Student Project in PDF. a System on a Chip for Audio Encoding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lossless Audio Codec Comparison
Contents Introduction 3 1 CD-audio test 4 1.1 CD's used . .4 1.2 Results all CD's together . .4 1.3 Interesting quirks . .7 1.3.1 Mono encoded as stereo (Dan Browns Angels and Demons) . .7 1.3.2 Compressibility . .9 1.4 Convergence of the results . 10 2 High-resolution audio 13 2.1 Nine Inch Nails' The Slip . 13 2.2 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 16 2.3 Wasted bits . 18 3 Multichannel audio 20 3.1 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 20 A Motivation for choosing these CDs 23 B Test setup 27 B.1 Scripting and graphing . 27 B.2 Codecs and parameters used . 27 B.3 MD5 checksumming . 28 C Revision history 30 Bibliography 31 2 Introduction While testing the efficiency of lossy codecs can be quite cumbersome (as results differ for each person), comparing lossless codecs is much easier. As the last well documented and comprehensive test available on the internet has been a few years ago, I thought it would be a good idea to update. Beside comparing with CD-audio (which is often done to assess codec performance) and spitting out a grand total, this comparison also looks at extremes that occurred during the test and takes a look at 'high-resolution audio' and multichannel/surround audio. While the comparison was made to update the comparison-page on the FLAC website, it aims to be fair and unbiased. -

Download Media Player Codec Pack Version 4.1 Media Player Codec Pack
download media player codec pack version 4.1 Media Player Codec Pack. Description: In Microsoft Windows 10 it is not possible to set all file associations using an installer. Microsoft chose to block changes of file associations with the introduction of their Zune players. Third party codecs are also blocked in some instances, preventing some files from playing in the Zune players. A simple workaround for this problem is to switch playback of video and music files to Windows Media Player manually. In start menu click on the "Settings". In the "Windows Settings" window click on "System". On the "System" pane click on "Default apps". On the "Choose default applications" pane click on "Films & TV" under "Video Player". On the "Choose an application" pop up menu click on "Windows Media Player" to set Windows Media Player as the default player for video files. Footnote: The same method can be used to apply file associations for music, by simply clicking on "Groove Music" under "Media Player" instead of changing Video Player in step 4. Media Player Codec Pack Plus. Codec's Explained: A codec is a piece of software on either a device or computer capable of encoding and/or decoding video and/or audio data from files, streams and broadcasts. The word Codec is a portmanteau of ' co mpressor- dec ompressor' Compression types that you will be able to play include: x264 | x265 | h.265 | HEVC | 10bit x265 | 10bit x264 | AVCHD | AVC DivX | XviD | MP4 | MPEG4 | MPEG2 and many more. File types you will be able to play include: .bdmv | .evo | .hevc | .mkv | .avi | .flv | .webm | .mp4 | .m4v | .m4a | .ts | .ogm .ac3 | .dts | .alac | .flac | .ape | .aac | .ogg | .ofr | .mpc | .3gp and many more. -

