38 Multimedia Search Reranking: a Literature Survey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Yong Rui Lenovo Group Dr
Yong Rui Lenovo Group Dr. Yong Rui is currently the Chief Technology Officer and Senior Vice President of Lenovo Group. He is responsible for overseeing Lenovo’s corporate technical strategy, research and development directions, and Lenovo Research organization, which covers intelligent devices, big data analytics, artificial intelligence, cloud computing, 5G and smart lifestyle-related technologies. Before joining Lenovo, Dr. Rui worked for Microsoft for 18 years. His roles included Senior Director and Deputy Managing Director of Microsoft Research Asia (MSRA) (2012-2016), GM of Microsoft Asia-Pacific R&D (ARD) Group (2010-2012), Director of Microsoft Education Product in China (2008-2010), Director of Strategy (2006-2008), and Researcher and Senior Researcher of the Multimedia Collaboration group at Microsoft Research, Redmond, USA (1999-2006). A Fellow of ACM, IEEE, IAPR and SPIE, Dr. Rui is recognized as a leading expert in his fields of research. He is a recipient of many awards, including the 2017 IEEE SMC Society Andrew P. Sage Best Transactions Paper Award, the 2017 ACM TOMM Nicolas Georganas Best Paper Award, the 2016 IEEE Computer Society Technical Achievement Award, the 2016 IEEE Signal Processing Society Best Paper Award and the 2010 Most Cited Paper of the Decade Award from Journal of Visual Communication and Image Representation. He holds 65 US and international issued patents. He has published 4 books, 12 book chapters, and 260 referred journal and conference papers. With over 21,000 citations, and an h-Index of 64, his publications are among the most referenced. Dr. Rui is an Associate Editor of ACM Trans. on Multimedia Computing, Communication and Applications (TOMM), and a founding Editor of International Journal of Multimedia Information Retrieval. -
ACM MM 96 Text ACM MULTIMEDIA 96
ACM MM 96 Text ACM MULTIMEDIA 96 General Information Technical Program Demonstrations Art Program Workshops Tutorials Stephan Fischer Last modified: Fri Nov 29 09:28:01 MET 1996 file:///C|/Documents%20and%20Settings/hsu.cheng-hsin/Desktop/acmmm96/index.htm[1/28/2010 9:42:17 AM] ACM MM 96 ACM MULTIMEDIA 96 The Fourth ACM International Multimedia Conference and Exhibition ADVANCE PROGRAM 18-22 November 1996 Hynes Convention Center Boston, Massachusetts, USA Co-located with SPIE's Symposium on Voice, Video and Data Communication, and Broadband Network Engineering program and overlapping with CSCW, to be held in nearby Cambridge. Welcome to ACM Multimedia '96 Special Events Conference-at-a-Glance Ongoing Events Courses Technical Papers Panels Registration Course Selections Hotels Conference Organization Welcome to ACM Multimedia '96 In what seems in retrospect to have been an astonishingly short time, multimedia has progressed from a technically- challenging curiosity to an essential feature of most computer systems -- both professional and consumer. Accordingly, leading-edge research in multimedia no longer is confined to dealing with processing or information- access bottlenecks, but addresses the ever-broadening ways in which the technology is changing and improving interpersonal communication, professional practice, entertainment, the arts, education, and community life. This year's program emphasizes this trend: off-the-shelf building blocks are now available to construct useful and appealing applications which are highlighted in the Demonstration and Art venues. In addition to the full complement of panels, courses, and workshops, the conference program features a distinguished set of technical papers. Keynotes will be provided by Glenn Hall, the Technical Director of Aardman Animations whose work includes Wallace and Gromit; and Professor Bill Buxton of the University of Toronto and Alias | Wavefront Inc. -

