The Architecture and Implementation of an Extensible Web Crawler
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IJIMAI20163 6.Pdf
INTERNATIONAL JOURNAL OF INTERACTIVE MULTIMEDIA AND ARTIFICIAL INTELLIGENCE ISSN: 1989-1660–VOL. III, NUMBER 6 IMAI RESEARCH GROUP COUNCIL Executive Director - Dr. Jesús Soto Carrión, Pontifical University of Salamanca, Spain Research Director - Dr. Rubén González Crespo, Universidad Internacional de La Rioja - UNIR, Spain Financial Director - Dr. Oscar Sanjuán Martínez, ElasticBox, USA Office of Publications Director - Lic. Ainhoa Puente, Universidad Internacional de La Rioja - UNIR, Spain Director, Latin-America regional board - Dr. Carlos Enrique Montenegro Marín, Francisco José de Caldas District University, Colombia EDITORIAL TEAM Editor-in-Chief Dr. Rubén González Crespo, Universidad Internacional de La Rioja – UNIR, Spain Associate Editors Dr. Jordán Pascual Espada, ElasticBox, USA Dr. Juan Pavón Mestras, Complutense University of Madrid, Spain Dr. Alvaro Rocha, University of Coimbra, Portugal Dr. Jörg Thomaschewski, Hochschule Emden/Leer, Emden, Germany Dr. Carlos Enrique Montenegro Marín, Francisco José de Caldas District University, Colombia Dr. Vijay Bhaskar Semwal, Indian Institute of Technology, Allahabad, India Editorial Board Members Dr. Rory McGreal, Athabasca University, Canada Dr. Abelardo Pardo, University of Sidney, Australia Dr. Hernán Sasastegui Chigne, UPAO, Perú Dr. Lei Shu, Osaka University, Japan Dr. León Welicki, Microsoft, USA Dr. Enrique Herrera, University of Granada, Spain Dr. Francisco Chiclana, De Montfort University, United Kingdom Dr. Luis Joyanes Aguilar, Pontifical University of Salamanca, Spain Dr. Ioannis Konstantinos Argyros, Cameron University, USA Dr. Juan Manuel Cueva Lovelle, University of Oviedo, Spain Dr. Pekka Siirtola, University of Oulu, Finland Dr. Francisco Mochón Morcillo, National Distance Education University, Spain Dr. Manuel Pérez Cota, University of Vigo, Spain Dr. Walter Colombo, Hochschule Emden/Leer, Emden, Germany Dr. Javier Bajo Pérez, Polytechnic University of Madrid, Spain Dr. -
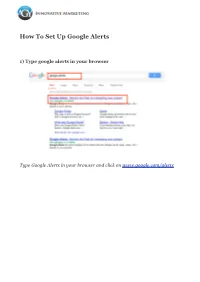
How to Set up Google Alerts
How To Set Up Google Alerts 1) Type google alerts in your browser Type Google Alerts in your browser and click on www.google.com/alerts 2) Set up your alerts In Search Query put in the topics you want google to source out for you. It might be of interest to have your name, your company domain, competitors domains, keywords you'd like to source information about or whatever you'd like to research. Enter the email address you want the alerts to go to. 3) Verify your alert Login into your email address that the alert is going to and verify it by clicking on the link. 4) Set up folders/labels so alerts skip your inbox (we will use Gmail for this example) 1) Tick the alerts that have come to your inbox. 2) Click on More, in the drop down menu choose 'Filter messages like these' 5) Create filter 1) Just click on 'create filter with this search' 6) Applying label/folder for alert to skip inbox. (Gmail calls folders labels, you can set them up under 'settings', 'labels'. 1) Tick skip the inbox (helps keep your inbox free) 2) Tick apply label 3) Choose what label (Here we have called it Alerts) 4) Tick to apply other alerts if found any 5) Create filter This is one easy way for information you are interested in to come to you. By setting up Alert Folders or Labels as Gmail calls them, they won't clog up your inbox, keeping it clear and leaving you to your choosing when you want to check your alerts for any useful information. -

