennsylvania ScholarlyCommons IRCS Technical Reports Series Institute for Research in Cognitive Science April 1995 Lexicalization and Grammar Development B. Srinivas University of Pennsylvania Dania Egedi University of Pennsylvania Christine D. Doran University of Pennsylvania Tilman Becker University of Pennsylvania Follow this and additional works at: https://repository.upenn.edu/ircs_reports Srinivas, B.; Egedi, Dania; Doran, Christine D.; and Becker, Tilman, "Lexicalization and Grammar Development" (1995). IRCS Technical Reports Series. 138. https://repository.upenn.edu/ircs_reports/138 University of Pennsylvania Institute for Research in Cognitive Science Technical Report No. IRCS-95-12. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/ircs_reports/138 For more information, please contact [email protected]. Lexicalization and Grammar Development Abstract In this paper we present a fully lexicalized grammar formalism as a particularly attractive framework for the specification of natural language grammars. We discuss in detail Feature-based, Lexicalized Tree Adjoining Grammars (FB-LTAGs), a representative of the class of lexicalized grammars. We illustrate the advantages of lexicalized grammars in various contexts of natural language processing, ranging from wide-coverage grammar development to parsing and machine translation. We also present a method for compact and efficientepr r esentation of lexicalized trees. In diesem Beitrag präsentieren wir einen völlig lexikalisierten Grammatikformalismus als eine besonders geeignete Basis für die Spezifikation onv Grammatiken für natürliche Sprachen. Wir stellen feature- basierte, lexikalisierte Tree Adjoining Grammars (FB-LTAGs) vor, ein Vertreter der Klasse der lexikalisierten Grammatiken. Wir führen die Vorteile von lexikalisierten Grammatiken in verschiedenen Bereichen der maschinellen Sprachverarbeitung aus; von der Entwicklung von Grammatiken für weite Sprachbereiche über Parsing bis zu maschineller Übersetzung. -

Parsing Aligned Parallel Corpus by Projecting Syntactic Relations from Annotated Source Corpus
Parsing Aligned Parallel Corpus by Projecting Syntactic Relations from Annotated Source Corpus Shailly Goyal Niladri Chatterjee Department of Mathematics Indian Institute of Technology Delhi Hauz Khas, New Delhi - 110 016, India {shailly goyal, niladri iitd}@yahoo.com Abstract approaches either use examples from the same lan- guage, e.g., (Bod et al., 2003; Streiter, 2002), or Example-based parsing has already been they try to imitate the parse of a given sentence proposed in literature. In particular, at- using the parse of the corresponding sentence in tempts are being made to develop tech- some other language (Hwa et al., 2005; Yarowsky niques for language pairs where the source and Ngai, 2001). In particular, Hwa et al. (2005) and target languages are different, e.g. have proposed a scheme called direct projection Direct Projection Algorithm (Hwa et al., algorithm (DPA) which assumes that the relation 2005). This enables one to develop parsed between two words in the source language sen- corpus for target languages having fewer tence is preserved across the corresponding words linguistic tools with the help of a resource- in the parallel target language. This is called Di- rich source language. The DPA algo- rect Correspondence Assumption (DCA). rithm works on the assumption of Di- However, with respect to Indian languages we rect Correspondence which simply means observed that the DCA does not hold good all the that the relation between two words of time. In order to overcome the difficulty, in this the source language sentence can be pro- work, we propose an algorithm based on a vari- jected directly between the correspond- ation of the DCA, which we call pseudo Direct ing words of the parallel target language Correspondence Assumption (pDCA). -

Dependency-Length Minimization in Natural and Artificial Languages*
Journal of Quantitative Linguistics 2008, Volume 15, Number 3, pp. 256 – 282 DOI: 10.1080/09296170802159512 Dependency-Length Minimization in Natural and Artificial Languages* David Temperley Eastman School of Music at the University of Rochester ABSTRACT A wide range of evidence points to a preference for syntactic structures in which dependencies are short. Here we examine the question: what kinds of dependency configurations minimize dependency length? We consider two well-established principles of dependency-length minimization; that dependencies should be consistently right-branching or left-branching, and that shorter dependent phrases should be closer to the head. We also add a third, novel, principle; that some ‘‘opposite-branching’’ of one-word phrases is desirable. In a series of computational experiments, using unordered dependency trees gathered from written English, we examine the effect of these three principles on dependency length, and show that all three contribute significantly to dependency-length reduction. Finally, we present what appears to be the optimal ‘‘grammar’’ for dependency-length minimization. INTRODUCTION A wide range of evidence from diverse areas of linguistic research points to a preference for syntactic structures in which dependencies between related words are short.1 This preference is reflected in numerous psycholinguistic phenomena: structures with long depen- dencies appear to cause increased complexity in comprehen- sion and tend to be avoided in production. The preference for shorter dependencies has also been cited as an explanation for certain *Address correspondence to: David Temperley, Eastman School of Music, 26 Gibbs Street, Rochester, NY 14604. Tel: 585-274-1557. E-mail: [email protected] 1Thanks to Daniel Gildea for valuable comments on a draft of this paper. -

