Arxiv:2009.08553V4 [Cs.CL] 6 Aug 2021 Taining to the Questions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Songs by Artist
Reil Entertainment Songs by Artist Karaoke by Artist Title Title &, Caitlin Will 12 Gauge Address In The Stars Dunkie Butt 10 Cc 12 Stones Donna We Are One Dreadlock Holiday 19 Somethin' Im Mandy Fly Me Mark Wills I'm Not In Love 1910 Fruitgum Co Rubber Bullets 1, 2, 3 Redlight Things We Do For Love Simon Says Wall Street Shuffle 1910 Fruitgum Co. 10 Years 1,2,3 Redlight Through The Iris Simon Says Wasteland 1975 10, 000 Maniacs Chocolate These Are The Days City 10,000 Maniacs Love Me Because Of The Night Sex... Because The Night Sex.... More Than This Sound These Are The Days The Sound Trouble Me UGH! 10,000 Maniacs Wvocal 1975, The Because The Night Chocolate 100 Proof Aged In Soul Sex Somebody's Been Sleeping The City 10Cc 1Barenaked Ladies Dreadlock Holiday Be My Yoko Ono I'm Not In Love Brian Wilson (2000 Version) We Do For Love Call And Answer 11) Enid OS Get In Line (Duet Version) 112 Get In Line (Solo Version) Come See Me It's All Been Done Cupid Jane Dance With Me Never Is Enough It's Over Now Old Apartment, The Only You One Week Peaches & Cream Shoe Box Peaches And Cream Straw Hat U Already Know What A Good Boy Song List Generator® Printed 11/21/2017 Page 1 of 486 Licensed to Greg Reil Reil Entertainment Songs by Artist Karaoke by Artist Title Title 1Barenaked Ladies 20 Fingers When I Fall Short Dick Man 1Beatles, The 2AM Club Come Together Not Your Boyfriend Day Tripper 2Pac Good Day Sunshine California Love (Original Version) Help! 3 Degrees I Saw Her Standing There When Will I See You Again Love Me Do Woman In Love Nowhere Man 3 Dog Night P.S. -

ORAL HISTORY PROJECT in Celebration of the City of Sugar Land 60Th Anniversary
ORAL HISTORY PROJECT in Celebration of the City of Sugar Land 60th Anniversary GOODSILL: What brought your family to Sugar Land, Billy? GOODSILL: What is William Alfred Streich’s story? STRITCH: My grandmother, Mary Alice Blair, was born in STRITCH: I never knew my grandfather. He died before I was Blessing, Texas, but her family moved to Sugar Land early in her born, in 1957 or so. My older sister is the only one who vaguely life. My grandmother and Buddy Blair were cousins. Mary Alice remembers him. He worked for a philanthropist in Houston whose was one of the founding families of First Presbyterian Church in name was Alonzo Welch. He had a foundation, the Welch Foundation, Sugar Land, founded in 1920 or so. There is definitely a Sugar which started in 1954, two years after Welch’s death in 1952. My Land connection that goes way back for us. grandfather was Mr. Welch’s right hand man. I know this through stories my grandmother told me over the years. At the time she married my dad, William Alfred Striech, they lived in Houston, where I was born in 1962. When I was about My dad who was an only child, who was raised in Houston. He went one, they decided to move out to Sugar Land and build a house. to Texas A & M for college and directly into the service afterward. He [Editor’s note: Striech was the original spelling of the name. Billy served two years in the Air Force. He met and married my mother, Jane goes by Stritch.] Toffelmire, during the course of the war. -

The True Christian's Love to the Unseen Christ
Copyright © Monergism Books The True Christian's Love to the Unseen Christ by Thomas Vincent Table of Contents Biographical Note To the Reader Section I: It is the Property of Truth Christians to Love Jesus Christ Whom They Have Never Seen Section II: The Object of a True Christian's Love is Jesus Christ Section III: The Love which True Christians Bear for the Unseen Christ Section IV: It is the Property of Christians to Love this Unseen Christ Section V. It is the Duty of All True Christians to Love the Unseen Christ Section VI: How Christians Ought to Love this Unseen Christ Section VII: Why Christians Love Christ Whom They Have Never Seen Section VIII: Use of Information Section IX: Use of Examination Section X: Use of Reproof Section XI: Use of Exhortation Section XII: The Consideration of Christ's LoveUnto True Christians Section XIII: The Consideration of Christ's Benefits Section XIV: The Consideration of the Love Christians Have For Christ Section XV: Two Sorts of Directions Section XVI: Directions on How to Attain Much Love to Christ Section XVII Driections on How to Show Your Love For Christ Copyright Biographical note regarding Thomas Vincent: The night before his death, he broke out in the following language, expressive of his comfort, peace and joy, "Farewell world—the pleasures, profits, and honors of the world! Farewell sin! I shall forever be with the Lord! Farewell my dear wife, farewell my dear children, farewell my servants, and farewell my spiritual children." With the latter, he left the following advice, "Be careful in your choice of a pastor; choose one who in his doctrine, life, and manners, may adorn the gospel. -

