Arxiv:1703.04222V2 [Cs.DL] 13 Apr 2017 This Article Is Available Under the Terms of the Creative Commons Attribution 4.0 License
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

The Misadventures of the New Satan Free
FREE THE MISADVENTURES OF THE NEW SATAN PDF Anton Tammsaare,Christopher Moseley | 256 pages | 01 Oct 2009 | Norvik Press | 9781870041805 | English | Norwich, United Kingdom Jüri Müür – Movies, Bio and Lists on MUBI The Misadventures of the New Satan 0. Tasub kohal olla omaenese elus. Sinu ostukorv:. Satan has a problem: God has come to the conclusion that it is unfair to send souls to hell if they are fundamentally incapable of living a decent life on earth. If this is the case, then hell will be shut down, and The Misadventures of the New Satan human race written off as an unfortunate mistake. Satan is given the chance to prove that human beings are capable of salvation - thus ensuring the survival of hell - if he agrees to live as a human being and demonstrate that it is possible to live a righteous life. St Peter suggests that life as a farmer might offer Satan the best chance of success, because of the catalogue of privations he will be forced to endure. And so Satan ends up back on earth, living as Jurka, a great bear of a man, the put-upon tenant of a run-down Estonian farm. His patience and good nature are sorely tested by the machinations of his scheming, unscrupulous landlord and the social and religious hypocrisy he encounters. The Misadventures of the New Satan is the last novel by Estonia's greatest twentieth-century writer, Anton Tammsaareand it constitutes a fitting summation of the themes that occupied him throughout his writing: the search for truth and social justice, and the struggle against corruption and greed. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Report on Requirements for Usage and Reuse Statistics for GLAM Content
Report on Requirements for Usage and Reuse Statistics for GLAM Content Author: Maarten Zeinstra, Kennisland 1/19 Report on Requirements for Usage and Reuse Statistics for GLAM Content 1. Table of Contents 1. Table of Contents 2 2. GLAMTools project 3 3. Executive Summary 4 4. Introduction 5 5. Problem definition 6 6. Current status 7 7. Research overview 8 7.1. Questionnaire 8 7.2. Qualitative research on the technical possibilities of GLAM stats 12 7.3. Research conclusions 13 8. Requirements for usage and reuse statistics for GLAM content 14 8.1. High-level requirements 14 8.2. High-level technical requirements 14 8.3. Medium-level technical requirements 15 8.4. Non-functional requirements 15 8.5. Non-requirements / out of scope 15 8.6. Data model 15 9. Next steps 19 2/19 2. GLAMTools project The “Report on requirements for usage and reuse statistics for GLAM content” is part of the Europeana GLAMTools project, a joint Wikimedia Chapters and Europeana project. The purpose of the project is to develop a scalable and maintainable system for mass uploading (open) content from galleries, libraries, archives and museums (henceforth GLAMs) to Wikimedia Commons and to create GLAM-specific requirements for usage statistics. The GLAMTools project is initiated and made possible by financial support from Wikimedia France, Wikimedia UK, Wikimedia Netherlands, and Wikimedia Switzerland. Maarten Zeinstra from Kennisland wrote the research behind this report and the report itself. Kennisland is a Dutch think tank active in the cultural sector, working especially with open content, dissemination of cultural heritage and copyright law and is also a partner in the project. -
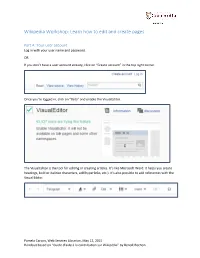
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

Brion Vibber 2011-08-05 Haifa Part I: Editing So Pretty!
Editing 2.0 MediaWiki's upcoming visual editor and the future of templates Brion Vibber 2011-08-05 Haifa Part I: Editing So pretty! Wikipedia articles can include rich formatting, beyond simple links and images to complex templates to generate tables, pronunciation guides, and all sorts of details. So icky! But when you push that “edit” button, you often come face to face with a giant blob of markup that’s very hard to read. Here we can’t even see the first paragraph of the article until we scroll past several pages of infobox setup. Even fairly straightforward paragraphs start to blur together when you break out the source. The markup is often non-obvious; features that are clearly visible in the rendered view like links and images don’t stand out in the source view, and long inline citations and such can make it harder to find the actual body text you wanted to edit. RTL WTF? As many of you here today will be well aware, the way our markup displays in a raw text editor can also be really problematic for right-to-left scripts like Hebrew and Arabic. It’s very easy to get lost about whether you’ve opened or closed some tag, or whether your list item is starting at the beginning of a line. Without control over the individual pieces, we can’t give any hints to the text editor. RTL A-OK The same text rendered as structured HTML doesn’t have these problems; bullets stay on the right side of their text, and reference citations are distinct entities. -

QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT
QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT C Features that we build to improve our technology A Foundation level goals offering B Features we build for others D Modernization, renewal and tech debt goals The goals in each team pack are annotated using this scheme illustrate the broad trends in our priorities Agenda ● CTO Team ● Research and Data ● Design Research ● Performance ● Release Engineering ● Security ● Technical Operations Photos (left to right) Technology (Services) CTO July 2017 quarterly check-in All content is © Wikimedia Foundation & available under CC BY-SA 4.0, unless noted otherwise. CTO Team ● Victoria Coleman - Chief Technology Officer ● Joel Aufrecht - Program Manager (Technology) ● Lani Goto - Project Assistant ● Megan Neisler - Senior Project Coordinator ● Sarah Rodlund - Senior Project Coordinator ● Kevin Smith - Program Manager (Engineering) Photos (left to right) CHECK IN TEAM/DEPT PROGRAM WIKIMEDIA FOUNDATION July 2017 CTO 4.5 [LINK] ANNUAL PLAN GOAL: expand and strengthen our technical communities What is your objective / Who are you working with? What impact / deliverables are you expecting? workflow? Program 4: Technical LAST QUARTER community building (none) Outcome 5: Organize Wikimedia Developer Summit NEXT QUARTER Objective 1: Developer Technical Collaboration Decide on event location, dates, theme, deadlines, etc. Summit web page and publicize the information published four months before the event (B) STATUS: OBJECTIVE IN PROGRESS Technology (Services) Research and Data July, 2017 quarterly -

Estonian Academy of Sciences Yearbook 2018 XXIV
Facta non solum verba ESTONIAN ACADEMY OF SCIENCES YEARBOOK FACTS AND FIGURES ANNALES ACADEMIAE SCIENTIARUM ESTONICAE XXIV (51) 2018 TALLINN 2019 This book was compiled by: Jaak Järv (editor-in-chief) Editorial team: Siiri Jakobson, Ebe Pilt, Marika Pärn, Tiina Rahkama, Ülle Raud, Ülle Sirk Translator: Kaija Viitpoom Layout: Erje Hakman Photos: Annika Haas p. 30, 31, 48, Reti Kokk p. 12, 41, 42, 45, 46, 47, 49, 52, 53, Janis Salins p. 33. The rest of the photos are from the archive of the Academy. Thanks to all authos for their contributions: Jaak Aaviksoo, Agnes Aljas, Madis Arukask, Villem Aruoja, Toomas Asser, Jüri Engelbrecht, Arvi Hamburg, Sirje Helme, Marin Jänes, Jelena Kallas, Marko Kass, Meelis Kitsing, Mati Koppel, Kerri Kotta, Urmas Kõljalg, Jakob Kübarsepp, Maris Laan, Marju Luts-Sootak, Märt Läänemets, Olga Mazina, Killu Mei, Andres Metspalu, Leo Mõtus, Peeter Müürsepp, Ülo Niine, Jüri Plado, Katre Pärn, Anu Reinart, Kaido Reivelt, Andrus Ristkok, Ave Soeorg, Tarmo Soomere, Külliki Steinberg, Evelin Tamm, Urmas Tartes, Jaana Tõnisson, Marja Unt, Tiit Vaasma, Rein Vaikmäe, Urmas Varblane, Eero Vasar Printed in Priting House Paar ISSN 1406-1503 (printed version) © EESTI TEADUSTE AKADEEMIA ISSN 2674-2446 (web version) CONTENTS FOREWORD ...........................................................................................................................................5 CHRONICLE 2018 ..................................................................................................................................7 MEMBERSHIP -