Natural Language Processing (NLP): Written and Oral Involves Processing of Written Text Using Computer Models at Lexical, Syntactic, and Semantic Level
Natural Language Processing (NLP): written and oral Involves processing of written text using computer models at lexical, syntactic, and semantic level. Introduction: 1. Understanding (of language) – map text/speech to immediately useful form. 2. Generation (of language) Sentence Analysis Phases: 1. Morphological Analysis: extracts root word from declined/inflection form of word after removing suffices and prefixes. 2. Syntactic Analysis: builds a structural description of a sentence using MAP (Morphological Analysis Process) based on grammatical rules, called Parsing. 3. Semantic Analysis: Creates a semantic structure by ascribing a literal meaning to sentence using parse structure obtained in syntactic phase. It maps individual words into corresponding objects in the knowledge base. Focus is on creation of target representation of the meaning of a sentence. 4. Pragmatic Analysis: to establish meaning of a sentence in different contexts. 5. Discourse Analysis: Interpretation based on belief during conversation. Grammars and Parsers: Parsing: Process of analyzing an input sequence in order to determine its structure with respect to a given grammar. Types of Parsing: 1. Rule-based parsing: syntactic structure of language is provided in the form of linguistic rules which can be coded as production rules that are similar to context-free rules. 1. Top-down parsing: Start with start symbol and apply grammar rules in the forward direction until the terminal symbols of the parse tree correspond to the words in the sentence. 2. Bottom-up parsing: Start with the words in the sentence in the sentence and apply grammar rules in the backward direction until a single tree is produced whose root matches with the start symbol. -

Report on the Progress of Civil Aviation 1939 – 1945
Report on the Progress of Civil Aviation 1939 – 1945 Prepared by John Wilson from contemporary documents in the library of the Civil Aviation Authority Foreword Page 1 Chapter I 1939: Civil Aviation after the outbreak of War Page 4 Chapter II Empire and Trans-Oceanic Services Page 9 Appendix B Details of Services Operated During the Period, set out year by year Page 68 Appendix C Regular Air Services in British Empire Countries other than the United Kingdom, set out year by year Page 140 Note that names of companies and places are copied as they were typed in the UK on a standard typewriter. Therefore no accented letters were available, and they have not been added into this transcript. Report on the Progress of Civil Aviation 1939 - 1945 Foreword by John Wilson When in the 1980s I was trying to unravel the exact story surrounding a PBY aircraft called "Guba" and its wartime career in carrying airmails to and from West Africa, I came across a voluminous report [Ref.1] in the Civil Aviation Authority (C.A.A.) Library which gave me the answers to most, if not all, of my questions, and enabled me to write a short booklet [Ref.2] on the vicissitudes of trying to keep an airmail service running in wartime conditions. The information contained in the report was so comprehensive that I was able to use it to answer questions raised by other researchers, both philatelic and aeronautic, but my response to requests for "a copy" of the full document had to be negative because I was well aware of the perils of copyright law as applied at the time, and also aware of the sheer cost of reproduction (I still have the original invoice for the photocopying charges levied by the C.A.A. -
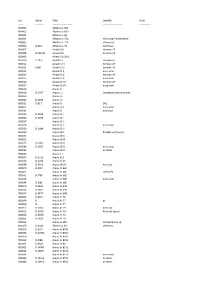
B&W Real.Xlsx
NO REGN TYPE OWNER YEAR ‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐ X00001 Albatros L‐68C X00002 Albatros L‐68D X00003 Albatros L‐69 X00004 Albatros L‐72C Hamburg Fremdenblatt X00005 Albatros L‐72C striped c/s X00006 D‐961 Albatros L‐73 Lufthansa X00007 Aviatik B.II German AF X00008 B.558/15 Aviatik B.II German AF X00009 Aviatik PG.20/2 X00010 C.1952 Aviatik C.I German AF X00011 Aviatik C.III German AF X00012 6306 Aviatik C.IX German AF X00013 Aviatik D.II nose view X00014 Aviatik D.III German AF X00015 Aviatik D.III nose view X00016 Aviatik D.VII German AF X00017 Aviatik D.VII nose view X00018 Arado J.1 X00019 D‐1707 Arado L.1 Ostseebad Warnemunde X00020 Arado L.II X00021 D‐1874 Arado L.II X00022 D‐817 Arado S.I DVL X00023 Arado S.IA nose view X00024 Arado S.I modified X00025 D‐1204 Arado SC.I X00026 D‐1192 Arado SC.I X00027 Arado SC.Ii X00028 Arado SC.II nose view X00029 D‐1984 Arado SC.II X00030 Arado SD.1 floatplane @ (poor) X00031 Arado SD.II X00032 Arado SD.III X00033 D‐1905 Arado SSD.I X00034 D‐1905 Arado SSD.I nose view X00035 Arado SSD.I on floats X00036 Arado V.I X00037 D‐1412 Arado W.2 X00038 D‐2994 Arado Ar.66 X00039 D‐IGAX Arado AR.66 Air to Air X00040 D‐IZOF Arado Ar.66C X00041 Arado Ar.68E Luftwaffe X00042 D‐ITEP Arado Ar.68E X00043 Arado Ar.68E nose view X00044 D‐IKIN Arado Ar.68F X00045 D‐2822 Arado Ar.69A X00046 D‐2827 Arado Ar.69B X00047 D‐EPYT Arado Ar.69B X00048 D‐IRAS Arado Ar.76 X00049 D‐ Arado Ar.77 @ X00050 D‐ Arado Ar.77 X00051 D‐EDCG Arado Ar.79 Air to Air X00052 D‐EHCR