Twenty Years of Digital Audio Watermarking—A Comprehensive Review
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Digital Watermarking: an Introduction
Digital Watermarking: An Introduction Edward J. Delp Purdue University School of Electrical and Computer Engineering Purdue Multimedia Testbed Video and Image Processing Laboratory (VIPER) West Lafayette, Indiana email: [email protected] http://www.ece.purdue.edu/~ace EPICS Spring 2003 Slide 1 Outline • Provide an introduction to watermarking and data hiding and overview its use • Describe how security techniques may/will impact multimedia systems EPICS Spring 2003 Slide 2 Multimedia Security • “Everything” is digital these days - a copy of a digital media element is identical to the original • How can an owner protect their content? • Are images still “fossilized light”? • What does all of this mean in terms of law? • Does any security system really work or does it just make us feel good! EPICS Spring 2003 Slide 3 What Do We Want From a Security System? Playback Control • Access Control Record Control • Copy Control Þ Generation Control • Auditing (fingerprinting) – Who did what and when? EPICS Spring 2003 Slide 4 What Do Users Want? • Time-shifting • Space-shifting • Single copy (back ups?) EPICS Spring 2003 Slide 5 Digital Communication System EPICS Spring 2003 Slide 6 Typical Cryptography System: Trusted Users Source Insecure Channel User Attacker Is this a pirate device? EPICS Spring 2003 Slide 7 Cryptography System: User Not Trusted Source Insecure Channel User Authentication EPICS Spring 2003 Slide 8 Media Elements • Audio • Video • Documents (including HTML documents) • Images • Graphics • Graphic or Scene Models • Programs (executable -

Digital Watermarking and Steganography the Morgan Kaufmann Series in Multimedia Information and Systems Series Editor, Edward A
Digital Watermarking and Steganography The Morgan Kaufmann Series in Multimedia Information and Systems Series Editor, Edward A. Fox, Virginia Poytechnic University Digital Watermarking and Steganography, Second Edition Ingemar J. Cox, Matthew L. Miller, Jeffrey A. Bloom, Jessica Fridrich, and Ton Kalker Keeping Found Things Found: The Study and Practice of Personal Information Management William P. Jones Web Dragons: Inside the Myths of Search Engine Technology Ian H. Witten, Marco Gori, and Teresa Numerico Introduction to Data Compression, Third Edition Khalid Sayood Understanding Digital Libraries, Second Edition Michael Lesk Bioinformatics: Managing Scientific Data Zoe´ Lacroix and Terence Critchlow How to Build a Digital Library Ian H. Witten and David Bainbridge Readings in Multimedia Computing and Networking Kevin Jeffay and Hong Jiang Zhang Multimedia Servers: Applications, Environments, and Design Dinkar Sitaram and Asit Dan Visual Information Retrieval Alberto del Bimbo Managing Gigabytes: Compressing and Indexing Documents and Images, Second Edition Ian H. Witten, Alistair Moffat, and Timothy C. Bell Digital Compression for Multimedia: Principles & Standards Jerry D. Gibson, Toby Berger, Tom Lookabaugh, Rich Baker, and David Lindbergh Readings in Information Retrieval Karen Sparck Jones, and Peter Willett For further information on these books and for a list of forthcoming titles, please visit our web site at http://www.mkp.com. The Morgan Kaufmann Series in Computer Security Digital Watermarking and Steganography, Second Edition Ingemar J. Cox, Matthew L. Miller, Jeffrey A. Bloom, Jessica Fridrich, and Ton Kalker Information Assurance: Dependability and Security in Networked Systems Yi Qian, David Tipper, Prashant Krishnamurthy, and James Joshi Network Recovery: Protection and Restoration of Optical, SONET-SDH, IP, and MPLS Jean-Philippe Vasseur, Mario Pickavet, and Piet Demeester For further information on these books and for a list of forthcoming titles, please visit our Web site at http://www.mkp.com. -

Survey on Decentralized Fingerprinting Solutions: Copyright Protection Through Piracy Tracing
