A Dataset Describing Data Discovery and Reuse Practices in Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2004-2005 Catalog
CENTRAL COLLEGE CATALOG 2004-05 Notice This catalog should not be construed as constituting a formal contract between the college and any person or group of persons. The college retains the right to make changes in the academic and social programs as well as operating procedures. All such changes will be effective at times deemed appropriate by the proper institutional authorities and may apply to enrolled as well as prospective students. For the most current information on Central College, contact: Office of Admission www.central.edu 812 University E-mail [email protected] Pella, IA 50219 Ph. 641-628-5285 Toll free 877-462-3687 2 TABLE OF CONTENTS Academic Calendar 3 Central…Briefly 4 Central College Mission 6 Central History 7 Student Records Notice 7 Admission 8 College Costs 13 Financial Assistance 16 Academic Philosophy 22 Graduation Requirements 23 Academic Policies 26 Academic Divisions & Departments 35 Academic Programs 39 Academic Resources 206 Pre-Professional Programs 207 Co-Op Agreement Programs 208 Special Programs 209 International Education 211 Awards 215 Directories 223 Index 235 3 ACADEMIC CALENDAR 2004-2005 Dates are subject to change. For current calendar information, check out our web site at www.central.edu or call toll-free 1-877-462-3687. August 2004 January 2005 18 New faculty orientation 15-16 New student welcome days 19-20 Faculty workshops 16 Residence halls open 8 a.m. 19-21 New international student orientation 17 Spring semester classes begin 21 New students arrive (Add/Drop Period: Jan. 17-28) 21 Welcome Week begins 17 Martin Luther King, Jr. -

Garrity & Baldwin
BW VOLUME XXXX. CHATSWORTH, ILLINOIS, FRIDAY, AUGUST 15, 1913. NUMBER 47. Here Tresble For H. W. A. Sign Yoar Communication A Dew trouble dow looms up before The editor is in receipt of two com the officers of the M W. A. head munications this week, which are not camp. Attorney Harry M. McCask- published. One is accompanied by a ^>andyj>ressera/aays rin of Rock Island filed with the board note requesting that it be published of review of Rock Island county‘a and neither tbe note nor the article is lij/ns becdl& ehe written petition to be appointed signed. Tbe other was handed in aDd " toean s'foin n in g special prosecutor against the Modern is signed, but tbe writer requested Woodmen in an attempt to collect that his name be omitted, although j taxes which the local man claims are he desired tbe communication publish dothes. 7&e sd l being dodged. He declares in bis ed. statement that “head officers” of the The columns of the Plaindealer are I 'Paa^f clothes society have willfully and maliciously open to anyone, and communications neglected and refused to list for taxa of local interest are gladly published, | dee ctar tion or schedule for .taxation, money but the editor absolutely refuses to -strife* and property in the general and bene publish anything except strictly news, fit fuDd and in the benefit invest unless the writer allows hiB signature READ ment fnnd. He alleges a total of to be attached. In other words, the 111,230,601 79 belonging to th e order is editof of the Plaindealer absolutely BELOW HOW subject to taxation and it was not as refuses to “father” other peoples’ AN OLD: sessed in 1912 and claims that State's opinions and statements and have Attorney Floyd E. -
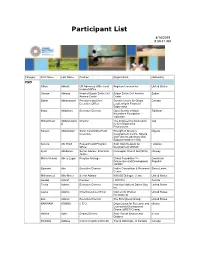
Participant List
Participant List 4/14/2019 8:59:41 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Osman Abbass Head of Sudan Sickle Cell Sudan Sickle Cell Anemia Sudan Anemia Center Center Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Ilhom Abdulloev Executive Director Open Society Institute Tajikistan Assistance Foundation - Tajikistan Mohammed Abdulmawjoo Director The Engineering Association Iraq d for Development & Environment Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Serena Abi Khalil Research and Program Arab NGO Network for Lebanon Officer Development (ANND) Kjetil Abildsnes Senior Adviser, Economic Norwegian Church Aid (NCA) Norway Justice Maria Victoria Abreu Lugar Program Manager Global Foundation for Dominican Democracy and Development Republic (GFDD) Edmond Abu Executive Director Native Consortium & Research Sierra Leone Center Mohammed Abu-Nimer Senior Advisor KAICIID Dialogue Centre United States Aouadi Achraf Founder I WATCH Tunisia Terica Adams Executive Director Hamilton National Dance Day United States Inc. Laurel Adams Chief Executive Officer Women for Women United States International Zoë Adams Executive Director The Strongheart Group United States BAKINAM ADAMU C E O Organization for Research and Ghana Community Development Ghana -

