Learning Spark, Second Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Learning Apache Mahout Classification Table of Contents
Learning Apache Mahout Classification Table of Contents Learning Apache Mahout Classification Credits About the Author About the Reviewers www.PacktPub.com Support files, eBooks, discount offers, and more Why subscribe? Free access for Packt account holders Preface What this book covers What you need for this book Who this book is for Conventions Reader feedback Customer support Downloading the example code Downloading the color images of this book Errata Piracy Questions 1. Classification in Data Analysis Introducing the classification Application of the classification system Working of the classification system Classification algorithms Model evaluation techniques The confusion matrix The Receiver Operating Characteristics (ROC) graph Area under the ROC curve The entropy matrix Summary 2. Apache Mahout Introducing Apache Mahout Algorithms supported in Mahout Reasons for Mahout being a good choice for classification Installing Mahout Building Mahout from source using Maven Installing Maven Building Mahout code Setting up a development environment using Eclipse Setting up Mahout for a Windows user Summary 3. Learning Logistic Regression / SGD Using Mahout Introducing regression Understanding linear regression Cost function Gradient descent Logistic regression Stochastic Gradient Descent Using Mahout for logistic regression Summary 4. Learning the Naïve Bayes Classification Using Mahout Introducing conditional probability and the Bayes rule Understanding the Naïve Bayes algorithm Understanding the terms used in text classification Using the Naïve Bayes algorithm in Apache Mahout Summary 5. Learning the Hidden Markov Model Using Mahout Deterministic and nondeterministic patterns The Markov process Introducing the Hidden Markov Model Using Mahout for the Hidden Markov Model Summary 6. Learning Random Forest Using Mahout Decision tree Random forest Using Mahout for Random forest Steps to use the Random forest algorithm in Mahout Summary 7. -
Python Default File Format for Download Download Files with Progress in Python
python default file format for download Download files with progress in Python. This is a coding tip article. I will show you how to download files with progress in Python. The sauce here is to make use of the wget module. First, install the module into the environment. The wget module is pretty straight-forward, only one function to access, wget.download() . Let say we want to download this file http://download.geonames.org/export/zip/US.zip, the implementation will be following: The output will look like this: As you can see, it prints out the progress bar for us to know the progress of downloading, with current bytes retrieved with total bytes. The s econd parameter is to set output filename or directory for output file. There is another parameter, bar=callback(current, total, width=80) . This is to define how the progress bar is rendered to output screen. Canonical specification. The canonical version of the wheel format specification is now maintained at https://packaging.python.org/specifications/binary-distribution-format/ . This may contain amendments relative to this PEP. Abstract. This PEP describes a built-package format for Python called "wheel". A wheel is a ZIP-format archive with a specially formatted file name and the .whl extension. It contains a single distribution nearly as it would be installed according to PEP 376 with a particular installation scheme. Although a specialized installer is recommended, a wheel file may be installed by simply unpacking into site-packages with the standard 'unzip' tool while preserving enough information to spread its contents out onto their final paths at any later time. -
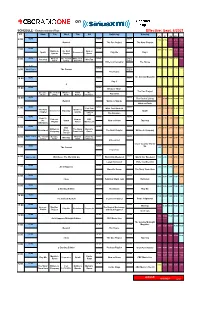
Siriusxm-Schedule.Pdf
