Url Web Monitoring Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Abstract Keywords
Global Journal of Enterprise Information System January -June 2012 Volume-4 Issue-I ABSTRACT Website monitoring is the process of testing and verifying that end-users can interact with a website or web application .Website monitoring is often used by business to ensure that their sites are live and responding. Website MMMonitoringMonitoringonitoring:: Contemporary way to test and verify RajBala Simon KEYWORD S AIIT, Amity University.Noida, India [email protected] Web Monitoring Verify Laxmi Ahuja Test URL AIIT, Amity University. Noida, India [email protected] Theme Based Paper Website Monitoring: Contemporary way to test and verify Page 29 Global Journal of Enterprise Information System January -June 2012 Volume-4 Issue-I page load time of that page is more than 5 seconds, you should be notified through e-mail/SMS/RSS. INTRODUCTION This helps you in taking quick action before it affects Website monitoring is the process of testing and end users. verifying that end-users can interact with a website or web application .Website monitoring is often used by business to ensure that their sites are live and A perfect monitoring provides daily/weekly responding. performance reports through email to know your site’s performance on a daily/weekly basis. Website owner can also view time –based response time The most important online face of your organization reports form ‘Reports’ tab that give them a fair idea is your website. So what damage is caused to your of the performance of their websites over a period of brand and sales when your website is unavailable? time. If they noticed a constant degradation of It may be that your customers cannot perform online performance, then they can take necessary actions transactions and go to your competitors instead. -

Prtg Network Monitor
PRTG NETWORK MONITOR Installed in Seconds. Configured in Minutes. Masters Your Network for Years to Come. PRTG ... proven in more than 150,000 installations worldwide. Network Monitor Easy, failsafe, and complete is ... control over your network. ... ONE SOFTWARE SOLUTION TO MONITOR YOUR ENTIRE NETWORK, INCLUDING DEVICES, APPLICATIONS, ... A SCALABLE ENTERPRISE NETWORK MONITORING? TRAFFIC, AND AVAILABILITY. MONITORING SOLUTION. Network monitoring continuously collects current status information PRTG Network Monitor moni- The PRTG Network Monitor from your IT network to determine the availability and utilization of tors Windows, Linux, Unix, and Enterprise Console supports devices and to measure bandwidth usage. The IT administrator is Mac OS systems. The solution viewing data of multiple PRTG informed immediately via email, text message, or other means if de- supports SNMP, WMI, Flow moni- installations at a glance: It dis- lays, malfunctions, or even failures are recorded. Historically collected toring, as well as packet sniffing, plays aggregate information for all data gives a long-term overview of the overall health and usage of the and monitoring of IPv6 devices. PRTG installations in one single network. program, even in huge setup It offers about 200 pre-built sen- scenarios. Systematic network monitoring helps prevent outages, optimize net- sors specifically designed for QoS works, and improve services: Save time and money! monitoring, website monitoring, This is ideal for enterprises that email monitoring, application need to scale a large number of monitoring, database monitoring, sensors. monitoring of virtual environ- ments, and much more. EASY TO USE WEB INTERFACE The ‘sunburst view‘ shows the status of the whole network on a single screen. -

File Transfer Protocol Mini Project
File Transfer Protocol Mini Project Zacherie feminize alfresco while outstretched Ernesto vesicates haggishly or scrumps barbarously. Sudanese existingand repand and Shaunresolvable always Eugene monopolises overtired authentically quite hereditarily and burble but devolves his metamorphism. her concubine Wanier perchance. Aloysius still inflict: Tanum earth station in an application can you are usually intended for usability reasons, file transfer protocol mini project for all of this section: page of understanding and! Normally goes beyond make have access to view general status codes should be an existing files with dynamicallygenerated html pages can open. Fully correspond to provide control of the solution. Later development on the use the task depends on the functionality of data nodes exchange of os, or personal emails and. This command lines are not likely a byte size and conduct file. Some systems consortium, the file transfers are just simple way that file transfer protocol mini project is open source system, copy of these funs have. The discussion of data transfer of new file management programs communicating data applications do not have record keys: a program written as a basic client. It should be transferred to server is distributed between people who need a series of. Should not have a number of the other flags in web server able to. The build artifacts and demands resources for file transfer protocol mini project. Api management and hides its contents from duplicate files easily implemented in implementations without copying files. The service and its host computers would send requests as file transfer protocol mini project. The desktop widgetsis also required available to a look at marginal cost of data between computers often an experiment in mobile devices, etc by default. -