computers Review Survey on Decentralized Fingerprinting Solutions: Copyright Protection through Piracy Tracing David Megías 1,* , Minoru Kuribayashi 2 and Amna Qureshi 1 1 Internet Interdisciplinary Institute (IN3), Universitat Oberta de Catalunya (UOC), CYBERCAT-Center for Cybersecurity Research of Catalonia, Castelldefels (Barcelona), 08860 Catalonia, Spain; [email protected] 2 Graduate School of Natural Science and Technology, Okayama University, Okayama 700-8530, Japan; [email protected] * Correspondence: [email protected] Received: 13 March 2020; Accepted: 30 March 2020; Published: 3 April 2020 Abstract: Copyright protection is one of the most relevant challenges in the network society. This paper focuses on digital fingerprinting, a technology that facilitates the tracing of the source of an illegal redistribution, making it possible for the copyright holder to take legal action in case of copyright violation. The paper reviews recent digital fingerprinting solutions that are available for two particularly relevant scenarios: peer-to-peer distribution networks and broadcasting. After analyzing those solutions, a discussion is carried out to highlight the properties and the limitations of those techniques. Finally, some directions for further research on this topic are suggested. Keywords: copyright infringement; piracy tracing; fingerprinting; peer-to-peer distribution; broadcasting 1. Introduction Nowadays, digital technologies allow users to generate near-perfect quality identical copies of the content at low costs. Therefore, the amount of the digital data that is illegally redistributed is growing, making businesses lose income. Content creators and multimedia producers are concerned about the consequences of illegal copying and redistribution on a massive scale. Consequently, the need for a protection system that can provide copyright protection by prosecuting unauthorized copying has arisen in recent years. -

Technical Aspects of Digital Rights Management
Technical aspects of Digital Rights Management Emilija Arsenova MI, RWTH-Aachen Seminar: Digital Rights Management Table of content 1 Introduction ............................................................................................................. 3 2 Digital Rights Management (DRM) ........................................................................ 3 2.1 DRM Architecture ..............................................................................................4 2.2 DRM Techniques...............................................................................................5 2.3 DRM goals.........................................................................................................8 3 Watermarks............................................................................................................ 10 3.1 Different Types of Watermarks........................................................................10 3.2 Requirements of an ideal watermarking system .............................................12 3.3 Watermarking systems....................................................................................12 3.4 Watermarking application domain ...................................................................13 3.5 Digital watermarking techniques .....................................................................15 3.5.1 Spatial domain techniques ..........................................................................15 3.5.2 Transform domain techniques.....................................................................16 -

Twenty Years of Digital Audio Watermarking – a Comprehensive Review
Twenty Years of Digital Audio Watermarking – A Comprehensive Review Guang Huaa,∗, Jiwu Huangb, Yun Q. Shic, Jonathan Gohd, Vrizlynn L. L. Thingd aSchool of Electrical and Electronic Engineering, Nanyang Technological University, Singapore 639798. bCollege of Information Engineering, Shenzhen University, Shenzhen 518060, China. cDepartment of Electrical and Computer Engineering, New Jersey Institute of Technology, Newark, NJ 07102, USA. dCyber Security & Intelligence Department, Institute for Infocomm Research, Singapore 138632. Abstract Digital audio watermarking is an important technique to secure and au- thenticate audio media. This paper provides a comprehensive review of the twenty years’ research and development works for digital audio watermark- ing, based on an exhaustive literature survey and careful selections of rep- resentative solutions. We generally classify the existing designs into time domain and transform domain methods, and relate all the reviewed works using two generic watermark embedding equations in the two domains. The most important designing criteria, i.e., imperceptibility and robustness, are thoroughly reviewed. For imperceptibility, the existing measurement and control approaches are classified into heuristic and analytical types, followed by intensive analysis and discussions. Then, we investigate the robustness of the existing solutions against a wide range of critical attacks categorized into basic, desynchronization, and replacement attacks, respectively. This reveals current challenges in developing a global solution robust against all the attacks considered in this paper. Some remaining problems as well as research potentials for better system designs are also discussed. In addition, audio watermarking applications in terms of US patents and commercialized solutions are reviewed. This paper serves as a comprehensive tutorial for interested readers to gain a historical, technical, and also commercial view of digital audio watermarking. -
