Mastering Fighting Game Using Deep Reinforcement Learning with Self-Play
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download the Catalog
WE SERVE BUSINESSES OF ALL SIZES WHO WE ARE We are an ambitious laser tag design and manufacturing company with a passion for changing the way people EXPERIENCE LIVE-COMBAT GAMING. We PROVIDE MANUFACTURING and support to businesses both big or small, around the world! With fresh thinking and INNOVATIVE GAMING concepts, our reputation has made us a leader in the live-action gaming space. One of the hallmarks of our approach to DESIGN & manufacturing is equipment versatility. Whether operating an indoor arena, outdoor battleground, mobile business, or a special entertainment OUR PRODUCTS HAVE THE HIGHEST REPLAY attraction our equipment can be CUSTOMIZED TO FIT your needs. Battle Company systems will expand your income opportunities and offer possibilities where the rest of the industry can only provide VALUE IN THE LASER TAG INDUSTRY limitations. Our products are DESIGNED AND TESTED at our 13-acre property headquarters. We’ve put the equipment into action in our 5,000 square-foot indoor laser tag facility as well as our newly constructed outdoor battlefield. This is to ensure the highest level of design quality across the different types of environments where laser tag is played. Using Agile development methodology and manufacturing that is ISO 9001 CERTIFIED, we are the fastest manufacturer in the industry when it comes to bringing new products and software to market. Battle Company equipment has a strong competitive advantage over other brands and our COMMITMENT TO R&D is the reason why we are leading the evolution of the laser tag industry! 3 OUT OF 4 PLAYERS WHO USE BATTLE COMPANY BUSINESSES THAT CHOOSE US TO POWER THEIR EXPERIENCE EQUIPMENT RETURN TO PLAY AGAIN! WE SERVE THE MILITARY 3 BIG ATTRACTION SMALL FOOTPRINT Have a 10ft x 12.5ft space not making your facility much money? Remove the clutter and fill that area with the Battle Cage. -

Fighting Games, Performativity, and Social Game Play a Dissertation
The Art of War: Fighting Games, Performativity, and Social Game Play A dissertation presented to the faculty of the Scripps College of Communication of Ohio University In partial fulfillment of the requirements for the degree Doctor of Philosophy Todd L. Harper November 2010 © 2010 Todd L. Harper. All Rights Reserved. This dissertation titled The Art of War: Fighting Games, Performativity, and Social Game Play by TODD L. HARPER has been approved for the School of Media Arts and Studies and the Scripps College of Communication by Mia L. Consalvo Associate Professor of Media Arts and Studies Gregory J. Shepherd Dean, Scripps College of Communication ii ABSTRACT HARPER, TODD L., Ph.D., November 2010, Mass Communications The Art of War: Fighting Games, Performativity, and Social Game Play (244 pp.) Director of Dissertation: Mia L. Consalvo This dissertation draws on feminist theory – specifically, performance and performativity – to explore how digital game players construct the game experience and social play. Scholarship in game studies has established the formal aspects of a game as being a combination of its rules and the fiction or narrative that contextualizes those rules. The question remains, how do the ways people play games influence what makes up a game, and how those players understand themselves as players and as social actors through the gaming experience? Taking a qualitative approach, this study explored players of fighting games: competitive games of one-on-one combat. Specifically, it combined observations at the Evolution fighting game tournament in July, 2009 and in-depth interviews with fighting game enthusiasts. In addition, three groups of college students with varying histories and experiences with games were observed playing both competitive and cooperative games together. -