Building a Scalable Index and a Web Search Engine for Music on the Internet Using Open Source Software
Department of Information Science and Technology Building a Scalable Index and a Web Search Engine for Music on the Internet using Open Source software André Parreira Ricardo Thesis submitted in partial fulfillment of the requirements for the degree of Master in Computer Science and Business Management Advisor: Professor Carlos Serrão, Assistant Professor, ISCTE-IUL September, 2010 Acknowledgments I should say that I feel grateful for doing a thesis linked to music, an art which I love and esteem so much. Therefore, I would like to take a moment to thank all the persons who made my accomplishment possible and hence this is also part of their deed too. To my family, first for having instigated in me the curiosity to read, to know, to think and go further. And secondly for allowing me to continue my studies, providing the environment and the financial means to make it possible. To my classmate André Guerreiro, I would like to thank the invaluable brainstorming, the patience and the help through our college years. To my friend Isabel Silva, who gave me a precious help in the final revision of this document. Everyone in ADETTI-IUL for the time and the attention they gave me. Especially the people over Caixa Mágica, because I truly value the expertise transmitted, which was useful to my thesis and I am sure will also help me during my professional course. To my teacher and MSc. advisor, Professor Carlos Serrão, for embracing my will to master in this area and for being always available to help me when I needed some advice. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

Efficient Focused Web Crawling Approach for Search Engine
Ayar Pranav et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.5, May- 2015, pg. 545-551 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IJCSMC, Vol. 4, Issue. 5, May 2015, pg.545 – 551 RESEARCH ARTICLE Efficient Focused Web Crawling Approach for Search Engine 1 2 Ayar Pranav , Sandip Chauhan Computer & Science Engineering, Kalol Institute of Technology and Research Canter, Kalol, Gujarat, India 1 [email protected]; 2 [email protected] Abstract— a focused crawler traverses the web, selecting out relevant pages to a predefined topic and neglecting those out of concern. Collecting domain specific documents using focused crawlers has been considered one of most important strategies to find relevant information. While surfing the internet, it is difficult to deal with irrelevant pages and to predict which links lead to quality pages. However most focused crawler use local search algorithm to traverse the web space, but they could easily trapped within limited a sub graph of the web that surrounds the starting URLs also there is problem related to relevant pages that are miss when no links from the starting URLs. There is some relevant pages are miss. To address this problem we design a focused crawler where calculating the frequency of the topic keyword also calculate the synonyms and sub synonyms of the keyword. The weight table is constructed according to the user query. To check the similarity of web pages with respect to topic keywords and priority of extracted link is calculated. -

Distributed Indexing/Searching Workshop Agenda, Attendee List, and Position Papers
Distributed Indexing/Searching Workshop Agenda, Attendee List, and Position Papers Held May 28-19, 1996 in Cambridge, Massachusetts Sponsored by the World Wide Web Consortium Workshop co-chairs: Michael Schwartz, @Home Network Mic Bowman, Transarc Corp. This workshop brings together a cross-section of people concerned with distributed indexing and searching, to explore areas of common concern where standards might be defined. The Call For Participation1 suggested particular focus on repository interfaces that support efficient and powerful distributed indexing and searching. There was a great deal of interest in this workshop. Because of our desire to limit attendance to a workable size group while maximizing breadth of attendee backgrounds, we limited attendance to one person per position paper, and furthermore we limited attendance to one person per institution. In some cases, attendees submitted multiple position papers, with the intention of discussing each of their projects or ideas that were relevant to the workshop. We had not anticipated this interpretation of the Call For Participation; our intention was to use the position papers to select participants, not to provide a forum for enumerating ideas and projects. As a compromise, we decided to choose among the submitted papers and allow multiple position papers per person and per institution, but to restrict attendance as noted above. Hence, in the paper list below there are some cases where one author or institution has multiple position papers. 1 http://www.w3.org/pub/WWW/Search/960528/cfp.html 1 Agenda The Distributed Indexing/Searching Workshop will span two days. The first day's goal is to identify areas for potential standardization through several directed discussion sessions. -