Sense Beauty Via Face, Dressing, And/Or Voice Tam Nguyen University of Dayton, [email protected]
University of Dayton eCommons Computer Science Faculty Publications Department of Computer Science 10-2012 Sense Beauty via Face, Dressing, and/or Voice Tam Nguyen University of Dayton, [email protected] Si Liu National Laboratory of Pattern Recognition Bingbing Ni Advanced Digital Sciences Center Jun Tan National University of Defense Technology Yong Rui Microsoft Research Asia See next page for additional authors Follow this and additional works at: http://ecommons.udayton.edu/cps_fac_pub Part of the Graphics and Human Computer Interfaces Commons, Other Computer Sciences Commons, Personality and Social Contexts Commons, and the Social Psychology Commons eCommons Citation Nguyen, Tam; Liu, Si; Ni, Bingbing; Tan, Jun; Rui, Yong; and Yan, Shuicheng, "Sense Beauty via Face, Dressing, and/or Voice" (2012). Computer Science Faculty Publications. Paper 67. http://ecommons.udayton.edu/cps_fac_pub/67 This Conference Paper is brought to you for free and open access by the Department of Computer Science at eCommons. It has been accepted for inclusion in Computer Science Faculty Publications by an authorized administrator of eCommons. For more information, please contact [email protected], [email protected]. Author(s) Tam Nguyen, Si Liu, Bingbing Ni, Jun Tan, Yong Rui, and Shuicheng Yan This conference paper is available at eCommons: http://ecommons.udayton.edu/cps_fac_pub/67 Sense Beauty via Face, Dressing, and/or Voice Tam V. Nguyen Si Liu Bingbing Ni National University of National Laboratory of Pattern Advanced Digital Sciences Singapore Recognition Center [email protected] [email protected] [email protected] Jun Tan Yo n g R u i Shuicheng Yan National University of Defense Microsoft Research Asia National University of Technology [email protected] Singapore [email protected] [email protected] ABSTRACT Discovering the secret of beauty has been the pursuit of artists and philosophers for centuries. -

Eakta Jain A. Professional Preparation: B. Appointments: C. Publications
Eakta Jain Department of Computer and Information Science and Engineering University of Florida Phone: (352) 562-3979 E-mail: [email protected] Webpage: jainlab.cise.ufl.edu A. Professional Preparation: Indian Institute of Technology Kanpur, India B.Tech. (Electrical Engineering) 2006 Carnegie Mellon University M.S. (Robotics) 2010 Carnegie Mellon University Ph.D. (Robotics) 2012 B. Appointments: 02/14 – present Assistant Professor, Department of Computer and Information Science and Engi- neering, University of Florida, Gainesville, FL 12/12-02/14 Member of Technical Staff, Texas Instruments Embedded Signal Processing Lab, Computer Vision Branch, Dallas, TX 07/12-12/12 Systems Software Engineer, Natural User Interfaces Team, Texas Instruments, Dallas, TX 09/11-01/12 Lab Associate, Disney Research Pittsburgh, PA 06/10-08/10 Lab Associate, Disney Research Pittsburgh, PA 06/08-08/08 Lab Associate, Disney Research Pittsburgh, PA 06/07-08/07 Walt Disney Animation Studios, Burbank, CA C. Publications: Is the Motion of a Child Perceivably Different from the Motion of an Adult? Jain, E., Anthony, L., Aloba, A., Castonguay, A., Cuba, I., Shaw, A. and Woodward, J. (2016). ACM Transactions on Applied Percep- tion (TAP), 13(4), Article 22. DOI: 10.1145/2947616 Decoupling Light Reflex from Pupillary Dilation to Measure Emotional Arousal in Videos, Rai- turkar, P., Kleinsmith, A., Keil, A., Banerjee, A., and Jain, E. (2016), ACM Symposium on Ap- plied Perception (SAP), 89-96. Gaze-driven Video Re-editing, Jain, E., Sheikh, Y., Shamir, A. and Hodgins, J., (2015), ACM Transac- tions on Graphics (TOG) (34, p21:1-p21:12). DOI: 10.1145/2699644 3D Saliency from Eye Tracking with Tomography, Ma, B., Jain, E., and Entezari, A. -

Links (Including Embedded Links) – in General
LINKS (INCLUDING EMBEDDED LINKS) – IN GENERAL Excerpted from Chapter 9 (Unique Intellectual Property Issues in Search Engine Marketing, Optimization and Related Indexing, Information Location Tools and Internet and Social Media Advertising Practices) from the April 2020 updates to E-Commerce and Internet Law: Legal Treatise with Forms 2d Edition A 5-volume legal treatise by Ian C. Ballon (Thomson/West Publishing, www.IanBallon.net) INTERNET, MOBILE AND DIGITAL LAW YEAR IN REVIEW: WHAT YOU NEED TO KNOW FOR 2021 AND BEYOND ASSOCIATION OF CORPORATE COUNSEL JANUARY 14, 2021 Ian C. Ballon Greenberg Traurig, LLP Silicon Valley: Los Angeles: 1900 University Avenue, 5th Fl. 1840 Century Park East, Ste. 1900 East Palo Alto, CA 914303 Los Angeles, CA 90067 Direct Dial: (650) 289-7881 Direct Dial: (310) 586-6575 Direct Fax: (650) 462-7881 Direct Fax: (310) 586-0575 [email protected] <www.ianballon.net> LinkedIn, Twitter, Facebook: IanBallon This paper has been excerpted from E-Commerce and Internet Law: Treatise with Forms 2d Edition (Thomson West April 2020 Annual Update), a 5-volume legal treatise by Ian C. Ballon, published by West, (888) 728-7677 www.ianballon.net Ian C. Ballon Silicon Valley 1900 University Avenue Shareholder 5th Floor Internet, Intellectual Property & Technology Litigation East Palo Alto, CA 94303 T 650.289.7881 Admitted: California, District of Columbia and Maryland F 650.462.7881 Second, Third, Fourth, Fifth, Seventh, Ninth, Eleventh and Federal Circuits Los Angeles U.S. Supreme Court 1840 Century Park East JD, LLM, CIPP/US Suite 1900 Los Angeles, CA 90067 [email protected] T 310.586.6575 LinkedIn, Twitter, Facebook: IanBallon F 310.586.0575 Ian C. -

