Constant and Linear Functions Constant Functions in the first Lecture, We Introduced the Notion of a Real-Valued Function As a Tool for Investigating the Real World
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Introduction to Mathematical Modelling
An Introduction to Mathematical Modelling Glenn Marion, Bioinformatics and Statistics Scotland Given 2008 by Daniel Lawson and Glenn Marion 2008 Contents 1 Introduction 1 1.1 Whatismathematicalmodelling?. .......... 1 1.2 Whatobjectivescanmodellingachieve? . ............ 1 1.3 Classificationsofmodels . ......... 1 1.4 Stagesofmodelling............................... ....... 2 2 Building models 4 2.1 Gettingstarted .................................. ...... 4 2.2 Systemsanalysis ................................. ...... 4 2.2.1 Makingassumptions ............................. .... 4 2.2.2 Flowdiagrams .................................. 6 2.3 Choosingmathematicalequations. ........... 7 2.3.1 Equationsfromtheliterature . ........ 7 2.3.2 Analogiesfromphysics. ...... 8 2.3.3 Dataexploration ............................... .... 8 2.4 Solvingequations................................ ....... 9 2.4.1 Analytically.................................. .... 9 2.4.2 Numerically................................... 10 3 Studying models 12 3.1 Dimensionlessform............................... ....... 12 3.2 Asymptoticbehaviour ............................. ....... 12 3.3 Sensitivityanalysis . ......... 14 3.4 Modellingmodeloutput . ....... 16 4 Testing models 18 4.1 Testingtheassumptions . ........ 18 4.2 Modelstructure.................................. ...... 18 i 4.3 Predictionofpreviouslyunuseddata . ............ 18 4.3.1 Reasonsforpredictionerrors . ........ 20 4.4 Estimatingmodelparameters . ......... 20 4.5 Comparingtwomodelsforthesamesystem . ......... -
![Example 10.8 Testing the Steady-State Approximation. ⊕ a B C C a B C P + → → + → D Dt K K K K K K [ ]](https://docslib.b-cdn.net/cover/6323/example-10-8-testing-the-steady-state-approximation-a-b-c-c-a-b-c-p-d-dt-k-k-k-k-k-k-156323.webp)
Example 10.8 Testing the Steady-State Approximation. ⊕ a B C C a B C P + → → + → D Dt K K K K K K [ ]
Example 10.8 Testing the steady-state approximation. Å The steady-state approximation contains an apparent contradiction: we set the time derivative of the concentration of some species (a reaction intermediate) equal to zero — implying that it is a constant — and then derive a formula showing how it changes with time. Actually, there is no contradiction since all that is required it that the rate of change of the "steady" species be small compared to the rate of reaction (as measured by the rate of disappearance of the reactant or appearance of the product). But exactly when (in a practical sense) is this approximation appropriate? It is often applied as a matter of convenience and justified ex post facto — that is, if the resulting rate law fits the data then the approximation is considered justified. But as this example demonstrates, such reasoning is dangerous and possible erroneous. We examine the mechanism A + B ¾¾1® C C ¾¾2® A + B (10.12) 3 C® P (Note that the second reaction is the reverse of the first, so we have a reversible second-order reaction followed by an irreversible first-order reaction.) The rate constants are k1 for the forward reaction of the first step, k2 for the reverse of the first step, and k3 for the second step. This mechanism is readily solved for with the steady-state approximation to give d[A] k1k3 = - ke[A][B] with ke = (10.13) dt k2 + k3 (TEXT Eq. (10.38)). With initial concentrations of A and B equal, hence [A] = [B] for all times, this equation integrates to 1 1 = + ket (10.14) [A] A0 where A0 is the initial concentration (equal to 1 in work to follow). -

