TIFF File Format Summary
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring the .BMP File Format
Exploring the .BMP File Format Don Lancaster Synergetics, Box 809, Thatcher, AZ 85552 copyright c2003 as GuruGram #14 http://www.tinaja.com [email protected] (928) 428-4073 The .BMP image standard is used by Windows and elsewhere to represent graphics images in any of several different display and compression options. The .BMP advantages are that each pixel is usually independently available for any alteration or modification. And that repeated use does not normally degrade the image. Because lossy compression is not used. Its main disadvantage is that file sizes are usually horrendous compared to JPEG, fractal, GIF, or other lossy compression schemes. A comparison of popular image standards can be found here. I’ve long been using the .BMP format for my eBay and my other phototography, scanning, and post processing. I firmly believe that… All photography, scanning, and all image post-processing should always be done using .BMP or a similar non-lossy format. Only after all post-processing is complete should JPEG or another compressed distribution format be chosen. Some current examples of my .BMP work now do include the IMAGIMAG.PDF post-processing tutorial, the Bitmap Typewriterthat generates fully anti-aliased small fonts, the Aerial Photo Combiner, and similar utilities and tutorials found on our Fonts & Images, PostScript, and on our Acrobat library pages. A few projects of current interest involving .BMP files include true view camera swings and tilts for a digital camera, distortion correction, dodging & burning, preventing white punchthrough on knockouts, and emphasis vignetting. Mainly applied to uncompressed RGBX 24-bit color .BMP files. -

PDF/A for Scanned Documents
Webinar www.pdfa.org PDF/A for Scanned Documents Paper Becomes Digital Mark McKinney, LuraTech, Inc., President Armin Ortmann, LuraTech, CTO Mark McKinney President, LuraTech, Inc. © 2009 PDF/A Competence Center, www.pdfa.org Existing Solutions for Scanned Documents www.pdfa.org Black & White: TIFF G4 Color: Mostly JPEG, but sometimes PNG, BMP and other raster graphics formats Often special version formats like “JPEG in TIFF” Disadvantages: Several formats already for scanned documents Even more formats for born digital documents Loss of information, e.g. with TIFF G4 Bad image quality and huge file size, e.g. with JPEG No standardized metadata spread over all formats Not full text searchable (OCR) inside of files Black/White: Color: - TIFF FAX G4 - TIFF - TIFF LZW Mark McKinney - JPEG President, LuraTech, Inc. - PDF 2 Existing Solutions for Scanned Documents www.pdfa.org Bad image quality vs. file size TIFF/BMP JPEG TIFF G4 23.8 MB 180 kB 60 kB Mark McKinney President, LuraTech, Inc. 3 Alternative Solution: PDF www.pdfa.org PDF is already widely used to: Unify file formats Image à PDF “Office” Documents à PDF Other sources à PDF Create full-text searchable files Apply modern compression technology (e.g. the JPEG2000 file formats family) Harmonize metadata Conclusion: PDF avoids the disadvantages of the legacy formats “So if you are already using PDF as archival Mark McKinney format, why not use PDF/A with its many President, LuraTech, Inc. advantages?” 4 PDF/A www.pdfa.org What is PDF/A? • ISO 19005-1, Document Management • Electronic document file format for long-term preservation Goals of PDF/A: • Maintain static visual representation of documents • Consistent handing of Metadata • Option to maintain structure and semantic meaning of content • Transparency to guarantee access • Limit the number of restrictions Mark McKinney President, LuraTech, Inc. -

