Kafka, Rabbitmq and NATS Streaming
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Robust Messaging with Rabbitmq
Spring RabbitMQ for High Load Martin Toshev Who am I Software consultant (CoffeeCupConsulting) BG JUG board member (http://jug.bg) OpenJDK and Oracle RDBMS enthusiast Twitter: @martin_fmi 2 3 Agenda • Messaging Basics • RabbitMQ Overview • Spring RabbitMQ 4 Messaging Basics 5 Messaging • Messaging provides a mechanism for loosely-coupled integration of systems • The central unit of processing in a message is a message which typically contains a body and a header 6 Use cases • Offloading long-running tasks to worker nodes • Distributing and processing high loads of data • Aggregating logs and propagating events between systems • Many others … 7 Messaging protocols • Messaging solutions implement different protocols for transferring of messages such as AMQP, XMPP, MQTT, STOMP, Kafka binary protocol and others • The variety of protocols imply vendor lock-in 8 Messaging protocols comparison AMQP MQTT XMPP STOMP Kafka goal replacement of messaging for instant messaging, message-oriented processing of large proprietary protocols resource-constrained adopted for wider middleware real-time data feeds devices use format binary binary XML-based text-based binary API divided into classes simple (5 basic different XML items ~ 10 basic commands 42 request types in (> 40 methods in operations with 2-3 with multiple types latest version (Kafka RabbitMQ) packet types for each) 2.0.0) reliability publisher/subscriber acknowledgements Acknowledgments Subscriber Acknowledgements, acknowledgements, and resumptions acknowledgements transactional transactions -

Rocketbufs: a Framework for Building Efficient, In-Memory, Message-Oriented Middleware
RocketBufs: A Framework for Building Efficient, In-Memory, Message-Oriented Middleware Huy Hoang, Benjamin Cassell, Tim Brecht, Samer Al-Kiswany Cheriton School of Computer Science, University of Waterloo ABSTRACT ACM Reference Format: As companies increasingly deploy message-oriented middleware Huy Hoang, Benjamin Cassell, Tim Brecht, Samer Al-Kiswany. 2020. Rock- (MOM) systems in mission-critical components of their infrastruc- etBufs: A Framework for Building Efficient, In-Memory, Message-Oriented Middleware. In The 14th ACM International Conference on Distributed and tures and services, the demand for improved performance and func- Event-based Systems (DEBS ’20), July 13–17, 2020, Virtual Event, QC, Canada. tionality has accelerated the rate at which new systems are being ACM, New York, NY, USA, 12 pages. https://doi.org/10.1145/3401025.3401744 developed. Unfortunately, existing MOM systems are not designed to take advantages of techniques for high-performance data center communication (e.g., RDMA). In this paper, we describe the design 1 INTRODUCTION and implementation of RocketBufs, a framework which provides Message-Oriented Middleware (MOM) systems, also often referred infrastructure for building high-performance, in-memory Message- to as publish/subscribe, message-queuing, or event-based systems, Oriented Middleware (MOM) applications. RocketBufs provides are a popular class of software designed to support loosely-coupled memory-based buffer abstractions and APIs, which are designed messaging in modern distributed applications. Examples of appli- to work efficiently with different transport protocols. Applications cations and services that utilize MOM systems include IBM’s cloud implemented using RocketBufs manage buffer data using input functions [29], the Apache OpenWhisk serverless framework [10], (rIn) and output (rOut) classes, while the framework is responsible the Hyperledger blockchain framework [7] and streaming media for transmitting, receiving and synchronizing buffer access. -