Humour and Irony in Dutch Post-War Fiction Film Framing Film
HUMOUR AND IRONY IN DUTCH POST-WAR FICTION FILM FRAMING FILM FRAMING FILM is a book series dedicated to theoretical and analytical studies in restoration, collection, archival, and exhibition practices in line with the existing archive of EYE Filmmuseum. With this series, Amsterdam University Press and EYE aim to support the academic research community, as well as practitioners in archive and restoration. SERIES EDITORS Giovanna Fossati, EYE Filmmuseum & University of Amsterdam, the Netherlands Leo van Hee, EYE Filmmuseum Frank Kessler, Utrecht University, the Netherlands Patricia Pisters, University of Amsterdam, the Netherlands Dan Streible, New York University, United States Nanna Verhoeff, Utrecht University, the Netherlands EDITORIAL BOARD Richard Abel, University of Michigan, United States Jane Gaines, Columbia University, United States Tom Gunning, University of Chicago, United States Vinzenz Hediger, Goethe University Frankfurt, Germany Martin Koerber, Deutsche Kinemathek, Germany Ann-Sophie Lehmann, University of Groningen, the Netherlands Charles Musser, Yale University, United States Julia Noordegraaf, University of Amsterdam, the Netherlands William Uricchio, Massachusetts Institute of Technology, United States Linda Williams, University of California at Berkeley, United States PETER VERSTRATEN HUMOUR AND IRONY IN DUTCH POST-WAR FICTION FILM AMSTERDAM UNIVERSITY PRESS This publication is made possible by grants from the Nederlands Filmfonds and the Netherlands Society of Cinematographers. Published by EYE Filmmuseum / Amsterdam University Press Cover illustration: Borgman © Drafthouse Films. Design: Brandon Schaefer. Cover design and lay-out: Magenta Ontwerpers, Bussum Amsterdam University Press English-language titles are distributed in the US and Canada by the University of Chicago Press. isbn 978 90 8964 943 0 e-isbn 978 90 4852 837 0 doi 10.5117/9789089649430 nur 670 Creative Commons License CC BY NC ND (http://creativecommons.org/licenses/by-nc-nd/3.0) P. -

2020-2021 Catalog
CENTRAL COLLEGE CO U R S E C ATALO G 2020-21 CENTRAL COLLEGE CATALOG 2020-21 Notice The Central College Catalog contains the most accurate information available at the time of publication. Statements contained herein or on the online version are not contractual obligations, and verbal or other representations that are inconsistent with or not contained within the catalog’s offerings or policies are not binding. Central College reserves the right to change, without specific notice, offerings, policies, procedures, qualifications, fees and other conditions. All such changes will be effective at times deemed appropriate by the proper institutional authorities and may apply to enrolled as well as prospective students. For the most current information on Central College, contact: Office of Admission www.central.edu 812 University E-mail [email protected] Pella, IA 50219 Phone: 641-628-5285 Toll free: 877-462-3687 2020-21 Central College Catalog 3 TABLE OF CONTENTS Academic Calendar 4 Central…Briefly 5 Central History 7 Mission of Central College 7 Student Records Notice 7 Admission 11 College Costs 16 Financial Aid 20 Academic Philosophy 25 Graduation Requirements 27 Academic Policies 29 Academic Programs 40 Academic Major Requirements 44 Course Descriptions 129 Academic Resources 189 Pre-Professional Programs 190 Honors 193 Special Programs 194 Study Abroad at Central College 195 Awards 196 Directories 206 Index 212 4 2020-2021 Central College Catalog 2020-2021 Academic Calendar Dates are subject to change. For current calendar information -

Home Mariadahl. M. Emma W. Ekblad, Coll., B.A., 1926; Aug
1929 1929 Home Mariadahl. m. Emma W. Ekblad, Coll., B.A., 1926; Aug. Sem., B.D., 1929. Aug. Sem., B.D., 1929, S.T.M., 1936; Univ. of RYDING, VERNON E.G., ordained June 9, Walsb~rg, Kan., June 11, 1931,3 children. d. Boxholm, Ia., 1929-40; Alta., 1940-48; asst. Le:ipzig, Germany. Augustana, Minneapolis, 1929, Rockford, Ill. b. Dec. 15, 1901, Nelson, July 8, 1961. Arlington Hills, Minn., 1948-53. m. Agnes Mmn., 1929-32; St. John's, Rock Island, Ill., Minn., Pastor John S. Ryding & Betty S. Erickson, Omaha, Neb., June 22, 1927,2 chil 1932-35; Gloria Dei, St. Paul, Minn., 1935-60· (Sture). Aug. Coll., B.A., 1926; Aug. Sem., DANIELSON, GUSTAF ANTON, ordained dren. d. Mar. 3, 1953. Si~gapore, Missions, 1960-61; St. Peter's: B.D., 1929. Negaunee & Scandia, Mich., June 9 1929, Rockford, Ill. b. Jan. 2, 1896, Mtami, Fla., 1961-62; Tremont, Minneapolis 1929-35; Iron Mt., 1935-41; Saran, Chicago, Spence~, Ia., Carl Danielson & Ada Maria LARSON, ARVID H., ordained June 9, Minn., 1964-67; Fort Snelling Mem. Chapel' Ill., 1941-48; Trinity, Chicago, 1949-69. Vice (Lundbeck). Aug. CoiL, B.A., 1926; Aug. 1929, Rockford, Ill. b. Dec. 19, 1896, Fergus Minneapolis, 1967- . Bds.: Aug. Sem.; G.A: pres. Sup. Conf. m. Grace H. Dahlstrom, Sem., B.D., 1929. Iron. ~t., Mich., 1929-?9; Falls, Minn., Herman & Jennie Larson. Con Coll.; Aug. Book Concern; Minn. Council of Chicago, Ill., 1929, 1 child. regional dir. Home M1sswns, 1939- . V1ee cordia, Minn., B.A., 1924; Aug. Sem., B.D., Churches. -

