A Personal Firewall for Linux” Describes My Attempt
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Security Administration
Information Security Group Information + Technology Services University of Toronto Endpoint Security Policy System A Network Access Control System with Vulnerability Detection and User Remediation Evgueni Martynov UNIX Systems Group Mike Wiseman Computer Security Administration Endpoint Security Policy System Table of Contents Acknowledgements............................................................................. 3 Change History .................................................................................... 4 Summary ............................................................................................. 5 Overview .............................................................................................. 5 Network Isolation ............................................................................... 6 Vulnerability Detection ....................................................................... 6 User Remediation ................................................................................ 8 Administering ESP ............................................................................... 8 ESP Operations Experience ................................................................ 9 Appendix I – Installation and Configuration of ESP server ........... 10 Using init.sh ..................................................................................... 10 Post-Installation ................................................................................ 11 Configuring an ESP Server to Work with an ESP Agent ....................... -

Personal Firewalls Are a Necessity for Solo Users
Personal firewalls are a necessity for solo users COMPANY PRODUCT PLATFORM NOTES PRICE Aladdin Knowledge Systems Ltd. SeSafe Desktop Windows Combines antivirus with content filtering, blocking and $72 Arlington Heights, Ill. monitoring 847-808-0300 www.ealaddin.com Agnitum Inc. Outpost Firewall Pro Windows Blocks ads, sites, programs; limits access by specific times $40 Nicosia, Cyprus www.agnitum.com Computer Associates International Inc. eTrust EZ Firewall Windows Basic firewall available only by download $40/year Islandia, N.Y. 631-342-6000 my-etrust.com Deerfield Canada VisNetic Firewall Windows Stateful, packet-level firewall for workstations, mobile $101 (Canadian) St. Thomas, Ontario for Workstations users or telecommuters 519-633-3403 www.deerfieldcanada.ca Glucose Development Corp. Impasse Mac OS X Full-featured firewall with real-time logging display $10 Sunnyvale, Calif. www.glu.com Intego Corp. NetBarrier Personal Firewall Windows Full-featured firewall with cookie and ad blocking $50 Miami 512-637-0700 NetBarrier 10.1 Mac OS X Full-featured firewall $60 www.intego.com NetBarrier 2.1 Mac OS 8 and 9 Full-featured firewall $60 Internet Security Systems Inc. BlackIce Windows Consumer-oriented PC firewall $30 Atlanta 404-236-2600 RealSecure Desktop Windows Enterprise-grade firewall system for remote, mobile and wireless users Varies blackice.iss.net/ Kerio Technologies Inc. Kerio Personal Firewall Windows Bidirectional, stateful firewall with encrypted remote-management option $39 Santa Clara, Calif. 408-496-4500 www.kerio.com Lava Software Pty. Ltd. AdWare Plus Windows Antispyware blocks some advertiser monitoring but isn't $27 Falköping, Sweden intended to block surveillance utilities 46-0-515-530-14 www.lavasoft.de Network Associates Inc. -

Hostscan 4.8.01064 Antimalware and Firewall Support Charts
HostScan 4.8.01064 Antimalware and Firewall Support Charts 10/1/19 © 2019 Cisco and/or its affiliates. All rights reserved. This document is Cisco public. Page 1 of 76 Contents HostScan Version 4.8.01064 Antimalware and Firewall Support Charts ............................................................................... 3 Antimalware and Firewall Attributes Supported by HostScan .................................................................................................. 3 OPSWAT Version Information ................................................................................................................................................. 5 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.890.0 for Windows .................................................. 5 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.890.0 for Windows ........................................................ 44 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.824.0 for macos .................................................... 65 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.824.0 for macOS ........................................................... 71 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.730.0 for Linux ...................................................... 73 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.730.0 for Linux .............................................................. 76 ©201 9 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. -

