Stochastic Modeling and Applications Vol. 24 No. 2 (July-December, 2020)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Captain Cool: the MS Dhoni Story
Captain Cool The MS Dhoni Story GULU Ezekiel is one of India’s best known sports writers and authors with nearly forty years of experience in print, TV, radio and internet. He has previously been Sports Editor at Asian Age, NDTV and indya.com and is the author of over a dozen sports books on cricket, the Olympics and table tennis. Gulu has also contributed extensively to sports books published from India, England and Australia and has written for over a hundred publications worldwide since his first article was published in 1980. Based in New Delhi from 1991, in August 2001 Gulu launched GE Features, a features and syndication service which has syndicated columns by Sir Richard Hadlee and Jacques Kallis (cricket) Mahesh Bhupathi (tennis) and Ajit Pal Singh (hockey) among others. He is also a familiar face on TV where he is a guest expert on numerous Indian news channels as well as on foreign channels and radio stations. This is his first book for Westland Limited and is the fourth revised and updated edition of the book first published in September 2008 and follows the third edition released in September 2013. Website: www.guluzekiel.com Twitter: @gulu1959 First Published by Westland Publications Private Limited in 2008 61, 2nd Floor, Silverline Building, Alapakkam Main Road, Maduravoyal, Chennai 600095 Westland and the Westland logo are the trademarks of Westland Publications Private Limited, or its affiliates. Text Copyright © Gulu Ezekiel, 2008 ISBN: 9788193655641 The views and opinions expressed in this work are the author’s own and the facts are as reported by him, and the publisher is in no way liable for the same. -
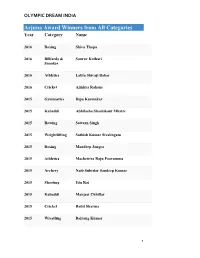
Arjuna Award Winners from All Categories Year Category Name
OLYMPIC DREAM INDIA Arjuna Award Winners from All Categories Year Category Name 2016 Boxing Shiva Thapa 2016 Billiards & Sourav Kothari Snooker 2016 Athletics Lalita Shivaji Babar 2016 Cricket Ajinkya Rahane 2015 Gymnastics Dipa Karmakar 2015 Kabaddi Abhilasha Shashikant Mhatre 2015 Rowing Sawarn Singh 2015 Weightlifting Sathish Kumar Sivalingam 2015 Boxing Mandeep Jangra 2015 Athletics Machettira Raju Poovamma 2015 Archery Naib Subedar Sandeep Kumar 2015 Shooting Jitu Rai 2015 Kabaddi Manjeet Chhillar 2015 Cricket Rohit Sharma 2015 Wrestling Bajrang Kumar 1 OLYMPIC DREAM INDIA 2015 Wrestling Babita Kumari 2015 Wushu Yumnam Sanathoi Devi 2015 Swimming Sharath M. Gayakwad (Paralympic Swimming) 2015 RollerSkating Anup Kumar Yama 2015 Badminton Kidambi Srikanth Nammalwar 2015 Hockey Parattu Raveendran Sreejesh 2014 Weightlifting Renubala Chanu 2014 Archery Abhishek Verma 2014 Athletics Tintu Luka 2014 Cricket Ravichandran Ashwin 2014 Kabaddi Mamta Pujari 2014 Shooting Heena Sidhu 2014 Rowing Saji Thomas 2014 Wrestling Sunil Kumar Rana 2014 Volleyball Tom Joseph 2014 Squash Anaka Alankamony 2014 Basketball Geetu Anna Jose 2 OLYMPIC DREAM INDIA 2014 Badminton Valiyaveetil Diju 2013 Hockey Saba Anjum 2013 Golf Gaganjeet Bhullar 2013 Athletics Ranjith Maheshwari (Athlete) 2013 Cricket Virat Kohli 2013 Archery Chekrovolu Swuro 2013 Badminton Pusarla Venkata Sindhu 2013 Billiards & Rupesh Shah Snooker 2013 Boxing Kavita Chahal 2013 Chess Abhijeet Gupta 2013 Shooting Rajkumari Rathore 2013 Squash Joshna Chinappa 2013 Wrestling Neha Rathi 2013 Wrestling Dharmender Dalal 2013 Athletics Amit Kumar Saroha 2012 Wrestling Narsingh Yadav 2012 Cricket Yuvraj Singh 3 OLYMPIC DREAM INDIA 2012 Swimming Sandeep Sejwal 2012 Billiards & Aditya S. Mehta Snooker 2012 Judo Yashpal Solanki 2012 Boxing Vikas Krishan 2012 Badminton Ashwini Ponnappa 2012 Polo Samir Suhag 2012 Badminton Parupalli Kashyap 2012 Hockey Sardar Singh 2012 Kabaddi Anup Kumar 2012 Wrestling Rajinder Kumar 2012 Wrestling Geeta Phogat 2012 Wushu M. -