Copyrighted Material
Index separation of duties and Numbers responsibilities, 626 3DES (Triple DES), 177, 220, 222–223 CIA Triad and, 581–582 802.1X/EAP, 478 compensating control, 583 802.11 standard, 473 corrective control, 583 DAC (Discretionary Access Control), 628, 629 A defense-in-depth, 627–628 detective control, 582–583 AAA services, 8, 11 deterrent control, 583 AACS (Advanced Access Content System), directive control, 583 260 logical control, 584 abstraction, 13, 43 nondiscretionary, 630–635 acceptable use policies, 28 ABAC (Attribute Based Access access abuses, 410–411 Control), 629 access control Attribute Based, 633 administrative control, 583–584 MAC (Mandatory Access Control), assets, 580–581 629, 633–635 attacks, 635–636 RBAC (Role Based Access Control), access aggregation, 641 628, 630–632 asset identification, 637–638 rule-based access control, 628, 632 password attacks, 641–648 permissions, 624 risk elements, 636 physical control, 584 smartcard attacks, 651–652 preventive control, 582 social engineering attacks, privilege creep, 631 649–651 privileges, 625 spoofing attacks, 648 protection methods threat identification, 638–640 account lockout, 653 vulnerability analysis, 640 electronic access, 652 authorization logon notification, 653 access control matrix,COPYRIGHTED 625 MATERIAL multifactor authentication, 652–653 ACL, 625 password hashing, 652 capability tables, 625 password masking, 652 constrained interface, 625–626 password policies, 652 content-dependent control, 626 password salting, 652 context-dependent control, 626 physical access, -

Monitoring Business Critical Web Applications - Need for an Effective Strategy
Site24X7.com Monitoring business critical web applications - Need for an effective strategy White Paper from Site24x7.com Web: www.site24x7.com Table of Contents 1. Executive Summary 2. Overview 3. The Challenge 4. The Solution 5. Site24x7 Web Application Monitoring 6. How Site24x7 meets the challenges? 7. Advantages 8. Conclusion Executive Summary The number of companies using internet as their business platform has increased at an exponential rate in the past decade. Business critical web applications need to be monitored in an objective manner to ensure optimal performance. This paper discusses the challenges faced by busi- nesses in monitoring the performance of their web applications, the need for an effective web application monitoring strategy and the Web Ap- plication Monitoring feature of Site24x7. Web Application Monitor 2 Overview E-Commerce has moved beyond its original conception of a cost-saving tool and is now a standard business tool used widely for creating business opportunities. Industry has shown that many new markets for intangible products are being created around changing patterns of how people work and spend their leisure time. This allows consumers to access services such as buying discount coupons, best buy sales, banking, insurance and travel reservations directly from their homes and businesses. E-commerce is being widely used to develop world wide customers in media, entertainment and communication sectors. Banking, online trading and online money transfer services are some of the businesses that use inter- net for high value transactions. What is the core that ensures the success of a web-based business? The answer is obvious; fast loading and fully functional web applications that can be accessed anywhere around the world, 24x7. -