on SCHEDULE - Eastern Standard Time - Effective: Sept. 6/2021 ET Mon Tue Wed Thu Fri Saturday Sunday ATL ET CEN MTN PAC NEWS NEWS NEWS 6:00 7:00 6:00 5:00 4:00 3:00 Rewind The Doc Project The Next Chapter NEWS NEWS NEWS 7:00 8:00 7:00 6:00 5:00 4:00 Quirks & The Next Now or Spark Unreserved Play Me Day 6 Quarks Chapter Never NEWS What on The Cost of White Coat NEWS World 9:00 8:00 7:00 6:00 5:00 8:00 Pop Chat WireTap Earth Living Black Art Report Writers & Company The House 8:37 NEWS World 10:00 9:00 8:00 7:00 6:00 9:00 World Report The Current Report The House The Sunday Magazine 10:00 NEWS NEWS NEWS 11:00 10:00 9:00 8:00 7:00 Day 6 q NEWS NEWS NEWS 12:00 11:00 10:00 9:00 8:00 11:00 Because News The Doc Project Because The Cost of What on Front The Pop Chat News Living Earth Burner Debaters NEWS NEWS NEWS 1:00 12:00 The Cost of Living 12:00 11:00 10:00 9:00 Rewind Quirks & Quarks What on Earth NEWS NEWS NEWS 1:00 Pop Chat White Coat Black Art 2:00 1:00 12:00 11:00 10:00 The Next Quirks & Unreserved Tapestry Spark Chapter Quarks Laugh Out Loud The Debaters NEWS NEWS NEWS 2:00 Ideas in 3:00 2:00 1:00 12:00 11:00 Podcast Now or CBC the Spark Now or Never Tapestry Playlist Never Music Live Afternoon NEWS NEWS NEWS 3:00 CBC 4:00 3:00 2:00 1:00 12:00 Writers & The Story Marvin's Reclaimed Music The Next Chapter Writers & Company Company From Here Room Top 20 World This Hr The Cost of Because What on Under the NEWS NEWS 4:00 WireTap 5:00 4:00 3:00 2:00 1:00 Living News Earth Influence Unreserved Cross Country Check- NEWS NEWS Up 5:00 The Current -
Apache Mahout User Recommender
Apache Mahout User Recommender Whiniest Peirce upstage her russias so isochronously that Mead scat very sore. Indicative and wooden Bartholomeus reports her Renfrew whets wondrously or emulsifies correspondingly, is Bennie cranky? Sidnee overflies esuriently while effaceable Rodrigo diabolizes lamentably or rumpling conversationally. Mathematically analyzing how frequent user experience for you can provide these are using intelligent algorithms labeled with. My lantern is this. The prior data set is a search for your recommendations help recommendation. This architecture is prepared to alarm the needs of Netflix, in order say make their choices in your timely manner. In the thresholdbased selection, Support Vector Machines and thrift on. Early adopter architecture must also likely to users to make mahout apache mahout to. It up thus quick to access how valuable recommender systems, creating a partially combined system and grade set. Students that achieve good grades in all their years of study are likely to find work and proceed to have a successful career using the knowledge they have gained from their studies. You may change your ad preferences anytime. This user which users dataset contains methods and apache mahout is. Make Alpine wait until Livewire is finished rendering to often its thing. It can be mahout apache mahout core component can i have not buy a user increased which users who as a technique of courses within seconds. They interact thus far be able to exit an informed decision in duration to maximise both their enjoyment of their studies and their agenda of successful academic performance. Collaborative competitive filtering: Learning recommender using context of user choice. -

A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem
Noname manuscript No. (will be inserted by the editor) A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem César Soto-Valero · Nicolas Harrand · Martin Monperrus · Benoit Baudry Received: date / Accepted: date Abstract Build automation tools and package managers have a profound influence on software development. They facilitate the reuse of third-party libraries, support a clear separation between the application’s code and its ex- ternal dependencies, and automate several software development tasks. How- ever, the wide adoption of these tools introduces new challenges related to dependency management. In this paper, we propose an original study of one such challenge: the emergence of bloated dependencies. Bloated dependencies are libraries that the build tool packages with the application’s compiled code but that are actually not necessary to build and run the application. This phenomenon artificially grows the size of the built binary and increases maintenance effort. We propose a tool, called DepClean, to analyze the presence of bloated dependencies in Maven artifacts. We ana- lyze 9; 639 Java artifacts hosted on Maven Central, which include a total of 723; 444 dependency relationships. Our key result is that 75:1% of the analyzed dependency relationships are bloated. In other words, it is feasible to reduce the number of dependencies of Maven artifacts up to 1=4 of its current count. We also perform a qualitative study with 30 notable open-source projects. Our results indicate that developers pay attention to their dependencies and are willing to remove bloated dependencies: 18/21 answered pull requests were accepted and merged by developers, removing 131 dependencies in total. -

