Terra Cognita 2011 Workshop Foundations, Technologies and Applications of the Geospatial Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chance the Rapper's Creation of a New Community of Christian
Bates College SCARAB Honors Theses Capstone Projects 5-2020 “Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book Samuel Patrick Glenn [email protected] Follow this and additional works at: https://scarab.bates.edu/honorstheses Recommended Citation Glenn, Samuel Patrick, "“Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book" (2020). Honors Theses. 336. https://scarab.bates.edu/honorstheses/336 This Open Access is brought to you for free and open access by the Capstone Projects at SCARAB. It has been accepted for inclusion in Honors Theses by an authorized administrator of SCARAB. For more information, please contact [email protected]. “Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book An Honors Thesis Presented to The Faculty of the Religious Studies Department Bates College in partial fulfillment of the requirements for the Degree of Bachelor of Arts By Samuel Patrick Glenn Lewiston, Maine March 30 2020 Acknowledgements I would first like to acknowledge my thesis advisor, Professor Marcus Bruce, for his never-ending support, interest, and positivity in this project. You have supported me through the lows and the highs. You have endlessly made sacrifices for myself and this project and I cannot express my thanks enough. -

Computational Models of Music Similarity and Their Applications In
Die approbierte Originalversion dieser Dissertation ist an der Hauptbibliothek der Technischen Universität Wien aufgestellt (http://www.ub.tuwien.ac.at). The approved original version of this thesis is available at the main library of the Vienna University of Technology (http://www.ub.tuwien.ac.at/englweb/). DISSERTATION Computational Models of Music Similarity and their Application in Music Information Retrieval ausgef¨uhrt zum Zwecke der Erlangung des akademischen Grades Doktor der technischen Wissenschaften unter der Leitung von Univ. Prof. Dipl.-Ing. Dr. techn. Gerhard Widmer Institut f¨urComputational Perception Johannes Kepler Universit¨atLinz eingereicht an der Technischen Universit¨at Wien Fakult¨atf¨urInformatik von Elias Pampalk Matrikelnummer: 9625173 Eglseegasse 10A, 1120 Wien Wien, M¨arz 2006 Kurzfassung Die Zielsetzung dieser Dissertation ist die Entwicklung von Methoden zur Unterst¨utzung von Anwendern beim Zugriff auf und bei der Entdeckung von Musik. Der Hauptteil besteht aus zwei Kapiteln. Kapitel 2 gibt eine Einf¨uhrung in berechenbare Modelle von Musik¨ahnlich- keit. Zudem wird die Optimierung der Kombination verschiedener Ans¨atze beschrieben und die gr¨oßte bisher publizierte Evaluierung von Musik¨ahnlich- keitsmassen pr¨asentiert. Die beste Kombination schneidet in den meisten Evaluierungskategorien signifikant besser ab als die Ausgangsmethode. Beson- dere Vorkehrungen wurden getroffen um Overfitting zu vermeiden. Um eine Gegenprobe zu den Ergebnissen der Genreklassifikation-basierten Evaluierung zu machen, wurde ein H¨ortest durchgef¨uhrt.Die Ergebnisse vom Test best¨a- tigen, dass Genre-basierte Evaluierungen angemessen sind um effizient große Parameterr¨aume zu evaluieren. Kapitel 2 endet mit Empfehlungen bez¨uglich der Verwendung von Ahnlichkeitsmaßen.¨ Kapitel 3 beschreibt drei Anwendungen von solchen Ahnlichkeitsmassen.¨ Die erste Anwendung demonstriert wie Musiksammlungen organisiert and visualisiert werden k¨onnen,so dass die Anwender den Ahnlichkeitsaspekt,¨ der sie interessiert, kontrollieren k¨onnen. -

