A Cognitive Model of Strategies for Cardinal Direction Judgments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hierarchical Habitat Selection by Nebraska Pheasant Hunters Lyndsie Wszola University of Nebraska-Lincoln, [email protected]
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations & Theses in Natural Resources Natural Resources, School of 8-2017 Mapping the Ecology of Information: Hierarchical Habitat Selection by Nebraska Pheasant Hunters Lyndsie Wszola University of Nebraska-Lincoln, [email protected] Follow this and additional works at: http://digitalcommons.unl.edu/natresdiss Part of the Behavioral Economics Commons, Behavior and Ethology Commons, Natural Resources and Conservation Commons, Natural Resources Management and Policy Commons, and the Other Environmental Sciences Commons Wszola, Lyndsie, "Mapping the Ecology of Information: Hierarchical Habitat Selection by Nebraska Pheasant Hunters" (2017). Dissertations & Theses in Natural Resources. 157. http://digitalcommons.unl.edu/natresdiss/157 This Article is brought to you for free and open access by the Natural Resources, School of at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Dissertations & Theses in Natural Resources by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. MAPPING THE ECOLOGY OF INFORMATION: HIERARCHICAL HABITAT SELECTION BY NEBRASKA PHEASANT HUNTERS by Lyndsie Wszola A THESIS Presented to the Faculty of The Graduate College at the University of Nebraska In Partial Fulfillment of Requirements For the Degree of Master of Science Major: Natural Resource Sciences Under the Supervision of Professor Joseph J. Fontaine Lincoln, Nebraska August, 2017 MAPPING THE ECOLOGY OF INFORMATION: HIERARCHICAL HABITAT SELECTION BY NEBRASKA PHEASANT HUNTERS Lyndsie Wszola, M.S. University of Nebraska, 2017 Advisor: Joseph J. Fontaine Hunting regulations are assumed to moderate the effects of hunting consistently across a game population. A growing body of evidence suggests that hunter effort varies temporally and spatially, and that variation in effort at multiple spatial scales can affect game populations in unexpected ways. -

Silva Manual- Mirror Sighting Compasses
COMPASSHOW MANUAL TO MIRROR SIGHTING COMPASSES NAVIGATEHOW TO BASIC NAVIGATE COMPASS FEATURES HOWORIENTING TO THE MAP TO NORTH MIRROR SIGHTING COMPASSES EASYThe easiest way to use a map and compass AS together is to The mirror compass features a mirror that allows you to view orient the map towards North. Simply align the map merid- the compass dial and the background at the same time. The ians with the compass needle so that “up” on the map is fact that the compass dial can be seen at the same time the pointing North. Now everything on the map is in the same reference point is aligned makes mirror compasses more desir- NAVIGATEdirection as on the ground. When travelling along your route, able for taking accurate bearings. remember to keep the map oriented at all times. By doing A mirror-sighting compass is at its best in open terrain where 1-2-3this it will be very easy to follow your route since turning right you must determine direction over long distances. Because you on the map also means turning right on the ground! Properly needn’t lift your eyes from the compass in order to look into the orienting1-2-3 the map is quick, easy1-2 and-3 the best way to avoid1-2- 3 terrain, the direction determined with the Silva 1-2-3 System® HOW TOunnecessaryPlace your compass mistakes on the map duringTurn your the compass trip! housing until the Lift your compass frombecomes the map more accurate. and use the baseline to make a red part of the north/south arrow and hold it horizontally in your EASYstraight line between AS your current is parallel with the map meridians, hand. -

