A Multi-Level View of Dependable Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FUNDAMENTALS of COMPUTING (2019-20) COURSE CODE: 5023 502800CH (Grade 7 for ½ High School Credit) 502900CH (Grade 8 for ½ High School Credit)
EXPLORING COMPUTER SCIENCE NEW NAME: FUNDAMENTALS OF COMPUTING (2019-20) COURSE CODE: 5023 502800CH (grade 7 for ½ high school credit) 502900CH (grade 8 for ½ high school credit) COURSE DESCRIPTION: Fundamentals of Computing is designed to introduce students to the field of computer science through an exploration of engaging and accessible topics. Through creativity and innovation, students will use critical thinking and problem solving skills to implement projects that are relevant to students’ lives. They will create a variety of computing artifacts while collaborating in teams. Students will gain a fundamental understanding of the history and operation of computers, programming, and web design. Students will also be introduced to computing careers and will examine societal and ethical issues of computing. OBJECTIVE: Given the necessary equipment, software, supplies, and facilities, the student will be able to successfully complete the following core standards for courses that grant one unit of credit. RECOMMENDED GRADE LEVELS: 9-12 (Preference 9-10) COURSE CREDIT: 1 unit (120 hours) COMPUTER REQUIREMENTS: One computer per student with Internet access RESOURCES: See attached Resource List A. SAFETY Effective professionals know the academic subject matter, including safety as required for proficiency within their area. They will use this knowledge as needed in their role. The following accountability criteria are considered essential for students in any program of study. 1. Review school safety policies and procedures. 2. Review classroom safety rules and procedures. 3. Review safety procedures for using equipment in the classroom. 4. Identify major causes of work-related accidents in office environments. 5. Demonstrate safety skills in an office/work environment. -

Use of Bioinformatics Resources and Tools by Users of Bioinformatics Centers in India Meera Yadav University of Delhi, [email protected]
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Library Philosophy and Practice (e-journal) Libraries at University of Nebraska-Lincoln 2015 Use of Bioinformatics Resources and Tools by Users of Bioinformatics Centers in India meera yadav University of Delhi, [email protected] Manlunching Tawmbing Saha Institute of Nuclear Physisc, [email protected] Follow this and additional works at: http://digitalcommons.unl.edu/libphilprac Part of the Library and Information Science Commons yadav, meera and Tawmbing, Manlunching, "Use of Bioinformatics Resources and Tools by Users of Bioinformatics Centers in India" (2015). Library Philosophy and Practice (e-journal). 1254. http://digitalcommons.unl.edu/libphilprac/1254 Use of Bioinformatics Resources and Tools by Users of Bioinformatics Centers in India Dr Meera, Manlunching Department of Library and Information Science, University of Delhi, India [email protected], [email protected] Abstract Information plays a vital role in Bioinformatics to achieve the existing Bioinformatics information technologies. Librarians have to identify the information needs, uses and problems faced to meet the needs and requirements of the Bioinformatics users. The paper analyses the response of 315 Bioinformatics users of 15 Bioinformatics centers in India. The papers analyze the data with respect to use of different Bioinformatics databases and tools used by scholars and scientists, areas of major research in Bioinformatics, Major research project, thrust areas of research and use of different resources by the user. The study identifies the various Bioinformatics services and resources used by the Bioinformatics researchers. Keywords: Informaion services, Users, Inforamtion needs, Bioinformatics resources 1. Introduction ‘Needs’ refer to lack of self-sufficiency and also represent gaps in the present knowledge of the users. -