Rita Wilson & Kristian Bush Embark on Joint U.S. Tour
RITA WILSON & KRISTIAN BUSH EMBARK ON JOINT U.S. TOUR KICKING OFF JUNE 5 RITA WILSON’S NEW ALBUM, HALFWAY TO HOME, OUT NOW Download hires images here Rita Wilson and Kristian Bush will embark on a joint concert tour kicking off June 5 in Atlanta (see complete itinerary below). Musical collaborators and good friends, Wilson and Bush will share both of their intimate and authentic songs with audiences, making for a memorable evening of live music. Wilson singer/songwriter, actress and producer just released her forth and acclaimed studio album, Halfway To Home (Sing it Loud/The Orchard), and was also recently honored by The Hollywood Chamber of Commerce with a star on the Hollywood Walk of Fame. Oprah.com called the new album, “deeply personal,” and said it “highlights Wilson's songwriting skills,” while CMT raved, “it’s genuine, and she’s poured her heart into every song.” “Throw Me A Party,” the first single, was premiered by Rolling Stonewho called it “evocative,” and Taste of Country noted the song has “touched everyone who has heard it.” The “moving” (People) music video was directed by AwardwinningPatrick Tracy; watch it HERE. Halfway to Home was largely recorded in Nashville, and coproduced by Rita and Nathan Chapman (Taylor Swift, Keith Urban), with Ron Aniello (Bruce Springsteen) and John Shanks (Bon Jovi, Sheryl Crow) also contributing as producers. Many of the songs were cowritten with an AList group including Kristian Bush, Grammy winner Liz Rose, Mozella (Kelly Clarkson, Miley Cyrus), Mitch Allan (Demi Lovato), Kara DioGuardi (Pink, Kelly Clarkson) and Emily Schackleton. -

Council Grapples with Homeless Solutions
WWW.BEVERLYPRESS.COM INSIDE • City tightens tobacco sales Sunny and rules. pg. 3 hot, temps • Burglary crew around 90 sought. pg. 4 Volume 25 No. 35 Serving the West Hollywood, Hancock Park and Wilshire Communities August 27, 2015 Smart bikes pedal into nCouncil weighs merit of short-term rentals PLUM committee nWeHo next spring examines taxes and Riders will rent bikes for trips around the city impacts on neighbors By gregory cornfield Hollywood’s community develop- By gregory cornfield ment department directs the staff to Less than a week after its neigh- negotiate a contract with bors in Los Angeles approved the CycleHop, LLC, for the purchase, Los Angeles City Hall experi- Mobility Plan 2035 to coax people construction, installation, operation enced a very “shared” experience out of their cars, the West and maintenance of 150 “smart on Tuesday. After the city council Hollywood City Council approved bikes” to create the share system approved plans to allow services the creation and implementation of that is expected to launch in Spring like Uber and Lyft to operate at a citywide public bikeshare pro- 2016. According to the motion, the LAX, the planning, land use and gram. contract will be for a three-year management (PLUM) committee The motion from West opened discussion on a motion for See Short-term rentals page 24 the city to regulate services that share rooms instead of cars. In June, councilmen Mike Bonin, 11th District, and Herb photo by Gregory Cornfield Wesson, 10th District, introduced a motion that would legalize the Advocates raised their hands in support of allowing short-term rentals practice of hosts renting their extra during a packed hearing in city council chambers on Tuesday. -

Robotic and Human Lunar Missions Past and Future
VOL. 96 NO. 5 15 MAR 2015 Earth & Space Science News Robotic and Human Lunar Missions Past and Future Increasing Diversity in the Geosciences Do Tiny Mineral Grains Drive Plate Tectonics? Cover Lines Ways To Improve AGU FellowsCover Program Lines Cover Lines Recognize The Exceptional Scientific Contributions And Achievements Of Your Colleagues Union Awards • Prizes • Fellows • Medals Awards Prizes Ambassador Award Climate Communication Prize Edward A. Flinn III Award NEW The Asahiko Taira International Charles S. Falkenberg Award Scientific Ocean Drilling Research Prize Athlestan Spilhaus Award Medals International Award William Bowie Medal Excellence in Geophysical Education Award James B. Macelwane Medal Science for Solutions Award John Adam Fleming Medal Robert C. Cowen Award for Sustained Achievement in Maurice Ewing Medal Science Journalism Robert E. Horton Medal Walter Sullivan Award for Excellence Harry H. Hess Medal in Science Journalism – Features Inge Lehmann Medal David Perlman Award for Excellence in Science Journalism – News Roger Revelle Medal Fellows Scientific eminence in the Earth and space sciences through achievements in research, as demonstrated by one or more of the following: breakthrough or discovery; innovation in disciplinary science, cross-disciplinary science, instrument development, or methods development; or sustained scientific impact. Nominations Deadline: 15 March honors.agu.org Earth & Space Science News Contents 15 MARCH 2015 FEATURE VOLUME 96, ISSUE 5 13 Increasing Diversity in the Geosciences Studies show that increasing students’ “sense of belonging” may help retain underrepresented minorities in geoscience fields. A few programs highlight successes. MEETING REPORT Developing Databases 7 of Ancient Sea Level and Ice Sheet Extents RESEARCH SPOTLIGHT 8 COVER 26 How Robotic Probes Helped Humans Survival of Young Sardines Explore the Moon…and May Again Flushed Out to Open Ocean Despite favorable conditions within eddies Robotic probes paved the way for humankind’s giant leap to the Moon. -