Deepcrawl: Deep Reinforcement Learning for Turn-Based Strategy Games
DeepCrawl: Deep Reinforcement Learning for Turn-based Strategy Games Alessandro Sestini,1 Alexander Kuhnle,2 Andrew D. Bagdanov1 1Dipartimento di Ingegneria dell’Informazione, Universita` degli Studi di Firenze, Florence, Italy 2Department of Computer Science and Technology, University of Cambridge, United Kingdom falessandro.sestini, andrew.bagdanovg@unifi.it Abstract super-human skills able to solve a variety of environments. However the main objective of DRL of this type is training In this paper we introduce DeepCrawl, a fully-playable Rogue- like prototype for iOS and Android in which all agents are con- agents to surpass human players in competitive play in clas- trolled by policy networks trained using Deep Reinforcement sical games like Go (Silver et al. 2016) and video games Learning (DRL). Our aim is to understand whether recent ad- like DOTA 2 (OpenAI 2019). The resulting, however, agents vances in DRL can be used to develop convincing behavioral clearly run the risk of being too strong, of exhibiting artificial models for non-player characters in videogames. We begin behavior, and in the end not being a fun gameplay element. with an analysis of requirements that such an AI system should Video games have become an integral part of our entertain- satisfy in order to be practically applicable in video game de- ment experience, and our goal in this work is to demonstrate velopment, and identify the elements of the DRL model used that DRL techniques can be used as an effective game design in the DeepCrawl prototype. The successes and limitations tool for learning compelling and convincing NPC behaviors of DeepCrawl are documented through a series of playability tests performed on the final game. -

Application of Retrograde Analysis to Fighting Games
University of Denver Digital Commons @ DU Electronic Theses and Dissertations Graduate Studies 1-1-2019 Application of Retrograde Analysis to Fighting Games Kristen Yu University of Denver Follow this and additional works at: https://digitalcommons.du.edu/etd Part of the Artificial Intelligence and Robotics Commons, and the Game Design Commons Recommended Citation Yu, Kristen, "Application of Retrograde Analysis to Fighting Games" (2019). Electronic Theses and Dissertations. 1633. https://digitalcommons.du.edu/etd/1633 This Thesis is brought to you for free and open access by the Graduate Studies at Digital Commons @ DU. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of Digital Commons @ DU. For more information, please contact [email protected],[email protected]. Application of Retrograde Analysis to Fighting Games A Thesis Presented to the Faculty of the Daniel Felix Ritchie School of Engineering and Computer Science University of Denver In Partial Fulfillment of the Requirements for the Degree Master of Science by Kristen Yu June 2019 Advisor: Nathan Sturtevant ©Copyright by Kristen Yu 2019 All Rights Reserved Author: Kristen Yu Title: Application of Retrograde Analysis to Fighting Games Advisor: Nathan Sturtevant Degree Date: June 2019 Abstract With the advent of the fighting game AI competition [34], there has been re- cent interest in two-player fighting games. Monte-Carlo Tree-Search approaches currently dominate the competition, but it is unclear if this is the best approach for all fighting games. In this thesis we study the design of two-player fighting games and the consequences of the game design on the types of AI that should be used for playing the game, as well as formally define the state space that fighting games are based on. -
History of Value Creation
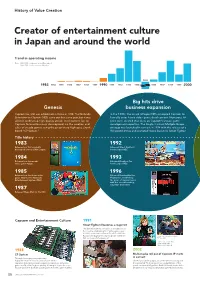
History of Value Creation Creator of entertainment culture in Japan and around the world Trend in operating income Note: 1983–1988: Fiscal years ended December 31 1989–2020: Fiscal years ended March 31 1995 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1996 1997 1998 1999 2000 Big hits drive Genesis business expansion Capcom Co., Ltd. was established in Osaka in 1983. The Nintendo In the 1990s, the arrival of Super NES prompted Capcom to Entertainment System (NES) came out that same year, but it was formally enter home video game development. Numerous hit difficult to develop high-quality arcade-level content for, so titles were created that drew on Capcom’s arcade game Capcom focused business development on the creation and development expertise. The Single Content Multiple Usage sales of arcade games using the proprietary high-spec circuit strategy was launched in earnest in 1994 with the release of a board “CP System.” Hollywood movie and animated movie based on Street Fighter. Title history 1983 1992 Released our first originally Released Street Fighter II developed coin-op Little League. for the Super NES. 1984 1993 Released our first arcade Released Breath of Fire video game Vulgus. for the Super NES. 1985 1996 Released our first home video Released Resident Evil for game 1942 for the Nintendo PlayStation, establishing Entertainment System (NES). the genre of survival horror with this record-breaking, long-time best-seller. 1987 Released Mega Man for the NES. Capcom and Entertainment Culture 1991 Street Fighter II becomes a major hit The game became a sensation in arcades across the country, establishing the fighting game genre. -