Cricket World Cup Begins Mar 8 Schedule on Page-3
www.Asia Times.US NRI Global Edition Email: [email protected] March 2016 Vol 7, Issue 3 Cricket World Cup begins Mar 8 Schedule on page-3 Indian Team: Pakistan Team: Shahid Afridi (c), Anwar Ali, Ahmed Shehzad MS Dhoni (capt, wk), Shikhar Dhawan, Rohit Mohammad Hafeez Bangladesh Team: Sharma, Virat Kohli, Ajinkya Rahane, Yuvraj Shoaib Malik, Mohammad Irfan Squad: Tamim Iqbal, Soumya Sarkar, Moham- Singh, Suresh Raina, R Ashwin, Ravindra Jadeja, Sharjeel Khan, Wahab Riaz mad Mithun, Shakib Al Hasan, Mushfiqur Ra- Mohammed Shami, Harbhajan Singh, Jasprit Mohammad Nawaz, Muhammad Sami him, Sabbir Rahman, Mashrafe Mortaza (capt), Bumrah, Pawan Negi, Ashish Nehra, Hardik Khalid Latif, Mohammad Amir Mahmudullah Riyad, Nasir Hossain, Nurul Pandya. Umar Akmal, Sarfraz Ahmed, Imad Wasim Hasan, Arafat Sunny, Mustafizur Rahman, Al- Amin Hossain, Taskin Ahmed and Abu Hider. Australia Team: Steven Smith (c), David Warner (vc), Ashton Agar, Nathan Coulter-Nile, James Faulkner, Aaron Finch, John Hastings, Josh Hazlewood, Usman Khawaja, Mitchell Marsh, Glenn Max- well, Peter Nevill (wk), Andrew Tye, Shane Watson, Adam Zampa England: Eoin Morgan (c), Alex Hales, Ja- Asia Times is Globalizing son Roy, Joe Root, Jos Buttler, James Vince, Ben Now appointing Stokes, Moeen Ali, Chris Jordan, Adil Rashid, David Willey, Steven Finn, Reece Topley, Sam Bureau Chiefs to represent Billings, Liam Dawson New Zealand Team: Asia Times in ALL cities Kane Williamson (c), Corey Anderson, Trent Worldwide Boult, Grant Elliott, Martin Guptill, Mitchell McClenaghan, -

Subjects Summative Assessment-III
C - 16 Vikram Lotus SUMMATIVE ASSESSMENT - III Term Book Syllabus : Class - III :: Vikram Lotus English Term 3 (Lesson 1 - 4) 50 1 Page No. 3 - 28 Time : 2 /2 Hours Max.Marks: 50 Name : Class : Section : Roll No. Listening and Speaking I. Have you heard a match commentary ? Listen to the match commentary which your teacher will read out. Then answer the questions. [5 × 1 = 5M] It's the second ball of the final over in the match between India and South Africa. Ashish Nehra is bowling to Robin Peterson. It's a six!!! Nehra bowls a length ball and Peterson slogs it over deep mid-wicket. Nehra bowls to Peterson again. It's the third ball. Peterson comes down the track and edges the ball to the right of Dhoni. Tendulkar starts chasing the ball and throws a direct hit at the stumps. However, Peterson is not out. The fourth ball of the over and it's boundary!!! Nehra bowls a fuller delivery outside the off stump and Peterson drives it through the covers. Peterson is a last over hero for South Africa. He yells out in joy and pumps his fist in the air. 1) Which teams are playing the game ? 2) Which team wins the match ? 3) What was the run scored in the last ball ? 4) Who was bowling to whom in the last ball ? 5) What does the batsman do when the game was over ? II. Talk about the dishes you love the most. [5M] Tell your partner who prepares the food at home. Do you help in cooking? What ingredients are required to make your favourite dish ? Does everyone in your family enjoy it too ? Reading I. -