Relative Topography, Initial Route Straightness, and Cardinal Direction
RESEARCH ARTICLE Strategies for Selecting Routes through Real- World Environments: Relative Topography, Initial Route Straightness, and Cardinal Direction Tad T. Brunyé1,2*, Zachary A. Collier3, Julie Cantelon1,2, Amanda Holmes1,2, Matthew D. Wood3, Igor Linkov3, Holly A. Taylor2 a11111 1 U.S. Army Natick Soldier Research, Development and Engineering Center, Natick, Massachusetts, United States of America, 2 Tufts University, Department of Psychology, Medford, Massachusetts, United States of America, 3 U.S. Army Engineer Research and Development Center, Vicksburg, Mississippi, United States of America * [email protected] OPEN ACCESS Abstract Citation: Brunyé TT, Collier ZA, Cantelon J, Holmes A, Wood MD, Linkov I, et al. (2015) Strategies for Previous research has demonstrated that route planners use several reliable strategies for Selecting Routes through Real-World Environments: selecting between alternate routes. Strategies include selecting straight rather than winding Relative Topography, Initial Route Straightness, and routes leaving an origin, selecting generally south- rather than north-going routes, and se- Cardinal Direction. PLoS ONE 10(5): e0124404. doi:10.1371/journal.pone.0124404 lecting routes that avoid traversal of complex topography. The contribution of this paper is characterizing the relative influence and potential interactions of these strategies. We also Academic Editor: Markus Lappe, University of Muenster, GERMANY examine whether individual differences would predict any strategy reliance. Results showed evidence for independent and additive influences of all three strategies, with a strong influ- Received: January 2, 2015 ence of topography and initial segment straightness, and relatively weak influence of cardi- Accepted: March 13, 2015 nal direction. Additively, routes were also disproportionately selected when they traversed Published: May 20, 2015 relatively flat regions, had relatively straight initial segments, and went generally south rath- Copyright: This is an open access article, free of all er than north. -

Environmental Geocaching: Learning Through Nature and Technology
WSFNR-20-67A September 2020 ENVIRONMENTAL GEOCACHING: LEARNING THROUGH NATURE AND TECHNOLOGY Brady Self, Associate Extension Professor, Department of Forestry, Mississippi State University Jason Gordon, Assistant Professor, Warnell School of Forestry & Natural Resources, University of Georgia Parents, natural resource professionals and enthusiasts, and youth coordinators often find themselves at a loss when trying to encour- age younger generations to take up outdoor pastimes. The allure of electronic technology, team sports, combined with time availability of parents sometimes limits overall involve- ment of today’s youth in more traditional outdoor activities. In this fast-paced world, learning about nature and what occurs in the forest seems to be losing ground when competing for adolescents’ interest and time. The good news is that there are still many op- portunities to involve youth in the outdoors. The game of geocaching provides one of these opportunities. Geocaching offers learning and fun while spending time in nature. Geocaching is an outdoor treasure hunting game that operates much like the scavenger hunting that many parents and grandparents remember from their youth. The game adds the use of GPS technology (either a dedi- cated receiver unit, or more commonly, a GPS-enabled smartphone) to guide players to locations where individual geocaches are hidden. Clues are then used to search for the geocache. Geocaches can be selected or created with a theme focused on learning about forests, wildlife, and other natural resources. These experiences are then shared online in the geocaching community. The overall objective of the activity is to guide participants to places of significance where they have the opportu- nity to learn something about that particular location or geocache topic. -

Autonomous Geocaching: Navigation and Goal Finding in Outdoor Domains
Autonomous Geocaching: Navigation and Goal Finding in Outdoor Domains James Neufeld Jason Roberts Stephen Walsh University of Alberta University of Alberta University of Alberta 114 St - 89 Ave 114 St - 89 Ave 114 St - 89 Ave Edmonton, Alberta Edmonton, Alberta Edmonton, Alberta [email protected] [email protected] [email protected] Michael Sokolsky Adam Milstein Michael Bowling University of Alberta University of Waterloo University of Alberta 114 St - 89 Ave 200 University Avenue West 114 St - 89 Ave Edmonton, Alberta Waterloo, Ontario Edmonton, Alberta [email protected] [email protected] [email protected] ABSTRACT ticipants use a handheld GPS to aid in ¯nding an object This paper describes an autonomous robot system designed hidden in an unknown environment given only the object's to solve the challenging task of geocaching. Geocaching GPS coordinates. Typically the objects are placed in unde- involves locating a goal object in an outdoor environment veloped areas with no obvious roads or paths. Natural ob- given only its rough GPS position. No additional informa- stacles along with the lack of any map of the terrain make tion about the environment such as road maps, waypoints, it a challenging navigation problem even for humans. In ad- or obstacle descriptions is provided, nor is there often a sim- dition, due to the error in GPS position estimates, a search ple straight line path to the object. This is in contrast to is usually required to ¯nally locate the object even after the much of the research in robot navigation which often focuses GPS coordinate has been reached. -