P. Diddy with Usher I Need a Girl Pablo Cruise Love Will
P Diddy Bad Boys For Life P Diddy feat Ginuwine I Need A Girl (Part 2) P. Diddy with Usher I Need A Girl Pablo Cruise Love Will Find A Way Paladins Going Down To Big Mary's Palmer Rissi No Air Paloma Faith Only Love Can Hurt Like This Pam Tillis After A Kiss Pam Tillis All The Good Ones Are Gone Pam Tillis Betty's Got A Bass Boat Pam Tillis Blue Rose Is Pam Tillis Cleopatra, Queen Of Denial Pam Tillis Don't Tell Me What To Do Pam Tillis Every Time Pam Tillis I Said A Prayer For You Pam Tillis I Was Blown Away Pam Tillis In Between Dances Pam Tillis Land Of The Living, The Pam Tillis Let That Pony Run Pam Tillis Maybe It Was Memphis Pam Tillis Mi Vida Loca Pam Tillis One Of Those Things Pam Tillis Please Pam Tillis River And The Highway, The Pam Tillis Shake The Sugar Tree Panic at the Disco High Hopes Panic at the Disco Say Amen Panic at the Disco Victorious Panic At The Disco Into The Unknown Panic! At The Disco Lying Is The Most Fun A Girl Can Have Panic! At The Disco Ready To Go Pantera Cemetery Gates Pantera Cowboys From Hell Pantera I'm Broken Pantera This Love Pantera Walk Paolo Nutini Jenny Don't Be Hasty Paolo Nutini Last Request Paolo Nutini New Shoes Paolo Nutini These Streets Papa Roach Broken Home Papa Roach Last Resort Papa Roach Scars Papa Roach She Loves Me Not Paper Kites Bloom Paper Lace Night Chicago Died, The Paramore Ain't It Fun Paramore Crush Crush Crush Paramore Misery Business Paramore Still Into You Paramore The Only Exception Paris Hilton Stars Are Bliind Paris Sisters I Love How You Love Me Parody (Doo Wop) That -

Country Christmas ...2 Rhythm
1 Ho li day se asons and va ca tions Fei er tag und Be triebs fe rien BEAR FAMILY will be on Christmas ho li days from Vom 23. De zem ber bis zum 10. Ja nuar macht De cem ber 23rd to Ja nuary 10th. During that peri od BEAR FAMILY Weihnach tsfe rien. Bestel len Sie in die ser plea se send written orders only. The staff will be back Zeit bitte nur schriftlich. Ab dem 10. Janu ar 2005 sind ser ving you du ring our re gu lar bu si ness hours on Mon- wir wie der für Sie da. day 10th, 2004. We would like to thank all our custo - Bei die ser Ge le gen heit be dan ken wir uns für die gute mers for their co-opera ti on in 2004. It has been a Zu sam men ar beit im ver gan ge nen Jahr. plea su re wor king with you. BEAR FAMILY is wis hing you a Wir wünschen Ihnen ein fro hes Weih nachts- Merry Christmas and a Happy New Year. fest und ein glüc kliches neu es Jahr. COUNTRY CHRISTMAS ..........2 BEAT, 60s/70s ..................86 COUNTRY .........................8 SURF .............................92 AMERICANA/ROOTS/ALT. .............25 REVIVAL/NEO ROCKABILLY ............93 OUTLAWS/SINGER-SONGWRITER .......25 PSYCHOBILLY ......................97 WESTERN..........................31 BRITISH R&R ........................98 WESTERN SWING....................32 SKIFFLE ...........................100 TRUCKS & TRAINS ...................32 INSTRUMENTAL R&R/BEAT .............100 C&W SOUNDTRACKS.................33 C&W SPECIAL COLLECTIONS...........33 POP.............................102 COUNTRY CANADA..................33 POP INSTRUMENTAL .................108 COUNTRY -