Analysis of Notification Methods with Respect to Mobile System Characteristics
Proceedings of the Federated Conference on DOI: 10.15439/2015F6 Computer Science and Information Systems pp. 1183–1189 ACSIS, Vol. 5 Analysis of notification methods with respect to mobile system characteristics Piotr Nawrocki ∗, Mikołaj Jakubowski † and Tomasz Godzik ‡ ∗AGH University of Science and Technology, al. A. Mickiewicza 30, 30-059 Krakow, Poland e-mail:[email protected] †e-mail:[email protected] ‡e-mail:[email protected] Abstract—Recently, there has been an increasing need for most promise and therefore the purpose is to discern their secure, efficient and simple notification methods for mobile usefulness in the best way possible. systems. Such systems are meant to provide users with precise In addition to the protocols and methods above, we inves- tools best suited for work or leisure environments and a lot of effort has been put into creating a multitude of mobile tigated other solutions, such as the Apple push notification applications. However, not much research has been put at the or Line application which, for various reasons, were not same time into determining which of the available protocols considered further. The Apple push notification technology is a are best suited for individual tasks. Here a number of basic good solution, but it is proprietary, i.e. limited to Apple devices notification methods are presented and tests are performed for and that is why we decided to test more universal solutions the most promising ones. An attempt is made to determine which methods have the best throughput, latency, security and other first. There are also solutions (applications) that use their own characteristics. -

AMQP and Rabbitmq Message Queuing As an Integration Mechanism
2/19/2018 MQTT A protocol for communicating with your things David Brinnen and Brett Cameron SESAM Seminar, March 2018 Abstract The Internet of Things refers to the ever-growing network of physical devices that have IP connectivity, allowing them to connect to the internet, and the communication that occurs between these devices and other internet-enabled devices and systems. In this talk, Brett and David will introduce the Internet of Things and will discuss some of the key technologies associated with the creation of Internet of Things solutions and services within the manufacturing domain. Particular attention will be given to MQTT, which is gaining acceptance as the preferred protocol for use by the Internet of Things applications. Currently available implementations of MQTT will be briefly reviewed and case studies illustrating the application of the protocol will be presented. Some examples of how MQTT might be used to implement secure, fault-tolerant, and scalable Internet of Things solutions will be discussed, and the application and use of MQTT in Next Generation SCADA systems that need to monitor and control devices at scale in a connected world will be will be discussed and demonstrated. 2 2/19/2018 About David Since completing his Masters studies in Embedded Software at the Swedish Royal Institute of Technology 2015 (KTH), David has been working as a software engineer across a range of projects, including the implementation of control logical and the commissioning of Energy Machines integrated energy systems and air handling units (https://www.energymachines.com/), and the development of a next-generation SADA platform (ControlMachines™) and simulation software to control, monitor, and model Energy Machines deployments. -

Writing a Message Broker in Golang
Writing a Message Broker in GoLang George Vanburgh Supervised by Alvaro A.A. Fernandes May 3, 2016 A report submitted in part fulfilment of the degree of BSc (Hons) in Computer Science with Industrial Experience Abstract This report details an exercise in learning and evaluating the 'Go' programming language, by building a feature-rich application message broker using modern software engineering techniques and best practises. Some of the unique features of Go are presented, and the importance and relevance of these features in building simple, high-performance distributed software is explored. Discussion of the novel 'CSP-style' concurrency features in Go lead to an unorthodox design proposal for an enterprise-style messaging broker - George's Asynchronous Message Broker (gamq). The implementation of gamq is then is then described and critiqued. Finally, the process and results of the software testing are presented, and analysed. Acknowledgements Many thanks to my supervisor, Alvaro Fernandes, for his continuous support, guidance and patience - without which, this project would have been impossible. Thanks also go to my family and friends for their help and encouragement both during this project, and throughout my time at University. Contents 1 Introduction 3 1.1 Background . .3 1.2 Goals . .3 2 Background 4 2.1 Messages . .4 2.2 Message Brokers . .4 2.2.1 Pub/Sub . .6 2.2.2 Queues . .8 2.2.3 Topics . .8 2.3 Broker Requirements . .8 2.3.1 Failure Handling . 10 2.3.2 Network Bandwidth Utilisation . 10 2.3.3 Network latency . 10 2.3.4 Network packet loss . 11 2.3.5 Message power cost . -