Lecture 11 Firewalls
BSc in Telecommunications Engineering TEL3214 Computer Communication Networks Lecture 11 Firewalls Eng Diarmuid O'Briain, CEng, CISSP 11-2 TEL3214 - Computer Communication Networks Copyright © 2017 Diarmuid Ó Briain Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back- Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". TEL3214 Firewalls 09 May 2017 TEL3214 - Computer Communication Networks 11-3 Table of Contents 1. AN INTRODUCTION TO FIREWALLS........................................................................................................................5 2. THE DIGITAL SECURITY PROBLEM...........................................................................................................................5 2.1 HOME......................................................................................................................................................................5 2.2 ENTERPRISE...............................................................................................................................................................6 2.3 ROAMING INDIVIDUAL.................................................................................................................................................6 2.4 PERIMETER DEFENCE AND FIREWALLS.............................................................................................................................6 -

Comodo Korugan UTM Security Target Lite
Comodo Yazılım A.Ş. Tasnif Dışı/Unclassified Comodo Korugan UTM Security Target Lite Comodo Yazılım A.Ş. Comodo Korugan UTM 1.10 Security Target Lite COMODO YAZILIM A.Ş. The copyright and design right in this document are vested in Comodo Yazılım A.Ş. and the document is supplied to you for a limited purpose and only in connection with this project. No information as to the contents or the subject matter of this document or any part thereof shall be communicated in any manner to any third party without the prior consent in writing of Comodo Yazılım A.Ş. Copyright © Comodo Yazılım A.Ş., 2014-2017 Comodo Yazılım A.Ş. 1 / 48 Author: Onur Özardıç Comodo Yazılım A.Ş. Tasnif Dışı/Unclassified Comodo Korugan UTM Security Target Lite List of Tables Table 1 ST and TOE References ........................................................................................ 6 Table 2 Functional features of TOE ..................................................................................... 8 Table 3 Major Security Features of TOE ............................................................................. 8 Table 4 Assets using TOE resources .................................................................................15 Table 5 Threats addressed by TOE only ............................................................................16 Table 6 Threats met by TOE and TOE Security Environment ............................................16 Table 7 Threats Addressed by TOE Security Environment .................................................16 Table -