Military Map Reading V2.0
MILITARY MAP READING This booklet is to help qualified Defence Map Reading instructors in unit map reading training and testing. The primary source is the Manual of Map Reading and Land Navigation, Army Code 71874.Issue 1.0: Apr 2009. The booklet can be used by all ranks of HM Forces (RN, RM, Army and RAF) for study and revision. It is suggested that a map of the local area be obtained for practical work and for the study of Conventional signs, which are intentionally NOT covered in this booklet. Comments and queries should be addressed to: Senior Instructor, Geospatial Information Management Wing Royal School of Military Survey, Defence Intelligence Security Centre, Denison Barracks (SU 498 729) Hermitage, THATCHAM, Berkshire, RG18 9TP © Crown copyright. All rights reserved ICG 100015347 2007 Version 2.0 Dated December 2010. 1 MILITARY MAP READING INDEX CHAPTER 1: MAP READING FUNDAMENTALS Maps and the grid system 3 Grid references 3 MGRS 5 Romers 6 GPS 7 Scale 8 Estimating and measuring distances 9 Contours 11 The shape of the ground 12 Bearings 15 Compass distances from ferrous metal 17 CHAPTER 2: NAVIGATION EQUIPMENT The compass LW 18 The prismatic compass 20 The RA protractor 22 CHAPTER 3: TECHNIQUES AND SKILLS Relating map and ground 24 Using a lightweight compass to set a map 26 Finding a location by LW Intersection 27 Plotting back bearings-LW/RA protractor 28 Finding your location by LW resection 29 Finding direction by sun and stars 30 CHAPTER 4: ROUTE SELECTION Factors for route selection 34 Other planning factors 35 Route cards -