Ardour Export Redesign
Ardour Export Redesign Thorsten Wilms [email protected] Revision 2 2007-07-17 Table of Contents 1 Introduction 4 4.5 Endianness 8 2 Insights From a Survey 4 4.6 Channel Count 8 2.1 Export When? 4 4.7 Mapping Channels 8 2.2 Channel Count 4 4.8 CD Marker Files 9 2.3 Requested File Types 5 4.9 Trimming 9 2.4 Sample Formats and Rates in Use 5 4.10 Filename Conflicts 9 2.5 Wish List 5 4.11 Peaks 10 2.5.1 More than one format at once 5 4.12 Blocking JACK 10 2.5.2 Files per Track / Bus 5 4.13 Does it have to be a dialog? 10 2.5.3 Optionally store timestamps 5 5 Track Export 11 2.6 General Problems 6 6 MIDI 12 3 Feature Requests 6 7 Steps After Exporting 12 3.1 Multichannel 6 7.1 Normalize 12 3.2 Individual Files 6 7.2 Trim silence 13 3.3 Realtime Export 6 7.3 Encode 13 3.4 Range ad File Export History 7 7.4 Tag 13 3.5 Running a Script 7 7.5 Upload 13 3.6 Export Markers as Text 7 7.6 Burn CD / DVD 13 4 The Current Dialog 7 7.7 Backup / Archiving 14 4.1 Time Span Selection 7 7.8 Authoring 14 4.2 Ranges 7 8 Container Formats 14 4.3 File vs Directory Selection 8 8.1 libsndfile, currently offered for Export 14 4.4 Container Types 8 8.2 libsndfile, also interesting 14 8.3 libsndfile, rather exotic 15 12 Specification 18 8.4 Interesting 15 12.1 Core 18 8.4.1 BWF – Broadcast Wave Format 15 12.2 Layout 18 8.4.2 Matroska 15 12.3 Presets 18 8.5 Problematic 15 12.4 Speed 18 8.6 Not of further interest 15 12.5 Time span 19 8.7 Check (Todo) 15 12.6 CD Marker Files 19 9 Encodings 16 12.7 Mapping 19 9.1 Libsndfile supported 16 12.8 Processing 19 9.2 Interesting 16 12.9 Container and Encodings 19 9.3 Problematic 16 12.10 Target Folder 20 9.4 Not of further interest 16 12.11 Filenames 20 10 Container / Encoding Combinations 17 12.12 Multiplication 20 11 Elements 17 12.13 Left out 21 11.1 Input 17 13 Credits 21 11.2 Output 17 14 Todo 22 1 Introduction 4 1 Introduction 2 Insights From a Survey The basic purpose of Ardour's export functionality is I conducted a quick survey on the Linux Audio Users to create mixdowns of multitrack arrangements. -

Lossless Audio Codec Comparison
Contents Introduction 3 1 Test setup 4 1.1 Scripting and graphing . .4 1.2 Codecs and parameters used . .5 1.3 WMA, RealAudio and ALAC . .6 2 CD-audio test 8 2.1 CD's used . .8 2.2 Results all CD's together . .9 2.3 Interesting quirks . 12 2.3.1 Mono encoded as stereo (Dan Browns Angels and Demons) 12 2.4 Convergence of the results . 15 3 High-resolution audio 17 3.1 Nine Inch Nails' The Slip . 17 3.2 Howard Shore's soundtrack for The Lord of the Rings: The Re- turn of the King . 20 3.3 Wasted bits . 22 4 Multichannel audio 24 4.1 Howard Shore's soundtrack for The Lord of the Rings: The Re- turn of the King . 24 A Motivation for choosing these CDs 27 Bibliography 31 2 Introduction While testing the efficiency of lossy codecs can be quite cumbersome (as results differ for each person), comparing lossless codecs is much easier. As the last well documented and comprehensive test available on the internet has been a few years ago, I thought it would be a good idea to update. Beside comparing with CD-audio (which is often done to assess codec perfor- mance) and spitting out a grand total, this comparison also looks at extremes that occurred during the test and takes a look at 'high-resolution audio' and multichannel/surround audio. While the comparison was made to update the comparison-page on the FLAC website, it aims to be fair and unbiased. Because of this, you'll probably won't find anything that looks like conclusions: test results are displayed and analysed, but there is no judgement or choice made. -

(A/V Codecs) REDCODE RAW (.R3D) ARRIRAW
What is a Codec? Codec is a portmanteau of either "Compressor-Decompressor" or "Coder-Decoder," which describes a device or program capable of performing transformations on a data stream or signal. Codecs encode a stream or signal for transmission, storage or encryption and decode it for viewing or editing. Codecs are often used in videoconferencing and streaming media solutions. A video codec converts analog video signals from a video camera into digital signals for transmission. It then converts the digital signals back to analog for display. An audio codec converts analog audio signals from a microphone into digital signals for transmission. It then converts the digital signals back to analog for playing. The raw encoded form of audio and video data is often called essence, to distinguish it from the metadata information that together make up the information content of the stream and any "wrapper" data that is then added to aid access to or improve the robustness of the stream. Most codecs are lossy, in order to get a reasonably small file size. There are lossless codecs as well, but for most purposes the almost imperceptible increase in quality is not worth the considerable increase in data size. The main exception is if the data will undergo more processing in the future, in which case the repeated lossy encoding would damage the eventual quality too much. Many multimedia data streams need to contain both audio and video data, and often some form of metadata that permits synchronization of the audio and video. Each of these three streams may be handled by different programs, processes, or hardware; but for the multimedia data stream to be useful in stored or transmitted form, they must be encapsulated together in a container format. -