Listener Q&A #8
Transcript of Episode #44 Listener Feedback Q&A #8 Description: Steve and Leo discuss questions asked by listeners of their previous episodes. They tie up loose ends, explore a wide range of topics that are too small to fill their own episode, clarify any confusion from previous installments, and present real world “application notes" for any of the security technologies and issues they have previously discussed. High quality (64 kbps) mp3 audio file URL: http://media.GRC.com/sn/SN-044.mp3 Quarter size (16 kbps) mp3 audio file URL: http://media.GRC.com/sn/sn-044-lq.mp3 Leo Laporte: Bandwidth for Security Now! is provided by AOL Radio at AOL.com/podcasting. This is Security Now! with Steve Gibson, Episode 44 for June 15, 2006: Your questions, Steve’s answers. Security Now! is brought to you by Astaro, makers of the Astaro Security Gateway, on the web at www.astaro.com. I smell a mod 4 episode. I do indeed. Leo Laporte here, Steve Gibson in Irvine, and it’s Episode 44. And as far as I can tell, that’s divisible by 4. Steve Gibson: That’s like a double mod 4. Leo: That’s a double mod 4. Steve: Yeah. Leo: So we get our usual 20 questions. Steve: It’s even mod 11. Leo: Mod 11, mod 4, mod 2, mod 0... Steve: Mod 22. Yeah. Leo: All right. You math showoff. Let’s get to the questions, unless there’s anything we want to cover from our last episode, where we talked all about ports. -
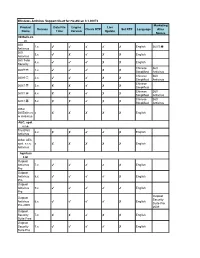
Windows Antivirus Support Chart for Hostscan 3.1.06073 Product Name
Windows Antivirus Support Chart for HostScan 3.1.06073 Marketing Product Data File Engine Live Version Check RTP Set RTP Language Alias Name Time Version Update Names 360Safe.co m 360 1.x ✔ ✔ ✔ ✔ ✔ English 360杀毒 Antivirus 360 3.x ✔ ✘ ✔ ✘ ✘ English Antivirus 360 Total 4.x ✔ ✔ ✔ ✘ ✘ English Security Chinese 360 360杀毒 1.x ✔ ✔ ✔ ✘ ✘ Simplified Antivirus Chinese 360 360杀毒 2.x ✔ ✔ ✔ ✘ ✘ Simplified Antivirus Chinese 360杀毒 3.x ✘ ✘ ✔ ✘ ✘ Simplified Chinese 360 360杀毒 4.x ✘ ✘ ✔ ✘ ✘ Simplified Antivirus Chinese 360 360杀毒 5.x ✘ ✘ ✔ ✘ ✘ Simplified Antivirus Other 360Safe.co x ✘ ✘ ✘ ✘ ✘ English m Antivirus AEC, spol. s r.o. TrustPort 2.x ✘ ✘ ✔ ✔ ✘ English Antivirus Other AEC, spol. s r.o. x ✘ ✘ ✘ ✘ ✘ English Antivirus Agnitum Ltd. Outpost Antivirus 7.x ✔ ✔ ✔ ✔ ✘ English Pro Outpost Antivirus 8.x ✔ ✔ ✔ ✔ ✘ English Pro Outpost Antivirus 9.x ✔ ✔ ✔ ✔ ✔ English Pro Outpost Outpost Security Antivirus 6.x ✔ ✔ ✔ ✔ ✘ English Suite Pro Pro 2009 2009 Outpost Security 7.x ✘ ✘ ✔ ✘ ✘ English Suite Free Outpost Security 7.x ✔ ✔ ✔ ✔ ✘ English Suite Pro Outpost Security 8.x ✔ ✔ ✔ ✔ ✔ English Suite Pro Outpost Security 9.x ✔ ✔ ✔ ✔ ✔ English Suite Pro Other Agnitum x ✘ ✘ ✘ ✘ ✘ English Ltd. Antivirus AhnLab, Inc. AhnLab Security 2.x ✔ ✔ ✘ ✔ ✘ English Pack AhnLab V3 Internet 7.x ✔ ✔ ✔ ✔ ✘ English Security 2007 AhnLab V3 Internet Security 7.x ✔ ✔ ✔ ✔ ✘ English 2007 Platinum AhnLab V3 Internet Security 7.x ✔ ✔ ✔ ✔ ✘ English 2008 Platinum AhnLab V3 Internet Security 7.x ✔ ✔ ✔ ✔ ✔ English 2009 Platinum AhnLab V3 Internet Security 7.0 7.x ✔ ✔ ✔ ✔ ✘ English Platinum Enterprise AhnLab V3 Internet 8.x ✔ ✔ ✔ ✔ ✔ English Security 8.0 AhnLab V3 Internet 9.x ✔ ✔ ✔ ✔ ✔ English Security 9.0 AhnLab V3 VirusBlock Internet 7.x ✔ ✔ ✘ ✔ ✘ English Security 2007 AhnLab V3 VirusBlock Internet Security 7.x ✔ ✔ ✔ ✘ ✔ English 2007 Platinum Enterprise V3 Click 1.x ✔ ✘ ✘ ✘ ✘ English V3 Lite 1.x ✔ ✔ ✔ ✔ ✔ Korean V3 Lite 3.x ✔ ✔ ✔ ✘ ✘ Korean V3 VirusBlock 6.x ✔ ✔ ✘ ✘ ✘ English 2005 V3 ウイルスブ NA ✔ ✔ ✘ ✔ ✘ Japanese ロック V3Pro 2004 6.x ✔ ✔ ✔ ✔ ✘ English Other AhnLab, x ✘ ✘ ✘ ✘ ✘ English Inc. -

