An Abstract of the Thesis Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

João Pedro Brito Cício De Carvalho
Universidade do Minho Escola de Economia e Gestão João Pedro Brito Cício de Carvalho eams Business Models in Professional Electronic ts T Sports Teams Business Models in Professional Electronic Spor tins Coelho abio José Mar F 5 1 UMinho|20 April, 2015 Universidade do Minho Escola de Economia e Gestão João Pedro Brito Cício de Carvalho Business Models in Professional Electronic Sports Teams Dissertation in Marketing and Strategy Supervisor: Professor Doutor Vasco Eiriz April, 2015 DECLARATION Name: João Pedro Brito Cício de Carvalho Electronic mail: [email protected] Identity Card Number: 13011205 Dissertation Title: Business Models in Professional Electronic Sports Teams Supervisor: Professor Doutor Vasco Eiriz Year of completion: 2015 Title of Master Degree: Marketing and Strategy IT IS AUTHORIZED THE FULL REPRODUCTION OF THIS THESIS/WORK FOR RESEARCH PURPOSES ONLY BY WRITTEN DECLARATION OF THE INTERESTED, WHO COMMITS TO SUCH; University of Minho, ___/___/______ Signature: ________________________________________________ Thank You Notes First of all, I’d like to thank my family and my friends for their support through this endeavor. Secondly, a big thank you to my co-workers and collaborators at Inygon and all its partners, for giving in the extra help while I was busy doing this research. Thirdly, my deepest appreciation towards my interviewees, who were extremely kind, helpful and patient. Fourthly, a special thank you to the people at Red Bull and Zowie Gear, who opened up their networking for my research. And finally, my complete gratitude to my research supervisor, Professor Dr. Vasco Eiriz, for his guidance, patience and faith in this research, all the way from the theme proposed to all difficulties encountered and surpassed. -

“Beautiful Forcefields!”
“Beautiful Forcefields!” Promotional Metadiscursive Language in eSports Commentaries ” Underbara kraftfält!” Promotionsbef rämjande metadiskursivt språ k i eSportskommentar er Johannes Byrö Faculty of Arts and Social Sciences English English III: D egree Project 15hp Supervisor: Andrea Schalley Examiner : Solveig Granath October 2017 Title: “Beautiful Forcefields!”: Promotiona l Metadiscursive language in eSports Commentaries Titel på svenska: ” Underbara kraftfält!”: Promoti onsbef rämjande metadiskursi v t språk i eSportskommenta rer Author: Johannes Byrö Pages: 45 Abstract For an eSports commentator, the ability to promote the rivalry between the competitors is just as important as fast and accurate commentary. Th us, it is of interest how an experienced commentator achieves this promotional language per some theoretical framework. Using the relatively new and unexplored linguistic field of pro motional metadiscourse the quality o f comment ary can be evaluated quantifiably . T hus, t his paper investigates the promotional l anguage used by accomplished eSports commentators, in contrast to inexpe rienced novices, in the game StarCraft II. This is achieved with a lexical analysis of two StarCraft I I commentaries using categories of promotional langu age previously identified in press releases. Experienced commentators were found to have a much more extensive and varied vocabulary than their inexperienced counterparts, adopting stronger evaluative adj ectives and adverbs, as well as metaphorical language, in their commentaries. After comparing the commentaries with each other, the comments of two experienced commentators were compared. In this analysis, the same results were found in regards to commenta tor experience, as the less experienced commentator in this team featured less varied and weaker evaluative language than his more experienced co - commentator, yet more varied and evaluative than the novices . -

