Petra Galuščáková Information Retrieval and Navigation in Audio
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Text-Based Description of Music for Indexing, Retrieval, and Browsing
JOHANNES KEPLER UNIVERSITAT¨ LINZ JKU Technisch-Naturwissenschaftliche Fakult¨at Text-Based Description of Music for Indexing, Retrieval, and Browsing DISSERTATION zur Erlangung des akademischen Grades Doktor im Doktoratsstudium der Technischen Wissenschaften Eingereicht von: Dipl.-Ing. Peter Knees Angefertigt am: Institut f¨ur Computational Perception Beurteilung: Univ.Prof. Dipl.-Ing. Dr. Gerhard Widmer (Betreuung) Ao.Univ.Prof. Dipl.-Ing. Dr. Andreas Rauber Linz, November 2010 ii Eidesstattliche Erkl¨arung Ich erkl¨are an Eides statt, dass ich die vorliegende Dissertation selbstst¨andig und ohne fremde Hilfe verfasst, andere als die angegebenen Quellen und Hilfsmittel nicht benutzt bzw. die w¨ortlich oder sinngem¨aß entnommenen Stellen als solche kenntlich gemacht habe. iii iv Kurzfassung Ziel der vorliegenden Dissertation ist die Entwicklung automatischer Methoden zur Extraktion von Deskriptoren aus dem Web, die mit Musikst¨ucken assoziiert wer- den k¨onnen. Die so gewonnenen Musikdeskriptoren erlauben die Indizierung um- fassender Musiksammlungen mithilfe vielf¨altiger Bezeichnungen und erm¨oglichen es, Musikst¨ucke auffindbar zu machen und Sammlungen zu explorieren. Die vorgestell- ten Techniken bedienen sich g¨angiger Web-Suchmaschinen um Texte zu finden, die in Beziehung zu den St¨ucken stehen. Aus diesen Texten werden Deskriptoren gewon- nen, die zum Einsatz kommen k¨onnen zur Beschriftung, um die Orientierung innerhalb von Musikinterfaces zu ver- • einfachen (speziell in einem ebenfalls vorgestellten dreidimensionalen Musik- interface), als Indizierungsschlagworte, die in Folge als Features in Retrieval-Systemen f¨ur • Musik dienen, die Abfragen bestehend aus beliebigem, beschreibendem Text verarbeiten k¨onnen, oder als Features in adaptiven Retrieval-Systemen, die versuchen, zielgerichtete • Vorschl¨age basierend auf dem Suchverhalten des Benutzers zu machen. -

TV Formats in Europe
TV Formats in Europe The value created for European broadcasters by the 100 major TV formats was $2,745 million in 2012. The 2012 figure was 5.3% up on the 2011 total, despite the number of hours broadcast increasing by 19.3%. Relative newcomer Money Drop was the top format title by value created in 2012; pushing Come Dine with Me into second place. The TV Formats in Europe report further states that The Voice entered the top 10 in 2012. Who Wants to Be a Millionaire was the top title in both 2009 and 2010, but had dropped to ninth in 2012. Endemol ($711 million – 26% of the total) was the leading distributor by value created in 2012, followed by FremantleMedia ($456 million – 17%). ITV was third, with 10% of the total. So, these three distributors combined took 53% of the total value created. These top three distributors accounted for half of the format hours screened in 2012. ITV Studios (5,425 hours) is the largest distributor by hours, mainly due to Come Dine with Me. FremantleMedia (3,316 hours and supplier of 13 titles in the top 100) and Endemol (4,231 hours and 12 titles) followed. Published in March 2013, this 172-page (23% larger than the previous edition), PDF-delivered report covers 100 major formats (double the number covered in the previous edition) on 84 channels across 16 European territories; with extensive comparison tables. Territory profiles include: Analysis of the formats in that market Overview of the TV market and the main channels Revenue generated by the top 100 formats by channel and country (2009-2012) Total -
100+ Alternative Search Engines You Should Know by Kay Tan
