Concurrency-Control.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Failures in DBMS
Chapter 11 Database Recovery 1 Failures in DBMS Two common kinds of failures StSystem filfailure (t)(e.g. power outage) ‒ affects all transactions currently in progress but does not physically damage the data (soft crash) Media failures (e.g. Head crash on the disk) ‒ damagg()e to the database (hard crash) ‒ need backup data Recoveryyp scheme responsible for handling failures and restoring database to consistent state 2 Recovery Recovering the database itself Recovery algorithm has two parts ‒ Actions taken during normal operation to ensure system can recover from failure (e.g., backup, log file) ‒ Actions taken after a failure to restore database to consistent state We will discuss (briefly) ‒ Transactions/Transaction recovery ‒ System Recovery 3 Transactions A database is updated by processing transactions that result in changes to one or more records. A user’s program may carry out many operations on the data retrieved from the database, but the DBMS is only concerned with data read/written from/to the database. The DBMS’s abstract view of a user program is a sequence of transactions (reads and writes). To understand database recovery, we must first understand the concept of transaction integrity. 4 Transactions A transaction is considered a logical unit of work ‒ START Statement: BEGIN TRANSACTION ‒ END Statement: COMMIT ‒ Execution errors: ROLLBACK Assume we want to transfer $100 from one bank (A) account to another (B): UPDATE Account_A SET Balance= Balance -100; UPDATE Account_B SET Balance= Balance +100; We want these two operations to appear as a single atomic action 5 Transactions We want these two operations to appear as a single atomic action ‒ To avoid inconsistent states of the database in-between the two updates ‒ And obviously we cannot allow the first UPDATE to be executed and the second not or vice versa. -

ACID Compliant Distributed Key-Value Store
ACID Compliant Distributed Key-Value Store #1 #2 #3 Lakshmi Narasimhan Seshan , Rajesh Jalisatgi , Vijaeendra Simha G A # 1l [email protected] # 2r [email protected] #3v [email protected] Abstract thought that would be easier to implement. All Built a fault-tolerant and strongly-consistent key/value storage components run http and grpc endpoints. Http endpoints service using the existing RAFT implementation. Add ACID are for debugging/configuration. Grpc Endpoints are transaction capability to the service using a 2PC variant. Build used for communication between components. on the raftexample[1] (available as part of etcd) to add atomic Replica Manager (RM): RM is the service discovery transactions. This supports sharding of keys and concurrent transactions on sharded KV Store. By Implementing a part of the system. RM is initiated with each of the transactional distributed KV store, we gain working knowledge Replica Servers available in the system. Users have to of different protocols and complexities to make it work together. instantiate the RM with the number of shards that the user wants the key to be split into. Currently we cannot Keywords— ACID, Key-Value, 2PC, sharding, 2PL Transaction dynamically change while RM is running. New Replica Servers cannot be added or removed from once RM is I. INTRODUCTION up and running. However Replica Servers can go down Distributed KV stores have become a norm with the and come back and RM can detect this. Each Shard advent of microservices architecture and the NoSql Leader updates the information to RM, while the DTM revolution. Initially KV Store discarded ACID properties leader updates its information to the RM. -

Lecture 15: March 28 15.1 Overview 15.2 Transactions
CMPSCI 677 Distributed and Operating Systems Spring 2019 Lecture 15: March 28 Lecturer: Prashant Shenoy 15.1 Overview This section covers the following topics: Distributed Transactions: ACID Properties, Concurrency Control, Serializability, Two-Phase Locking 15.2 Transactions Transactions are used widely in databases as they provide atomicity (all or nothing property). Atomicity is the property in which operations inside a transaction all execute successfully or none of the operations execute. Thus, if a process crashes during a transaction, all operations that happened during that transaction must be undone. Transactions are usually implemented using locks. Without locks there would be interleaving of operations from two transactions, causing overwrites and inconsistencies. It has to look like all instructions/operations of one transaction are executed at once, while ensuring other external instructions/operations are not executing at the same time. This is especially important in real-world applications such as banking applications. 15.2.1 ACID: Most transaction systems will provide the following properties • Atomicity: All or nothing (all instructions execute or none; cannot have some instructions execute and some do not) • Consistency: Transaction takes system from one consistent (valid) state to another • Isolated: Transaction executes as if it is the only transaction in the system. Ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed sequentially (serializability). -