Metisentry - Esports
The University of Akron IdeaExchange@UAkron Williams Honors College, Honors Research The Dr. Gary B. and Pamela S. Williams Honors Projects College Spring 2020 MetiSentry - Esports Justin So The University of Akron, [email protected] Nathan Ray University of Akron, [email protected] Bethany R. Truax The University of Akron, [email protected] Ryan Hevesi [email protected] Daniel Shomper [email protected] Follow this and additional works at: https://ideaexchange.uakron.edu/honors_research_projects Part of the Entrepreneurial and Small Business Operations Commons Please take a moment to share how this work helps you through this survey. Your feedback will be important as we plan further development of our repository. Recommended Citation So, Justin; Ray, Nathan; Truax, Bethany R.; Hevesi, Ryan; and Shomper, Daniel, "MetiSentry - Esports" (2020). Williams Honors College, Honors Research Projects. 1170. https://ideaexchange.uakron.edu/honors_research_projects/1170 This Dissertation/Thesis is brought to you for free and open access by The Dr. Gary B. and Pamela S. Williams Honors College at IdeaExchange@UAkron, the institutional repository of The University of Akron in Akron, Ohio, USA. It has been accepted for inclusion in Williams Honors College, Honors Research Projects by an authorized administrator of IdeaExchange@UAkron. For more information, please contact [email protected], [email protected]. eSports Market Analysis 1 eSports: Market Analysis Ryan Hevesi Bethany Truax Nathan Ray Daniel Shomper Justin So The University of Akron eSports Market Analysis 2 Abstract In the following secondary research, the goal is to achieve an understanding of the eSports world on the collegiate level. -

Evidence from Sports Data
Graduate Theses, Dissertations, and Problem Reports 2019 Incentives and Economic Decisions: Evidence from Sports Data Iuliia Chikish [email protected] Follow this and additional works at: https://researchrepository.wvu.edu/etd Part of the Behavioral Economics Commons, and the Other Economics Commons Recommended Citation Chikish, Iuliia, "Incentives and Economic Decisions: Evidence from Sports Data" (2019). Graduate Theses, Dissertations, and Problem Reports. 4078. https://researchrepository.wvu.edu/etd/4078 This Dissertation is protected by copyright and/or related rights. It has been brought to you by the The Research Repository @ WVU with permission from the rights-holder(s). You are free to use this Dissertation in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you must obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/ or on the work itself. This Dissertation has been accepted for inclusion in WVU Graduate Theses, Dissertations, and Problem Reports collection by an authorized administrator of The Research Repository @ WVU. For more information, please contact [email protected]. Incentives and Economic Decisions: Evidence from Sports Data Iuliia Chikish Dissertation submitted to the John Chambers College of Business and Economics at West Virginia University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Economics Brad R. Humphreys, Ph.D., Chair Barbara Apostolou, Ph.D. Adam Nowak, Ph.D. Jane Ruseski, Ph.D. Department of Economics Morgantown, West Virginia 2019 Keywords: reference point, effort, tournament theory, professional sports, local amenities Copyright 2019 Iuliia Chikish ABSTRACT Incentives and Economic Decisions: Evidence from Sports Data Iuliia Chikish This dissertation presents three essays which demonstrate how sports data can be applied to answer economic questions. -

E-Sports: More Than Just a Fad Michael Mctee
Oklahoma Journal of Law and Technology Volume 10 | Number 1 January 2014 E-Sports: More Than Just a Fad Michael McTee Follow this and additional works at: http://digitalcommons.law.ou.edu/okjolt Part of the Entertainment, Arts, and Sports Law Commons Recommended Citation McTee, Michael (2014) "E-Sports: More Than Just a Fad," Oklahoma Journal of Law and Technology: Vol. 10 : No. 1 , Article 3. Available at: http://digitalcommons.law.ou.edu/okjolt/vol10/iss1/3 This Article is brought to you for free and open access by University of Oklahoma College of Law Digital Commons. It has been accepted for inclusion in Oklahoma Journal of Law and Technology by an authorized editor of University of Oklahoma College of Law Digital Commons. For more information, please contact [email protected]. 10 Okla. J.L. & Tech. 70 (2014) www.okjolt.org E-SPORTS: MORE THAN JUST A FAD © 2014 Michael McTee On October 4, 2013 at the Staples Center, home of the Los Angeles Kings, Clippers, and Lakers, Riot Games hosted the Season 3 World Championship Grand Finals for League of Legends.1 There, in front of thousands of fans and thirty-two million watching online, Korea’s SK Telecom T1 swept China’s Royal Club three games to none, securing for themselves the $1 million prize and title of World Champions. 2 The event was the largest gaming contest held in North America to date, easily surpassing the prior year’s event held at the Galen Center.3 The phenomenon known as e-sports is rapidly growing in popularity and gaining support as a legitimate sport. -