100+ Alternative Search Engines You Should Know By Kay Tan. Filed in Tools Ads by Google Web Site Optimizer Tooloptimizely.com/Web_Optimizer_ToolThe Hottest Web Site Optimizer Tool on the Planet. Test it out! Google is the most powerful search engine available, but when it comes to searching for something specific, Google may churn out general results for some. For instance, a search for a song in Google may return the singer, the lyrics and even fan sites – depending on the keywords you entered. This is when niche-specific search engines comes into the picture. These search engines allows you to search for the things you’re looking for, and because they are more focused, their results tend to be more accurate. E-books & PDF files, audio & music, videos, etc. are probably the most commonly searched items everyday and with this list, you’ll be able to locate them easily from now on. Enjoy! E-Book & PDF Search Engine PDF Searcher Pdf Searcher is a pdf and ebook search engine. You can search and download every ebook or pdf for free! PDFGeni PDFGeni is a dedicated pdf search engine for PDF ebooks, sheets, forms and documents. Data-Sheet Data-Sheet is a pdf ebook datasheet manual search engine where you can search any ebook datasheet pdf files and download. PDFDatabase PDF Database is a new search engine which uses a unique algorithm to search for pdf and doc files from all over the web quickly and efficiently. PDF Search Engine PDF Search Engine is a book search engine search on sites, forums, message boards for pdf files. -

Image and Video Searching on the World Wide Web
Image and Video Searching on the World Wide Web Michael J. Swain Cambridge Research Laboratory Compaq Computer Corporation One Kendall Square, Bldg. 700 Cambridge, MA 02139, USA [email protected] Abstract The proliferation of multimedia on the World Wide Web has led to the introduction of Web search engines for images, video, and audio. On the Web, multimedia is typically embedded within documents that provide a wealth of indexing information. Harsh computational constraints imposed by the economics of advertising-supported searches restrict the complexity of analysis that can be performed at query time. And users may be unwilling to do much more than type a keyword or two to input a query. Therefore, the primary sources of information for indexing multimedia documents are text cues extracted from HTML pages and multimedia document headers. Off-line analysis of the content of multimedia documents can be successfully employed in Web search engines when combined with these other information sources. Content analysis can be used to categorize and summarize multimedia, in addition to providing cues for finding similar documents. This paper was delivered as a keynote address at the Challenge of Image Retrieval ’99. It represents a personal and purposefully selective review of image and video searching on the World Wide Web. 1 Introduction The World Wide Web is full of images, video, and audio, as well as text. Search engines are starting to appear that can allow users to find such multimedia, the quantity of which is growing even faster than text on the Web. As 56 kbps (V.90) modems have become standardized and widely used, and as broadband cable modem and telephone-network based Digital Subscribe Line (DSL) services gain following in the United States and Europe, multimedia on the Web is becoming freed of its major impediment: low-bandwidth consumer Internet connectivity. -

Search Computing Cover.Indd
Search Computing Business Areas, Research and Socio-Economic Challenges Media Search Cluster White Paper European Commission European SocietyInformation and Media LEGAL NOTICE By the Commission of the European Communities, Information Society & Media Directorate-General, Future and Emerging Technologies units. Neither the European Commission nor any person acting on its behalf is responsible for the use which might be made of the information contained in the present publication. The European Commission is not responsible for the external web sites referred to in the present publication. The views expressed in this publication are those of the authors and do not necessarily reflect the official European Commission view on the subject. Luxembourg: Publications Office of the European Union, 2011 ISBN 978-92-79-18514-4 doi:10.2759/52084 © European Union, July 2011 Reproduction is authorised provided the source is acknowledged. © Cover picture: Alinari 24 ORE, Firenze, Italy Printed in Belgium White paper: Search Computing: Business Areas, Research and Socio-Economic Challenges Search Computing: Business Areas, Research and Socio- Economic Challenges Media Search Cluster White Paper Media Search Cluster - 2011 Page 1 White paper: Search Computing: Business Areas, Research and Socio-Economic Challenges Coordinated by the CHORUS+ project co-funded by the European Commission under - 7th Framework Programme (2007-2013) by the –Networked Media and Search Systems Unit of DG INFSO Media Search Cluster - 2011 Page 2 White paper: Search Computing: -