Establishing the Basis for a CIS (Computer Information Systems) Undergraduate Program: on Seeking the Body of Knowledge
Information Systems Education Journal (ISEDJ) 13 (5) ISSN: 1545-679X September 2015 Establishing the Basis for a CIS (Computer Information Systems) Undergraduate Program: On Seeking the Body of Knowledge Herbert E. Longenecker, Jr. [email protected] University of South Alabama Mobile, AL 36688, USA Jeffry Babb [email protected] West Texas A&M University Canyon, TX 79016, USA Leslie J. Waguespack [email protected] Bentley University Waltham, Massachusetts 02452, USA Thomas N. Janicki [email protected] University of North Carolina Wilmington Wilmington, NC 28403, USA David Feinstein [email protected] University of South Alabama Mobile, AL 36688, USA Abstract The evolution of computing education spans a spectrum from computer science (CS) grounded in the theory of computing, to information systems (IS), grounded in the organizational application of data processing. This paper reports on a project focusing on a particular slice of that spectrum commonly labeled as computer information systems (CIS) and reflected in undergraduate academic programs designed to prepare graduates for professions as software developers building systems in government, commercial and not-for-profit enterprises. These programs with varying titles number in the hundreds. This project is an effort to determine if a common knowledge footprint characterizes CIS. If so, an eventual goal would be to describe the proportions of those essential knowledge components and propose guidelines specifically for effective undergraduate CIS curricula. Professional computing societies (ACM, IEEE, AITP (formerly DPMA), etc.) over the past fifty years have sponsored curriculum guidelines for various slices of education that in aggregate offer a compendium of knowledge areas in ©2015 EDSIG (Education Special Interest Group of the AITP) Page 37 www.aitp-edsig.org /www.isedj.org Information Systems Education Journal (ISEDJ) 13 (5) ISSN: 1545-679X September 2015 computing. -
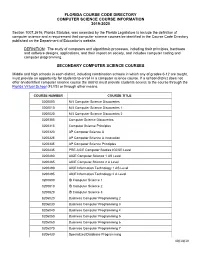
Florida Course Code Directory Computer Science Course Information 2019-2020
FLORIDA COURSE CODE DIRECTORY COMPUTER SCIENCE COURSE INFORMATION 2019-2020 Section 1007.2616, Florida Statutes, was amended by the Florida Legislature to include the definition of computer science and a requirement that computer science courses be identified in the Course Code Directory published on the Department of Education’s website. DEFINITION: The study of computers and algorithmic processes, including their principles, hardware and software designs, applications, and their impact on society, and includes computer coding and computer programming. SECONDARY COMPUTER SCIENCE COURSES Middle and high schools in each district, including combination schools in which any of grades 6-12 are taught, must provide an opportunity for students to enroll in a computer science course. If a school district does not offer an identified computer science course the district must provide students access to the course through the Florida Virtual School (FLVS) or through other means. COURSE NUMBER COURSE TITLE 0200000 M/J Computer Science Discoveries 0200010 M/J Computer Science Discoveries 1 0200020 M/J Computer Science Discoveries 2 0200305 Computer Science Discoveries 0200315 Computer Science Principles 0200320 AP Computer Science A 0200325 AP Computer Science A Innovation 0200335 AP Computer Science Principles 0200435 PRE-AICE Computer Studies IGCSE Level 0200480 AICE Computer Science 1 AS Level 0200485 AICE Computer Science 2 A Level 0200490 AICE Information Technology 1 AS Level 0200495 AICE Information Technology 2 A Level 0200800 IB Computer -

Safety and Security Challenge
SAFETY AND SECURITY CHALLENGE TOP SUPERCOMPUTERS IN THE WORLD - FEATURING TWO of DOE’S!! Summary: The U.S. Department of Energy (DOE) plays a very special role in In fields where scientists deal with issues from disaster relief to the keeping you safe. DOE has two supercomputers in the top ten supercomputers in electric grid, simulations provide real-time situational awareness to the whole world. Titan is the name of the supercomputer at the Oak Ridge inform decisions. DOE supercomputers have helped the Federal National Laboratory (ORNL) in Oak Ridge, Tennessee. Sequoia is the name of Bureau of Investigation find criminals, and the Department of the supercomputer at Lawrence Livermore National Laboratory (LLNL) in Defense assess terrorist threats. Currently, ORNL is building a Livermore, California. How do supercomputers keep us safe and what makes computing infrastructure to help the Centers for Medicare and them in the Top Ten in the world? Medicaid Services combat fraud. An important focus lab-wide is managing the tsunamis of data generated by supercomputers and facilities like ORNL’s Spallation Neutron Source. In terms of national security, ORNL plays an important role in national and global security due to its expertise in advanced materials, nuclear science, supercomputing and other scientific specialties. Discovery and innovation in these areas are essential for protecting US citizens and advancing national and global security priorities. Titan Supercomputer at Oak Ridge National Laboratory Background: ORNL is using computing to tackle national challenges such as safe nuclear energy systems and running simulations for lower costs for vehicle Lawrence Livermore's Sequoia ranked No. -