The Principles of Esports Engagement: a Universal Code of Conduct
Journal of Intellectual Property Law Volume 27 Issue 2 Article 3 The Principles of Esports Engagement: A Universal Code of Conduct Yen-Shyang Tseng Horvitz & Levy LLP Follow this and additional works at: https://digitalcommons.law.uga.edu/jipl Part of the Intellectual Property Law Commons Recommended Citation Yen-Shyang Tseng, The Principles of Esports Engagement: A Universal Code of Conduct, 27 J. INTELL. PROP. L. 209 (). Available at: https://digitalcommons.law.uga.edu/jipl/vol27/iss2/3 This Article is brought to you for free and open access by Digital Commons @ Georgia Law. It has been accepted for inclusion in Journal of Intellectual Property Law by an authorized editor of Digital Commons @ Georgia Law. Please share how you have benefited from this access For more information, please contact [email protected]. The Principles of Esports Engagement: A Universal Code of Conduct Cover Page Footnote Appellate attorney at Horvitz & Levy LLP in Burbank, California. Given how quickly esports evolves, new statistics and information might be available by the time of publication. Thanks to Dan Nabel, to the editors of the Journal of Intellectual Property Law, and to all friends of Purple Poring. This article is available in Journal of Intellectual Property Law: https://digitalcommons.law.uga.edu/jipl/vol27/iss2/3 Tseng: The Principles of Esports Engagement: A Universal Code of Conduct THE PRINCIPLES OF ESPORTS ENGAGEMENT: A UNIVERSAL CODE OF CONDUCT? Yen-Shyang Tseng * *Appellate attorney at Horvitz & Levy LLP in Burbank, California. Given how quickly esports evolves, new statistics and information might be available by the time of publication. -

E-Sports Biz in Korea
ee--SportsSports BizBiz inin KoreaKorea May. 2008 / Korea e -Sports Association MAY. 2008 Unbelievable Truths 18,000,000 Number of Koreans who love e-Sports 120,000 Number of e-Sports fans on hot summer Kwang-An- Li beach 432 Number of Pro-gamers leading Korea e-Sports 520,906 Number of pro-gamer SLayerS_'BoxeR‘ fan club members 5,000,000,000 Number of people around the world who can enjoy Korea e-Sports’ future Korea e-Sports & Role of KeSPA ■ Korea e-Sports started 10 years ago ■ KeSPA established in 2000 with the approval of the Ministry of Culture, Sports and Tourism Korea ■ KeSPA contributed to the settlement of Korean e-Sports as a sound leisure culture for youth life and coordinating among various e-Sports actors ■ KeSPA carried out as a representative e-Sports organization in Korea e-Sports Actors Role of KeSPA • Supporting pro & amateur gamers and pro-game e-Sports Related User Institute teams • Set the e-Sports infra like rule, stadium, etc. Game Gamer Team • Hosting the world largest e-Sports ‘Pro-League’ Academy KeSPA Media • Hosting, approving, supporting Amateur tournaments League Gov’t • Coordinating among various e-Sports actors Sponsor • Supporting e-Sports research studies & publishing Game Developer e-Sports User • Performing International Roles as a Korean Rep. KeSPA Structure KeSPA President Boarders Office League Planning Dept. Management Dept. • Official registering and recognize about pro-gamer, • 12 Executives (11 Corporate, 1 Government agency) • Role to discuss and decide about pro-game Team, games, league etc. business program operation, rule revision, • Official e-Sports league organizing and operation approval of new executive application, etc. -