Differentiation Rules (Differential Calculus)
Differentiation Rules (Differential Calculus) 1. Notation The derivative of a function f with respect to one independent variable (usually x or t) is a function that will be denoted by D f . Note that f (x) and (D f )(x) are the values of these functions at x. 2. Alternate Notations for (D f )(x) d d f (x) d f 0 (1) For functions f in one variable, x, alternate notations are: Dx f (x), dx f (x), dx , dx (x), f (x), f (x). The “(x)” part might be dropped although technically this changes the meaning: f is the name of a function, dy 0 whereas f (x) is the value of it at x. If y = f (x), then Dxy, dx , y , etc. can be used. If the variable t represents time then Dt f can be written f˙. The differential, “d f ”, and the change in f ,“D f ”, are related to the derivative but have special meanings and are never used to indicate ordinary differentiation. dy 0 Historical note: Newton used y,˙ while Leibniz used dx . About a century later Lagrange introduced y and Arbogast introduced the operator notation D. 3. Domains The domain of D f is always a subset of the domain of f . The conventional domain of f , if f (x) is given by an algebraic expression, is all values of x for which the expression is defined and results in a real number. If f has the conventional domain, then D f usually, but not always, has conventional domain. Exceptions are noted below. -
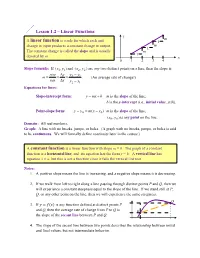
Lesson 1.2 – Linear Functions Y M a Linear Function Is a Rule for Which Each Unit 1 Change in Input Produces a Constant Change in Output
Lesson 1.2 – Linear Functions y m A linear function is a rule for which each unit 1 change in input produces a constant change in output. m 1 The constant change is called the slope and is usually m 1 denoted by m. x 0 1 2 3 4 Slope formula: If (x1, y1)and (x2 , y2 ) are any two distinct points on a line, then the slope is rise y y y m 2 1 . (An average rate of change!) run x x x 2 1 Equations for lines: Slope-intercept form: y mx b m is the slope of the line; b is the y-intercept (i.e., initial value, y(0)). Point-slope form: y y0 m(x x0 ) m is the slope of the line; (x0, y0 ) is any point on the line. Domain: All real numbers. Graph: A line with no breaks, jumps, or holes. (A graph with no breaks, jumps, or holes is said to be continuous. We will formally define continuity later in the course.) A constant function is a linear function with slope m = 0. The graph of a constant function is a horizontal line, and its equation has the form y = b. A vertical line has equation x = a, but this is not a function since it fails the vertical line test. Notes: 1. A positive slope means the line is increasing, and a negative slope means it is decreasing. 2. If we walk from left to right along a line passing through distinct points P and Q, then we will experience a constant steepness equal to the slope of the line. -

PLEASANTON UNIFIED SCHOOL DISTRICT Math 8/Algebra I Course Outline Form Course Title
PLEASANTON UNIFIED SCHOOL DISTRICT Math 8/Algebra I Course Outline Form Course Title: Math 8/Algebra I Course Number/CBED Number: Grade Level: 8 Length of Course: 1 year Credit: 10 Meets Graduation Requirements: n/a Required for Graduation: Prerequisite: Math 6/7 or Math 7 Course Description: Main concepts from the CCSS 8th grade content standards include: knowing that there are numbers that are not rational, and approximate them by rational numbers; working with radicals and integer exponents; understanding the connections between proportional relationships, lines, and linear equations; analyzing and solving linear equations and pairs of simultaneous linear equations; defining, evaluating, and comparing functions; using functions to model relationships between quantities; understanding congruence and similarity using physical models, transparencies, or geometry software; understanding and applying the Pythagorean Theorem; investigating patterns of association in bivariate data. Algebra (CCSS Algebra) main concepts include: reason quantitatively and use units to solve problems; create equations that describe numbers or relationships; understanding solving equations as a process of reasoning and explain reasoning; solve equations and inequalities in one variable; solve systems of equations; represent and solve equations and inequalities graphically; extend the properties of exponents to rational exponents; use properties of rational and irrational numbers; analyze and solve linear equations and pairs of simultaneous linear equations; define, -

The Exponential Constant E
The exponential constant e mc-bus-expconstant-2009-1 Introduction The letter e is used in many mathematical calculations to stand for a particular number known as the exponential constant. This leaflet provides information about this important constant, and the related exponential function. The exponential constant The exponential constant is an important mathematical constant and is given the symbol e. Its value is approximately 2.718. It has been found that this value occurs so frequently when mathematics is used to model physical and economic phenomena that it is convenient to write simply e. It is often necessary to work out powers of this constant, such as e2, e3 and so on. Your scientific calculator will be programmed to do this already. You should check that you can use your calculator to do this. Look for a button marked ex, and check that e2 =7.389, and e3 = 20.086 In both cases we have quoted the answer to three decimal places although your calculator will give a more accurate answer than this. You should also check that you can evaluate negative and fractional powers of e such as e1/2 =1.649 and e−2 =0.135 The exponential function If we write y = ex we can calculate the value of y as we vary x. Values obtained in this way can be placed in a table. For example: x −3 −2 −1 01 2 3 y = ex 0.050 0.135 0.368 1 2.718 7.389 20.086 This is a table of values of the exponential function ex. -