The Book of PF Covers the Most • Stay in Control of Your Traffic with Monitoring and Up-To-Date Developments in PF, Including New Content PETER N.M
EDITION3RD BUILD A Covers OpenBSD 5.6, MORE SECURE FreeBSD 10.x, and NETWORK EDITION NETWORK 3RD NetBSD 6.x WITH PF THETHE BOOKBOOK THE BOOK OF PF OF THE BOOK THE BOOK OF PF OF THE BOOK OFOF PFPF OpenBSD’s stateful packet filter, PF, is the heart of • Build adaptive firewalls to proactively defend against A GUIDE TO THE the OpenBSD firewall. With more and more services attackers and spammers NO-NONSENSE placing high demands on bandwidth and an increas- OPENBSD FIREWALL • Harness OpenBSD’s latest traffic-shaping system ingly hostile Internet environment, no sysadmin can to keep your network responsive, and convert your afford to be without PF expertise. existing ALTQ configurations to the new system The third edition of The Book of PF covers the most • Stay in control of your traffic with monitoring and up-to-date developments in PF, including new content PETER N.M. HANSTEEN visualization tools (including NetFlow) on IPv6, dual stack configurations, the “queues and priorities” traffic-shaping system, NAT and redirection, The Book of PF is the essential guide to building a secure wireless networking, spam fighting, failover provision- network with PF. With a little effort and this book, you’ll ing, logging, and more. be well prepared to unlock PF’s full potential. You’ll also learn how to: ABOUT THE AUTHOR • Create rule sets for all kinds of network traffic, whether Peter N.M. Hansteen is a consultant, writer, and crossing a simple LAN, hiding behind NAT, traversing sysadmin based in Bergen, Norway. A longtime DMZs, or spanning bridges or wider networks Freenix advocate, Hansteen is a frequent lecturer on OpenBSD and FreeBSD topics, an occasional • Set up wireless networks with access points, and contributor to BSD Magazine, and the author of an lock them down using authpf and special access often-slashdotted blog (http://bsdly.blogspot.com/ ). -

Listener Feedback Q&A
Security Now! Transcript of Episode #173 Page 1 of 37 Transcript of Episode #173 Listener Feedback Q&A #55 Description: Steve and Leo discuss the week's major security events and discuss questions and comments from listeners of previous episodes. They tie up loose ends, explore a wide range of topics that are too small to fill their own episode, clarify any confusion from previous installments, and present real world 'application notes' for any of the security technologies and issues we have previously discussed. High quality (64 kbps) mp3 audio file URL: http://media.GRC.com/sn/SN-173.mp3 Quarter size (16 kbps) mp3 audio file URL: http://media.GRC.com/sn/sn-173-lq.mp3 INTRO: Netcasts you love, from people you trust. This is TWiT. Leo Laporte: Bandwidth for Security Now! is provided by AOL Radio at AOL.com/podcasting. This is Security Now! with Steve Gibson, Episode 173 for December 4, 2008: Listener Feedback #55. This show is brought to you by listeners like you and your contributions. We couldn't do it without you. Thanks so much. It's time for Security Now!, the show that looks at security, now. Right now. Right this minute. Steve Gibson is here. Hi, Steve. Steve Gibson: Hey, Leo. Leo: From GRC.com, the man who discovered spyware, coined the term, created the first antispyware program, has written so many useful security utilities like ShieldsUP!, Shoot The Messenger, Unplug n' Pray. And every week we talk about the latest security news and answer questions and also kind of explain, I think you're really good at teaching, what all this is. -