Primary & Secondary Sources
Primary & Secondary Sources Brands & Products Agencies & Clients Media & Content Influencers & Licensees Organizations & Associations Government & Education Research & Data Multicultural Media Forecast 2019: Primary & Secondary Sources COPYRIGHT U.S. Multicultural Media Forecast 2019 Exclusive market research & strategic intelligence from PQ Media – Intelligent data for smarter business decisions In partnership with the Alliance for Inclusive and Multicultural Marketing at the Association of National Advertisers Co-authored at PQM by: Patrick Quinn – President & CEO Leo Kivijarv, PhD – EVP & Research Director Editorial Support at AIMM by: Bill Duggan – Group Executive Vice President, ANA Claudine Waite – Director, Content Marketing, Committees & Conferences, ANA Carlos Santiago – President & Chief Strategist, Santiago Solutions Group Except by express prior written permission from PQ Media LLC or the Association of National Advertisers, no part of this work may be copied or publicly distributed, displayed or disseminated by any means of publication or communication now known or developed hereafter, including in or by any: (i) directory or compilation or other printed publication; (ii) information storage or retrieval system; (iii) electronic device, including any analog or digital visual or audiovisual device or product. PQ Media and the Alliance for Inclusive and Multicultural Marketing at the Association of National Advertisers will protect and defend their copyright and all their other rights in this publication, including under the laws of copyright, misappropriation, trade secrets and unfair competition. All information and data contained in this report is obtained by PQ Media from sources that PQ Media believes to be accurate and reliable. However, errors and omissions in this report may result from human error and malfunctions in electronic conversion and transmission of textual and numeric data. -
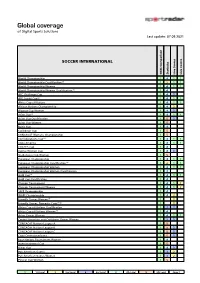
Sportradar Coverage List
Global coverage of Digital Sports Solutions Last update: 07.09.2021 SOCCER INTERNATIONAL Odds Comparison Statistics Live Scores Live Centre World Championship 1 4 1 1 World Championship Qualification (1) 1 2 1 1 World Championship Women 1 4 1 1 World Championship Women Qualification (1) 1 4 AFC Challenge Cup 1 4 3 AFF Suzuki Cup (6) 1 4 1 1 Africa Cup of Nations 1 4 1 1 African Nations Championship 1 4 2 Algarve Cup Women 1 4 3 Asian Cup (6) 1 4 1 1 Asian Cup Qualification 1 5 3 Asian Cup Women 1 5 Baltic Cup 1 4 Caribbean Cup 1 5 CONCACAF Womens Championship 1 5 Confederations Cup (1) 1 4 1 1 Copa America 1 4 1 1 COSAFA Cup 1 4 Cyprus Women Cup 1 4 3 SheBelieves Cup Women 1 5 European Championship 1 4 1 1 European Championship Qualification (1) 1 2 1 1 European Championship Women 1 4 1 1 European Championship Women Qualification 1 4 Gold Cup (6) 1 4 1 1 Gold Cup Qualification 1 4 Olympic Tournament 1 4 1 2 Olympic Tournament Women 1 4 1 2 SAFF Championship 1 4 WAFF Championship 1 4 2 Friendly Games Women (1) 1 2 Friendly Games, Domestic Cups (1) (2) 1 2 Africa Cup of Nations Qualification 1 3 3 Africa Cup of Nations Women (1) 1 4 Asian Games Women 1 4 1 1 Central American and Caribbean Games Women 1 3 3 CONCACAF Nations League A 1 5 CONCACAF Nations League B 1 5 3 CONCACAF Nations League C 1 5 3 Copa Centroamericana 1 5 3 Four Nations Tournament Women 1 4 Intercontinental Cup 1 5 Kings Cup 1 4 3 Pan American Games 1 3 2 Pan American Games Women 1 3 2 Pinatar Cup Women 1 5 1 1st Level 2 2nd Level 3 3rd Level 4 4th Level 5 5th Level Page: -
Tenkanen Juho.Pdf (1.467Mt)
Opinnäytetyö (AMK) Tradenomi, Liiketalous 2019 Juho Tenkanen SPONSORINÄKYVYYDEN KEHITTÄMINEN E- URHEILUORGANISAATIOSSA OPINNÄYTETYÖ (AMK) | TIIVISTELMÄ TURUN AMMATTIKORKEAKOULU Liiketalous, tradenomi 2019 | 52 sivua Juho Tenkanen SPONSORINÄKYVYYDEN KEHITTÄMINEN E- URHEILUORGANISAATIOSSA Opinnäytetyö on kirjallisuustutkimus sponsorinäkyvyyden kehittämisestä e- urheiluorganisaatioissa. Tutkimuksessa etsitään e-urheiluorganisaatioille mahdollisia markkinointiratkaisuja, joita tarjota olemassa oleville tai potentiaalisille sponsoreille. Lisäksi tavoitteena on löytää ratkaisuja osapuolien välisen yhteistyön kehittämiseksi. Opinnäytetyön tulosten avulla voidaan löytää sellaisia sponsorointiratkaisuja, joilla tuottaa e-urheiluorganisaation ja yrityksen kohderyhmille elämyksellistä sisältöä. Tuloksia voidaan soveltaa joukkueen tai yksittäisen pelaajan näkökulmasta. Taustatutkimusosassa perehdytään e-urheiluun, sekä sponsorointiin. E-urheilun osalta tarkastellaan e-urheilun alatyyppejä, ja nykymuotoista sponsorointia e-urheilussa. Tutkimusosassa eri lähteitä käyttäen kootaan kattava määrä tietoa e-urheilun tämän hetkisestä näkyvyydestä. Organisaatioiden suosion mittareina on käytetty runsaasti katsojalukuja sekä eri kanavien seuraajalukuja, joissa e-urheiluorganisaatioilla on näkyvyyttä. Tutkimuksessa saatujen tietojen pohjalta tarjotaan erilaisia ratkaisuja sponsorinäkyvyyden kehittämiseksi. Tutkimuksen johtopäätös on, että sponsorinäkyvyydessä on vielä runsaasti kehitettävää e-urheilussa. Tämänhetkisessä sponsorinäkyvyydessä on paljon eroja, -