Location Independent Inter-Process Communication As Software Buses
Location independent inter-process communication as software buses Erik Samuelsson Erik Samuelsson VT 2016 Bachelor Thesis, 15 credits Supervisor: Cristian Klein, Ewnetu Bayuh Lakew Extern Supervisor: Clas H¨ogvall, Rickard Sj¨ostr¨om, Johan Forsman Examiner: Jerry Eriksson Bachelor’s Programme in Computing Science, 180 credits Abstract Telecommunication networks will transform and gradually migrate into virtualized cloud environments as a result of the potential for higher profitability through reduced costs and increased revenues. The purpose of this thesis is to investigate architectural mecha- nisms for location-independent communication between software components in a virtualized base station. Systems that provide such mechanisms are typically referred to as middleware and de- ployed as Platform-as-a-Service (PaaS). The overall goal is to achieve desired characteristics in cloud deployment regarding on- demand self-service, rapid elasticity of capacity while upholding services and high availability. Four communication protocols are examined and evaluated based on a set of functional and non- functional requirements that are especially relevant for a virtu- alized base station. In comparison with the Advanced Message Queuing Protocol (AMQP), Message Queuing Telemetry Trans- port (MQTT) and the eXtensible Messaging and Presence Pro- tocol (XMPP), the Data Distribution Service (DDS) standard is found to have excellent performance characteristics. Its complex- ity might have implications for the development and deployment though, that will increase the time it takes to reap the benefits from its advantages. Acknowledgements I wish to sincerely thank my supervisors at Tieto, Clas H¨ogvall, Rickard Sj¨ostr¨om and Johan Forsman for introducing an interesting and challenging thesis idea and for entrusting me with the task. -

Industry Paper: Kafka Versus Rabbitmq a Comparative Study of Two Industry Reference Publish/Subscribe Implementations
Industry Paper: Kafka versus RabbitMQ A comparative study of two industry reference publish/subscribe implementations Philippe Dobbelaere Kyumars Sheykh Esmaili Nokia Bell Labs Nokia Bell Labs Antwerp, Belgium Antwerp, Belgium ABSTRACT 1 INTRODUCTION Publish/subscribe is a distributed interaction paradigm well adapted e Internet has considerably changed the scale of distributed sys- to the deployment of scalable and loosely coupled systems. tems. Distributed systems now involve thousands of entities po- Apache Kaa and RabbitMQ are two popular open-source and tentially distributed all over the world whose location and behav- commercially-supported pub/sub systems that have been around for ior may greatly vary throughout the lifetime of the system. ese almost a decade and have seen wide adoption. Given the popularity constraints underline the need for more exible communication of these two systems and the fact that both are branded as pub/sub models and systems that reect the dynamic and decoupled na- systems, two frequently asked questions in the relevant online ture of the applications. Individual point-to-point and synchronous forums are: how do they compare against each other and which communications lead to rigid and static applications, and make the one to use? development of dynamic large-scale applications cumbersome [14]. In this paper, we frame the arguments in a holistic approach by To reduce the burden of application designers, the glue between establishing a common comparison framework based on the core the dierent entities in such large-scale seings should rather be functionalities of pub/sub systems. Using this framework, we then provided by a dedicated middleware infrastructure, based on an ad- venture into a qualitative and quantitative (i.e. -