Free Lossless Image Format
FREE LOSSLESS IMAGE FORMAT Jon Sneyers and Pieter Wuille [email protected] [email protected] Cloudinary Blockstream ICIP 2016, September 26th DON’T WE HAVE ENOUGH IMAGE FORMATS ALREADY? • JPEG, PNG, GIF, WebP, JPEG 2000, JPEG XR, JPEG-LS, JBIG(2), APNG, MNG, BPG, TIFF, BMP, TGA, PCX, PBM/PGM/PPM, PAM, … • Obligatory XKCD comic: YES, BUT… • There are many kinds of images: photographs, medical images, diagrams, plots, maps, line art, paintings, comics, logos, game graphics, textures, rendered scenes, scanned documents, screenshots, … EVERYTHING SUCKS AT SOMETHING • None of the existing formats works well on all kinds of images. • JPEG / JP2 / JXR is great for photographs, but… • PNG / GIF is great for line art, but… • WebP: basically two totally different formats • Lossy WebP: somewhat better than (moz)JPEG • Lossless WebP: somewhat better than PNG • They are both .webp, but you still have to pick the format GOAL: ONE FORMAT THAT COMPRESSES ALL IMAGES WELL EXPERIMENTAL RESULTS Corpus Lossless formats JPEG* (bit depth) FLIF FLIF* WebP BPG PNG PNG* JP2* JXR JLS 100% 90% interlaced PNGs, we used OptiPNG [21]. For BPG we used [4] 8 1.002 1.000 1.234 1.318 1.480 2.108 1.253 1.676 1.242 1.054 0.302 the options -m 9 -e jctvc; for WebP we used -m 6 -q [4] 16 1.017 1.000 / / 1.414 1.502 1.012 2.011 1.111 / / 100. For the other formats we used default lossless options. [5] 8 1.032 1.000 1.099 1.163 1.429 1.664 1.097 1.248 1.500 1.017 0.302� [6] 8 1.003 1.000 1.040 1.081 1.282 1.441 1.074 1.168 1.225 0.980 0.263 Figure 4 shows the results; see [22] for more details. -

TS 101 499 V2.2.1 (2008-07) Technical Specification
ETSI TS 101 499 V2.2.1 (2008-07) Technical Specification Digital Audio Broadcasting (DAB); MOT SlideShow; User Application Specification European Broadcasting Union Union Européenne de Radio-Télévision EBU·UER 2 ETSI TS 101 499 V2.2.1 (2008-07) Reference RTS/JTC-DAB-57 Keywords audio, broadcasting, DAB, digital, PAD ETSI 650 Route des Lucioles F-06921 Sophia Antipolis Cedex - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 Important notice Individual copies of the present document can be downloaded from: http://www.etsi.org The present document may be made available in more than one electronic version or in print. In any case of existing or perceived difference in contents between such versions, the reference version is the Portable Document Format (PDF). In case of dispute, the reference shall be the printing on ETSI printers of the PDF version kept on a specific network drive within ETSI Secretariat. Users of the present document should be aware that the document may be subject to revision or change of status. Information on the current status of this and other ETSI documents is available at http://portal.etsi.org/tb/status/status.asp If you find errors in the present document, please send your comment to one of the following services: http://portal.etsi.org/chaircor/ETSI_support.asp Copyright Notification No part may be reproduced except as authorized by written permission. -
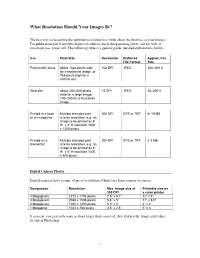
What Resolution Should Your Images Be?
What Resolution Should Your Images Be? The best way to determine the optimum resolution is to think about the final use of your images. For publication you’ll need the highest resolution, for desktop printing lower, and for web or classroom use, lower still. The following table is a general guide; detailed explanations follow. Use Pixel Size Resolution Preferred Approx. File File Format Size Projected in class About 1024 pixels wide 102 DPI JPEG 300–600 K for a horizontal image; or 768 pixels high for a vertical one Web site About 400–600 pixels 72 DPI JPEG 20–200 K wide for a large image; 100–200 for a thumbnail image Printed in a book Multiply intended print 300 DPI EPS or TIFF 6–10 MB or art magazine size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1800 x 1200 pixels. Printed on a Multiply intended print 200 DPI EPS or TIFF 2-3 MB laserwriter size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1200 x 800 pixels. Digital Camera Photos Digital cameras have a range of preset resolutions which vary from camera to camera. Designation Resolution Max. Image size at Printable size on 300 DPI a color printer 4 Megapixels 2272 x 1704 pixels 7.5” x 5.7” 12” x 9” 3 Megapixels 2048 x 1536 pixels 6.8” x 5” 11” x 8.5” 2 Megapixels 1600 x 1200 pixels 5.3” x 4” 6” x 4” 1 Megapixel 1024 x 768 pixels 3.5” x 2.5” 5” x 3 If you can, you generally want to shoot larger than you need, then sharpen the image and reduce its size in Photoshop. -