Query by Example of Speaker Audio Signals Using Power Spectrum and Mfccs
Institute of Advanced Engineering and Science Institute of Advanced Engineering and Science International Journal of Electrical and Computer Engineering (IJECE) Vol. 7, No. 6, December 2017, pp. 3369 – 3384 ISSN: 2088-8708 3369 Query by Example of Speaker Audio Signals using Power Spectrum and MFCCs Pafan Doungpaisan1 and Anirach Mingkhwan2 1,2Faculty of Information Technology, King Mongkut’s University of Technology North Bangkok, 1518 Pracharat 1 Road, Wongsawang, Bangsue, Bangkok 10800, Thailand 2Faculty of Industrial Technology and Management, King Mongkut’s University of Technology North Bangkok, 1518 Pracharat 1 Road, Wongsawang, Bangsue, Bangkok 10800, Thailand Article Info ABSTRACT Article history: Search engine is the popular term for an information retrieval (IR) system. Typically, Received: Mar 13, 2017 search engine can be based on full-text indexing. Changing the presentation from the Revised: Aug 9, 2017 text data to multimedia data types make an information retrieval process more complex Accepted: Aug 22, 2017 such as a retrieval of image or sounds in large databases. This paper introduces the use of language and text independent speech as input queries in a large sound database Keyword: by using Speaker identification algorithm. The method consists of 2 main processing Speaker identification first steps, we separate vocal and non-vocal identification after that vocal be used to Acoustic signal processing speaker identification for audio query by speaker voice. For the speaker identification and audio query by process, we estimate the similarity of the example signal and the Content-Based Audio samples in the queried database by calculating the Euclidian distance between the Mel Retrieval frequency cepstral coefficients (MFCC) and Energy spectrum of acoustic features. -
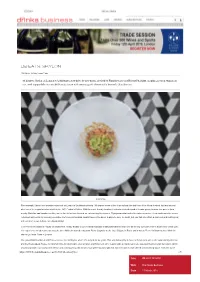
Db Eats: Skylon
3/22/2019 db Eats: Skylon DB EATS: SKYLON 11th March, 2019 by Lauren Eads db heads to Skylon on London’s Southbank to test-drive its new menu, devised by Finnish-born chef Helena Puolakka, gorging on cured salmon on rye, fresh pappardelle in a smoked tomato sauce with creamy goat’s cheese and a heavenly chocolate tart. Steak tartare The concept: Skylon is a riverside restaurant on London’s Southbank offering 180 degree views of the Thames from the first floor of the Royal Festival Hall and named after one of the original structures built for the 1951 Festival of Britain. With its touristfriendly location, it attracts a mixed crowd of theatregoers, tourists that pour in from nearby Waterloo and Londoners alike, but its fare is far from focused on entertaining the masses. Flying somewhat under the radar, a concise, clean and innovative menu, refreshed last month by incoming executive chef Helena Puolakka, awaits those in the know. A place to dine, no doubt, but one that also offers a spacious and buzzing bar, with excellent views to boot, for a liquid pitstop. Chef Helena Puolakka (a regular on Masterchef, Ready Steady Cook (Finland) and BBC’s Saturday Kitchen) took over as its new executive chef in September of last year. Her experience includes time spent at the three Michelinstarred restaurant Pierre Gagnaire at the Hotel Balzac, in Paris, and a stint at Pierre Koffmann’s three Michelin starred La Tante Claire in London. She joined D&D London in 2007 as executive chef at Skylon, where she stayed for six years. -

Web-Scale Multimedia Search for Internet Video Content