Nftables Och Iptables En Jämförelse Av Latens Nftables and Iptables a Comparison in Latency
NFtables and IPtables Jonas Svensson Eidsheim NFtables och IPtables En jämförelse av latens NFtables and IPtables A Comparison in Latency Bachelors Degree Project in Computer Science Network and Systems Administration, G2E, 22.5 hp IT604G Jonas Svensson Eidsheim [email protected] Examiner Jonas Gamalielsson Supervisor Johan Zaxmy Abstract Firewalls are one of the essential tools to secure any network. IPtables has been the de facto firewall in all Linux systems, and the developers behind IPtables are also responsible for its intended replacement, NFtables. Both IPtables and NFtables are firewalls developed to filter packets. Some services are heavily dependent on low latency transport of packets, such as VoIP, cloud gaming, storage area networks and stock trading. This work is aiming to compare the latency between the selected firewalls while under generated network load. The network traffic is generated by iPerf and the latency is measured by using ping. The measurement of the latency is done on ping packets between two dedicated hosts, one on either side of the firewall. The measurement was done on two configurations one with regular forwarding and another with PAT (Port Address Translation). Both configurations are measured while under network load and while not under network load. Each test is repeated ten times to increase the statistical power behind the conclusion. The results gathered in the experiment resulted in NFtables being the firewall with overall lower latency both while under network load and not under network load. Abstrakt Brandväggen är ett av de viktigaste verktygen för att säkra upp nätverk. IPtables har varit den främst använda brandväggen i alla Linux-system och utvecklarna bakom IPtables är också ansvariga för den avsedda ersättaren, NFtables. -

Netfilter:Making Large Iptables Rulesets Scale
Netfilter:Netfilter: MakingMaking largelarge iptablesiptables rulesetsrulesets scalescale Netfilter Developers Workshop 2008 d.1/10-2008 by Jesper Dangaard Brouer <[email protected]> Master of Computer Science ComX Networks A/S Who am I Name: Jesper Dangaard Brouer Edu: Computer Science for Uni. Copenhagen Focus on Network, Dist. sys and OS Linux user since 1996, professional since 1998 Sysadm, Developer, Embedded OpenSource projects Author of ADSL-optimizer CPAN IPTables::libiptc Patches accepted into Kernel, iproute2 and iptables Netfilter: Making large iptables rulesets scale 2/29 Physical surroundings ComX delivers fiber based solutions Our primary customers are apartment buildings but with end-user relation Ring based network topology with POPs (Point Of Presence) POPs have fiber strings to apartment buildings CPE box in apartment performs service separation into VLANs Netfilter: Making large iptables rulesets scale 3/29 The Linux box The iptables box(es), this talk is all about placed at each POP (near the core routers) high-end server PC, with only two netcards Internet traffic: from several apartment buildings, layer2 terminated via VLANs on one netcard, routed out the other. Cost efficient but needs to scale to a large number of customers goal is to scale to 5000 customers per machine Netfilter: Making large iptables rulesets scale 4/29 Issues and limitations First generation solution was in production. business grew and customers where added; several scalability issues arose The two primary were: Routing performance reduced (20 kpps) -

Firehol + Fireqos Reference
FireHOL + FireQOS Reference FireHOL Team Release 2.0.0-pre7 Built 13 Apr 2014 FireHOL + FireQOS Reference Release 2.0.0-pre7 i Copyright © 2012-2014 Phil Whineray <[email protected]> Copyright © 2004, 2013-2014 Costa Tsaousis <[email protected]> FireHOL + FireQOS Reference Release 2.0.0-pre7 ii Contents 1 Introduction 1 1.1 Latest version........................................1 1.2 Who should read this manual................................1 1.3 Where to get help......................................1 1.4 Manual Organisation....................................1 1.5 Installation.........................................2 1.6 Licence...........................................2 I FireHOL3 2 Configuration 4 2.1 Getting started........................................4 2.2 Language..........................................4 2.2.1 Use of bash.....................................4 2.2.1.1 What to avoid..............................4 3 Security 6 3.1 Important Security Note..................................6 3.2 What happens when FireHOL Runs?............................6 3.3 Where to learn more....................................7 4 Troubleshooting 8 4.1 Reading log output.....................................8 FireHOL + FireQOS Reference Release 2.0.0-pre7 iii II FireQOS 11 5 Configuration 12 III FireHOL Reference 13 6 Running and Configuring 14 6.1 FireHOL program: firehol................................. 15 6.2 FireHOL configuration: firehol.conf............................ 18 6.3 control variables: firehol-variables............................. 23