Distributed Transactions
Distributed Systems 600.437 Distributed Transactions Department of Computer Science The Johns Hopkins University Yair Amir Fall 16/ Lecture 6 1 Distributed Transactions Lecture 6 Further reading: Concurrency Control and Recovery in Database Systems P. A. Bernstein, V. Hadzilacos, and N. Goodman, Addison Wesley. 1987. Transaction Processing: Concepts and Techniques Jim Gray & Andreas Reuter, Morgan Kaufmann Publishers, 1993. Yair Amir Fall 16/ Lecture 6 2 Transaction Processing System Clients Messages to TPS outside world Real actions (firing a missile) Database Yair Amir Fall 16/ Lecture 6 3 Basic Definition Transaction - a collection of operations on the physical and abstract application state, with the following properties: • Atomicity. • Consistency. • Isolation. • Durability. The ACID properties of a transaction. Yair Amir Fall 16/ Lecture 6 4 Atomicity Changes to the state are atomic: - A jump from the initial state to the result state without any observable intermediate state. - All or nothing ( Commit / Abort ) semantics. - Changes include: - Database changes. - Messages to outside world. - Actions on transducers. (testable / untestable) Yair Amir Fall 16/ Lecture 6 5 Consistency - The transaction is a correct transformation of the state. This means that the transaction is a correct program. Yair Amir Fall 16/ Lecture 6 6 Isolation Even though transactions execute concurrently, it appears to the outside observer as if they execute in some serial order. Isolation is required to guarantee consistent input, which is needed for a consistent program to provide consistent output. Yair Amir Fall 16/ Lecture 6 7 Durability - Once a transaction completes successfully (commits), its changes to the state survive failures (what is the failure model ? ). -

Concurrency Control
Concurrency Control Instructor: Matei Zaharia cs245.stanford.edu Outline What makes a schedule serializable? Conflict serializability Precedence graphs Enforcing serializability via 2-phase locking » Shared and exclusive locks » Lock tables and multi-level locking Optimistic concurrency with validation Concurrency control + recovery CS 245 2 Lock Modes Beyond S/X Examples: (1) increment lock (2) update lock CS 245 3 Example 1: Increment Lock Atomic addition action: INi(A) {Read(A); A ¬ A+k; Write(A)} INi(A), INj(A) do not conflict, because addition is commutative! CS 245 4 Compatibility Matrix compat S X I S T F F X F F F I F F T CS 245 5 Update Locks A common deadlock problem with upgrades: T1 T2 l-S1(A) l-S2(A) l-X1(A) l-X2(A) --- Deadlock --- CS 245 6 Solution If Ti wants to read A and knows it may later want to write A, it requests an update lock (not shared lock) CS 245 7 Compatibility Matrix New request compat S X U S T F Lock already X F F held in U CS 245 8 Compatibility Matrix New request compat S X U S T F T Lock already X F F F held in U F F F Note: asymmetric table! CS 245 9 How Is Locking Implemented In Practice? Every system is different (e.g., may not even provide conflict serializable schedules) But here is one (simplified) way ... CS 245 10 Sample Locking System 1. Don’t ask transactions to request/release locks: just get the weakest lock for each action they perform 2. -

Sundial: Harmonizing Concurrency Control and Caching in a Distributed OLTP Database Management System
Sundial: Harmonizing Concurrency Control and Caching in a Distributed OLTP Database Management System Xiangyao Yu, Yu Xia, Andrew Pavlo♠ Daniel Sanchez, Larry Rudolph|, Srinivas Devadas Massachusetts Institute of Technology, ♠Carnegie Mellon University, |Two Sigma Investments, LP [email protected], [email protected], [email protected] [email protected], [email protected], [email protected] ABSTRACT and foremost, long network delays lead to long execution time of Distributed transactions suffer from poor performance due to two distributed transactions, making them slower than single-partition major limiting factors. First, distributed transactions suffer from transactions. Second, long execution time increases the likelihood high latency because each of their accesses to remote data incurs a of contention among transactions, leading to more aborts and per- long network delay. Second, this high latency increases the likeli- formance degradation. hood of contention among distributed transactions, leading to high Recent work on improving distributed concurrency control has abort rates and low performance. focused on protocol-level and hardware-level improvements. Im- We present Sundial, an in-memory distributed optimistic concur- proved protocols can reduce synchronization overhead among trans- rency control protocol that addresses these two limitations. First, to actions [22, 35, 36, 46], but can still limit performance due to high reduce the transaction abort rate, Sundial dynamically determines coordination overhead (e.g., lock blocking). Hardware-level im- the logical order among transactions at runtime, based on their data provements include using special hardware like optimized networks access patterns. Sundial achieves this by applying logical leases to that enable low-latency remote memory accesses [20, 48, 55], which each data element, which allows the database to dynamically calcu- can increase the overall cost of the system. -