Top 10 Reasons to Major in Computing
Top 10 Reasons to Major in Computing 1. Computing is part of everything we do! Computing and computer technology are part of just about everything that touches our lives from the cars we drive, to the movies we watch, to the ways businesses and governments deal with us. Understanding different dimensions of computing is part of the necessary skill set for an educated person in the 21st century. Whether you want to be a scientist, develop the latest killer application, or just know what it really means when someone says “the computer made a mistake”, studying computing will provide you with valuable knowledge. 2. Expertise in computing enables you to solve complex, challenging problems. Computing is a discipline that offers rewarding and challenging possibilities for a wide range of people regardless of their range of interests. Computing requires and develops capabilities in solving deep, multidimensional problems requiring imagination and sensitivity to a variety of concerns. 3. Computing enables you to make a positive difference in the world. Computing drives innovation in the sciences (human genome project, AIDS vaccine research, environmental monitoring and protection just to mention a few), and also in engineering, business, entertainment and education. If you want to make a positive difference in the world, study computing. 4. Computing offers many types of lucrative careers. Computing jobs are among the highest paid and have the highest job satisfaction. Computing is very often associated with innovation, and developments in computing tend to drive it. This, in turn, is the key to national competitiveness. The possibilities for future developments are expected to be even greater than they have been in the past. -

Open Dissertation Draft Revised Final.Pdf
The Pennsylvania State University The Graduate School ICT AND STEM EDUCATION AT THE COLONIAL BORDER: A POSTCOLONIAL COMPUTING PERSPECTIVE OF INDIGENOUS CULTURAL INTEGRATION INTO ICT AND STEM OUTREACH IN BRITISH COLUMBIA A Dissertation in Information Sciences and Technology by Richard Canevez © 2020 Richard Canevez Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy December 2020 ii The dissertation of Richard Canevez was reviewed and approved by the following: Carleen Maitland Associate Professor of Information Sciences and Technology Dissertation Advisor Chair of Committee Daniel Susser Assistant Professor of Information Sciences and Technology and Philosophy Lynette (Kvasny) Yarger Associate Professor of Information Sciences and Technology Craig Campbell Assistant Teaching Professor of Education (Lifelong Learning and Adult Education) Mary Beth Rosson Professor of Information Sciences and Technology Director of Graduate Programs iii ABSTRACT Information and communication technologies (ICTs) have achieved a global reach, particularly in social groups within the ‘Global North,’ such as those within the province of British Columbia (BC), Canada. It has produced the need for a computing workforce, and increasingly, diversity is becoming an integral aspect of that workforce. Today, educational outreach programs with ICT components that are extending education to Indigenous communities in BC are charting a new direction in crossing the cultural barrier in education by tailoring their curricula to distinct Indigenous cultures, commonly within broader science, technology, engineering, and mathematics (STEM) initiatives. These efforts require examination, as they integrate Indigenous cultural material and guidance into what has been a largely Euro-Western-centric domain of education. Postcolonial computing theory provides a lens through which this integration can be investigated, connecting technological development and education disciplines within the parallel goals of cross-cultural, cross-colonial humanitarian development. -