CARNEGIE MELLON UNIVERSITY Web-scale Multimedia Search for Internet Video Content Lu Jiang CMU-LTI-17-003 Language and Information Technologies School of Computer Science Carnegie Mellon University 5000 Forbes Avenue, Pittsburgh, PA, 15213 www.lti.cs.cmu.edu Thesis Committee: Dr. Alex Hauptmann, Carnegie Mellon University Dr. Teruko Mitamura, Carnegie Mellon University Dr. Louis-Philippe Morency, Carnegie Mellon University Dr. Tat-Seng Chua, National University of Singapore Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Language and Information Technologies c 2017 Lu Jiang Abstract The Internet has been witnessing an explosion of video content. According to a Cisco study, video content accounted for 64% of all the world’s internet traffic in 2014, and this percentage is estimated to reach 80% by 2019. Video data are becoming one of the most valuable sources to assess information and knowledge. However, existing video search solutions are still based on text matching (text-to-text search), and could fail for the huge volumes of videos that have little relevant metadata or no metadata at all. The need for large-scale and intelligent video search, which bridges the gap between the user’s information need and the video content, seems to be urgent. In this thesis, we propose an accurate, efficient and scalable search method for video content. As opposed to text matching, the proposed method relies on automatic video content understanding, and allows for intelligent and flexible search paradigms over the video content (text-to-video and text&video-to-video search). It provides a new way to look at content-based video search from finding a simple concept like “puppy” to searching a complex incident like “a scene in urban area where people running away after an explosion”. -
IPG Spring 2020 Cooking Titles - January 2020 Page 1
Cooking Titles Spring 2020 {IPG} The Philosophy of Tea Tony Gebely Summary How did drinking the infusions of a unique plant from China become a vital part of everyday life? This gift book presents an entertaining and illuminating introduction to the history and culture of tea, from its origins in the Far East to the flavors and properties of different varieties, and the rituals of tea preparation and drinking around the world. This simple hot beverage is suffused with artistic and religious overtones. The Chinese Ch'a Ching gave very precise guidelines to the preparation and sipping of tea, and the Japanese tea ceremony elevated it to an art form. Following its introduction to the royal court in the 17th century, the British created their own traditions, from the elaborate etiquette of afternoon tea to the humble pot of tea at the heart of family life, and the modern appreciation for specialty infusions. British Library Publishing 9780712352598 Contributor Bio Pub Date: 3/1/20 Tony Gebely is a tea enthusiast and expert. He is the author of Tea: A User's Guide , and the founder of the On Sale Date: 3/1/20 award-winning blog World of Tea. $16.95 USD/£9.99 GBP Discount Code: LON Hardcover 112 Pages Carton Qty: 44 Cooking / Beverages CKB019000 Series: British Library Philosophy of series 8.3 in H | 5 in W | 0.5 in T | 0.5 lb Wt Fizz 80 Joyful Cocktails and Mocktails For Every Occasion Olly Smith Summary Brighten your day with bubbles! 80 seriously simple cocktail recipes for everyone from award-winning wine writer and BBC One drinks expert, Olly Smith. -

Search Computing Cover.Indd
Search Computing Business Areas, Research and Socio-Economic Challenges Media Search Cluster White Paper European Commission European Information Society and Media LEGAL NOTICE By the Commission of the European Communities, Information Society & Media Directorate-General, Future and Emerging Technologies units. Neither the European Commission nor any person acting on its behalf is responsible for the use which might be made of the information contained in the present publication. The European Commission is not responsible for the external web sites referred to in the present publication. The views expressed in this publication are those of the authors and do not necessarily reflect the official European Commission view on the subject. Luxembourg: Publications Office of the European Union, !"## ISBN $%&-$!-%$-#&'#(-( doi:#".!%'$/'!"&( © European Union, July !"## Reproduction is authorised provided the source is acknowledged. © Cover picture: Alinari !