A Study of the Availability and Serializability in a Distributed Database System
A STUDY OF THE AVAILABILITY AND SERIALIZABILITY IN A DISTRIBUTED DATABASE SYSTEM David Wai-Lok Cheung B.Sc., Chinese University of Hong Kong, 1971 M.Sc., Simon Fraser University, 1985 A THESIS SUBMI'ITED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHLLOSOPHY , in the School of Computing Science 0 David Wai-Lok Cheung 1988 SIMON FRASER UNIVERSITY January 1988 All rights reserved. This thesis may not be reproduced in whole or in part, by photocopy or other means, without permission of the author. 1 APPROVAL Name: David Wai-Lok Cheung Degree: Doctor of Philosophy Title of Thesis: A Study of the Availability and Serializability in a Distributed Database System Examining Committee: Chairperson: Dr. Binay Bhattacharya Senior Supervisor: Dr. TikoJameda WJ ru p v Dr. Arthur Lee Liestman Dr. Wo-Shun Luk Dr. Jia-Wei Han External Examiner: Toshihide Ibaraki Department of Applied Mathematics and Physics Kyoto University, Japan Bate Approved: January 15, 1988 PARTIAL COPYRIGHT LICENSE I hereby grant to Simon Fraser University the right to lend my thesis, project or extended essay (the title of which is shown below) to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response to a request from the library of any other university, or other educational institution, on its own behalf or for one of its users. I further agree that permission for multiple copying of this work for scholarly purposes may be granted by me or the Dean of Graduate Studies. It is understood that copying or publication of this work for financial gain shall not be allowed without my written permission, T it l e of Thes i s/Project/Extended Essay Author: (signature) ( name (date) ABSTRACT Replication of data objects enhances the reliability and availability of a distributed database system. -

An Alternative Model to Overcoming Two Phase Commit Blocking Problem
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by International Journal of Computer (IJC - Global Society of Scientific Research and... International Journal of Computer (IJC) ISSN 2307-4523 (Print & Online) © Global Society of Scientific Research and Researchers http://ijcjournal.org/ An Alternative Model to Overcoming Two Phase Commit Blocking Problem Hassan Jafar Sheikh Salaha*, Dr. Richard M. Rimirub , Dr. Michael W. Kimwelec a,b,cComputer Science, Jomo Kenyatta University of Agriculture and Technology Kenya aEmail: [email protected] bEmail: [email protected] cEmail: [email protected] Abstract In distributed transactions, the atomicity requirement of the atomic commitment protocol should be preserved. The two phased commit protocol algorithm is widely used to ensure that transactions in distributed environment are atomic. However, a main drawback was attributed to the algorithm, which is a blocking problem. The system will get in stuck when participating sites or the coordinator itself crashes. To address this problem a number of algorithms related to 2PC protocol were proposed such as back up coordinator and a technique whereby the algorithm passes through 3PC during failure. However, both algorithms face limitations such as multiple site and backup coordinator failures. Therefore, we proposed an alternative model to overcoming the blocking problem in combined form. The algorithm was simulated using Britonix transaction manager (BTM) using Eclipse IDE and MYSQL. In this paper, we assessed the performance of the alternative model and found that this algorithm handled site and coordinator failures in distributed transactions using hybridization (combination of two algorithms) with minimal communication messages. -