Avril/Mai 2015 Sommaire
N° 87 – AVRIL/MAI 2015 A l'attention des artistes : pour nous informer de votre actualité, pour nous communiquer vos dates de concerts, pour nous faire parvenir les photos de vos formations, contactez Jacques : [email protected] SOMMAIRE ● Les news de Nashville : Country Rendez Vous Festival 2015, nouveautés, la série Nashville, par Alison ● Cd reviews : Carol Rich, Eddy Ray Cooper, par Jacques « Rockin’Boy » Dufour ● Les Mavericks à Paris, par Bruno Gadaut ● Portrait d'artiste : Dan Dickson, par Gérard Vieules ● Rencontre avec … Will des Subway Cowboys, par Jacques « Rockin'Boy » Dufour ● Les championnats de France dits country, par Pierre Vauthier ● Heather Myles à Saint Cyr au Mont d’Or, par Jacques « Rockin’Boy » Dufour ● Les news de Nashville : Blackjack Billy, Reba en duo avec Jennifer Nettles, Darius Rucker, nouveautés, Brooks and Dunn, par Alison ● Cd reviews : Tom Shepherd, Billy Yates, James Carothus, Doyle Lawson & Quicksilver ● Villette d’Anthon, 14 mars, par Jacques « Rockin’Boy » Dufour ● La gazette de Richmond : Cowboy, du rêve à la réalité, par Bruno Richmond ● Made in France, par Jacques « Rockin’Boy » Dufour ● L’agenda, par Jacques « Rockin’Boy » Dufour ● Radios Country sur le Net, par Gilles Bataille 01 Country Rendez vous festival l’affiche 2015 Cette année et ce pour la 28ème année consécutive, l’équipe du Country Rendez Vous Festival, s’est mobilisés pour nous offrir encore une superbe affiche. Vous pouvez d’ores et déjà noter dans vos agendas, les dates de ce méga festival, le 24, 25 et juillet 2015 c'est-à-dire le dernier week end de juillet ! Voici toute suite le détail de ce qui vous attend. -

Downtown Nashville Goodwill Launches Guided Public Tours
AmbassadorSUMMER 2015 Downtown Nashville Goodwill Launches Guided Public Tours Hundreds Attend Grand Opening in Clarksville Country Star Kristian Bush Greets Nashville Area Donors Judge Visits Store to Praise Probationer contents Ambassador SUMMER 2015 3 I Got it at Goodwill 4 Goodwill Success Stories 2015 President and CEO Matthew S. Bourlakas 6 Goodwill Week Recap Publisher Karl Houston Hundreds Attend Grand Opening Senior Director of Marketing & 8 of New Clarksville Goodwill Community Relations Editor and Writer Chris Fletcher Law Boosts Transparency, PR & Communications Manager 9 Accountability for Donation Bins Art Director EJ Kerr Local Goodwill Store Featured in Manager of Creative Services 10 Music Video Ambassador is a quarterly magazine published by Goodwill Industries of Goodwill Q&A with Country Middle Tennessee, Inc., 1015 Herman 11 Music Star Kristian Bush Street, Nashville, TN 37208. Downtown Nashville Goodwill For the nearest retail store, donation 12 center, or Career Solutions center, launches Guided Public Tours please call 800.545.9231 or visit www.giveit2goodwill.org. Goodwill Cares: Helping Students 13 Ambassador provides readers with and Families in Need stories of the events, activities and people who support the mission of Goodwill Industries of Middle Estate Donation: Couple’s Final Tennessee. We are pleased to provide 14 Gesture of Compassion, Generosity you this information and hope you will share our publication with others. Please note that the opinions 16 Real Estate Pickup Service expressed in Ambassador do not necessarily reflect the opinions or Goodwill Begins Round Up official position of management or 17 Program in Retail Stores employees of Goodwill Industries of Middle Tennessee, Inc. -