Linda Davis 87Th Session
NEW YOU’RE INVITED VENUE Don’t Miss Out! 2021 Register Today! Call 817-426-9395 TACO SPRING MEETING To Register & TRADE SHOW (In The Fall) September 14 & 15, 2021 Lone Star Convention & Expo Center Conroe, TX Entertainment Gov’t Affairs THREE-Time Grammy Winner: See more on pgs 4 & 5 & Education See more on pg 6 Full Report of 2021 Linda Davis 87th Session Largest Campground Vendor Tradeshow In The Southwest - TEXAS CAMPGROUNDS Including Park Model Area See more on pgs 4 & 5 TEXAS CAMPGROUNDS www.TACOMembers.com Meet Some of Our Exhibitors - Here for YOU! ACCESSPARKS . 858-353-0845 CLEC-COMMERCIAL AND LELANDS COMMERCIAL CABINS . 817-587-6520 Tim Rout • San Diego, CA COIN LAUNDRY EQUIPMENT CO . 800-888-0074 Carol Stevens • Grandview, TX Wi-Fi that just works, enabling 4,000+ devices to Trey Stein/ Danny English • Pasadena, TX Cabins, Portable Buildings, RV Covers . simultaneously stream . Sales/service/parts for coin & card operated laundry lelandscabins.com accessparks.com equipment . MARSHALL & STERLING CAMPGROUND INSURANCE AGS GUEST GUIDES . 877-518-1989 clecco.com PROGRAM . 800-782-2926 Michael Moore • Crowley, TX COMMERCIAL EQUIPMENT CO . 972-991-9274 Brian Seigerman / Irene Jones • Monticello, NY Guest guides, site maps and marketing . Forrest Smith / John Francis Insurance broker with new, exclusive campground agspub.com Laundry Equipment Provider . insurance carrier . AMERIS BANK SBA & USDA LENDING . 281-384-2595 ceclaundry.com campgroundandhospitalityinsure.com Bruce Hurta • Houston, TX FIRESIDE LODGE FURNITURE CO 218-568-6188 NEWPORT PACIFIC CAPITAL CO . 281-334-6426 SBA & USDA lending - dedicated to helping small Sara Pridgen • Pequot Lakes, MN Karri Seeds / Ruth Gomez • Irvine, CA businesses grow . -

Working Finding Aid the Center for Popular Music
THIS COLLECTION IS STILL IN PROCESS – WORKING FINDING AID THE CENTER FOR POPULAR MUSIC, MIDDLE TENNESSEE STATE UNIVERSITY, MURFREESBORO, TN ALAN L. MAYOR COLLECTION 17-005 Creator: Mayor, Alan Leslie (August 21, 1949 – February 22, 2015) Type of Material: Manuscript Materials, Photographs, Negatives, Slides, Datebooks, Sound Recordings Physical Description: 162 linear feet of manuscript material including: 113 linear feet of photographic prints 19 linear feet of negatives 22 linear feet of slides 5 linear feet of CD/DVD/Floppy disc photographic files 1 linear foot of datebooks 2 linear foot of press passes Dates: circa 1977 – 2012, bulk 1990-2000 Access/Restrictions: The collection is partially processed, but is open for research use. The Center for Popular Music only owns rights to the physical materials in this collection. All materials in this collection are under copyright that is owned by the Mayor Family. Researchers must receive prior written permission from the Mayor Family for any reproductions of use. Center staff are able to assist with copyright questions for this material. Provenance and Acquisition Information: This collection was donated by Alan Mayor’s sister, Theresa Mayor Smith, in October 2017. The Center’s Director and Archivist picked up a portion of the collection on October 6, 2017 from Mrs. Smith’s storage unit in Cadiz, Kentucky. The second, and largest, portion was picked up by the Center’s Archivist and Assistant Archivist on October 13, 2017 from Cadiz, Kentucky. The third batch of remanding binders of negatives was dropped off at the Center by Mrs. Smith on November 9, 2017. Subjects/Index Terms: Country music – 1971-1980 THIS COLLECTION IS STILL IN PROCESS – WORKING FINDING AID Alan L. -