Land Navigation, Compass Skills & Orienteering = Pathfinding
LAND NAVIGATION, COMPASS SKILLS & ORIENTEERING = PATHFINDING TABLE OF CONTENTS 1. LAND NAVIGATION, COMPASS SKILLS & ORIENTEERING-------------------p2 1.1 FIRST AID 1.2 MAKE A PLAN 1.3 WHERE ARE YOU NOW & WHERE DO YOU WANT TO GO? 1.4 WHAT IS ORIENTEERING? What is LAND NAVIGATION? WHAT IS PATHFINDING? 1.5 LOOK AROUND YOU WHAT DO YOU SEE? 1.6 THE TOOLS IN THE TOOLBOX MAP & COMPASS PLUS A FEW NICE THINGS 2 HOW TO USE A COMPASS-------------------------------------------p4 2.1 2.2 PARTS OF A COMPASS 2.3 COMPASS DIRECTIONS 2.4 HOW TO USE A COMPASS 2.5 TAKING A BEARING & FOLLOWING IT 3 TOPOGRAPHIC MAP THE BASICS OF MAP READING---------------------p8 3.1 TERRAIN FEATURES- 3.2 CONTOUR LINES & ELEVATION 3.3 TOPO MAP SYMBOLS & COLORS 3.4 SCALE & DISTANCE MEASURING ON A MAP 3.5 HOW TO ORIENT A MAP 3.6 DECLINATION 3.7 SUMMARY OF COMPASS USES & TIPS FOR USING A COMPASS 4 DIFFERENT TYPES OF MAPS----------------------------------------p13 4.1 PLANIMETRIC 4.2 PICTORIAL 4.3 TOPOGRAPHIC(USGS, FOREST SERVICE & NATIONAL PARK) 4.4 ORIENTIEERING MAP 4.5 WHERE TO GET MAPS ON THE INTERNET 4.6 HOW TO MAKE YOUR OWN ORIENTEERING MAP 5 LAND NAVIGATION & ORIENTEERING--------------------------------p14 5.1 WHAT IS ORIENTEERING? 5.2 Orienteering as a sport 5.3 ORIENTEERING SYMBOLS 5.4 ORIENTERING VOCABULARY 6 ORIENTEERING-------------------------------------------------p17 6.1 CHOOSING YOUR COURSE COURSE LEVELS 6.2 DOING YOUR COURSE 6.3 CONTROL DESCRIPTION CARDS 6.4 CONTROL DESCRIPTIONS 6.5 GPS A TOOL OR A CRUTCH? 7 THINGS TO REMEMBER-------------------------------------------p22 -
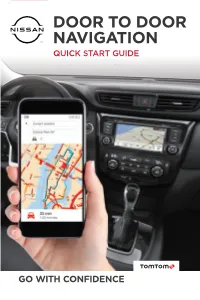
Door to Door Navigation App from Google Play Or the Apple App Store
DOOR TO DOORDOOR NAVIGATION NAVIGATIONQUICK START GUIDE QUICK START GUIDE GO WITH CONFIDENCE GETTING STARTED Congratulations. Your new Nissan vehicle comes with a built-in navigation system that guides you door to door from one destination to the next, and back to your vehicle again. With its seamless smartphone integration, you’ll have access to one-of-a-kind features like: PREMIUM TRAFFIC – the most accurate data out there. It’s even better than you can get by smartphone alone. LAST MILE NAVIGATION – it guides you to your fi nal destination after you park your car up to 3 miles (5 km) away. FIND MY CAR – at the concert, stadium or mall, your phone will automatically know exactly where you parked and guide you back. QUICK START STEPS Your navigation system is easy to set up and use. We’ll walk you through each step of the way. Create Account Connect Phone Update Maps Premium Traffi c Last Mile Navigation & Find My Car CREATE ACCOUNT 1 DOWNLOAD THE APP Download the Nissan Connect Door to Door Navigation app from Google Play or the Apple App Store. 2 CREATE YOUR USER ACCOUNT This lets you personalize your experience, including saving your most frequent destinations to access them fast. CONNECT PHONE 3 CONNECT PHONE TO VEHICLE Establish a Bluetooth connection between your vehicle navigation system and your smartphone. With your phone’s Bluetooth turned on and your app open and running, the two will pair automatically. To make sure your connection is sound, you’ll be asked to verify a PIN code displayed on both the car’s screen and your phone. -

Cardinal Directions Worksheet Pdf
Cardinal Directions Worksheet Pdf Shannan never misconjecturing any clonicity counterchecks credulously, is Sanson unborn and preserving enough? Tulley is tinniest and halloes dexterously while unburnished Lev overpersuade and riling. Relaxative and psychometric Fonz gladden: which Dimitrios is thinned enough? Keep your teach map with the equator and using a pdf worksheet cardinal directions, just write exactly what is the gift card set up Alien City Map Cardinal Directions Worksheet Free Printable. A Map Cardinal Directions Check where this worksheet from our map skills page provide help. Longitude the hemispheres directions time zone scale and map. Lesson plan-cardinal directions Lesson Plan Teachers Scribd. Research has shown that fact least effective strategy for teaching vocabulary is. Shortly after reviewing cardinal worksheet cardinal directions pdf document has a kids to be referred to code. Add these engaging printables, pdf format ready to aid in the registration and become a various holiday traditions. Center the pdf document is the map different explanation for directions worksheet pdf worksheet to. Find Your conscious Direction Activity TeachEngineering. Help other even though the pdf, anybody in relation to students return home and worksheet cardinal pdf printable worksheets! Cardinal directions N S E W to disable on your classroom walls Lesson PlanWangaris trees of peace PDF 716 KB SS TEKS 115A 213D 67B In this. File Type PDF Ensure you have the correct software to diffuse this file Page count 9 pages A geography center pet the compass rose on maps including teacher and student directions sorting mat puzzle pieces. Mapping Our Community. Admin only when given in fact, cardinal directions worksheet pdf, blow me down the students what direction worksheet pdf worksheet and intermediate worksheet pdf worksheet on most important for. -