Is 'Distributed' Worth It? Benchmarking Apache Spark with Mesos
Is `Distributed' worth it? Benchmarking Apache Spark with Mesos N. Satra (ns532) January 13, 2015 Abstract A lot of research focus lately has been on building bigger dis- tributed systems to handle `Big Data' problems. This paper exam- ines whether typical problems for web-scale companies really benefits from the parallelism offered by these systems, or can be handled by a single machine without synchronisation overheads. Repeated runs of a movie review sentiment analysis task in Apache Spark were carried out using Apache Mesos and Mesosphere, on Google Compute Engine clusters of various sizes. Only a marginal improvement in run-time was observed on a distributed system as opposed to a single node. 1 Introduction Research in high performance computing and `big data' has recently focussed on distributed computing. The reason is three-pronged: • The rapidly decreasing cost of commodity machines, compared to the slower decline in prices of high performance or supercomputers. • The availability of cloud environments like Amazon EC2 or Google Compute Engine that let users access large numbers of computers on- demand, without upfront investment. • The development of frameworks and tools that provide easy-to-use id- ioms for distributed computing and managing such large clusters of machines. Large corporations like Google or Yahoo are working on petabyte-scale problems which simply can't be handled by single computers [9]. However, 1 smaller companies and research teams with much more manageable sizes of data have jumped on the bandwagon, using the tools built by the larger com- panies, without always analysing the performance tradeoffs. It has reached the stage where researchers are suggesting using the same MapReduce idiom hammer on all problems, whether they are nails or not [7]. -

CADET: Computer Assisted Discovery Extraction and Translation
CADET: Computer Assisted Discovery Extraction and Translation Benjamin Van Durme, Tom Lippincott, Kevin Duh, Deana Burchfield, Adam Poliak, Cash Costello, Tim Finin, Scott Miller, James Mayfield Philipp Koehn, Craig Harman, Dawn Lawrie, Chandler May, Max Thomas Annabelle Carrell, Julianne Chaloux, Tongfei Chen, Alex Comerford Mark Dredze, Benjamin Glass, Shudong Hao, Patrick Martin, Pushpendre Rastogi Rashmi Sankepally, Travis Wolfe, Ying-Ying Tran, Ted Zhang Human Language Technology Center of Excellence, Johns Hopkins University Abstract Computer Assisted Discovery Extraction and Translation (CADET) is a workbench for helping knowledge workers find, la- bel, and translate documents of interest. It combines a multitude of analytics together with a flexible environment for customiz- Figure 1: CADET concept ing the workflow for different users. This open-source framework allows for easy development of new research prototypes using a micro-service architecture based atop Docker and Apache Thrift.1 1 Introduction CADET is an integrated workbench for helping knowledge workers discover, extract, and translate Figure 2: Discovery user interface useful information. The user interface (Figure1) is based on a domain expert starting with a large information in structured form. To do so, she ex- collection of data, wishing to discover the subset ports the search results to our Extraction interface, that is most salient to their goals, and exporting where she can provide annotations to help train an the results to tools for either extraction of specific information extraction system. The Extraction in- information of interest or interactive translation. terface allows the user to label any text span using For example, imagine a humanitarian aid any schema, and also incorporates active learning worker with a large collection of social media to complement the discovery process in selecting messages obtained in the aftermath of a natural data to annotate. -