Songs by Title
Karaoke Song Book Songs by Title Title Artist Title Artist #1 Nelly 18 And Life Skid Row #1 Crush Garbage 18 'til I Die Adams, Bryan #Dream Lennon, John 18 Yellow Roses Darin, Bobby (doo Wop) That Thing Parody 19 2000 Gorillaz (I Hate) Everything About You Three Days Grace 19 2000 Gorrilaz (I Would Do) Anything For Love Meatloaf 19 Somethin' Mark Wills (If You're Not In It For Love) I'm Outta Here Twain, Shania 19 Somethin' Wills, Mark (I'm Not Your) Steppin' Stone Monkees, The 19 SOMETHING WILLS,MARK (Now & Then) There's A Fool Such As I Presley, Elvis 192000 Gorillaz (Our Love) Don't Throw It All Away Andy Gibb 1969 Stegall, Keith (Sitting On The) Dock Of The Bay Redding, Otis 1979 Smashing Pumpkins (Theme From) The Monkees Monkees, The 1982 Randy Travis (you Drive Me) Crazy Britney Spears 1982 Travis, Randy (Your Love Has Lifted Me) Higher And Higher Coolidge, Rita 1985 BOWLING FOR SOUP 03 Bonnie & Clyde Jay Z & Beyonce 1985 Bowling For Soup 03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 BOWLING FOR SOUP '03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 Bowling For Soup 03 Bonnie And Clyde Jay Z & Beyonce 1999 Prince 1 2 3 Estefan, Gloria 1999 Prince & Revolution 1 Thing Amerie 1999 Wilkinsons, The 1, 2, 3, 4, Sumpin' New Coolio 19Th Nervous Breakdown Rolling Stones, The 1,2 STEP CIARA & M. ELLIOTT 2 Become 1 Jewel 10 Days Late Third Eye Blind 2 Become 1 Spice Girls 10 Min Sorry We've Stopped Taking Requests 2 Become 1 Spice Girls, The 10 Min The Karaoke Show Is Over 2 Become One SPICE GIRLS 10 Min Welcome To Karaoke Show 2 Faced Louise 10 Out Of 10 Louchie Lou 2 Find U Jewel 10 Rounds With Jose Cuervo Byrd, Tracy 2 For The Show Trooper 10 Seconds Down Sugar Ray 2 Legit 2 Quit Hammer, M.C. -

Women's Hit Cheating Songs: Country Music and Feminist Change in American Society, 1962-2015 Madeline Rachel Morrow University of Denver
University of Denver Digital Commons @ DU Electronic Theses and Dissertations Graduate Studies 1-1-2017 Women's Hit Cheating Songs: Country Music and Feminist Change in American Society, 1962-2015 Madeline Rachel Morrow University of Denver Follow this and additional works at: https://digitalcommons.du.edu/etd Part of the Feminist, Gender, and Sexuality Studies Commons, Music Commons, and the Women's History Commons Recommended Citation Morrow, Madeline Rachel, "Women's Hit Cheating Songs: Country Music and Feminist Change in American Society, 1962-2015" (2017). Electronic Theses and Dissertations. 1258. https://digitalcommons.du.edu/etd/1258 This Thesis is brought to you for free and open access by the Graduate Studies at Digital Commons @ DU. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of Digital Commons @ DU. For more information, please contact [email protected],[email protected]. WOMEN’S HIT CHEATING SONGS: COUNTRY MUSIC AND FEMINIST CHANGE IN AMERICAN SOCIETY, 1962-2015 __________ A Thesis Presented to the Faculty of Arts and Humanities University of Denver __________ In Partial Fulfillment of the requirements for the Degree Master of Arts __________ by Madeline Rachel Morrow June 2017 Advisor: John J. Sheinbaum ©Copyright by Madeline Rachel Morrow 2017 All Rights Reserved Author: Madeline Rachel Morrow Title: WOMEN’S HIT CHEATING SONGS: COUNTRY MUSIC AND FEMINIST CHANGE IN AMERICAN SOCIETY, 1962-2015 Advisor: John J. Sheinbaum Degree Date: June 2017 ABSTRACT This thesis examines songs about cheating performed by women in country music that appeared on year-end country songs charts in Billboard magazine from 1962 through 2015. -

Nelly's Project.Indd
Nelly’s Project Presented by WELCOME Welcome to Nellys’ Project – the fi rst fundraiser for Soul Sisters Memorial Foundation. Our non profi t society was formed in February 2014; a few short months after the death of our daughter Evening Itinerary Jeanelle Lobsinger. My sisters and I felt the need to organize a way to bring awareness to suicide and mental health issues within the community. Our mission is to get people talking about mental Cocktails 5pm health and to erase the stigma attached; thus reducing the suicide rate. This has been an uphill battle for myself and my family; however planning this event has assisted us on our path of healing. Master of Ceremonies - Danny Hooper Together and with the right information; we hope to save lives. Grace - Blair & Vincent Lobsinger THANK YOU It all started with an idea and look where we are in less than 7 months! Dinner 6 PM Tonight would not be possible without the generosity of everyone in this hall; and for that we thank you from the bottom of our hearts . Whether you were a volunteer, donated an auction item, bought Live Auctions throughout 50/50 tickets, purchased a cookbook, provided the entertainment, made a cash contribution; each and every one of you has helped our fi rst fundraiser be an absolute success. I am very pleased to Westlock Victim Services - Angie Hampshire donate proceeds from tonight to Victim Services Westlock and Pilgrims Hospice Edmonton. We will continue to fundraise and create awareness for suicide and mental health issues. Pilgrims Hospice - Cheryl Saulter-Roberts We look forward to our next event – stay tuned! Colored Tears & Expressive Arts - Blair Lobsinger God bless the community we live in and the generous people in our lives. -