JPEG File Interchange Format Version 1.02
JPEG File Interchange Format Version 1.02 September 1, 1992 Eric Hamilton C-Cube Microsystems 1778 McCarthy Blvd. Milpitas, CA 95035 +1 408 944-6300 Fax: +1 408 944-6314 E-mail: [email protected] JPEG File Interchange Format Version 1.02 Why a File Interchange Format JPEG File Interchange Format is a minimal file format which enables JPEG bitstreams to be exchanged between a wide variety of platforms and applications. This minimal format does not include any of the advanced features found in the TIFF JPEG specification or any application specific file format. Nor should it, for the only purpose of this simplified format is to allow the exchange of JPEG compressed images. JPEG File Interchange Format features • Uses JPEG compression • Uses JPEG interchange format compressed image representation • PC or Mac or Unix workstation compatible • Standard color space: one or three components. For three components, YCbCr (CCIR 601-256 levels) • APP0 marker used to specify Units, X pixel density, Y pixel density, thumbnail • APP0 marker also used to specify JFIF extensions • APP0 marker also used to specify application-specific information JPEG Compression Although any JPEG process is supported by the syntax of the JPEG File Interchange Format (JFIF) it is strongly recommended that the JPEG baseline process be used for the purposes of file interchange. This ensures maximum compatibility with all applications supporting JPEG. JFIF conforms to the JPEG Draft International Standard (ISO DIS 10918-1). The JPEG File Interchange Format is entirely compatible with the standard JPEG interchange format; the only additional requirement is the mandatory presence of the APP0 marker right after the SOI marker. -
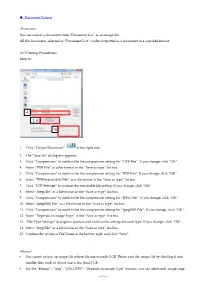
51 Document Output
◆ Document Output <Function> You can output a document from “Document List” as an image file. All the documents selected in “Document List” can be outputted as a document in a specified format. <ICP Setting Procedures> Refer to 4 3, 6 15 1. Click “Output Document” at the right side. 2. The “Save As” dialog box appears. 3. Click “Compression” to confirm the file compression setting for “TIFF File”. If you change, click “OK”. 4. Select “PDF File” as a file format in the “Save as type” list box. 5. Click “Compression” to confirm the file compression setting for “PDF File”. If you change, click “OK”. 6. Select “PDF(Searchable) File” as a file format in the “Save as type” list box. 7. Click “OCR Settings” to confirm the searchable file setting. If you change, click “OK”. 8. Select “Jpeg File” as a file format in the “Save as type” list box. 9. Click “Compression” to confirm the file compression setting for “JPEG File”. If you change, click “OK”. 10. Select “Jpeg2000 File” as a file format in the “Save as type” list box. 11. Click “Compression” to confirm the file compression setting for “Jpeg2000 File”. If you change, click “OK”. 12. Select “Depends on Image Type” in the “Save as type” list box. 13. “File Type Settings” dialog box appears and confirm the settings for each type. If you change, click “OK”. 14. Select “Jpeg File” as a file format in the “Save as type” list box. 15. Confirm the setting of File Name at the bottom right and click “Save”. -

JPEG-Resistant Adversarial Images
JPEG-resistant Adversarial Images Richard Shin Dawn Song Computer Science Division Computer Science Division University of California, Berkeley University of California, Berkeley [email protected] [email protected] Abstract Several papers have explored the use of JPEG compression as a defense against adversarial images [3, 2, 5]. In this work, we show that we can generate adversarial images which survive JPEG compression, by including a differentiable approxima- tion to JPEG in the target model. By ensembling multiple target models employing varying levels of compression, we generate adversarial images with up to 691× greater success rate than the baseline method on a model using JPEG as defense. 1 Introduction Image classification models has been a highly-studied domain for adversarial examples. While adversarial images generated against these models are nevertheless very close to the original image according to L1 or L2 norm, unnatural high-frequency components or random-looking dot patterns are sometimes noticeable. As such, some proposed defenses to adversarial examples involve an initial input transformation step which attempts to remove such unnatural-looking additions. In particular, several papers [3, 2, 5] have proposed and evaluated JPEG compression as a potential method for preventing adversarial images. To summarize, they compress and then decompress an image using JPEG before providing it to the image classification model. Since JPEG is a lossy image compression method designed to preferentially preserve details important to the human visual system, the hope is that JPEG compression will keep the aspects of the image important for classification, but discard any adversarial perturbations. The method is appealingly simple and, according to the previous work, can reduce the attack success rate of adversarial examples. -