This Is Disturbing: Andre Russell on Picture of Cop Pointing Rubber- Bullet Gun at a Child During US Protests
6/2/2020 This is disturbing: Andre Russell on picture of cops pointing rubber-bullet gun at a child during US protests | Sports News This is disturbing: Andre Russell on picture of cop pointing rubber- bullet gun at a child during US protests Others TN Sports Desk Updated Jun 02, 2020 | 19:09 IST West Indies all-rounder Andre Russell shared a picture of a cop pointing a rubber-bullet gun at a child during the ongoing protests over George Floyd's death in the United States. KEY HIGHLIGHTS Andre Russell on Tuesday shared a picture of a cop in the United States pointing a rubber- bullet gun at a child Andre Russell said he was disturbed by the picture which is from the ongoing protests in the US over George Floyd's death Several cricketers and footballers have joined the 'Black lives matter' campaign on social media Andre Russell said he was disturbed by the viral photo. | @ar12russell | | Photo Credit: Instagram West Indies all-rounder Andre Russell on Tuesday took to social media to share a picture of a cop in the United States pointing a rubber-bullet gun at a child during the ongoing protests over George Floyd's death. The forty-six-year-old died in Minneapolis, Minnesota on May 25 aer a police officer kneeled on his neck for over eight minutes. The tragic passing away of Floyd has sparked massive outrage across the United States as people are protesting over his death. At least 4 police officers have been suspended by the authorities and people are demanding that all four should be charged for murder. -

Page10sportfgs.Qxd (Page 1)
MONDAY, MAY 3, 2021 (PAGE 10) DAILY EXCELSIOR, JAMMU Buttler blitzkrieg powers Royals Webinar on 'Teaching of Guru Tegh Bahadur' organised to 55-run victory over SRH Excelsior Correspondent temporary times when the world is NEW DELHI, May 2: Chris Morris (3/29) and ous Jonny Bairstow (30) and Vijay grappling with the pandemic as Mustafizur Rahman (3/20) did the Shankar (8) soon followed. JAMMU, May 2: Department they fortify our faith in human Jos Buttler announced his bulk of the work with the ball With the pressure mounting, of Dean Students Welfare of nature and their problems. return to form with belligerent while Kartik Tyagi (1/32) Rahul skipper Kane Williamson (20) Cluster University of Jammu today The programme commenced maiden T20 hundred as Rajasthan Twetia (1/45) picked a wicket went for the big shot only to be organised webinar on the life and with a prayer video imploring for Royals made a mincemeat of an apiece. caught at deep midwicket by teachings of Guru Tegh Bahadur, hope and cure of millions of fellow out-of-sorts Sun Risers Hyderabad, With the win, the Royals Morris off Tyagi as wickets tum- the 9th Guru of Sikh community. Indians falling prey to the deadly winning Sunday's IPL encounter moved up to fifth spot while SRH bled at regular intervals. The webinar was organised as pandemic, followed by a one by a whopping 55-run margin. continued to stay at the bottom, Mohammad Nabi (17 off 5) part of Azaadi Ka Amrut Mahotsav. minute silence to pay homage to all Opening the innings, Buttler having won only one match all sea- injected some hope in the SRH The objective of the lecture was to the departed souls who fell victim smashed a breathtaking 124 off 64 son. -

P14 5 Layout 1
14 Established 1961 Sports Tuesday, March 27, 2018 Australian cricket faces huge backlash over ball-tampering Cricket Australia chief Sutherland rushing to S Africa SYDNEY: Sutherland was rushing to South Africa yes- Monday. “We know Australians want answers and we terday with the sport facing one of the toughest weeks will keep you updated on our findings and next steps, as in its history as a backlash grows over a ball-tampering a matter of urgency.” Smith and all members of the team scandal which is likely to cost Steve Smith the Test cap- will remain in South Africa to assist in the probe to taincy. Sponsors expressed “deep concern” as media determine exactly what happened, and who knew. and fans called for wide- Smith, whose talents with the spread changes and deci- bat have drawn breathless sive action following the comparisons with Aussie great shock admission that Smith Don Bradman, is not the only and senior team members man caught in the crosshairs. plotted to cheat in South Sponsors David Warner also stood Africa. Smith, 28, was down from his role as vice- removed from the captain- expressed captain, while questions remain cy for the remainder of the over coach Darren Lehmann third Test against South ‘deep concern’ although Smith said the former Africa on Sunday and was Australian international was not then banned for one match involved in the conspiracy. by the International Cricket Smith initially said the deci- Council (ICC). sion was made by the leader- His team’s weekend of ship group within the team, but shame then ended in a crushing 322-run rout. -