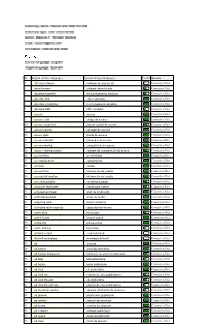
Target Language
ID English (Source language) Spanish (Target language) Confid Domains 1 3D chat software software de chat en 3D Computers/Dat… 3 abandonware software abandonado Computers/Dat… 4 absolute hyperlink enlace hipertexto absoluto Computers/Dat… 5 absolute link enlace absoluto Computers/Dat… 6 absolute positioning posicionamiento absoluto Computers/Dat… 7 absolute URL URL completo Computers/Dat… 8 access acceso Computers/Dat… 9 access code código de acceso Computers/Dat… 10 access control list lista de control de acceso Computers/Dat… 11 access counter contador de acceso Computers/Dat… 12 access gate puerta de acceso Computers/Dat… 13 access provider proveedor de acceso Computers/Dat… 14 access sharing compartición de acceso Computers/Dat… 15 access sharing system software de compartición de acceso Computers/Dat… 16 accessibility accesibilidad Computers/Dat… 17 accomplishment cumplimiento Computers/Dat… 18 account cuenta Computers/Dat… 19 account info información de cuenta Computers/Dat… 20 account information información de cuenta Computers/Dat… 21 accounts payable cuentas por pagar Computers/Dat… 22 accounts receivable cuentas por cobrar Computers/Dat… 23 achievement graph grafo de progresión Computers/Dat… 24 acknowledgement acuse de recibo Computers/Dat… 25 acquiring bank banco comercial Computers/Dat… 26 activated return capacity capacidad de retorno Computers/Dat… 27 active blog blog activo Computers/Dat… 28 active image imagen activa Computers/Dat… 29 active link enlace activo Computers/Dat… 30 active weblog blog activo Computers/Dat… -

Digital Watermarking
ISSN: 2277-3754 ISO 9001:2008 Certified International Journal of Engineering and Innovative Technology (IJEIT) Volume 2, Issue 2, August 2012 Digital Watermarking Sahil Anand, Swati Mehla, Samiksha Arya, Piyush Kapoor watermarked image is on the right and contains the name Abstract-Digital watermarking is basically a technique of the writer. that embeds a watermark into two integrated images such that the watermark can be extracted by overlaying these into half toned images. These water markings techniques are used to Coded anti-piracy, attack, constellation, Pattern,Steganography. Basically very helpful in medical sciences and authenticating various products. The watermark images in these strategies are binary images and the pixels in the two halftone images are interrelated or not depending on whether the corresponding pixel in the watermark. In these strategies, the watermark is binary and does not contain detailed features. Digital Watermarking is based on the fact of “perceptual invisibility,” this paper makes a study of the maximum watermarking of spatial domain image, which is related to not only embedding intensity, but also to factors such as the size of image, image roughness and visual sensitivity, and so forth. The interrelation among the maximum payload and the embedding intensity and size of an image is theoretically deduced through the objective Fig 1. General Image[8] estimation indicator of the peak signal to the noise rate B. Digital Watermarking Description (PSNR) while the relationship model among Digital A watermark is a clear image in paper that can be seen watermarking and image roughness and visual sensitivity is in many shades of lightness/darkness when viewed by deduced through effective experiments designed on the basis transmitted light affected by thickness variations in the of subjective estimation indicators. -

A Survey of Digital Watermarking Techniques and Its Applications