Natural Language Processing Technique for Information Extraction and Analysis
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 2, Issue 8, August 2015, PP 32-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Natural Language Processing Technique for Information Extraction and Analysis T. Sri Sravya1, T. Sudha2, M. Soumya Harika3 1 M.Tech (C.S.E) Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 2 Head (I/C) of C.S.E & IT Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 3 M. Tech C.S.E, Assistant Professor, Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] Abstract: In the current internet era, there are a large number of systems and sensors which generate data continuously and inform users about their status and the status of devices and surroundings they monitor. Examples include web cameras at traffic intersections, key government installations etc., seismic activity measurement sensors, tsunami early warning systems and many others. A Natural Language Processing based activity, the current project is aimed at extracting entities from data collected from various sources such as social media, internet news articles and other websites and integrating this data into contextual information, providing visualization of this data on a map and further performing co-reference analysis to establish linkage amongst the entities. Keywords: Apache Nutch, Solr, crawling, indexing 1. INTRODUCTION In today’s harsh global business arena, the pace of events has increased rapidly, with technological innovations occurring at ever-increasing speed and considerably shorter life cycles. -

An Ontology-Based Web Crawling Approach for the Retrieval of Materials in the Educational Domain
An Ontology-based Web Crawling Approach for the Retrieval of Materials in the Educational Domain Mohammed Ibrahim1 a and Yanyan Yang2 b 1School of Engineering, University of Portsmouth, Anglesea Road, PO1 3DJ, Portsmouth, United Kingdom 2School of Computing, University of Portsmouth, Anglesea Road, PO1 3DJ, Portsmouth, United Kingdom Keywords: Web Crawling, Ontology, Education Domain. Abstract: As the web continues to be a huge source of information for various domains, the information available is rapidly increasing. Most of this information is stored in unstructured databases and therefore searching for relevant information becomes a complex task and the search for pertinent information within a specific domain is time-consuming and, in all probability, results in irrelevant information being retrieved. Crawling and downloading pages that are related to the user’s enquiries alone is a tedious activity. In particular, crawlers focus on converting unstructured data and sorting this into a structured database. In this paper, among others kind of crawling, we focus on those techniques that extract the content of a web page based on the relations of ontology concepts. Ontology is a promising technique by which to access and crawl only related data within specific web pages or a domain. The methodology proposed is a Web Crawler approach based on Ontology (WCO) which defines several relevance computation strategies with increased efficiency thereby reducing the number of extracted items in addition to the crawling time. It seeks to select and search out web pages in the education domain that matches the user’s requirements. In WCO, data is structured based on the hierarchical relationship, the concepts which are adapted in the ontology domain. -

A Hadoop Based Platform for Natural Language Processing of Web Pages and Documents
Journal of Visual Languages and Computing 31 (2015) 130–138 Contents lists available at ScienceDirect Journal of Visual Languages and Computing journal homepage: www.elsevier.com/locate/jvlc A hadoop based platform for natural language processing of web pages and documents Paolo Nesi n,1, Gianni Pantaleo 1, Gianmarco Sanesi 1 Distributed Systems and Internet Technology Lab, DISIT Lab, Department of Information Engineering (DINFO), University of Florence, Firenze, Italy article info abstract Available online 30 October 2015 The rapid and extensive pervasion of information through the web has enhanced the Keywords: diffusion of a huge amount of unstructured natural language textual resources. A great Natural language processing interest has arisen in the last decade for discovering, accessing and sharing such a vast Hadoop source of knowledge. For this reason, processing very large data volumes in a reasonable Part-of-speech tagging time frame is becoming a major challenge and a crucial requirement for many commercial Text parsing and research fields. Distributed systems, computer clusters and parallel computing Web crawling paradigms have been increasingly applied in the recent years, since they introduced Big Data Mining significant improvements for computing performance in data-intensive contexts, such as Parallel computing Big Data mining and analysis. Natural Language Processing, and particularly the tasks of Distributed systems text annotation and key feature extraction, is an application area with high computational requirements; therefore, these tasks can significantly benefit of parallel architectures. This paper presents a distributed framework for crawling web documents and running Natural Language Processing tasks in a parallel fashion. The system is based on the Apache Hadoop ecosystem and its parallel programming paradigm, called MapReduce. -