Sarwan: WICB Nails Canards
Friday 22nd April 2011 13 The West Indies Cricket Board issued him the necessary No Objection Certificate (NOC), but issued a media release critical of Gayle’s choice. Gayle said the dispute Sophia Vergara predates the World Cup, claiming he was She has the looks and the curvaceous threatened with body that could kill, and he is one of the exclusion from most famous faces in the world. the tournament So it is no wonder that Pepsi chose for asking Modern Family star Sophia Vergara and whether the Beckham and footballer David Beckham, 35, to team up tournament and star in their latest advertising cam- contract was swimsuit-clad paign. approved by In the 30-second advertisement, the 38- the West year-old old Colombian suns herself in a Indies Vergara debut low-cut electric one-piece swimsuit. Players’ She spots a young girl sipping a can of Association. their first ever Pepsi and immediately craves the soft “I got a drink. reply, copied to Pepsi commercial Getting a glimpse of the long line at the refreshment booth, she takes to Twitter to craftily dupe the crowd. Dangerous curves In the 31 second advertisement, the 38- Gayle claims forced year-old old Colombian suns herself in a low-cut electric one-piece swimsuit Immediately beach-goers hurtle away from the drink stand in a bid to find the famous footballer, making way for the stun- ning brunette to purchase her much need- to skip Pakistan series ed refreshment. Getting up from her lounge, she gives viewers a glimpse of her stunning behind CASTRIES (St. -

SPORTS 2424 Saturday, February 18, 2017
Mourinho upbraids P23 unfocused Man United SPORTS 2424 Saturday, February 18, 2017 Sri Lanka beat Australia off last ball to win first T20 Melbourne bowler Andrew Tye’s final delivery through Finch shared in an opening stand of 76 hamara Kapugedera smashed the covers to the boundary rope for the with T20I debutant Michael Klinger. a four off the last ball to give winning hit. Klinger, making his debut at the age of 36 CSri Lanka a thrilling five-wicket The win put Sri Lanka one up in the series after starring with the Perth Scorchers in the victory over Australia in their with two matches to play in Geelong on domestic Big Bash League, hammered 38 off first Twenty20 international at Sunday and Adelaide on Wednesday. 32 balls with four boundaries. the Melbourne Cricket Ground For a time it looked as though the Lasith Malinga, who has played virtually yesterday Australians, playing without their leading no cricket for nearly a year due to injuries, The win kept Sri Lanka stars, Steve Smith, David Warner, Mitchell was an influential figure taking two wickets unbeaten in four T20 Starc and Josh Hazlewood all on tour in in two balls and taking two catches. internationals in Australia India, would hold off the fast-finishing Sri Malinga claimed the wickets of Travis and followed their 2-1 series Lankans. Head for 31 off 24 balls and debutant Ashton win over South Africa last The home side posted a competitive total Turner for 18 off 13 balls, both caught by month. of 168 for six off their 20 overs with skipper Seekkugge Prasanna at deep mid-wicket. -