Name Synopsis Description
SHNTOOL(1) local SHNTOOL(1) NAME shntool − a multi-purpose WAV Edata processing and reporting utility SYNOPSIS shntool mode ... shntool [CORE OPTION] DESCRIPTION shntool is a command-line utility to viewand/or modify WAV Edata and properties. It runs in several dif- ferent operating modes, and supports various lossless audio formats. shntool is comprised of three parts - its core, mode modules, and format modules. This helps to makethe code easier to maintain, as well as aid other programmers in developing newfunctionality.The distribution archive contains a file named ’modules.howto’ that describes howtocreate a newmode or format module, for those so inclined. Mode modules shntool performs various functions on WAV Edata through the use of mode modules. The core of shntool is simply a wrapper around the mode modules. In fact, when shntool is run with a valid mode as its first argument, it essentially runs the main procedure for the specified mode, and quits. shntool comes with sev- eral built-in modes, described below: len Displays length, size and properties of PCM WAV Edata fix Fixes sector-boundary problems with CD-quality PCM WAV Edata hash Computes the MD5 or SHA1 fingerprint of PCM WAV Edata pad Pads CD(hyquality files not aligned on sector boundaries with silence join Joins PCM WAV Edata from multiple files into one split Splits PCM WAV Edata from one file into multiple files cat Writes PCM WAV Edata from one or more files to the terminal cmp Compares PCM WAV Edata in twofiles cue Generates a CUE sheet or split points from a set of files conv Converts files from one format to another info Displays detailed information about PCM WAV Edata strip Strips extra RIFF chunks and/or writes canonical headers gen Generates CD-quality PCM WAV Edata files containing silence trim Trims PCM WAV Esilence from the ends of files Formore information on the meaning of the various command-line options for each mode, see the MODE- SPECIFIC OPTIONS section below. -

Spb Tv Encoder
SPB TV ENCODER INPUT IP Input Interfaces 2x Gigabit Ethernet SPB TV Encoder is a professional solution for the fast, high- that processes multi-format video streams for delivery to different quality transcoding of live and on-demand video streams from end-user devices: Mobile, Tablet, Desktop, and connected TV-sets. Optional Digital Input Interfaces SDI, DVB-S a single headend to multi-screen devices. Leverage your network SPB TV Encoding solution can be delivered in a flexible software- Input IP Streams UDP Unicast/Multicast, HTTP, HLS, RTSP, RTMP, MMS with a unified platform for IP TV, OTT TV and mobile TV services based configuration or as off the-shelf equipment. Supported Codecs MPEG-2, MPEG-4, H.264, MPEG-1, MPEG-1 Layer 3, AAC, HE AAC, AC3, WMV 7, WMV 8, WMV 9, WMA 1, WMA 2, WMA 9 Pro, On2 VP3, On2 VP5, On2 VP6, On2 VP8, PNG Filters Video cropping, Image insertion on input source loss, automatic audio loudness adjustment Up to 100 multi-rate channels FEC (Forward Error Correction) OUTPUT Live and on-demand video encoding 5.1 Audio, auto audio gain support IP Output Interfaces 2x Gigabit Ethernet Remote monitoring tools Keeping aspect ratio Output IP streams RTP Unicast/Multicast Image insertion on input loss Image overlay Output Codecs H.264 (Baseline, Main, High), MPEG-4, AAC, HE AAC, H.265 Web GUI and CLI interfaces Hardsubs overlay VoD Output Multi Track MP4 VoD Publishing FTP, SFTP SNMP 3D encoding support Thumbnails PNG, JPEG Managed updates to include the latest Multi output support codecs, formats, profiles and devices MANAGEMENT/MONITORING -