3. Internet – Participating in the Knowledge Society
3. Internet – Participating in the knowledge society “Knowledge is power. Information is liberating. Education is the premise of progress, in every society, in every family.” Kofi Annan, former Secretary General of the United Nations, January 1997-December 2006 CHECKLIST FACT SHEET 10 – SEARCHING FOR INFORMATION Do you read the disclaimer when you are consulting a website? How can you be sure the information you find is factual and objective? Do you consult several websites to check your facts? CHECKLIST FACT SHEET 11 – FINDING QUALITY INFORMATION ON THE WEB Before downloading files, do you check that your anti-virus software is active? If you get your news from the Internet, do you seek multiple perspectives on the same story? Clean out your cookies from time to time to avoid being “profiled” by search engines. CHECKLIST FACT SHEET 12 – DISTANCE LEARNING AND MOOCs Choose a method of distance learning that is appropriate for you: determine what type of learning (synchronous, asynchronous, open schedule, hybrid distance learning) will best help you reach your goals. Before selecting a distance learning course, research the reviews – both from students and teachers. Take adequate precautions to ensure that your computer equipment and software is secure from hackers, viruses and other threats. CHECKLIST FACT SHEET 13 – SHOPPING ONLINE Do not make online purchases on unsecure Internet connections. Understand and agree to the key information provided about the product or service. Disable in-app purchases on your smartphone or tablet. Do not believe all user recommendations you see, creating “user” recommendations can also be a money-making business. Fact sheet 11 Finding quality information on the Web he original idea behind the creation of the Internet1 was to develop an electronic library for the Teasy access and distribution of information2. -

Curlcrawler:A Framework of Curlcrawler and Cached Database for Crawling the Web with Thumb
Ela Kumaret al, / (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 2 (4) , 2011, 1700-1705 CurlCrawler:A framework of CurlCrawler and Cached Database for crawling the web with thumb. Dr Ela Kumar#,Ashok Kumar$ # School of Information and Communication Technology, Gautam Buddha University, Greater Noida $ AIM & ACT.Banasthali University,Banasthali(Rajasthan.) Abstract-WWW is a vast source of information and search engines about basic modules of search engine functioning and these are the meshwork to navigate the web for several purposes. It is essential modules are (see Fig.1)[9,10]. problematic to identify and ping with graphical frame of mind for the desired information amongst the large set of web pages resulted by the search engine. With further increase in the size of the Internet, the problem grows exponentially. This paper is an endeavor to develop and implement an efficient framework with multi search agents to make search engines inapt to chaffing using curl features of the programming, called CurlCrawler. This work is an implementation experience for use of graphical perception to upright search on the web. Main features of this framework are curl programming, personalization of information, caching and graphical perception. Keywords and Phrases-Indexing Agent, Filtering Agent, Interacting Agent, Seolinktool, Thumb, Whois, CachedDatabase, IECapture, Searchcon, Main_spider, apnasearchdb. 1. INTRODUCTION Information is a vital role playing versatile thing from availability at church level to web through trends of books. WWW is now the prominent and up-to-date huge repository of information available to everyone, everywhere and every time. Moreover information on web is navigated using search Fig.1: Components of Information Retrieval System engines like AltaVista, WebCrawler, Hot Boat etc[1].Amount of information on the web is growing at very fast and owing to this search engine’s optimized functioning is always a thrust Store: It stores the crawled pages. -

Efficient Monitoring Algorithm for Fast News Alerts
1 Efficient Monitoring Algorithm for Fast News Alerts Ka Cheung Sia, Junghoo Cho, and Hyun-Kyu Cho Abstract— Recently, there has been a dramatic increase in and its appearance at the aggregator? Note that the aggregation the use of XML data to deliver information over the Web. can be done either at a desktop (e.g., RSS feed readers) or at Personal weblogs, news Web sites, and discussion forums are a central server (e.g., Personalized Yahoo/Google homepage). now publishing RSS feeds for their subscribers to retrieve new postings. As the popularity of personal weblogs and the RSS While some of our developed techniques can be applied to the feeds grow rapidly, RSS aggregation services and blog search desktop-based aggregation, in this paper we primarily focus on engines have appeared, which try to provide a central access the server-based aggregation scenario. This problem is similar point for simpler access and discovery of new content from a to the index refresh problem for Web-search engines [7], [9], large number of diverse RSS sources. In this paper, we study how [11], [13], [15], [30], [31], [40], but two important properties the RSS aggregation services should monitor the data sources to retrieve new content quickly using minimal resources and to of the information in the RSS domain make this problem provide its subscribers with fast news alerts. We believe that unique and interesting: the change characteristics of RSS sources and the general user • The information in the RSS domain is often time sensi- access behavior pose distinct requirements that make this task significantly different from the traditional index refresh problem tive.