Preparation Method for TIFF File (*.Tif) Over 300Dpi
Preparation method for TIFF file (*.tif) over 300dpi Using software with saving function of TIFF file. (e.g. DeltaGraph) 1. Select the figure. 2. On the “File” menu, point to “Export”, and then select “Image”. 3. Click “Option”, and select “Color/Gray-scale”. 4. Select “TIFF” in the “File type” dialog box, and save the file at over “300”dpi. Using Microsoft Excel. A) Using draw type graphics software. (e.g. Illustrator, Canvas, etc.) 1. Select the figure in Excel. 2. Copy the figure and paste into graphics software. 3. On the “File” menu, point to “Save as”, and save the file after select “TIFF (over 300dpi)“ in the “File type” dialog box. Compression “LZW”, “ZIP”, or “JPEG” should be used in compression mode for TIFF file to reduce the file size. B) Simple method Color printing by Excel or PowerPoint graphics 1. Select the figure in Excel or PowerPoint. 2. On the “File” menu, point to “Print”, and select “Microsoft Office Document Image Writer” under “printer”. Click “Properties”, click the “Advanced” tab, and then check “MDI” under “Output format”. 3. Click “OK”、and then close the “Properties”. 4. Click “OK” under “printer” and save the MDI file. 5. Start Windows Explorer. 6. Open the saved MDI file, or right-click of the saved MDI file —in the “Open with” dialog box; click “Microsoft Office Document Imaging”. 7. On the “Tool” menu, point to “Option”. In the “Compression” tab, check “LZW”, and then click “OK”. 8. On the “File” menu, point to “Save as”, and then select “TIFF ” in the “File type” dialog box. -

Understanding Image Formats and When to Use Them
Understanding Image Formats And When to Use Them Are you familiar with the extensions after your images? There are so many image formats that it’s so easy to get confused! File extensions like .jpeg, .bmp, .gif, and more can be seen after an image’s file name. Most of us disregard it, thinking there is no significance regarding these image formats. These are all different and not cross‐ compatible. These image formats have their own pros and cons. They were created for specific, yet different purposes. What’s the difference, and when is each format appropriate to use? Every graphic you see online is an image file. Most everything you see printed on paper, plastic or a t‐shirt came from an image file. These files come in a variety of formats, and each is optimized for a specific use. Using the right type for the right job means your design will come out picture perfect and just how you intended. The wrong format could mean a bad print or a poor web image, a giant download or a missing graphic in an email Most image files fit into one of two general categories—raster files and vector files—and each category has its own specific uses. This breakdown isn’t perfect. For example, certain formats can actually contain elements of both types. But this is a good place to start when thinking about which format to use for your projects. Raster Images Raster images are made up of a set grid of dots called pixels where each pixel is assigned a color. -

GNU MPFR the Multiple Precision Floating-Point Reliable Library Edition 4.1.0 July 2020
GNU MPFR The Multiple Precision Floating-Point Reliable Library Edition 4.1.0 July 2020 The MPFR team [email protected] This manual documents how to install and use the Multiple Precision Floating-Point Reliable Library, version 4.1.0. Copyright 1991, 1993-2020 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back- Cover Texts. A copy of the license is included in Appendix A [GNU Free Documentation License], page 59. i Table of Contents MPFR Copying Conditions ::::::::::::::::::::::::::::::::::::::: 1 1 Introduction to MPFR :::::::::::::::::::::::::::::::::::::::: 2 1.1 How to Use This Manual::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 2 Installing MPFR ::::::::::::::::::::::::::::::::::::::::::::::: 3 2.1 How to Install ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.2 Other `make' Targets :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 2.3 Build Problems :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 2.4 Getting the Latest Version of MPFR ::::::::::::::::::::::::::::::::::::::::::::::: 4 3 Reporting Bugs::::::::::::::::::::::::::::::::::::::::::::::::: 5 4 MPFR Basics ::::::::::::::::::::::::::::::::::::::::::::::::::: 6 4.1 Headers and Libraries :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 6 -

Perl 6 Deep Dive
Perl 6 Deep Dive Data manipulation, concurrency, functional programming, and more Andrew Shitov BIRMINGHAM - MUMBAI Perl 6 Deep Dive Copyright © 2017 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: September 2017 Production reference: 1060917 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78728-204-9 www.packtpub.com Credits Author Copy Editor Andrew Shitov Safis Editing Reviewer Project Coordinator Alex Kapranoff Prajakta Naik Commissioning Editor Proofreader Merint Mathew Safis Editing Acquisition Editor Indexer Chaitanya Nair Francy Puthiry Content Development Editor Graphics Lawrence Veigas Abhinash Sahu Technical Editor Production Coordinator Mehul Singh Nilesh Mohite About the Author Andrew Shitov has been a Perl enthusiast since the end of the 1990s, and is the organizer of over 30 Perl conferences in eight countries.