Searching Personal Photos on the Phone with Instant Visual Query Suggestion and Joint Text-Image Hashing
Searching Personal Photos on the Phone with Instant Visual Query Suggestion and Joint Text-Image Hashing Zhaoyang Zengy, Jianlong Fuz, Hongyang Chaoy, Tao Meiz ySchool of Data and Computer Science, Sun Yat-Sen University, Guangzhou, China zMicrosoft Research, Beijing, China [email protected]; {jianf, tmei}@microsoft.com; [email protected] ABSTRACT The ubiquitous mobile devices have led to the unprecedented grow- ing of personal photo collections on the phone. One significant pain point of today’s mobile users is instantly finding specific pho- tos of what they want. Existing applications (e.g., Google Photo and OneDrive) have predominantly focused on cloud-based solu- tions, while leaving the client-side challenges (e.g., query formula- tion, photo tagging and search, etc.) unsolved. This considerably hinders user experience on the phone. In this paper, we present an innovative personal photo search system on the phone, which en- ables instant and accurate photo search by visual query suggestion and joint text-image hashing. Specifically, the system is character- ized by several distinctive properties: 1) visual query suggestion Figure 1: The procedure of image search with visual query (VQS) to facilitate the formulation of queries in a joint text-image suggestion. User can (1) enter a few characters; (2) browse form, 2) light-weight convolutional and sequential deep neural net- the instantly suggested items; (3) select one suggestion to works to extract representations for both photos and queries, and specify search intent; (4) perform image search based on the 3) joint text-image hashing (with compact binary codes) to facili- new query and the compact hashing technique. -

Department of Computer Science and Engineering
Department of Computer Science and Engineering Journals SJR Title ISSN SJR Quartile Country Molecular Systems Biology ISSN 17444292 8.87 Q1 United Kingdom IEEE Transactions on Pattern Analysis and Machine Intelligence ISSN 01628828 7.653 Q1 United States MIS Quarterly: Management Information Systems ISSN 02767783 6.984 Q1 United States Wiley Interdisciplinary Reviews: Computational Molecular Science ISSN 17590884, 17590876 6.715 Q1 United States Foundations and Trends in Machine Learning ISSN 19358237 6.194 Q1 United States IEEE Transactions on Fuzzy Systems ISSN 10636706 5.8 Q1 United States International Journal of Computer Vision ISSN 09205691 5.633 Q1 Netherlands Journal of Supply Chain Management ISSN 15232409 5.343 Q1 United Kingdom Journal of Operations Management ISSN 02726963 5.052 Q1 Netherlands IEEE Transactions on Smart Grid ISSN 19493053 4.784 Q1 United States Bioinformatics ISSN 13674811, 13674803 4.643 Q1 United Kingdom Information Systems Research ISSN 15265536, 10477047 4.397 Q1 United States IEEE Transactions on Evolutionary Computation ISSN 1089778X 4.308 Q1 United States IEEE Transactions on Automatic Control ISSN 00189286 4.238 Q1 United States International Journal of Robotics Research ISSN 02783649 4.184 Q1 United States Briefings in Bioinformatics ISSN 14774054, 14675463 4.086 Q1 United Kingdom SIAM Journal on Optimization ISSN 10526234, 10957189 3.943 Q1 United States IEEE Transactions on Systems, Man and Cybernetics Part B: Cybernetics ISSN 10834419 3.921 Q1 United States Internet and Higher Education ISSN 10967516 -