Voxpro/Audionlabs Was Acquired by Wheatstone Corporation in the Fall of 2015
NOTE: VoxPro/AudionLabs was acquired by Wheatstone Corporation in the fall of 2015. As a result the contact information and support links listed in this legacy document are no longer current. Should you require further assistance regarding the information presented here, please refer to the following contact info: EMAIL: [email protected] TEL: +1.252-638-7000 (9am-5pm EST) WEB: wheatstone.com [menu item: VoxPro] MAIL: Wheatstone Corporation 600 Industrial Drive New Bern, NC. 28562 USA 100716 Contents 3 Table of Contents 0 Chapter 1 Introduction 8 Chapter 2 Getting Started 10 1 VoxPro Main................................................................................................................................... Window 11 2 VoxPro Control................................................................................................................................... Panel 12 3 User Accounts................................................................................................................................... 13 4 Passwords ................................................................................................................................... 14 Chapter 3 Recording 16 1 Create New ...................................................................................................................................Recording 16 2 Create Empty................................................................................................................................... Recording 18 3 Create Recording.................................................................................................................................. -

Lossless Compression of Audio Data
CHAPTER 12 Lossless Compression of Audio Data ROBERT C. MAHER OVERVIEW Lossless data compression of digital audio signals is useful when it is necessary to minimize the storage space or transmission bandwidth of audio data while still maintaining archival quality. Available techniques for lossless audio compression, or lossless audio packing, generally employ an adaptive waveform predictor with a variable-rate entropy coding of the residual, such as Huffman or Golomb-Rice coding. The amount of data compression can vary considerably from one audio waveform to another, but ratios of less than 3 are typical. Several freeware, shareware, and proprietary commercial lossless audio packing programs are available. 12.1 INTRODUCTION The Internet is increasingly being used as a means to deliver audio content to end-users for en tertainment, education, and commerce. It is clearly advantageous to minimize the time required to download an audio data file and the storage capacity required to hold it. Moreover, the expec tations of end-users with regard to signal quality, number of audio channels, meta-data such as song lyrics, and similar additional features provide incentives to compress the audio data. 12.1.1 Background In the past decade there have been significant breakthroughs in audio data compression using lossy perceptual coding [1]. These techniques lower the bit rate required to represent the signal by establishing perceptual error criteria, meaning that a model of human hearing perception is Copyright 2003. Elsevier Science (USA). 255 AU rights reserved. 256 PART III / APPLICATIONS used to guide the elimination of excess bits that can be either reconstructed (redundancy in the signal) orignored (inaudible components in the signal). -