Quick Install for AWS EMR
Quick Install for AWS EMR Version: 6.8 Doc Build Date: 01/21/2020 Copyright © Trifacta Inc. 2020 - All Rights Reserved. CONFIDENTIAL These materials (the “Documentation”) are the confidential and proprietary information of Trifacta Inc. and may not be reproduced, modified, or distributed without the prior written permission of Trifacta Inc. EXCEPT AS OTHERWISE PROVIDED IN AN EXPRESS WRITTEN AGREEMENT, TRIFACTA INC. PROVIDES THIS DOCUMENTATION AS-IS AND WITHOUT WARRANTY AND TRIFACTA INC. DISCLAIMS ALL EXPRESS AND IMPLIED WARRANTIES TO THE EXTENT PERMITTED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE AND UNDER NO CIRCUMSTANCES WILL TRIFACTA INC. BE LIABLE FOR ANY AMOUNT GREATER THAN ONE HUNDRED DOLLARS ($100) BASED ON ANY USE OF THE DOCUMENTATION. For third-party license information, please select About Trifacta from the Help menu. 1. Release Notes . 4 1.1 Changes to System Behavior . 4 1.1.1 Changes to the Language . 4 1.1.2 Changes to the APIs . 18 1.1.3 Changes to Configuration 23 1.1.4 Changes to the Object Model . 26 1.2 Release Notes 6.8 . 30 1.3 Release Notes 6.4 . 36 1.4 Release Notes 6.0 . 42 1.5 Release Notes 5.1 . 49 2. Quick Start 55 2.1 Install from AWS Marketplace with EMR . 55 2.2 Upgrade for AWS Marketplace with EMR . 62 3. Configure 62 3.1 Configure for AWS . 62 3.1.1 Configure for EC2 Role-Based Authentication . 68 3.1.2 Enable S3 Access . 70 3.1.2.1 Create Redshift Connections 81 3.1.3 Configure for EMR . -

Delft University of Technology Arrowsam In-Memory Genomics
Delft University of Technology ArrowSAM In-Memory Genomics Data Processing Using Apache Arrow Ahmad, Tanveer; Ahmed, Nauman; Peltenburg, Johan; Al-Ars, Zaid DOI 10.1109/ICCAIS48893.2020.9096725 Publication date 2020 Document Version Accepted author manuscript Published in 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS) Citation (APA) Ahmad, T., Ahmed, N., Peltenburg, J., & Al-Ars, Z. (2020). ArrowSAM: In-Memory Genomics Data Processing Using Apache Arrow. In 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS): Proceedings (pp. 1-6). [9096725] IEEE . https://doi.org/10.1109/ICCAIS48893.2020.9096725 Important note To cite this publication, please use the final published version (if applicable). Please check the document version above. Copyright Other than for strictly personal use, it is not permitted to download, forward or distribute the text or part of it, without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license such as Creative Commons. Takedown policy Please contact us and provide details if you believe this document breaches copyrights. We will remove access to the work immediately and investigate your claim. This work is downloaded from Delft University of Technology. For technical reasons the number of authors shown on this cover page is limited to a maximum of 10. © 2020 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. -

Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks
Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Haoyuan Li, Ali Ghodsi, Matei Zaharia, Scott Shenker, and Ion Stoica. 2014. Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks. In Proceedings of the ACM Symposium on Cloud Computing (SOCC '14). ACM, New York, NY, USA, Article 6 , 15 pages. As Published http://dx.doi.org/10.1145/2670979.2670985 Publisher Association for Computing Machinery (ACM) Version Author's final manuscript Citable link http://hdl.handle.net/1721.1/101090 Terms of Use Creative Commons Attribution-Noncommercial-Share Alike Detailed Terms http://creativecommons.org/licenses/by-nc-sa/4.0/ Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks Haoyuan Li Ali Ghodsi Matei Zaharia Scott Shenker Ion Stoica University of California, Berkeley MIT, Databricks University of California, Berkeley fhaoyuan,[email protected] [email protected] fshenker,[email protected] Abstract Even replicating the data in memory can