The Linear Algebra Version of the Chain Rule 1
Ralph M Kaufmann The Linear Algebra Version of the Chain Rule 1 Idea The differential of a differentiable function at a point gives a good linear approximation of the function – by definition. This means that locally one can just regard linear functions. The algebra of linear functions is best described in terms of linear algebra, i.e. vectors and matrices. Now, in terms of matrices the concatenation of linear functions is the matrix product. Putting these observations together gives the formulation of the chain rule as the Theorem that the linearization of the concatenations of two functions at a point is given by the concatenation of the respective linearizations. Or in other words that matrix describing the linearization of the concatenation is the product of the two matrices describing the linearizations of the two functions. 1. Linear Maps Let V n be the space of n–dimensional vectors. 1.1. Definition. A linear map F : V n → V m is a rule that associates to each n–dimensional vector ~x = hx1, . xni an m–dimensional vector F (~x) = ~y = hy1, . , yni = hf1(~x),..., (fm(~x))i in such a way that: 1) For c ∈ R : F (c~x) = cF (~x) 2) For any two n–dimensional vectors ~x and ~x0: F (~x + ~x0) = F (~x) + F (~x0) If m = 1 such a map is called a linear function. Note that the component functions f1, . , fm are all linear functions. 1.2. Examples. 1) m=1, n=3: all linear functions are of the form y = ax1 + bx2 + cx3 for some a, b, c ∈ R. -

9 Power and Polynomial Functions
Arkansas Tech University MATH 2243: Business Calculus Dr. Marcel B. Finan 9 Power and Polynomial Functions A function f(x) is a power function of x if there is a constant k such that f(x) = kxn If n > 0, then we say that f(x) is proportional to the nth power of x: If n < 0 then f(x) is said to be inversely proportional to the nth power of x. We call k the constant of proportionality. Example 9.1 (a) The strength, S, of a beam is proportional to the square of its thickness, h: Write a formula for S in terms of h: (b) The gravitational force, F; between two bodies is inversely proportional to the square of the distance d between them. Write a formula for F in terms of d: Solution. 2 k (a) S = kh ; where k > 0: (b) F = d2 ; k > 0: A power function f(x) = kxn , with n a positive integer, is called a mono- mial function. A polynomial function is a sum of several monomial func- tions. Typically, a polynomial function is a function of the form n n−1 f(x) = anx + an−1x + ··· + a1x + a0; an 6= 0 where an; an−1; ··· ; a1; a0 are all real numbers, called the coefficients of f(x): The number n is a non-negative integer. It is called the degree of the polynomial. A polynomial of degree zero is just a constant function. A polynomial of degree one is a linear function, of degree two a quadratic function, etc. The number an is called the leading coefficient and a0 is called the constant term. -

Polynomials.Pdf
POLYNOMIALS James T. Smith San Francisco State University For any real coefficients a0,a1,...,an with n $ 0 and an =' 0, the function p defined by setting n p(x) = a0 + a1 x + AAA + an x for all real x is called a real polynomial of degree n. Often, we write n = degree p and call an its leading coefficient. The constant function with value zero is regarded as a real polynomial of degree –1. For each n the set of all polynomials with degree # n is closed under addition, subtraction, and multiplication by scalars. The algebra of polynomials of degree # 0 —the constant functions—is the same as that of real num- bers, and you need not distinguish between those concepts. Polynomials of degrees 1 and 2 are called linear and quadratic. Polynomial multiplication Suppose f and g are nonzero polynomials of degrees m and n: m f (x) = a0 + a1 x + AAA + am x & am =' 0, n g(x) = b0 + b1 x + AAA + bn x & bn =' 0. Their product fg is a nonzero polynomial of degree m + n: m+n f (x) g(x) = a 0 b 0 + AAA + a m bn x & a m bn =' 0. From this you can deduce the cancellation law: if f, g, and h are polynomials, f =' 0, and fg = f h, then g = h. For then you have 0 = fg – f h = f ( g – h), hence g – h = 0. Note the analogy between this wording of the cancellation law and the corresponding fact about multiplication of numbers. One of the most useful results about integer multiplication is the unique factoriza- tion theorem: for every integer f > 1 there exist primes p1 ,..., pm and integers e1 em e1 ,...,em > 0 such that f = pp1 " m ; the set consisting of all pairs <pk , ek > is unique. -