教學大綱 098 1 2769 Public Domain 公版著作
朝陽科技大學 098學年度第1學期教學大綱 Public Domain 公版著作 當 2769 2769 期 Course Number 課 號 授 毛慶禎 Mao,Ching Chen 課 Instructor 教 師 中 公版著作 Public Domain 文 Course Name 課 名 開 資訊管理系(四日)四C 課 Department 單 位 修 選修 Elective 習 Required/Elective 別 學 2 2 分 Credits 數 1. 公版著作物就是著作財產權消滅之著作,依照著作權法 1. Public domain materials are those whose copyrights 的規定,以自由利用為原則。著作財產權的存續期,以著 have expired and can be freely used. Copyright of 課 作人之生存期間及其死亡後五十年為限,攝影、視聽、錄 creative works extend up to 50 years after the death of 程 音及表演之著作財產權的存續期,以公開發表後五十年為 Objectives the author. Copyright of photos, videos, recordings, and 目 限。 performances extend up to 50 years after the first 標 2. 檢視現有的公版著作,蒐集整理。 publication. 2. Examine and organize existing public domain materials. 參考資源 http://sites.google.com/site/maolins/teaching/pd 1. The Public Domain: Enclosing the Commons of the Mind [公領域: 納入共用的思維] / James Boyle. -- Yale University Press (December 9, 2008). -- 336 p. -- ISBN-10: 0300137400, ISBN-13: 978-0300137408 [PDF] [HTML], http://www.thepublicdomain.org/ 2. 自由資訊概論, http://www.lins.fju.edu.tw/mao/works/freeinformation4lac.htm 3. 自由資訊概論, http://www.lins.fju.edu.tw/mao/works/mtp4www.htm, 2004/7 for PCOffice 4. 公版著作物 / 毛慶禎, 2003/09/1, http://www.lins.fju.edu.tw/mao/works/fspd.htm 5. 古騰堡計畫, 2003/02/19, http://www.lins.fju.edu.tw/mao/foi/pg.htm 6. 海盜灣(Pirate Bay), http://thepiratebay.org/ 7. TPB Tracker Geo Statistic, http://geo.keff.org/ 8. 開放式課程計畫, http://www.myoops.org/twocw/ 9. 合法下載何必盜版 10. 維基百科, http://tinyurl.com/wikipediataiwan 學英文救饑荒, http://www.freerice.com/ 古騰堡計畫, http://blue.lins.fju.edu.tw/~mao/foi/pg.htm 11. -

Generating Openmath Content Dictionaries from Wikidata
Generating OpenMath Content Dictionaries from Wikidata Moritz Schubotz Dept. of Computer and Information Science, University of Konstanz, Box 76, 78464 Konstanz, Germany, [email protected] Abstract OpenMath content dictionaries are collections of mathematical sym- bols. Traditionally, content dictionaries are handcrafted by experts. The OpenMath specification requires a name and a textual description in English for each symbol in a dictionary. In our recently published MathML benchmark (MathMLBen), we represent mathematical for- mulae in Content MathML referring to Wikidata as the knowledge base for the grounding of the semantics. Based on this benchmark, we present an OpenMath content dictionary, which we generated auto- matically from Wikidata. Our Wikidata content dictionary consists of 330 entries. We used the 280 entries of the benchmark MathMLBen, as well as 50 entries that correspond to already existing items in the official OpenMath content dictionary entries. To create these items, we proposed the Wikidata property P5610. With this property, everyone can link OpenMath symbols and Wikidata items. By linking Wikidata and OpenMath data, the multilingual community maintained textual descriptions, references to Wikipedia articles, external links to other knowledge bases (such as the Wolfram Functions Site) are connected to the expert crafted OpenMath content dictionaries. Ultimately, these connections form a new content dictionary base. This provides multi- lingual background information for symbols in MathML formulae. 1 Introduction and Prior Works Traditionally, mathematical formulae occur in a textual or situational context. Human readers infer the meaning of formulae from their layout and the context. An essential task in mathematical information retrieval (MathIR) is to mimic parts of this process to automate MathIR tasks. -

February 5, 2011
February Arguing the law with Nicolaus Everardi 5, 2011 Posted by rechtsgeschiedenis under Digital editions | Tags: Bibliography,Digital libraries, Great Council of Malines, Legal history, Medieval law,Netherlands, Rare books In the early sixteenth century some changes become already visible in the way lawyers approached the law. Not only was there a growing interest in the history of Roman and canon law, but lawyers began to free themselves from the framework offered by these legal systems. One of the signs of this are the titles of legal treatises, the growth itself of this genre, and a more systematic approach of law. Nicolaus Everardi’s book on legal argumentation, his Topicorum seu de locis legalibus liber (Louvain 1516) is an example of this development. The book of this Dutch lawyer who presided the Court of Holland and the Great Council of Malines became almost a bestseller because of the reprints published everywhere in Europe. Printers in Bologna, Basel, Paris, Lyon, Strasbourg, Venice, Frankfurt am Main and Cologne printed this book until the mid-seventeenth century. I have found eight reprints of the first edition and eighteen of the second edition. On the blog of the Arbeitsgemeinschaft Frühe Neuzeit Klaus Graf recently criticized sharply the new database Early Modern Thought Online (EMTO) of the Fernuniversität Hagen that enables you to search for editions of texts in the broad field of early modern philosophy and thought. The EMTO database notes in the search results the availability of online versions. In this respect Graf saw major shortcomings, because EMTO does not harvest its results from some of the major sources for early modern texts online.