Dengeki Bunko Fighting Climax Download Pc Free
Dengeki Bunko Fighting Climax Download Pc Free Dengeki Bunko Fighting Climax Download Pc Free 1 / 3 2 / 3 The update to Dengeki Bunko: Fighting Climax titled IGNITION is ... Store for download on Playstation 4 console(Vita and PS3 should be .... Amazon.com: Dengeki Bunko: Fighting Climax - PlayStation 3 Standard Edition: ... Note: Available at a lower price from other sellers that may not offer free Prime .... Mega Game - Dengeki Bunko: Fighting Climax Version - Summary: Dengeki Bunko: Fighting Climax sports a character roster of 14 playable .... Speaking of the ps3 version, dengeki bunko fighting climax ignition english ps3 i wonder if this patch would work for it. ... Download game pc 18+, game pc sexy, game pc hentai, game pc 18+ 3d, game pc 18+ free, game eroge, game 3dcg.. Dengeki Bunko Fighting Climax psvita, Download game psvita free new, Hack game psvita update dlc nonpdrm maidump vpk ... Guide Connect PS Vita to PC.. Dengeki Bunko Fighting Climax Ignition PS3 ISO Download. Download Size: 1.49 GB Show Download Links. Solve Captcha to see links and .... Dengeki Bunko Fighting Climax PS4 JPN ISO, Download Dengeki Bunko ... PS4 Full Version [USA + JPN] ISO & PKG + Fix all update DLC Free.. Dengeki Bunko: Fighting Climax is a two-dimensional fighting game, in which two ... The roster features characters under the Dengeki Bunko imprint, among .... Play Dengeki Bunko: Fighting Climax Ignition on PC, NO EMULATOR NEEDED. Dengeki ... See more of Free PC games download full version on Facebook.. [MEGA] Dengeki Bunko Fighting Climax IGNITION Complete Game + v1.04 ... Tried to fix an issue with a could not download error with PKGJ a ... -

Creating Human-Like Fighting Game AI Through Planning
Creating Human-like Fighting Game AI through Planning Roger Liu CMU-CS-17-128 December 2017 School of Computer Science Computer Science Department Carnegie Mellon University Pittsburgh, PA Thesis Committee Maxim Likhachev, Chair Jessica Hodgins Submitted in partial fulfillment of the requirements for the Degree of Master of Science Copyright c 2017 Roger Liu ii Keywords: Artificial Intelligence, Human-Computer Interaction, Game AI, Plan- ning, Human-Imitation, Fighting Games iii CARNEGIE MELLON UNIVERSITY Abstract Faculty Name Department or School Name Master of Science Creating Human-like Fighting Game AI through Planning by Roger LIU Games are a major testing ground for Artificial Intelligence. Though AI has be- come proficient at playing games such as Space Invaders, it behaves in a way that is distinctly artificial, lacking the human-like qualities of a real player. This human ele- ment is important in competitive multiplayer games, as a large part of the enjoyment comes from outwitting other human strategies. To address this issue, we investigate a novel AI technique that leverages planning and human demonstrations to create an opponent that exhibits desirable qualities of human play in the context of a fight- ing game. We introduce the idea of action-ds, which relate the action performed with the change in the game state. These action-ds are learned from human demon- strations and are used to help the AI plan out strategies to hit the opponent. We implement a simple fighting game called FG for the AI to compete in and provide it a human demonstration to learn from. The AI utilizes action-ds with other search techniques to emulate human behavior. -