( ORE, Firenze, Italy Printed in Belgium !&'2#&..#0S&+#0!&&--+.32',%S&331',#11&50#1Q&7#1#0!&&,"&+-!'-V:!-,-+'!&-&**#,%#1 Search Computing: Business Areas, Research and Socio- Economic Challenges Media Search Cluster White Paper <#"'&+#0!&&-*312#0&V&TRSS& @%#&S& !&'2#&..#0S&+#0!&&--+.32',%S&331',#11&50#1Q&7#1#0!&&,"&+-!'-V:!-,-+'!&-&**#,%#1 Search Computing is a fortuitous term used since 2008 by Prof. Stefano Ceri of the Politecnico di Milano, in the EU – ERC project SeCo which pioneered this domain. Coordinated by the CHORUS+ project co-funded by the European Commission under - 7th Framework Programme (2007-2013) by the –Networked Media and Search Systems Unit of DG INFSO <#"'&+#0!&&-*312#0&V&TRSS& @%#&T& !&'2#&..#0S&+#0!&&--+.32',%S&331',#11&50#1Q&7#1#0!&&,"&+-!'-V:!-,-+'!&-&**#,%#1 Table of Contents 1 Executive Summary .......................................................................................................... -

Team IMEDIA2
Activity Report 2012 Team IMEDIA2 Images et multimédia : indexation, navigation et recherche RESEARCH CENTER Paris - Rocquencourt THEME Vision, Perception and Multimedia Understanding Table of contents 1. Members :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 2. Overall Objectives :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 3. Scientific Foundations :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::2 3.1. Introduction 2 3.2. Modeling, construction and structuring of the feature space2 3.3. Pattern recognition and statistical learning3 4. Application Domains ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::4 4.1. Scientific applications4 4.2. Audio-visual applications4 5. Software ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 6. New Results :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 5 6.1. Feature space modeling5 6.1.1. Spatial relations between salient points on a leaf5 6.1.2. Detection and extraction of leaf parts for plant identification6 6.1.3. Multi-organ plant identification6 6.1.4. Segmentation transfer method for articulated models8 6.2. Feature space structuring8 6.2.1. Plant Leaves Morphological Categorization with Shared Nearest Neighbors Clustering8 6.2.2. Distributed KNN-Graph approximation via Hashing9 6.2.3. Hash-Based Support Vector Machines Approximation for Large Scale Prediction9 6.3. Pattern recognition and statistical learning 10 6.3.1. Machine -

Tbivision.Com August/September 2017
TBI Interview: Amazon: Endemol Shine's originals assessed Perrin on formats Page 4 Page 6 TBIvision.com August/September 2017 pOFC TBI AugSep17.indd 1 21/08/2017 18:15 presents pIFC Go-N TBI AugSep17.indd 1 17/08/2017 11:44 CONTENTS AUGUST/SEPTEMBER 2017 6 4 10 4 Monitor: Amazon Is Amazon’s original programming strategy a recipe for success or disaster? Kaltrina Bylykbashi talks with producers and analysts to find out 6 TBI interview: Lisa Perrin How do you go about overseeing indie format television’s largest catalogue? Endemol Shine Creative Networks chief executive Lisa Perrin reveals the key challenges to Jesse Whittock 16 10 Children’s Media Conference review The UK event revealed the growing impact of kids video-on-demand services from Sky and Virgin Media, plus the latest shopping lists from the established, linear players. Jesse Whittock reports 16 Kids Hot Picks A series dubbed “Total Wipeout meets Power Rangers”, a preschool cartoon featuring an autistic lead and talent, and a TV version of the online Badanamu brand feature in our round up 22 22 Talking drama TBI hears about three quirky scripted series set to hit the international market – including a BBC period medical comedy, an apocalytic Neil Cross drama and an Australian millennials dramedy 28 Content Innovation Awards 2017 preview Television’s hottest ticket is back: we run down the runners and riderds at our annual content-meets- tech awards ceremony as the CIAs turn three Regulars 2 Ed Note • 32 Last Word: Harry Gamsu, Red Arrow 28 For the latest in TV programming news visit TBIVISION.COM TBI August/September 2017 1 p01 Contents TBI AugSep17KBjw.indd 3 21/08/2017 18:19 EDITOR’S NOTE JESSE WHITTOCK t’s all getting a bit confusing, isn’t it? One minute Disney is buying of kids TV in the UK.