Gp-Cabaretseries-Feb2021-Full-Playbill
Experience, Knowledge, Proven Results. FROM OLD NAPLES TO NAPLES SQUARE TO THE ISLES OF COLLIER PRESERVE Whether you are selling your home or condo or buying a home or condo, call me and let’s get started! BRUCE MILLER (239) 206-0868 720 5th Avenue South, Suite 201, Naples, FL 34102 [email protected] www.NaplesBeachesRealEstate.com CERTIFIED LUXURY HOME MARKETING SPECIALIST®, REALTOR® Welcome to Gulfshore Playhouse. On behalf of the law firm Denton’s Cohen & Grigsby, we are honored to serve once again as a corporate partner of Gulfshore Playhouse and to play a supporting role in bringing first class, professional theatre to Naples. For more than a decade, Denton’s Cohen & Grigsby has been practicing A Culture of Performance in Southwest Florida, representing clients with sound business counsel, innovative legal thinking, and a powerful understanding of the dynamics that shape our world. We are particularly proud of our collaboration with Gulfshore Playhouse which assists with bringing the arts and education to area schools, including the ThinkTheatre cross-curricular program, the STAR Academy afterschool and summer programs, the community partnerships, and more. Our partnership with Gulfshore Playhouse is a way of extending our firm’s high level of commitment to the arts, enriching the communities in which we serve. We hope you enjoy tonight’s performance and continue to support Gulfshore Playhouse, an exceptional cultural resource and treasure for our community. Sincerely, Jason Hunter Korn Managing Director, Denton’s Cohen & Grigsby, Florida A Letter from the Founder elcome home. I am sure I need not tell you how unspeakably thrilled I am that after EIGHT WMONTHS of darkness we are able to safely gather and present you with a season filled with a variety of unique opportunities created expressly with the safety of our actors, staff, and of course YOU in mind. -
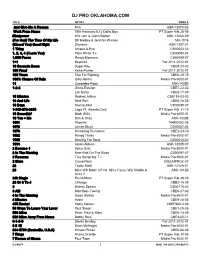
1 Column Unindented
DJ PRO OKLAHOMA.COM TITLE ARTIST SONG # Just Give Me A Reason Pink ASK-1307A-08 Work From Home Fifth Harmony ft.Ty Dolla $ign PT Super Hits 28-06 #thatpower Will.i.am & Justin Bieber ASK-1306A-09 (I've Had) The Time Of My Life Bill Medley & Jennifer Warnes MH-1016 (Kissed You) Good Night Gloriana ASK-1207-01 1 Thing Amerie & Eve CB30053-02 1, 2, 3, 4 (I Love You) Plain White T's CB30094-04 1,000 Faces Randy Montana CB60459-07 1+1 Beyonce Fall 2011-2012-01 10 Seconds Down Sugar Ray CBE9-23-02 100 Proof Kellie Pickler Fall 2011-2012-01 100 Years Five For Fighting CBE6-29-15 100% Chance Of Rain Gary Morris Media Pro 6000-01 11 Cassadee Pope ASK-1403B 1-2-3 Gloria Estefan CBE7-23-03 Len Barry CBE9-11-09 15 Minutes Rodney Atkins CB5134-03-03 18 And Life Skid Row CBE6-26-05 18 Days Saving Abel CB30088-07 1-800-273-8255 Logic Ft. Alessia Cara PT Super Hits 31-10 19 Somethin' Mark Wills Media Pro 6000-01 19 You + Me Dan & Shay ASK-1402B 1901 Phoenix PHM1002-05 1973 James Blunt CB30067-04 1979 Smashing Pumpkins CBE3-24-10 1982 Randy Travis Media Pro 6000-01 1985 Bowling For Soup CB30048-02 1994 Jason Aldean ASK-1303B-07 2 Become 1 Spice Girls Media Pro 6000-01 2 In The Morning New Kids On The Block CB30097-07 2 Reasons Trey Songz ftg. T.I. Media Pro 6000-01 2 Stars Camp Rock DISCMPRCK-07 22 Taylor Swift ASK-1212A-01 23 Mike Will Made It Feat.