THE COWL News Co-Editor
Welcome Back to Friartown! 2015 - 2016 Page 2 News September 3, 2015 The New Face of PC Construction Projects are Underway on Campus by Meaghan Dodson ’17 KRISTINA HO ’18 / THE COWL News Co-Editor on campus As its 2017 centennial approaches, Providence College honors its past by looking towards its future—and, in particular, a future filled with major construction and renovation projects as part of a campus-wide transformation. Last year marked the completion of several key projects, including the award-winning Hendricken Field and Ray Treacy Track. Construction was far from over, however, as renovations continued throughout the summer, specifically focusing on the vacant residential halls. John Sweeney, the senior vice president for finance and business/ CFO, confirmed that the College tackled “essentials” during summer 2015. Aquinas Hall’s 86-year-old roof was replaced with a new copper one, affording greater structure and durability to one of the oldest buildings on campus. The 30-year-old roofs of DiTraglia and Mal Brown were Anderson Stadium and Chapey Field are expected to be completed by December 2015. likewise replaced. Phase Two of the Residence Hall Wireless Upgrade was also completed, maintaining and even increasing its that the College has named DIMEO construct an atrium in place of the and Sweeney was pleased to announce current number of parking spots. Construction as the firm overseeing the patio that currently connects Alumni that McVinney Hall, Suites Hall, and A softball field behind Suites Hall is project. DIMEO is also responsible for Hall and Slavin Center. All of the Davis Hall are now receiving faster expected to be completed by Sept. -

Disappearing Deterrent THOUSANDS of NUCLEAR WEAPONS WILL SOON BE TOO OLD to COUNT ON
THE MAGAZINE OF TECHNOLOGY INSIDERS 03.09 Disappearing Deterrent THOUSANDS OF NUCLEAR WEAPONS WILL SOON BE TOO OLD TO COUNT ON. HERE’S WHY FIXING THEM MAKES MORE SENSE THAN REPLACING THEM BRINGING PROSTHETIC ARMS INTO THE 21ST CENTURY YOUR PLUG-IN CAR: NOT SO GREEN AFTER ALL THE LASER KITTY TEASER AND OTHER PATENT NONSENSE www.spectrum.ieee.org volume 46 number 3 north american 03.09 UPDATE 11 FUSION FACTORY STARTS UP The US $4 billion National Ignition Facility opens for business. By Willie D. Jones 12 WILL WASHINGTON KICK-START THE U.S. BATTERY BIZ? 14 GAMING IN THE CLOUDS 15 A STOWAWAY MISSION TO THE MOON 16 SIGN LANGUAGE BY CELLPHONE 18 THE BIG PICTURE Here’s a big shocker! OPINION 7 SPECTRAL LINES In hard times, Google has lots of money for tilting at windmills. 10 FORUM Readers offer feedback on our January Winners & Losers—and a solution to RepRap’s self-reproduction problems. 18 25 REFLECTIONS Upgrading to a new computer is A LITTLE COVER STORY a necessary evil. By Robert W. Lucky TURBULENCE: By zapping model aircraft, 26 WHAT ABOUT DEPARTMENTS Lightning 4 BACK STORY Technologies is THE NUKES? An article in this issue has roots in the helping engineers The United States has added no new warheads to its nuclear arsenal meeting of two geeky kids 30 years ago. protect electronic in more than two decades. As the existing stockpile ages, a debate now systems on 6 CONTRIBUTORS real aircraft rages over how best to maintain its safety, reliability, and effectiveness from storms. -

Liner Notes: Songwriters, Stories and Music with Rita Wilson and Friends
Media Contact: Katy Sweet & Associates [email protected]/310.479.2333 LINER NOTES: SONGWRITERS, STORIES AND MUSIC WITH RITA WILSON AND FRIENDS JESSI ALEXANDER, KRISTIAN BUSH, RICHARD MARX, JON RANDALL, LINDY ROBBINS, BILLY STEINBERG AND OTHER GUEST MUSICIANS WILL JOIN WILSON FOR AN EXCLUSIVE TWO- WEEKEND DECEMBER ENGAGEMENT IN THE INTIMATE AUDREY SKIRBALL KENIS THEATER LOS ANGELES (October 29, 2015) – Rita Wilson brings her vocal and songwriting talents to the Audrey Skirball Kenis Theater at the Geffen Playhouse for eight shows in December. For each performance, Wilson will be joined by special guests for an evening of songwriters telling the stories behind their songs. The shows will be performed in the round with the audience surrounding the artists, providing an up-close and personal experience. They include: Jessi Alexander, Kristian Bush, Richard Marx, Jon Randall, Lindy Robbins, Billy Steinberg among others. Wilson is no stranger to the Geffen, having appeared in numerous productions over the theater’s 20-year history, including Dinner with Friends and Love, Loss and What I Wore. In 2009, she was presented the Distinction in Theater Award at the annual Backstage at the Geffen event. Well-known as an actress (It’s Complicated, Sleepless in Seattle, a recurring role in CBS’s The Good Wife, HBO’s award-winning series, Girls and, most recently on Broadway in Larry David’s smash hit, Fish in the Dark), and as a film producer (Mamma Mia!, My Big Fat Greek Wedding and its upcoming sequel), her first love is music. Wilson achieved her dream with the 2012 Decca Records release of her debut album, AM/FM, an intimate, elegant and beautifully-sung collection of classics from the ‘60s and ‘70s that, taken together, make up the soundtrack of her young life. -