Information Systems Foundations Theory, Representation and Reality
Information Systems Foundations Theory, Representation and Reality Information Systems Foundations Theory, Representation and Reality Dennis N. Hart and Shirley D. Gregor (Editors) Workshop Chair Shirley D. Gregor ANU Program Chairs Dennis N. Hart ANU Shirley D. Gregor ANU Program Committee Bob Colomb University of Queensland Walter Fernandez ANU Steven Fraser ANU Sigi Goode ANU Peter Green University of Queensland Robert Johnston University of Melbourne Sumit Lodhia ANU Mike Metcalfe University of South Australia Graham Pervan Curtin University of Technology Michael Rosemann Queensland University of Technology Graeme Shanks University of Melbourne Tim Turner Australian Defence Force Academy Leoni Warne Defence Science and Technology Organisation David Wilson University of Technology, Sydney Published by ANU E Press The Australian National University Canberra ACT 0200, Australia Email: [email protected] This title is also available online at: http://epress.anu.edu.au/info_systems02_citation.html National Library of Australia Cataloguing-in-Publication entry Information systems foundations : theory, representation and reality Bibliography. ISBN 9781921313134 (pbk.) ISBN 9781921313141 (online) 1. Management information systems–Congresses. 2. Information resources management–Congresses. 658.4038 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying or otherwise, without the prior permission of the publisher. Cover design by Brendon McKinley with logo by Michael Gregor Authors’ photographs on back cover: ANU Photography Printed by University Printing Services, ANU This edition © 2007 ANU E Press Table of Contents Preface vii The Papers ix Theory Designing for Mutability in Information Systems Artifacts, Shirley Gregor and Juhani Iivari 3 The Eect of the Application Domain in IS Problem Solving: A Theoretical Analysis, Iris Vessey 25 Towards a Unied Theory of Fit: Task, Technology and Individual, Michael J. -

Information System Owner
DOE CYBERSECURITY: CORE COMPETENCY TRAINING REQUIREMENTS Key Cybersecurity Role: Information System Owner Role Definition: The Information System Owner (also referred to as System Owner) is the individual responsible for the overall procurement, development, integration, modification, operation, maintenance, and retirement of an information system. The System Owner is a key contributor in developing system design specifications to ensure the security and user operational needs are documented, tested, and implemented. Competency Area: Data Security Functional Requirement: Design Competency Definition: Refers to the application of the principles, policies, and procedures necessary to ensure the confidentiality, integrity, availability, and privacy of data in all forms of media (i.e., electronic and hardcopy) throughout the data life cycle. Behavioral Outcome: The System Owner will understand the policies and procedures required to protect all categories of information as well as have a working knowledge of data access controls required to ensure the confidentiality, integrity, and availability of information. He/she will apply this knowledge during all phases of the System Development Life Cycle (SDLC). Training concepts to be addressed at a minimum: Identify and document the appropriate level of protection for data, including use of encryption. Specify data and information classification, sensitivity, and need-to-know requirements by information type on a system in terms of its confidentiality, integrity, and availability. Utilize DOE M 205.1-5 to determine the information impacts for unclassified information and DOE M 205.1-4 to determine the Consequence of Loss for classified information. Create authentication and authorization system for users to gain access to data based on assigned privileges and permissions. -
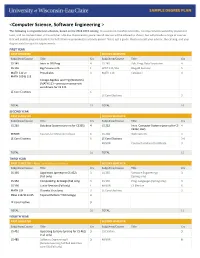
<Computer Science, Software Engineering >
<Computer Science, Software Engineering > The following is a hypothetical schedule, based on the 2018-2019 catalog. It assumes no transferred credits, no requirements waived by placement tests, and no courses taken in the summer. UW-Eau Claire cannot guarantee all courses will be offered as shown, but will provide a range of courses that will enable prepared students to fulfill their requirements in a timely period. This is just a guide. Please consult your advisor, the catalog, and your degree audit for specific requirements. FIRST YEAR FIRST SEMESTER SECOND SEMESTER Subj/Area/Course Title Crs Subj/Area/Course Title Crs CS 145 Intro to OO Prog 4 CS 245 Adv. Prog. Data Structures 4 CS 146 Big Picture in CS 1 WRIT 114/116 Blugold Seminar 5 MATH 112 or Precalculus 4 MATH 114 Calculus I 4 MATH 109 & 113 College Algebra and Trig (Winterim) (MATH 113 – prereq or concurrent enrollment for CS 245 LE Core Electives 6 LE Core Electives 3 TOTAL 15 TOTAL 16 SECOND YEAR FIRST SEMESTER SECOND SEMESTER Subj/Area/Course Title Crs Subj/Area/Course Title Crs CS 260 Database Systems (prereq for CS355) 4 CS 252 Intro. Computer Systems (prereq for CS 4 CS352, 452) MINOR Courses for Minor/Certificate 6 CS 268 Web Systems 3 LE Core Electives 6 LE Core Electives 3-6 MINOR Courses for Minor/Certificate 3 TOTAL 16 TOTAL 15 THIRD YEAR FIRST SEMESTER – Apply for Admission to Major SECOND SEMESTER Subj/Area/Course Title Crs Subj/Area/Course Title Crs CS 335 Algorithms (prereq for CS 452) 3 CS 355 Software Engineering I 3 (Fall only) (Spring only) CS 352 ComputeOrg. -