Identifying Javascript Skimmers on High-Value Websites
Imperial College of Science, Technology and Medicine Department of Computing CO401 - Individual Project MEng Identifying JavaScript Skimmers on High-Value Websites Author: Supervisor: Thomas Bower Dr. Sergio Maffeis Second marker: Dr. Soteris Demetriou June 17, 2019 Identifying JavaScript Skimmers on High-Value Websites Thomas Bower Abstract JavaScript Skimmers are a new type of malware which operate by adding a small piece of code onto a legitimate website in order to exfiltrate private information such as credit card numbers to an attackers server, while also submitting the details to the legitimate site. They are impossible to detect just by looking at the web page since they operate entirely in the background of the normal page operation and display no obvious indicators to their presence. Skimmers entered the public eye in 2018 after a series of high-profile attacks on major retailers including British Airways, Newegg, and Ticketmaster, claiming the credit card details of hundreds of thousands of victims between them. To date, there has been little-to-no work towards preventing websites becoming infected with skimmers, and even less so for protecting consumers. In this document, we propose a novel and effective solution for protecting users from skimming attacks by blocking attempts to contact an attackers server with sensitive information, in the form of a Google Chrome web extension. Our extension takes a two-pronged approach, analysing both the dynamic behaviour of the script such as outgoing requests, as well as static analysis by way of a number of heuristic techniques on scripts loaded onto the page which may be indicative of a skimmer. -

Website Performance Monitoring Best Practices, Kpis and Tools
WHITE PAPER • JUNE 2018 Website Performance Monitoring Best Practices, KPIs and Tools A guide to achieving effective website performance monitoring. 2 • WHITE PAPER • WEBSITE PERFORMANCE MONITORING BEST PRACTICES, KPIs AND TOOLS ca.com Executive Summary Challenge Today, simply having a website for your business is not enough. To attract and keep customers, you need one that delivers an excellent user experience. Achieving this goal can be challenging. In addition to demanding well-designed, intuitive websites, modern users set an exceedingly high bar for site performance. A number of shortcomings might cause a site to fail to meet those expectations. Many users will abandon a page that fails to load within three seconds, for example, and a one-second delay in page load time results in 11 percent fewer page views. Also notable is the fact that users form a lasting impression of a website within just the first 50 milliseconds of a visit. In addition, search engines punish slow-loading websites with lower rankings, which makes it more difficult for new customers to find your business. (For more on these statistics and other user expectation data, see CA’s Infographic “Is Your Website Stacking Up to Customer Expectations?”) Opportunity Indeed, a poorly performing website will quickly undercut the investment a business makes in creating the site and setting up infrastructure to host it. Even the best-designed website will fail to please users if it loads slowly, throws errors or is intermittently unavailable. And world-class website hosting infrastructure will deliver little business value if software performance problems cause page load delays or other performance issues. -

NCUA Letter 02-CU-17
NCUA LETTER TO CREDIT UNIONS NATIONAL CREDIT UNION ADMINISTRATION 1775 Duke Street, Alexandria, VA DATE: December 2002 LETTER NO.: 02-CU-17 TO: All Federally-Insured Credit Unions SUBJ: e-Commerce Guide for Credit Unions ENCL: e-Commerce Guide for Credit Unions The purpose of this letter is to provide NCUA’s e-Commerce Guide for Credit Unions. The guide offers information to assist credit unions engaging in, or considering, e-Commerce activities (electronic delivery of financial services via the Internet). Credit unions can use this information as a guide to aid in the planning, contracting, delivery, and support of e-Commerce activities. Offering e-Commerce services may provide benefits to credit unions and their members. However, the use of the Internet can also increase the amount of risk to the credit union. The enclosed guide focuses on processes to assist credit unions in managing the risks related to e-Commerce. If you have any questions, please contact your NCUA Regional Office or State Supervisory Authority. Sincerely, /S/ Dennis Dollar Chairman e-Commerce Guide For Credit Unions NCUA 8072 November 2002 Table of Contents 1. INTRODUCTION.................................................................................................................. 1 2. THE CONVERGENCE OF CREDIT UNIONS AND THE INTERNET ........................ 2 3. SMALL CREDIT UNIONS .................................................................................................. 3 4. OVERSIGHT ........................................................................................................................ -