Dutch Post-War Fiction Film Through a Lens of Psychoanalysis
FRAMING PETER VERSTRATEN FILM DUTCH POST-WAR FICTION PETER VERSTRATEN FILM THROUGH A LENS OF PSYCHOANALYSIS DUTCH POST-WAR FICTION FILM THROUGH A LENS OF PSYCHOANALYSIS Dutch Post-war Fiction Film through a Lens of Psychoanalysis is a DUTCH POST-WAR FICTION FILM POST-WAR DUTCH Peter Verstraten is Assistant THROUGH A LENS OF PSYCHOANALYSIS sequel to Humour and Irony in Dutch Post-war Fiction Film (AUP, Professor of Film and Literary 2016), but the two studies can be read separately. Because of the Studies at Leiden University. sheer variety of Fons Rademakers’ oeuvre, which spans ‘art’ cinema His publications include and cult, genre film and historical epics, each chapter will start with Film Narratology (2009) and one of his titles to introduce a key concept from psychoanalysis. It is Humour and Irony in Dutch an oft-voiced claim that Dutch cinema strongly adheres to realism, Post-war Fiction Film (2016). Together with directors of but this idea is put into perspective by using psychoanalytic theories photography Richard van on desire and fantasy. In the vein of cinephilia, this study brings Oosterhout and Maarten together canonical titles (Als twee druppels water; Soldaat van Oranje) van Rossem, he co-edited and little gems (Monsieur Hawarden; Kracht). It juxtaposes among Shooting Time (2012), a others Gluckauf and De vliegende Hollander (on father figures); volume on cinematography. Flanagan and Spoorloos (on rabbles and heroes); De aanslag and He is a regular contributor to Senses of Cinema. Leedvermaak (on historical traumas); and Antonia and Bluebird (on aphanisis). FRAMING AUP.nl FILM 9789463725330 Eye Filmmuseum DUTCH POST-WAR FICTION FILM THROUGH A LENS OF PSYCHOANALYSIS FRAMING FILM FRAMING FILM is a book series dedicated to theoretical and analytical studies in restoration, collection, archival, and exhibition practices in line with the existing archive of Eye Filmmuseum. -

The Mayfly Newsletter
The Mayfly Newsletter Volume 12 Issue 2 Article 1 5-1-2003 The Mayfly Newsletter Peter M. Grant Southwestern Oklahoma State University, [email protected] Follow this and additional works at: https://dc.swosu.edu/mayfly Recommended Citation Grant, Peter M. (2003) "The Mayfly Newsletter," The Mayfly Newsletter: Vol. 12 : Iss. 2 , Article 1. Available at: https://dc.swosu.edu/mayfly/vol12/iss2/1 This Article is brought to you for free and open access by the Newsletters at SWOSU Digital Commons. It has been accepted for inclusion in The Mayfly Newsletter by an authorized editor of SWOSU Digital Commons. An ADA compliant document is available upon request. For more information, please contact [email protected]. THE MAYFLY NEWSLETTER Vol. 12 No. 2 Southwestern Oklahoma State University, Weatherford, Oklahoma 73096-3098 USA May 2003 Mayfly Diversity in the Headwaters of Brazilian Altitudinal Streams (Serra do Cipo National Park) Michael D. C. Goulart, supervised by Dr. Marcos Callisto, Lab. of Benthic Ecology, Department of General Biology, Institute of Biological Sciences, Federal University of Minas Gerais, Belo Horizonte, MG, Brazil michaeld_03 @ hotmail .com Introduction stereomicroscope, and the identified organisms were Serra do Cipo is located in the central part of the Minas preserved in 70% alcohol and deposited in the Reference Gerais State (19°-20° S; 43°-44° W), the southeastern region Collection of Benthic Macroinvertebrates, Institute of of Espinhatj'o Mountain Chain. The vegetation is composed Biological Sciences, Federal University of Minas Gerais of savanna (locally called “cerrado”) in the lower altitudes (Callisto et al., 1998). The physical and chemical parameters (up to 1000 m), rupestrian fields in the highest portions of the water column were measured “in situ” using a Horiba (above 1000 m) and riparian forest in the humid valleys multiprobe (temperature, pH, electrical conductivity and along the rivers (Giulietti, 2002).