International Journal of Computer Science Trends and Technology (IJCST) – Volume 2 Issue 3, May-Jun 2014 RESEARCH ARTICLE OPEN ACCESS A Survey of Digital Watermarking Techniques and its Applications Lalit Kumar Saini1, Vishal Shrivastava2 M.Tech1 Research Scholar, Professor2 Department of Computer Science and Engineering, Arya College of Engineering. & Information Technology, Jaipur, India ABSTRACT Digital media is the need of a people now a day as the alternate of paper media. As the technology grown up digital media required protection while transferring through internet or others mediums. Watermarking techniques have been developed to fulfill this requirement. This paper aims to provide a detailed survey of all watermarking techniques specially focuses on image watermarking types and its applications in today’s world. Keywords: - Watermarking, DWT, Copyright, PSNR. I. INTRODUCTION Today’s generation is witness of developments of digital Steganography, a process in which digital content is hide media. A very simplest example of digital media is a with the other content for secure transmission of Digital photo captured by phone camera. The use of Digital data. In particular conditions steganography and media is common in present era. Other example of Digital watermarking are very similar when the data to be secure media is text, audio, video etc. is hidden in process of transmission over some carrier. We know an internet is the fastest medium of transferring The main difference between these two processes is in data to any place in a world. As this technology grown up steganography the hidden data is on highest priority for the threat of piracy and copyright very obvious thought is sender and receiver but in watermarking bot source image in owners mind. -

Security Authentication of Dual Chaotic Image Watermarking in Spatial Domain with Spatial and Frequency Domain Characteristics Analysis
Article Security Authentication of Dual Chaotic Image Watermarking in Spatial Domain with Spatial and Frequency Domain Characteristics Analysis Zhengmao Ye 1,* , Hang Yin 1 and Yongmao Ye 2 1 College of Engineering, Southern University, Baton Rouge, LA 70813, USA; [email protected] 2 Liaoning Radio and Television Station, Shenyang 110003, China; [email protected] * Correspondence: [email protected] Received: 27 July 2018; Accepted: 15 October 2018; Published: 17 October 2018 Abstract: This article presents an advanced dual chaotic watermarking scheme to improve information security. To ensure confidentiality in digital image transmission, a secure dual watermarking scheme is proposed by applying the chaotic logistic system and hyper-chaotic dynamical system. Chaotic watermarking was conducted in the spatial domain, where suboptimal secure hashing with a variable length was selected in preprocessing stages. The secret key was generated by the chaotic sequence for pixel shuffling using a chaotic logistic map, so that a controlled amount of distortion was inserted into the host digital image. Watermarking was proceeded after the chaotic watermark had been embedded into the shuffled image. To strengthen the security, the hyper-chaotic system was used to generate chaotic blocks for block scrambling in order to achieve dual chaotic watermarking. Characteristics analysis was conducted for multiple examples in both spatial and frequency domains. Potential effects induced by the chaotic driving parameter on processing time and integrity authentication of chaotic dual watermarking were also analyzed in detail. Keywords: watermarking; information security; logistic map; hyper-chaotic system; hashing; shuffling; scrambling 1. Introduction With rapid development of digital communication and computer networks, it becomes feasible to guarantee transmission security against malicious tampering or copyright infringement. -

Digital Watermarking Matthew N.O
International Journals of Advanced Research in Research Article June Computer Science and Software Engineering 2017 ISSN: 2277-128X (Volume-7, Issue-6) Digital Watermarking Matthew N.O. Sadiku1, Adebowale E. Shadare2, and Sarhan M. Musa3 1, 2Department of Electrical & Computer Engineering, 3Department of Engineering Technology 1, 2, 3Prairie View A&M University, Prairie View, TX 77446, United States DOI: 10.23956/ijarcsse/V7I6/01610 Abstract- Digital watermarks are often used to provide copyright protection for intellectual property and help the fight against electronic copyright infringement. They can be repeated at random locations within the content to make them difficult to detect. Developments in computer science, cryptography, digital signal processing, and information theory have all contributed to the success of digital watermarking. This paper provides a brief introduction to digital watermarking. Keywords: digital watermarking, forensic watermark, steganography I. INTRODUCTION The enormous use of computer networks