BAB I PENDAHULUAN A. Latar Belakang Budaya Populer Jepang
BAB I PENDAHULUAN A. Latar Belakang Budaya populer Jepang merupakan sebuah budaya yang berasal dari Jepang yang diakui, dinikmati, disebarluaskan dan merupakan jalan hidup mayoritas masyarakat Jepang secara umum. Budaya populer Jepang meliputi manga, anime, game, cosplay, dorama, j-pop, dan sebagainya. Manga merupakan suatu media yang di dalamnya terdapat sekumpulan gambar yang mengandung cerita yang bermacam-macam variasinya. Pada umumnya manga dicetak dalam warna hitam-putih dan terkadang ada beberapa bagian yang dicetak berwarna. Di Jepang, manga pada umumnya dicetak dalam majalah yang berukuran sebesar buku telepon dan sering terdiri dari berbagai cerita yang bersambung pada episode berikutnya. Budaya populer Jepang lainnya yaitu anime. Anime adalah produksi animasi Jepang yang menampilkan hasil gambar animasi melalui tangan maupun komputer. Istilah anime merupakan bahasa serapan dari bahasa Inggris “animation”. Dalam bahasa Inggris, istilah ini didefinisikan sebagai penyebarluasan gaya animasi Jepang yang pada umumnya dicirikan dengan grafis yang warna-warni, karakter yang bersemangat dan tema yang terkadang tidak masuk akal. Selain manga dan anime, cosplay juga termasuk ke dalam budaya populer Jepang. Cosplay adalah kata-kata bahasa Jepang yang dibuat dari menggabungkan dua kata dari bahasa Inggris "costume" dan "play". Cosplay merupakan sebuah pertunjukan seni di mana para pesertanya menggunakan kostum dan aksesori yang menunjukkan secara spesifik suatu karakter atau ide. Pada umumnya cosplay mengacu pada manga dan anime, manga, dan video game. Penduduk Jepang merupakan masyarakat penyuka game. Budaya Jepang yang disiplin dan pekerja keras menyebabkan masyarakat Jepang menyukai game sebagai salah satu sarana hiburan karena dengan bermain game masyarakat Jepang dapat mendapatkan kesenangan, menyegarkan kembali pikiran yang jenuh dengan pekerjaannya dan dapat membayangkan dirinya sebagai karakter game yang dimainkannya. -

Deduction of Fighting-Game Countermeasures Using the K-Nearest Neighbor Algorithm and a Game Simulator
Deduction of Fighting-Game Countermeasures Using the k-Nearest Neighbor Algorithm and a Game Simulator Kaito Yamamoto Syunsuke Mizuno1 Chun Yin Chu Ruck Thawonmas Intelligent Computer Intelligent Computer Department of Intelligent Computer Entertainment Laboratory Entertainment Laboratory Computer Science and Engineering Entertainment Laboratory Ritsumeikan University Ritsumeikan University Hong Kong University of Science & Technology Ritsumeikan University Shiga, Japan Shiga, Japan Hong Kong, PR China Shiga, Japan [email protected] Abstract—This paper proposes an artificial intelligence al- gorithm that uses the k-nearest neighbor algorithm to predict its opponent’s attack action and a game simulator to deduce a countermeasure action for controlling an in-game character in a fighting game. This AI algorithm (AI) aims at achieving good results in the fighting-game AI competition having been organized by our laboratory since 2013. It is also a sample AI, called MizunoAI, publicly available for the 2014 competition at CIG 2014. In fighting games, every action is either advantageous or disadvantageous against another. By predicting its opponent’s next action, our AI can devise a countermeasure which is advantageous against that action, leading to higher scores in the game. The effectiveness of the proposed AI is confirmed by the results of matches against the top-three AI entries of the 2013 competition. Fig. 1. Screen-shot of FightingICE where both sides use the same character I. INTRODUCTION from the 2013 competition. A fighting game is a genre of game in which humanoid or quasi-humanoid characters, individually controlled by nor- mally two players, engage in a hand-to-hand combat or a To avoid such situations, an AI must be able to choose combat with melee weapons, and the winner is determined from a variety of action patterns. -