Extending IBM Websphere MQ and Websphere Message Broker to The
Extending IBM WebSphere MQ and WebSphere Message Broker to the Clouds Session 14238 Ralph Bateman ( [email protected] ) STSM, Messaging and Integration Customer Support IBM Hursley Lab Private Community Deploy to a Cloud. Application Public Public Private 2 Don’t worry it’s in the cloud….. Thanks for listening. Questions? 3 Topics Cloud Concepts Introduction to PureApplication System, IWD, and SCAS Patterns and Messaging Virtual System Pattern – WebSphere MQ Hypervisor Edition Virtual Application Pattern – Messaging Extension Virtual System Pattern – Message Broker Reference – Current Versions and Links 4 Cloud Deployment Models Private Private –Used solely by the owning organisation –Benefits include in-house storage of critical data Community –Owned by several organisations but supporting a specific Community community –Some of the benefits of public cloud whilst in a closed community Public –The consumer and provider of cloud services are separate enterprises Public –Benefits include low-cost and scalability Hybrid Public –Seamlessly combines services from public and private cloud Private –Combination of benefits, but requires careful placement of secure/regulated data and apps 5 Cloud Service Models Reflect the traditional computing layers Software as a Service (SaaS) –Provides access to hosted applications or services, which Client Devices/Browsers may themselves use PaaS and IaaS services – Usage based charging , per hour or per ‘transaction’ Client Platform as a Service (PaaS) –Application Centric view - consumer’s application deployed -

A Survey of Distributed Message Broker Queues
A Survey of Distributed Message Broker Queues Vineet John Xia Liu University of Waterloo University of Waterloo [email protected] [email protected] ABSTRACT This paper surveys the message brokers that are in vogue today for distributed communication. Their primary goal is to facilitate the construction of decentralized topolo- gies without single points of failure, enabling fault tol- erance and high availability. These characteristics make them optimal for usage within distributed architectures. However, there are multiple protocols built to achieve this, and it would be beneficial to have a empirical comparison between their features and performance to determine their real-world applicability. Figure 1: Kafka Architecture This paper focuses on two popular protocols (Kafka and AMQP) and explores the divergence in their fea- RQ0 What are the message broker implementations tures as well as their performance under varied testing commonly in use today? workloads. RQ1 What are the common requirements for the im- plementation of message queues? KEYWORDS RQ2 What are the divergent functionalities in the distributed message broker, message queue, kafka, amqp, current message queue offerings? rabbitmq RQ3 How do each of the implementations offer relia- bility, partitioning and fault tolerance? 1 INTRODUCTION 3 KAFKA Kafka was developed at LinkedIn and primarily used Distributed Message Brokers are typically used to decou- for log processing. This worked well for Kafka’s user en- ple separate stages of a software architecture. They per- gagement metrics collection use-case. The fundamental mit communication between these stages asynchronously, features behind Kafka are performance over reliability by using the publish-subscribe paradigm.[1]. These mes- and it offers high throughput, low latency message queu- sage brokers are also finding new applications in the ing. -

Message-Oriented Middleware As a Queue Management Solution to Improve Job Handling Within an E- Commerce System
DEGREE PROJECT IN INFORMATION AND COMMUNICATION TECHNOLOGY, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2018 Message-Oriented Middleware as a Queue Management Solution to Improve Job Handling within an E- Commerce System TOBIAS JOHANSSON KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE CONTENTS 1 Abstract Today’s applications are required to continuously adapt and adjust, to be able to meet a constant change in demand. As result of an in- creasing amount of data, choosing the right communication method becomes a vital step. A solution that have been functional for a long time, may at any point in time be unable to reach the level it requires and instead turns into bottlenecks and inefficient solutions. Using a database as a communication method between system enti- ties, does not have to be a bad solution. A database has it perks with being a simple solution and efficient query operations. However, us- ing it as a queue management system, requires entities to continuously poll new table entries. This solution may not be the most suitable nor best available option. There exists communication system developed for the specific purpose of efficiently distributing messages to avail- able parties. Implementing a message-oriented middleware enables for asynchronous communication which promotes applications to be more loosely cou- pled. As a result, available resources could be better utilised and im- prove the system performance. This degree project investigates the development and integration of two message-oriented middlewares, RabbitMQ and AcviteMQ, within an e-commerce system. The pur- pose is to explore the potentials of changing queue management sys- tem from a database to a message broker. -