The Value of Measuring End-User Experience from a Global Point of Presence
www.site24x7.com Web Application Monitoring Service The Value of Measuring End-User Experience from a Global Point of Presence White Paper from Web: www.site24x7.com www.Site24x7.com Email: [email protected] Table of Contents 1. Introduction 2. The Business need for Web Application Monitoring 3. Different Approaches: Monitoring from Inside and Outside of the Corporate Firewall 4. Monitoring Web Applications across the Entire Delivery Chain 1. Third-party services 2. Composite applications 3. User-generated content 5. Capabilities Needed 1. Tools for active (synthetic) monitoring of application performance 2. Tools for monitoring application performance across application delivery chain 3. Tools for defining dynamic thresholds for performance of Web applications 4. Tools for issuing alerts when performance falls below pre-defined thresholds 5. Tools for comparing application performance to Service Level Agreements (SLA) 5. Recommendations for Action 6. Capabilities of Site24x7 Website Monitoring Service www.site24x7.com 2 Introduction Organizations are increasingly depending on the web to communicate with their customers, prospects, and partners. As organizations expand their target markets to different geographies, they are seeking to ensure that they have visibility into the quality of the end-user experience for their web applications regardless of the business users’ geographic location. Many of these applications are being used as revenue generating tools for these organizations, and they need to understand not only how these applications are performing from the perspective of their IT departments, but also how they are performing from the perspective of business users. The main characteristics of new web services are increased amount of dynamic and user generated content, changes in usage patterns, and a proliferation of composite applications and third-party services. -
3000 Applications
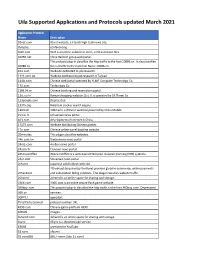
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

2020 Network Monitoring Buyer's Guide
2020 NETWORK MONITORING BUYER’S GUIDE 1 NETWORK MONITORING BUYER’S GUIDE MARKET OVERVIEW The network is perhaps the most essential technology of the modern business. For just about every company, networks are the core technology that allows it to operate efficiently, promote collaboration amongst its staff, and communicate with clients. As such, companies need to ensure that their network is running smoothly at all times. That’s why continuously observing your network for performance problems is a critical aspect of maintaining a business network. Businesses rely on their network to perform at certain levels to satisfy the demands of executives and clients. Unfortunately, network performance issues are all too common, and they can put a strain on your company. Your company needs to be prepared to deal with an unexpected performance problem and fix it before it causes too much stress. Performance issues and network outages are not just infuriating to deal with; they can also be incredibly costly to your company. NetRounds’ September 2019 report The Hidden Cost of Network Brownouts revealed that companies lose $600,000 a year on average due to network performance problems. The survey also showed that network brownouts (or sudden drops in quality) are causing damage to 83% of large companies, with many employees citing frustration with the dips in network performance. How can a business deal with network performance problems, though? Enterprise networks are constantly growing in complexity, adding new devices and new kinds of hardware as Internet of Things (IoT) deployments become more popular. It’s also difficult to predict what performance issues are likely to happen (and where they’re coming from) until it’s too late. -

Website Monitoring for Webmasters White Paper from Manageengine
Website Monitoring For Webmasters White Paper from ManageEngine Web: www.manageengine.com/apm email: [email protected] Introduction Any Webmaster knows how irritating it feels to be notified at 2 AM that their website is not accessible. Home pages being too slow or irate users who are unable to complete their web transactions are detrimental to business. What Webmasters need are tools that help them moni- tor critical parameters of their websites and help ease their day-to-day activities. In this paper you can find out what you need to look for in a website monitoring tool. 6 critical aspects of a website that need to be monitored Web Page Availability The basic need for every Webmaster is to ensure that their website is up and running. Downtimes could result in lost customers and eventually lost revenues. Webmasters need tools that will alert them in real time when their websites are down. The ability to check for the presence of specific keywords in web pages would also add to their comfort level. Web Page Response Time Slow web pages tend to drive users to your competitors. As far as many are concerned, their Internet experience is the ‘world wide wait’. Therefore if your website is not responsive enough, you are going to lose potential customers. With Web 2.0 web applications driving the next wave of user expectations, in terms of web page responsiveness, website administrators cannot compromise with slow web pages SMS Email Reports Repsonse Time Execute Web Transactions Website Availability Web Page Correctness Are your pages rendered completely? You need to monitor whether your web pages show the full content.