Characterization of Non-Differentiable Points in a Function by Fractional Derivative of Jumarrie Type
Characterization of non-differentiable points in a function by Fractional derivative of Jumarrie type Uttam Ghosh (1), Srijan Sengupta(2), Susmita Sarkar (2), Shantanu Das (3) (1): Department of Mathematics, Nabadwip Vidyasagar College, Nabadwip, Nadia, West Bengal, India; Email: [email protected] (2):Department of Applied Mathematics, Calcutta University, Kolkata, India Email: [email protected] (3)Scientist H+, RCSDS, BARC Mumbai India Senior Research Professor, Dept. of Physics, Jadavpur University Kolkata Adjunct Professor. DIAT-Pune Ex-UGC Visiting Fellow Dept. of Applied Mathematics, Calcutta University, Kolkata India Email (3): [email protected] The Birth of fractional calculus from the question raised in the year 1695 by Marquis de L'Hopital to Gottfried Wilhelm Leibniz, which sought the meaning of Leibniz's notation for the derivative of order N when N = 1/2. Leibnitz responses it is an apparent paradox from which one day useful consequences will be drown. Abstract There are many functions which are continuous everywhere but not differentiable at some points, like in physical systems of ECG, EEG plots, and cracks pattern and for several other phenomena. Using classical calculus those functions cannot be characterized-especially at the non- differentiable points. To characterize those functions the concept of Fractional Derivative is used. From the analysis it is established that though those functions are unreachable at the non- differentiable points, in classical sense but can be characterized using Fractional derivative. In this paper we demonstrate use of modified Riemann-Liouvelli derivative by Jumarrie to calculate the fractional derivatives of the non-differentiable points of a function, which may be one step to characterize and distinguish and compare several non-differentiable points in a system or across the systems. -
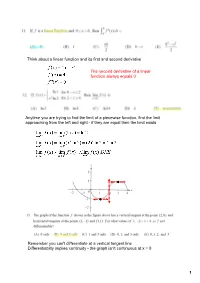
1 Think About a Linear Function and Its First and Second Derivative The
Think about a linear function and its first and second derivative The second derivative of a linear function always equals 0 Anytime you are trying to find the limit of a piecewise function, find the limit approaching from the left and right if they are equal then the limit exists Remember you can't differentiate at a vertical tangent line Differentiabilty implies continuity the graph isn't continuous at x = 0 1 To find the velocity, take the first derivative of the position function. To find where the velocity equals zero, set the first derivative equal to zero 2 From the graph, we know that f (1) = 0; Since the graph is increasing, we know that f '(1) is positive; since the graph is concave down, we know that f ''(1) is negative Possible points of inflection need to set up a table to see where concavity changes (that verifies points of inflection) (∞, 1) (1, 0) (0, 2) (2, ∞) + + + concave up concave down concave up concave up Since the concavity changes when x = 1 and when x = 0, they are points of inflection. x = 2 is not a point of inflection 3 We need to find the derivative, find the critical numbers and use them in the first derivative test to find where f (x) is increasing and decreasing (∞, 0) (0, ∞) + Decreasing Increasing 4 This is the graph of y = cos x, shifted right (A) and (C) are the only graphs of sin x, and (A) is the graph of sin x, which reflects across the xaxis 5 Take the derivative of the velocity function to find the acceleration function There are no critical numbers, because v '(t) doesn't ever equal zero (you can verify this by graphing v '(t) there are no xintercepts). -

1. Antiderivatives for Exponential Functions Recall That for F(X) = Ec⋅X, F ′(X) = C ⋅ Ec⋅X (For Any Constant C)
1. Antiderivatives for exponential functions Recall that for f(x) = ec⋅x, f ′(x) = c ⋅ ec⋅x (for any constant c). That is, ex is its own derivative. So it makes sense that it is its own antiderivative as well! Theorem 1.1 (Antiderivatives of exponential functions). Let f(x) = ec⋅x for some 1 constant c. Then F x ec⋅c D, for any constant D, is an antiderivative of ( ) = c + f(x). 1 c⋅x ′ 1 c⋅x c⋅x Proof. Consider F (x) = c e +D. Then by the chain rule, F (x) = c⋅ c e +0 = e . So F (x) is an antiderivative of f(x). Of course, the theorem does not work for c = 0, but then we would have that f(x) = e0 = 1, which is constant. By the power rule, an antiderivative would be F (x) = x + C for some constant C. 1 2. Antiderivative for f(x) = x We have the power rule for antiderivatives, but it does not work for f(x) = x−1. 1 However, we know that the derivative of ln(x) is x . So it makes sense that the 1 antiderivative of x should be ln(x). Unfortunately, it is not. But it is close. 1 1 Theorem 2.1 (Antiderivative of f(x) = x ). Let f(x) = x . Then the antiderivatives of f(x) are of the form F (x) = ln(SxS) + C. Proof. Notice that ln(x) for x > 0 F (x) = ln(SxS) = . ln(−x) for x < 0 ′ 1 For x > 0, we have [ln(x)] = x .