Student Matinee Series Troubadour Study Guide
Student Matinee Series Troubadour Study Guide Created by Chamblee Charter High School Musical Theatre Class of Ms. Linda Lirette As part of the Alliance Arts for Learning’s Dramaturgy by Students Under the guidance of Teaching Artist Rachel Jones Troubadour at the Alliance Theatre Page 1 of 22 Table of Contents Costume rendering by Costume Designer Lex Liang Preparing Students for the Performance 3 Artist Bios 5 Character List 11 Synopsis 12 Troubadour on YouTube 13 A Brief Timeline of Nashville as an American Musical Capital 14 Changes in Country Music 15 History of Nudie Suits 16 Classroom Discussion Questions & Writing Prompts 17 Historical Understanding of Seizures (printable) 18 Country Music in the 1950s (printable) 19 Nashville in the 1950s (printable) 20 Nudie Suits (printable) 21 Cycle of Abuse (printable) 22 Troubadour at the Alliance Theatre Page 2 of 22 Preparing Students for the Performance DISCUSS THE STORY Before you come to the show, review the synopsis of Troubadour with your students (p 11) and consider using the pre-show discussion prompts (p 21) to prime the students with various themes and ideas that they will encounter when they view the play. OTHER QUESTIONS Does the theatre have a dress code? What is the typical attire? Don’t stress about your dress. In most cases, school dress codes will also represent appropriate attire for visiting the theater. Note that all of our facilities are air conditioned/heated for your comfort — please dress appropriately. How can I know if a particular show will be appropriate for my students? Information regarding content disclaimers and recommended ages for particular shows may be found on the specific production information page by viewing our production listings. -
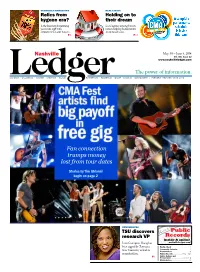
Fan Connection Trumps Money Lost from Tour Dates
GUERRILLA MARKETING Relics from bygone era? Is the Internet threatening your sales staff with extinction? Doesn’t have to. REAL ESTATE Holding on to P3 Nashville their dream Local agency among best in nation helping homeowners avoid foreclosure. DaviLedgerDson • Williamson • sUmnER • ChEatham • Wilson RUthERFoRD • R P13 oBERtson • maURY • DiCkson • montGomERY | May 30 – June 5, 2014 www.nashvilleledger.com The power of information. Vol. 40 | Issue 22 F oR mer lY WESTVIEW sinCE 1978 Page 13 Fan connection trumps money Dec.: lost from tour dates Dec.: Keith Turner, Ratliff, Jeanan Mills Stuart, Resp.: Kimberly Dawn Wallace, Atty: Mary C Lagrone, 08/24/2010, 10P1318 In re: Jeanan Mills Stuart, Princess Angela Gates, Jeanan Mills Stuart, Princess Angela Gates,Dec.: Resp.: Kim Prince Patrick, Angelo Terry Patrick, Gates, Atty: Monica D Edwards, 08/25/2010, 10P1326 In re: Keith Turner, TN Dept Of Correction, www.westviewonline.com TN Dept Of Correction, Resp.: Johnny Moore,Dec.: Melinda Atty: Bryce L Tomlinson, Coatney, Resp.: Pltf(s): Rodney A Hall, Pltf Atty(s): n/a, 08/27/2010, 10P1336 Stories by Tim Ghianni Pltf(s): Sandra Heavilon, In re: Kim Patrick, Terry Patrick, Resp.: Jewell Tinnon, Atty: Ronald Andre Stewart, 08/24/2010,Dec.: Seton Corp 10P1322 Insurance Company, Dec.: Regions Bank, Resp.: Leigh A Collins, In re: Melinda L Tomlinson, Def(s): Jit Steel Transport Inc, National Fire Insurance Company, Elizabeth D Hale, Atty: William Warner McNeilly, 08/24/2010, begin on page 2 Def Atty(s): J Brent Moore, 08/26/2010, 10C3316 10P1321