Bilateral Correspondence Model for Words-And-Pictures Association in Multimedia-Rich Microblogs
1 Bilateral Correspondence Model for Words-and-Pictures Association in Multimedia-rich Microblogs ZHIYU WANG, Tsinghua University, Department of Computer Science and Technology PENG CUI, Tsinghua University, Department of Computer Science and Technology LEXING XIE, Australian National University and NICTA WENWU ZHU, Tsinghua University, Department of Computer Science and Technology YONG RUI, Microsoft Research Asia SHIQIANG YANG, Tsinghua University, Department of Computer Science and Technology Nowadays, the amount of multimedia contents in microblogs is growing significantly. More than 20% of microblogs link to a picture or video in certain large systems. The rich semantics in microblogs provide an opportunity to endow images with higher- level semantics beyond object labels. However, this arises new challenges for understanding the association between multimodal multimedia contents in multimedia-rich microblogs. Disobeying the fundamental assumptions of traditional annotation, tagging, and retrieval systems, pictures and words in multimedia-rich microblogs are loosely associated and a correspondence between pictures and words cannot be established. To address the aforementioned challenges, we present the first study analyzing and modeling the associations between multimodal contents in microblog streams, aiming to discover multimodal topics from microblogs by establishing correspondences between pictures and words in microblogs. We first use a data-driven approach to analyze the new characteristics of the words, pictures and their association types in microblogs. We then propose a novel generative model, called the Bilateral Correspondence Latent Dirichlet Allocation (BC-LDA) model. Our BC-LDA model can assign flexible associations between pictures and words, and is able to not only allow picture-word co-occurrence with bilateral directions, but also single modal association. -
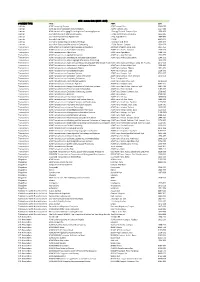
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -
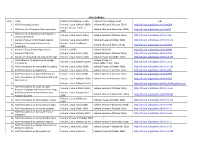
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Web-Scale Responsive Visual Search at Bing
Web-Scale Responsive Visual Search at Bing Houdong Hu, Yan Wang, Linjun Yang, Pavel Komlev, Li Huang, Xi (Stephen) Chen, Jiapei Huang, Ye Wu, Meenaz Merchant, Arun Sacheti Microsoft Redmond, Washington {houhu,wanyan,linjuny,pkomlev,huangli,chnxi,jiaphuan,wuye,meemerc,aruns}@microsoft.com ABSTRACT build a relevant, responsive, and scalable web-scale visual search In this paper, we introduce a web-scale general visual search system engine. To the best of the authors’ knowledge, this is the first work deployed in Microsoft Bing. The system accommodates tens of introducing a general web-scale visual search engine. billions of images in the index, with thousands of features for each Web-scale visual search engine is more than extending existing image, and can respond in less than 200 ms. In order to overcome visual search approaches to a larger database. Here web-scale means the challenges in relevance, latency, and scalability in such large the database is not restricted to a certain vertical or a certain web- scale of data, we employ a cascaded learning-to-rank framework site, but from a spider of a general web search engine. Usually the based on various latest deep learning visual features, and deploy in database contains tens of billions of images, if not more. With this a distributed heterogeneous computing platform. Quantitative and amount of data, the major challenges come from three aspects. First, qualitative experiments show that our system is able to support a lot of approaches that may work on a smaller dataset become im- various applications on Bing website and apps. -

10 Search Engines Suitable for Children
www.medialiteracycouncil.sg 10 Search Engines suitable for Children Even if you have installed internet filters, there is no 100% guarantee that your kids will not be able to access or stumble onto inappropriate content like adult or horror content that may be disturbing for kids. Help is however on hand, in the form of “safe search engines” which help children find relevant information in a safe, kid-friendly setting. These search engines do not display results or images that are inappropriate for children. They are useful tools for children when they need to research on stuff for their school work or simply to explore the internet on their own. Get your kids to use one of these search engines today! 1. Safe Search (www.google.safesearchkids.com) – This search engine was the brainchild of a UK company that is dedicated to providing the best online resources for kids. It uses Google’s SafeSearch technology to filter out offensive content and also removes distracting ads from search results. It is a great site for home and school use. Unlike other Google Safe Search engines for kids, SafeSearch for Kids does not feature picture icons by search results, hence preventing the kids from seeing any inappropriate images unintentionally. SafeSearch for Kids is the child friendly search engine where safe search is always 'on', powered by Google. The safe browsing feature allows your kids to safely surf the web with a much lower risk of accidentally seeing illicit material. 2. Fact Monster (http://www.factmonster.com) – Does your child need help researching an assignment for school? Fact Monster is a free online almanac, dictionary, encyclopedia and thesaurus which will help kids quickly find the information they need.