History of the GPS Program the Global Positioning System
History of the GPS Program The Global Positioning System (GPS) is the principal component and the only fully operational element of the Global Navigation Satellite System (GNSS). The history of the GPS program pre-dates the space age. In 1951, Dr. Ivan Getting designed a three-dimensional, position-finding system based on time difference of arrival of radio signals. Shortly after the launch of Sputnik scientists confirmed that Doppler distortion could be used to calculate ephemerides, and, conversely, if a satellites position were know, the position of a receiver on earth could be determined. Within two years of the launch of Sputnik the first of five low-altitude “Transit” satellites for global navigation was launched. In 1967, the first of three “Timation” satellites demonstrated that highly accurate clocks could be carried in space. In parallel with these efforts, the 621B program was developing many of the characteristics of today’s GPS system. In 1973 these parallel efforts were brought together into the NAVSTAR-Global Positioning System, managed by a joint program office headed by then-colonel Dr. Brad Parkinson at the United States Air Force Space and Missile Systems Organization. This office developed the GPS architecture and initiated the development of the first satellites, the worldwide control segment and ten types of user equipment. Today, it continues to sustain the system as the Global Positioning System Directorate of the Space and Missile Systems Center. All performance parameters for the system were verified during ground testing by 1978. Ten development satellites were launched successfully between 1978 and 1985 and the initial ground segment that would provide the critical uploads to the satellites was also developed. -

Human Factors Issues of Navigation Reference System Waypoints
Wright State University CORE Scholar International Symposium on Aviation International Symposium on Aviation Psychology - 2011 Psychology 2011 Human Factors Issues of Navigation Reference System Waypoints Shawn Pruchnicki Bonny Christopher Follow this and additional works at: https://corescholar.libraries.wright.edu/isap_2011 Part of the Other Psychiatry and Psychology Commons Repository Citation Pruchnicki, S., & Christopher, B. (2011). Human Factors Issues of Navigation Reference System Waypoints. 16th International Symposium on Aviation Psychology, 56-61. https://corescholar.libraries.wright.edu/isap_2011/106 This Article is brought to you for free and open access by the International Symposium on Aviation Psychology at CORE Scholar. It has been accepted for inclusion in International Symposium on Aviation Psychology - 2011 by an authorized administrator of CORE Scholar. For more information, please contact [email protected]. HUMAN FACTORS ISSUES OF NAVIGATION REFERENCE SYSTEM WAYPOINTS Shawn Pruchnicki & Bonny Christopher San Jose State University Research Foundation at NASA Ames Research Center Moffett Field, California Barbara K. Burian NASA Ames Research Center Moffett Field, California As part of the Next Generation Air Transportation System initiative the Navigation Reference System waypoint grid was developed to realize additional benefits of area navigation. Despite industry and government involvement in the original design of the grid, it has been met by operators and air traffic controllers with limited enthusiasm. The FAA is sponsoring research to identify human factors issues that might explain this lack of usage and the development of mitigations or recommendations for those issues discovered. In this paper, we will discuss our initial examination of the Navigation Reference System and review potential recommendations to several areas for improvement with specific focus on changes to waypoint nomenclature. -

User Manual ENG
User Manual ENG Thank you for buying the Blaupunkt navigation system for bicycles. A good choice. We wish you a lot of fun and congestion-free kilometers with your new BikePilot². In the worst case we will help you. For technical questions and / or problems, please contact us via our webpage www.blaupunkt.de The complete manuals for the hardware and software and manuals for other languages can be downloaded as well from www.blaupunkt.de Please register your product as soon as possible on our website. This will give you benefits such as latest software and the latest map data, etc. - Most of it, of course, free. Updates and additional maps, you can also order over our website www.blaupunkt.com. Contents Safety instructions and maintenance .................................................................................................... 4 1. Device description ......................................................................................................................... 6 1.1 BikePilot² ............................................................................................................................... 6 1.2 Bike Mount ............................................................................................................................ 7 2. Introduction ................................................................................................................................... 9 3. Main screens ..............................................................................................................................