A Comparison Between Rabbitmq and REST Ful API for Communication Between Micro-Services Web Application
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 07 Issue: 05 | May 2020 www.irjet.net p-ISSN: 2395-0072 A Comparison between RabbitMQ and REST ful API for Communication between Micro-Services Web Application Akshay Kamath B1, Chaitra B H2 1B.E Student, Department of Computer Science and Engineering, RV College of Engineering, Bangalore 2Professor, Department of Computer Science and Engineering, RV College of Engineering, Bangalore ---------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - As Micro-Service architecture is being used as trend technology, it becomes important to discuss what should be the communication medium between multiple micro- services making it efficient and scalable. This paper discusses about why AMQP (Advanced Message Queuing Protocol) technology is better at handling load than traditional REST (Representational State Transfer) communication. AMQP seems to be promising technology specially when there is massive data that is communicated between micro-services. Fig -1: RESTful API operations This paper discusses about RabbitMQ as the AMQP Message broker. 1.2 Advanced Message Queuing Protocol Key Words: AMQP, REST, RabbitMQ AMQP is advanced Message Queuing protocol, which is quite different compared to RESTful API. This messaging 1. INTRODUCTION middleware service helps in sending and receiving messages. Message broker is hosted seperately and runs independent RESTful (Representational State Transfer) is a architecture of Client or Server Micro-service [4]. This paper discuss style used to send and receive resource between two piece of about RabbitMQ as the message broker. There are three software usually they are called as client and server or main components while considering any AMQP messaging publisher and subscriber [1][2]. -
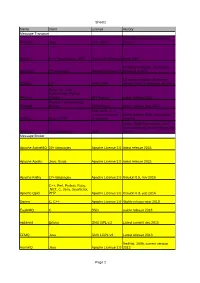
Sheet1 Page 1 Name Client License History Message Transport Jeromq
Sheet1 Name client License History Message Transport Java implementation of zeromq JeroMQ Java GNU LGPL library MSMQ C++, Visual Basic, .NET, Part of OS Windows since 1997 Currently only beta, version 0.6. Nanomsg 23 languages Apache License 2.0 released ul 2015 C# implementation of zeromq, NetMQ C# GNU LGPL version 3.3.2.1. released sep 2015 Ruby, Go, Java, CoffeeScript, Python, Resque Clojure MIT license stable release 2013 Python, Cyclone, Ruby, RestMQ Erlang BSD license stable release may 2015 GNU LGPL v3, or commercial license stable release 2015, community Sidekiq Ruby, HTTP for business growing IMatix, 2008, first version; 2011 mass produced, latest release aug ZeroMQ 30+ languages LGPL 2015 Message Broker Apache ActiveMQ 20+ languages Apache License 2.0 latest release 2015 Apache Apollo Java, Scala Apache License 2.0 latest release 2015 Apache Kafka 17+ languages Apache License 2.0 Version 0.9, nov 2015 C++, Perl, Python, Ruby, .NET, C, Java, JavaScript, Apache Qpid PHP Apache License 2.0 Version 0.3, sep 2014 Darner C, C++ Apache License 2.0 Stable release mar 2013 EagleMQ C BSD stable release 2013 ejabberd Erlang GNU GPL v.2 Latest commit dec 2015 FFMQ Java GNU LGPL v3 Latest release 2013 RedHat, 2009, current version HornetQ Java Apache License 2.0 2013 Page 1 Sheet1 IBM Websphere C, Visual Basic, .NET, C++, Various IBM IBM, 1990's, latest MQ V8 released in MQ Java, JMS, ActiveX licences 2014 OW2, 1999, latest release may JORAM Java, XML, 13+ others LGPL 2015 Kestrel ASP.NET, Java Apache License 2.0 2.4.1 released nov 2012 MemcacheQ Perl, Python, C, BSD license ~2009, version 0.2.0.