Primo.Qxd (Page 1)
FRIDAY, APRIL 10, 2015 (PAGE 14) DAILY EXCELSIOR, JAMMU Kings XI Punjab face JU’s Inter-Department Tournaments 2015 CSK beat Delhi Daredevils Rajasthan Royals today Department of Physical Education at new home ground by 1-run in IPL thriller PUNE, Apr 9: dominates in Badminton Excelsior Sports Correspondent Mathematics Department by 2- CHENNAI, Apr 9: per Mahendra Singh Dhoni space of four balls in the third Kings XI Punjab would look 0; The Business School (MBA) (30). over to reduce Delhi to 20 for to adapt quickly to their new Pacer Ashish Nehra JAMMU, Apr 9: Department trounced Deptt. of Phy. Defending the total, two. 'home ground' when they lock snapped up three wickets to of Physical Education dominat- Education by 2-1; Commerce Ashish Nehra produced a Nehra, who will turn 36 on horns with former champions lead a disciplined bowling ed in Badminton on day-2 of the Deptt. beat Law Deptt. by 2-1. fiery spell of fast bowling, April 29, then came back to Rajasthan Royals in their cam- Inter-Department Tournaments CARROM (Men): The snap up another wicket, get- paign opener in the Indian in the disciplines of Table Department of Law defeated ting rid of Shreyas Iyer (7) Premier League (IPL) here tomor- Winners posing along with dignitaries at DPL Rajouri on Tennis, Badminton, Chess, The Business School by 2-0 and with Faf du Plessis taking a row. Thursday. Carrom and Volleyball, being in Carrom (Women), Deptt. of brilliant catch. The Royals, who have three played in Gymnasium Hall at Law beat Department of Morkel and Kedar Jadhav 2015 World Cup winners in University of Jammu, here. -

Greek Game Abandoned Due to Fan, Police Clashes by DEMETRIS NELLAS
Tuesday 20th March, 2012 15 Greek game abandoned due to fan, police clashes BY DEMETRIS NELLAS ATHENS, Greece (AP) — The Greek league game between leader Olympiakos and Panathinaikos was abandoned with eight minutes to go on Sunday because of escalating clashes between fans and the police. Police announced that 57 people had been detained and a further 20 arrested, while nine police officers were injured, two of them seriously. “We dedicated several thousand per- sonnel to policing the game and we faced, beginning two hours before the game started, escalating attacks,” police Riot police officers are attacked with fire spokesman Athanassios Kokalakis said. bombs,thrown by Panathinaikos’ fans during a Olympiakos, four points ahead of soccer match in the Greek Super League at the Panathinaikos before the game, was lead- Olympic stadium in Athens, Sunday, March 18 ing 1-0 from Djamel Abdoun’s 51st- 2012. The Greek league game between leader minute goal. No Olympiakos fans attended the Olympiakos and Panathinaikos was abandoned game at Olympic Stadium in accordance with eight minutes to go because of escalating with a league policy not to allow visiting clashes between fans and the police. fans due to fears of violence. (AP Photo/Kostas Tsironis) Sports general secretary Panos Bitsaxis said on television that the state had taken “the best possible security measures” and accused football clubs of doing nothing to curb the fanatical sup- porters and of opposing the state’s attempts to impose tougher sanctions. Bitsaxis left open the option of postpon- ing the next round. According to league rules, Panathinaikos is facing having three points deducted and a steep fine, up to 180,000, and could play several games in front of empty stands. -

THE WINNING STRATEGY in T20 CRICKET Winning Strategy in T20 Cricket
THE WINNING STRATEGY IN T20 CRICKET Winning Strategy in T20 Cricket Table of Contents 1.0 Abbreviation 2.0 Introduction 3.0 Batting Strategies 4.0 Bowling Strategies 5.0 Fielding Strategies 6.0 Captaincy Picks 7.0 Conclusion Winning Strategy in T20 Cricket 1.0 ABBREVIATION Avg Average BPB Balls Per Boundary Death-Overs Overs 16-20 of an innings Econ Economy Inns Innings Middle-Overs Overs 7-15 of an innings Powerplay First 6 overs of an innings Wkts Wickets Winning Strategy in T20 Cricket 2.0 Introduction Twenty20 (T20) cricket is a format that was started in England in 2003 as an inter-county championship. Over the past seventeen years this format has grown leaps and bounds and is very keenly watched by all stakeholders involved with the game. The popularity and the growth of T20 has led to cricket boards taking this format with uttermost seriousness and every major cricket playing nation has its own international team and domestic league. Over the past seventeen years the strategies involved in succeeding in this format have also evolved and teams at the international, franchise and domestic level are trying to evolve their playbook to gain a comparative advantage. Seventeen years since T20 cricket started, preparation for matches globally have changed from casual chats in team meetings. For coaches and captains, dossiers of 25 pages are common; these dissect the opponent's strengths and weaknesses, suggest set-plays, which are the optimum ways that a bowler can set up a batsman, and explain the best parts of the ground to target and which end might suit each bowler best This research paper will delve into a potential winning strategy for a T20 side.