From Ethnomathematics to Ethnocomputing
1 Bill Babbitt, Dan Lyles, and Ron Eglash. “From Ethnomathematics to Ethnocomputing: indigenous algorithms in traditional context and contemporary simulation.” 205-220 in Alternative forms of knowing in mathematics: Celebrations of Diversity of Mathematical Practices, ed Swapna Mukhopadhyay and Wolff- Michael Roth, Rotterdam: Sense Publishers 2012. From Ethnomathematics to Ethnocomputing: indigenous algorithms in traditional context and contemporary simulation 1. Introduction Ethnomathematics faces two challenges: first, it must investigate the mathematical ideas in cultural practices that are often assumed to be unrelated to math. Second, even if we are successful in finding this previously unrecognized mathematics, applying this to children’s education may be difficult. In this essay, we will describe the use of computational media to help address both of these challenges. We refer to this approach as “ethnocomputing.” As noted by Rosa and Orey (2010), modeling is an essential tool for ethnomathematics. But when we create a model for a cultural artifact or practice, it is hard to know if we are capturing the right aspects; whether the model is accurately reflecting the mathematical ideas or practices of the artisan who made it, or imposing mathematical content external to the indigenous cognitive repertoire. If I find a village in which there is a chain hanging from posts, I can model that chain as a catenary curve. But I cannot attribute the knowledge of the catenary equation to the people who live in the village, just on the basis of that chain. Computational models are useful not only because they can simulate patterns, but also because they can provide insight into this crucial question of epistemological status. -

Information System Development Using Augmented Reality Tools*
Information system development using augmented reality tools* Grigorev Rostislav Aleksandrovich Valijanov Bahrom Adhamdzon-ugli Kazan Federal University Kazan Federal University Kazan, Russia Kazan, Russia [email protected] [email protected] Medvedeva Olga Anatolievna Mustafina Svetlana Anatol’evna Kazan Federal University Bashkir State University Kazan, Russia Ufa, Russia [email protected] [email protected] Abstract This work is devoted to the issues of visualization and information processing, in particular, to improving the visualization of 3D objects using augmented reality technology. The concept of augmented reality offers a more advanced user interface for visualization due to a combination of natural ways to control the change of angle of an object and visualization in a real context. In the process of performing the work, computer graphics, algorithms, and modeling methods were used. The experimental part of the work was carried out using a set of development tools for tracking Vuforia and Unity development tools. Introduction Augmented reality (AR) is an interactive experience of a real-world environment where the objects that reside in the real world are enhanced by computer-generated perceptual information, sometimes across multiple sensory modalities, including visual, auditory, haptic, somatosensory and olfactory. AR can be defined as a system that fulfills three basic features: a combination of real and virtual worlds, real-time interaction, and accurate 3D registration of virtual and real objects. The overlaid sensory information can be constructive (i.e. additive to the natural environment), or destructive (i.e. masking of the natural environment). This experience is seamlessly interwoven with the physical world such that it is perceived as an immersive aspect of the real environment.