Transaction Management in the R* Distributed Database Management System
Transaction Management in the R* Distributed Database Management System C. MOHAN, B. LINDSAY, and R. OBERMARCK IBM Almaden Research Center This paper deals with the transaction management aspects of the R* distributed database system. It concentrates primarily on the description of the R* commit protocols, Presumed Abort (PA) and Presumed Commit (PC). PA and PC are extensions of the well-known, two-phase (2P) commit protocol. PA is optimized for read-only transactions and a class of multisite update transactions, and PC is optimized for other classes of multisite update transactions. The optimizations result in reduced intersite message traffic and log writes, and, consequently, a better response time. The paper also discusses R*‘s approach toward distributed deadlock detection and resolution. Categories and Subject Descriptors: C.2.4 [Computer-Communication Networks]: Distributed Systems-distributed datahes; D.4.1 [Operating Systems]: Process Management-concurrency; deadlocks, syndvonization; D.4.7 [Operating Systems]: Organization and Design-distributed sys- tems; D.4.5 [Operating Systems]: Reliability--fault tolerance; H.2.0 [Database Management]: General-concurrency control; H.2.2 [Database Management]: ‘Physical Design-recouery and restart; H.2.4 [Database Management]: Systems-ditributed systems; transactionprocessing; H.2.7 [Database Management]: Database Administration-logging and recouery General Terms: Algorithms, Design, Reliability Additional Key Words and Phrases: Commit protocols, deadlock victim selection 1. INTRODUCTION R* is an experimental, distributed database management system (DDBMS) developed and operational at the IBM San Jose Research Laboratory (now renamed the IBM Almaden Research Center) 118, 201. In a distributed database system, the actions of a transaction (an atomic unit of consistency and recovery [13]) may occur at more than one site. -
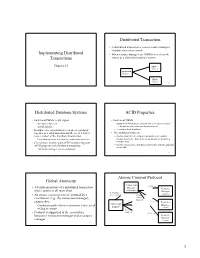
Implementing Distributed Transactions Distributed Transaction Distributed Database Systems ACID Properties Global Atomicity Atom
Distributed Transaction • A distributed transaction accesses resource managers distributed across a network Implementing Distributed • When resource managers are DBMSs we refer to the Transactions system as a distributed database system Chapter 24 DBMS at Site 1 Application Program DBMS 1 at Site 2 2 Distributed Database Systems ACID Properties • Each local DBMS might export • Each local DBMS – stored procedures, or – supports ACID properties locally for each subtransaction – an SQL interface. • Just like any other transaction that executes there • In either case, operations at each site are grouped – eliminates local deadlocks together as a subtransaction and the site is referred • The additional issues are: to as a cohort of the distributed transaction – Global atomicity: all cohorts must abort or all commit – Each subtransaction is treated as a transaction at its site – Global deadlocks: there must be no deadlocks involving • Coordinator module (part of TP monitor) supports multiple sites ACID properties of distributed transaction – Global serialization: distributed transaction must be globally serializable – Transaction manager acts as coordinator 3 4 Atomic Commit Protocol Global Atomicity Transaction (3) xa_reg • All subtransactions of a distributed transaction Manager Resource must commit or all must abort (coordinator) Manager (1) tx_begin (cohort) • An atomic commit protocol, initiated by a (4) tx_commit (5) atomic coordinator (e.g., the transaction manager), commit protocol ensures this. (3) xa_reg Resource Application – Coordinator -

Distributed Transaction Processing: Reference Model, Version 3
Guide Distributed Transaction Processing: Reference Model, Version 3 HNICA C L E G T U I D E S [This page intentionally left blank] X/Open Guide Distributed Transaction Processing: Reference Model, Version 3 X/Open Company Ltd. February 1996, X/Open Company Limited All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owners. X/Open Guide Distributed Transaction Processing: Reference Model, Version 3 ISBN: 1-85912-170-5 X/Open Document Number: G504 Published by X/Open Company Ltd., U.K. Any comments relating to the material contained in this document may be submitted to X/Open at: X/Open Company Limited Apex Plaza Forbury Road Reading Berkshire, RG1 1AX United Kingdom or by Electronic Mail to: [email protected] ii X/Open Guide Contents Chapter 1 Introduction............................................................................................... 1 1.1 Overview ...................................................................................................... 1 1.2 Benefits of X/Open DTP ........................................................................... 1 1.3 Areas Not Addressed................................................................................. 2 1.4 Relationship to International Standards................................................ 2 Chapter 2 Definitions................................................................................................. -
Concurrency Control and Recovery ACID • Transactions • Recovery Transaction Model Concurency Control Recovery
Data Management Systems • Transaction Processing • Concurrency control and recovery ACID • Transactions • Recovery Transaction model Concurency Control Recovery Gustavo Alonso Institute of Computing Platforms Department of Computer Science ETH Zürich Transactions-CC&R 1 A bit of theory • Before discussing implementations, we will cover the theoretical underpinning behind concurrency control and recovery • Discussion at an abstract level, without relation to implementations • No consideration of how the concepts map to real elements (tuples, pages, blocks, buffers, etc.) • Theoretical background important to understand variations in implementations and what is considered to be correct • Theoretical background also key to understand how system have evolved over the years Transactions-CC&R 2 Reference Concurrency Control and Recovery in Database Systems Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman • https://www.microsoft.com/en- us/research/people/philbe/book/ Transactions-CC&R 3 ACID Transactions-CC&R 4 Conventional notion of database correctness • ACID: • Atomicity: the notion that an operation or a group of operations must take place in their entirety or not at all • Consistency: operations should take the database from a correct state to another correct state • Isolation: concurrent execution of operations should yield results that are predictable and correct • Durability: the database needs to remember the state it is in at all moments, even when failures occur • Like all acronyms, more effort in making it sound cute than in