Overview Your Task
( ( .) ) .) ) `(,' (, `(,' (, ). (, (' __ __ _ _ _____ ). (, (' ( ) ; ' ) | \/ | | | | __ \ ( ) ; ' ) ')_,_)_(` | \ / | | | | | | | ')_,_)_(` [_____] | |\/| | | | | | | | [_____] \_ _/ | | | | |__| | |__| | \_ _/ |_| |_| |_|\____/|_____/ |_| C Sc 335 Fall 2013 – Final Project Overview A MUD, or Multi-User Dungeon/Dimension/Domain, is a multi-player text environment (The player types commands and the MUD responds with text). This option involves implementing a functional, networked MUD. They often take the form of an RPG (role- playing game), however, you are not required to make it an RPG. Though there are many types and uses of MUDs, all of them share several common elements. A MUD consists of players, rooms, items, and MOBs (MOBile non player characters). Multiple players can connect to the MUD at any given time. They can interact with one another, move about from room to room and collect items that affect them or allow them to do things. MOBs can also move from room to room, and players may have complex interactions with them. Though most MOBs are hostile towards the player, they do not all need to be. Some MOBs may offer quests, services or games to the players. Rooms in a MUD should be thought of as locations rather than an indoor area with walls and a ceiling (A "room" could be a clearing in the woods with a path leading to the north and another to the west, or the middle of a field with paths leading in all directions). Rooms have exits that connect them to other rooms, descriptions, and contents (including items, players and MOBs). -

Fighting Games and Arcades Have Gone Hand in Hand for Decades, but Few Are More Famous Than Capcom's Flagship Game Series
Fighting games and arcades have gone hand in hand for decades, but few are more famous than Capcom’s flagship game series, Street Fighter. Of the many games in the series, Street Fighter 2 Turbo, out in 1994, has had the longest and largest impact, and is credited with launching the fighting game phenomenon both in arcades and tournaments across the world. We’re going to be throwing it back with this year’s release of the Street Fighter 30th Anniversary Edition; we are able to project this classic game onto our Noble planetarium dome screen, for players to duke it out in a larger than life setting. Free play will be offered for those who just want to relive a little bit of the 90’s, but for those who think they have what it takes, we are offering a lighthearted tournament with prizes for 1st, 2nd, and 3rd place. Additional entry fee is required separate from Give Back Game Night tickets. Tournament Rules: • Default Settings • Single elimination; 2/3 games per set • Standard character selection method • Winner must keep character, loser may choose new character • Stage selection will be random • Akuma is banned from character selection • Players must be present when their match is called for, otherwise the missing party will forfeit • Controllers will be provided, no outside controllers will be allowed. • Players must agree on which side they will play (P1 or P2), if an agreement cannot be reached it will be settled with Rock-Paper-Scissors • Stopping the match for any reason beyond a game-breaking glitch or projector error will result in forfeiture of that round. -

Routledge Handbook of Global Sport E-Sports
This article was downloaded by: 10.3.98.104 On: 26 Sep 2021 Access details: subscription number Publisher: Routledge Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: 5 Howick Place, London SW1P 1WG, UK Routledge Handbook of Global Sport John Nauright, Sarah Zipp E-sports Publication details https://www.routledgehandbooks.com/doi/10.4324/9781315714264-36 Jacob Hindin, Matthew Hawzen, Hanhan Xue, Haozhou Pu, Joshua Newman Published online on: 23 Jan 2020 How to cite :- Jacob Hindin, Matthew Hawzen, Hanhan Xue, Haozhou Pu, Joshua Newman. 23 Jan 2020, E-sports from: Routledge Handbook of Global Sport Routledge Accessed on: 26 Sep 2021 https://www.routledgehandbooks.com/doi/10.4324/9781315714264-36 PLEASE SCROLL DOWN FOR DOCUMENT Full terms and conditions of use: https://www.routledgehandbooks.com/legal-notices/terms This Document PDF may be used for research, teaching and private study purposes. Any substantial or systematic reproductions, re-distribution, re-selling, loan or sub-licensing, systematic supply or distribution in any form to anyone is expressly forbidden. The publisher does not give any warranty express or implied or make any representation that the contents will be complete or accurate or up to date. The publisher shall not be liable for an loss, actions, claims, proceedings, demand or costs or damages whatsoever or howsoever caused arising directly or indirectly in connection with or arising out of the use of this material. 35 E-sports Jacob Hindin, Matthew Hawzen, Hanhan Xue, Haozhou Pu and Joshua Newman In recent years, the world has witnessed a phenomenal growth of professional organized video game competitions, known more commonly as ‘e-sports.’1 The letter ‘e’ in e-sports represents ‘electronic,’ which denotes that e-sports is largely dependent on digital and computer-mediated content; ‘sports’ within such nomenclature refers to the gaming form’s organized, immediate, and competitive features.