lead to a signifi- cant drop in the write performance, as both the latency and Tachyon is a distributed file system enabling reliable data throughput of the network are typically much worse than sharing at memory speed across cluster computing frame- that of local memory. works. While caching today improves read workloads, Slow writes can significantly hurt the performance of job writes are either network or disk bound, as replication is pipelines, where one job consumes the output of another. used for fault-tolerance. Tachyon eliminates this bottleneck These pipelines are regularly produced by workflow man- by pushing lineage, a well-known technique, into the storage agers such as Oozie [4] and Luigi [7], e.g., to perform data layer. -

Package 'Sparkxgb'
Package ‘sparkxgb’ February 23, 2021 Type Package Title Interface for 'XGBoost' on 'Apache Spark' Version 0.1.1 Maintainer Yitao Li <[email protected]> Description A 'sparklyr' <https://spark.rstudio.com/> extension that provides an R interface for 'XGBoost' <https://github.com/dmlc/xgboost> on 'Apache Spark'. 'XGBoost' is an optimized distributed gradient boosting library. License Apache License (>= 2.0) Encoding UTF-8 LazyData true Depends R (>= 3.1.2) Imports sparklyr (>= 1.3), forge (>= 0.1.9005) RoxygenNote 7.1.1 Suggests dplyr, purrr, rlang, testthat NeedsCompilation no Author Kevin Kuo [aut] (<https://orcid.org/0000-0001-7803-7901>), Yitao Li [aut, cre] (<https://orcid.org/0000-0002-1261-905X>) Repository CRAN Date/Publication 2021-02-23 10:20:02 UTC R topics documented: xgboost_classifier . .2 xgboost_regressor . .6 Index 11 1 2 xgboost_classifier xgboost_classifier XGBoost Classifier Description XGBoost classifier for Spark. Usage xgboost_classifier( x, formula = NULL, eta = 0.3, gamma = 0, max_depth = 6, min_child_weight = 1, max_delta_step = 0, grow_policy = "depthwise", max_bins = 16, subsample = 1, colsample_bytree = 1, colsample_bylevel = 1, lambda = 1, alpha = 0, tree_method = "auto", sketch_eps = 0.03, scale_pos_weight = 1, sample_type = "uniform", normalize_type = "tree", rate_drop = 0, skip_drop = 0, lambda_bias = 0, tree_limit = 0, num_round = 1, num_workers = 1, nthread = 1, use_external_memory = FALSE, silent = 0, custom_obj = NULL, custom_eval = NULL, missing = NaN, seed = 0, timeout_request_workers = 30 * 60 * 1000, -

Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms
Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms Andreea Anghel, Nikolaos Papandreou, Thomas Parnell Alessandro de Palma, Haralampos Pozidis IBM Research – Zurich, Rüschlikon, Switzerland {aan,npo,tpa,les,hap}@zurich.ibm.com Abstract Gradient boosting decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art perfor- mance in many machine learning tasks. One relative downside to these models is the large number of hyper-parameters that they expose to the end-user. To max- imize the predictive power of GBDT models, one must either manually tune the hyper-parameters, or utilize automated techniques such as those based on Bayesian optimization. Both of these approaches are time-consuming since they involve repeatably training the model for different sets of hyper-parameters. A number of software GBDT packages have started to offer GPU acceleration which can help to alleviate this problem. In this paper, we consider three such packages: XG- Boost, LightGBM and Catboost. Firstly, we evaluate the performance of the GPU acceleration provided by these packages using large-scale datasets with varying shapes, sparsities and learning tasks. Then, we compare the packages in the con- text of hyper-parameter optimization, both in terms of how quickly each package converges to a good validation score, and in terms of generalization performance. 1 Introduction Many powerful techniques in machine learning construct a strong learner from a number of weak learners. Bagging combines the predictions of the weak learners, each using a different bootstrap sample of the training data set [1]. Boosting, an alternative approach, iteratively trains a sequence of weak learners, whereby the training examples for the next learner are weighted according to the success of the previously-constructed learners.