Idra RAGE Highlights 2011 Data Publikacji : 30.07.2012 Ocena: 5/5 (3)
IdrA RAGE Highlights 2011 Data publikacji : 30.07.2012 Ocena: 5/5 (3) Z serii znalezione w sieci - wprawdzie video ma już sporo czasu, ale kto nie lubi popatrzeć na grę Idry i jego epickie rage quit. Pamiętne gry z MLG z MMA, w którym wyszedł z praktycznie wygranej gry, przegrana gra z Trimasterem czy halucynowane Voidraye Huka. Tagi: IdrA, highlights Uprasza się osoby kopiujące w całości newsy z naszej witryny na swoje strony lub fora o wstawianie widocznych klikalnych linków, bezpośrednio do pobranego tekstu. W przypadku braku widocznego linku, skopiowanie tekstu uważa się za kradzież własności intelektualnej. Dziękujemy: Administratorzy serwisu. Autor: Fanek Data publikacji : 30.07.2012 Liczba wyświetleń tekstu: 2296 Komentarz (6) dodaj komentarz Mnie i pewnie nie tylko mnie do dziś ciekawi dlaczego Idra wyszedł z tamtej gry. Ogólnie filmik śmiechowy;p~rirs0n 2012/07/31 13:14 Ten gość to frustrat, masakra po prostu. Śmiesznie by było jak by ktoś mu plaskacza kiedyś sprzedał na jakimś turnieju :-)~AlfaExecutor 2012/07/31 14:19 ~AlfaExecutor W pełni się zgadzam. Zachowuje się jak gówniarz, żeby nie rzec jak ciota...~Vendeur 2012/07/31 18:37 A ja wam powiem że w tej grze z MMA idra nie wiedział że mma zniszczył sobie expe miss clickiem, a sam idra stracił dużo dron na swojej ekspansji i myslał że follow up mma go zabije ;)~archimond 2012/07/31 20:23 to była dziwna gra, ale na stałe zapisała sie w historii :)~Fanek Battlenet Network 2012/07/31 22:37 WTF? To ja jestem totalnym noobem w SC2 a wiem, że: 1. -

Amusement Arcades Is Where the First Generation of Video Games Was Born
ESPORTS IN EDUCATION Lesson 1 LESSON 1 Presentation and Introductions The History of Esports Spacewar! Tournament The Evolution of Gaming WHAT ARE ESPORTS? COMPETITION ESPORTS HISTORY I) The Beginning: 1970-1990 II) The Consolidation: 1990-2000 III) The Springboard: 2000-2010 IV) Consacration: 2010-Today HISTORY Amusement arcades is where the first generation of video games was born. Players had to go to public game rooms where video games were inside heavy and awkwardly large playing stations. These playing stations were coin operated, and players paid to purchased single matches. Between the end of the 1980s and the early 1990s, the production on a large scale of the first game consoles, made gaming platforms much more economically accessible. In 1989, Nintendo GameBoy became the first real portable console, and four batteries guaranteed hours of entertainment. In 1998, the colour version, GameBoy Color, was a worldwide success less than a month after its launch on the Japanese market. In those years, video games became quickly popular and people bought the physical copy of the game and all its content directly from the manufacturers and developers of the game. In the new millennium, the Internet became widely available from home at lower costs and with good connectivity, revolutionising the world of video gaming, which was the first to experiment this new technology for the development of multiplayer games. HISTORY Video games were transformed: players were no longer alone, they played online with more than one other player at the time, all connected to the same match of the same video game downloaded online.