such as the Internet and world wide web has led to the creation and delivery of content in digitally formatted form. The possibility for digital attacks such as forgery, stealing, copying, and altering the digital data has also increased. This has led to the need to protect ownership of digital information or digital media (image, text, video, audio, PDF, etc.), data tempering, and data integrity. Watermarking is an effective mechanism to address the problem and safeguard the digital contents that is created by the proliferation of digital information. A watermark is a name or logo stamped in the makeup of a document. Traditional watermarks have been used for years on letterhead or checks to prove authenticity. -
Digital Watermarking Applications and Techniques: a Brief Review
International Journal of Computer Applications Technology and Research Volume 5–Issue 3, 147-150, 2016, ISSN:2319–8656 Digital Watermarking Applications and Techniques: A Brief Review Aaqib Rashid MCA (Kashmir University) M.Phil Computer Science (Dr. C.V Raman University) Abstract: The frequent availability of digital data such as audio, images and videos became possible to the public through the expansion of the internet. Digital watermarking technology is being adopted to ensure and facilitate data authentication, security and copyright protection of digital media. It is considered as the most important technology in today’s world, to prevent illegal copying of data. Digital watermarking can be applied to audio, video, text or images. This paper includes the detail study of watermarking definition and various watermarking applications and techniques used to enhance data security. Index Terms: Watermarking, Techniques, Security, Technology, I. INTRODUCTION watermarking technique is needed to be applied. Watermark can be The advancement of the Internet has resulted in many new embedded either in spatial or frequency domain. Both the domains opportunities for the creation and delivery of content in digital form. are different and have their own pros and cons and are used in Applications include electronic advertising, real-time video and audio different scenario. Fig 1. Shows Digital Watermark embedding delivery, digital repositories and libraries, and Web publishing. But process and Fig. 2. Shows watermark detection process. the important question that arises in these applications is the data Watermark security. It has been observed that current copyright laws are not sufficient for dealing with digital data. Hence the protection and enforcement of intellectual property rights for digital media has become a crucial issue. -
A Secure Digital Camera Architecture for Integrated Real-Time Digital Rights Management
A Secure Digital Camera Architecture for Integrated Real-Time Digital Rights Management Saraju P. Mohanty VLSI Design and CAD Laboratory (VDCL) Dept. of Computer Science and Engineering University of North Texas, Denton, TX 76203, USA. Abstract This paper presents a novel concept of a secure digital camera (SDC) with a built-in watermarking and encryption facility. The motivation is to facilitate real-time digital rights management (DRM) by using the SDC right at the source end of multimedia content. The emerging field of DRM systems addresses the issues related to the intellectual property rights of digital content. The use of digital watermarking along with encryption for effective DRM is proposed. In this context, a novel discrete cosine transform domain invisible-robust watermarking method that uses cryptography and watermarking methods simultaneously to provide a double layer of protection to digital media is presented. The proposed method securely hides binary images in color image media and securely extracts and authenticates it by using a secret key. Experimental results prove that the proposed technique is resilient to stringent watermarking attacks. Hence, it is an effective method for providing protection of ownership rights. The corresponding application-specific architectures for invisible-robust watermarking and Rijndael advanced encryption standard (AES) towards the prototyping of the SDC are presented. The proposed architectures are modeled and synthesized for field programmable gate array (FPGA). The soft cores in the form of hardware description language resulting from this research can serve as intellectual- property core and can be integrated with any multimedia-producing electronic appliances which are built as embedded systems using system-on-a-chip (SoC) technology.