Codec Is a Portmanteau of Either
What is a Codec? Codec is a portmanteau of either "Compressor-Decompressor" or "Coder-Decoder," which describes a device or program capable of performing transformations on a data stream or signal. Codecs encode a stream or signal for transmission, storage or encryption and decode it for viewing or editing. Codecs are often used in videoconferencing and streaming media solutions. A video codec converts analog video signals from a video camera into digital signals for transmission. It then converts the digital signals back to analog for display. An audio codec converts analog audio signals from a microphone into digital signals for transmission. It then converts the digital signals back to analog for playing. The raw encoded form of audio and video data is often called essence, to distinguish it from the metadata information that together make up the information content of the stream and any "wrapper" data that is then added to aid access to or improve the robustness of the stream. Most codecs are lossy, in order to get a reasonably small file size. There are lossless codecs as well, but for most purposes the almost imperceptible increase in quality is not worth the considerable increase in data size. The main exception is if the data will undergo more processing in the future, in which case the repeated lossy encoding would damage the eventual quality too much. Many multimedia data streams need to contain both audio and video data, and often some form of metadata that permits synchronization of the audio and video. Each of these three streams may be handled by different programs, processes, or hardware; but for the multimedia data stream to be useful in stored or transmitted form, they must be encapsulated together in a container format. -
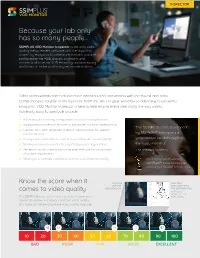
Download the Inspector Product Sheet (Pdf)
INSPECTOR Because your lab only has so many people... SSIMPLUS VOD Monitor Inspector is the only video quality measurement software with the algorithm trusted by Hollywood to determine the best possible configuration for R&D groups, engineers and architects who set up VOD encoding and processing workflows or make purchasing recommendations. Video professionals can evaluate more encoders and transcoders with the fastest and most comprehensive solution in the business. From the start of your workflow to delivering to consumer endpoints, VOD Monitor Inspector is here to help ensure every step along the way works flawlessly. Easy-to-use tools provide: A/B testing for encoding configurations and purchasing decisions Sandbox environment for encoder or transcoder output troubleshooting “The SSIMPLUS score developed Creation of custom templates to identify best practices for specific content libraries by SSIMWAVE represents a Configurable automation to save time and eliminate manual QA/QC generational breakthrough in Side-by-side visual inspector to subjectively assess degradations the video industry.” Perceptual quality maps that provide pixel level graphic visualization –The Television Academy of content impairments Allows you to optimize network performance and improve quality Our Emmy Award-winning SSIMPLUS™ score mimics the accuracy of 100,000 human eyes. Know the score when it YOU CAN HOW OUR SEE THE SOFTWARE SEES DEGRADATION THE DEGRADATION comes to video quality NARROW IT DOWN TO THE The SSIMPLUS score is the most accurate measurement PIXEL LEVEL representing how end-viewers perceive video quality. Our score can tell exactly where video quality degrades. 18 34 59 72 87 10 20 30 40 50 60 70 80 90 100 BAD POOR FAIR GOOD EXCELLENT Helping your workflow, work SSIMPLUS VOD Monitor Inspector helps ensure your video infrastructure is not negatively impacting content anywhere in your workflow. -

How to Play Itunes Purchased and Rental Movies with XBMC
How to Play iTunes Purchased and Rental Movies with XBMC What are XBMC Player Video Formats? XBMC is an open source media player software developed by XBMC team. With XBMC media player, you can view and watch any videos, music, podcasts on your local computer or from internet. XBMC is developed for Mac, Windows, iOS, Android platform now. So almost all of us can use this powerful media player app without obstacles. XBMC for Mac can be compatible with Mac OS X tiger or later. It supports playing 1080p video on Mac computer via software decoding on the CPU if it is powerful enough. And XBMC for Windows is compatible with Windows 7, Vista and XP. Even though it can run well on 64-bit machine, it is not yet optimized for that architecture so there is no performance gain when running on 64-bit Windows. Let's learn what formats does XBMC support at first. Video formats supported by XBMC: MPEG-1, MPEG-2, H.263, MPEG-4 SP and ASP, MPEG-4 AVC (H.264), HuffYUV, Indeo, MJPEG, RealVideo, RMVB, Sorenson, WMV, Cinepak. Audio formats supported by XBMC: MIDI, AIFF, WAV/WAVE, AIFF, MP2, MP3, AAC, AACplus (AAC+), Vorbis, AC3, DTS, ALAC, AMR, FLAC, Monkey's Audio (APE), RealAudio, SHN, WavPack, MPC/Musepack/Mpeg+, Shorten, Speex, WMA, IT, S3M, MOD (Amiga Module), XM, NSF (NES Sound Format), SPC (SNES), GYM (Genesis), SID (Commodore 64), Adlib, YM (Atari ST), ADPCM (Nintendo GameCube), and CD-DA. Can XBMC Play iTunes Downloaded Videos? The current software limitation on XBMC is that it can't play any DRM-protected music and videos, like audio files purchased from online music stores as iTunes Music Store, MSN Music, Audible.com, Windows Media Player Stores, and video files protected with Windows Media DRM, Fairplay DRM or DivX proprietary DRM.