Hadoop Operations and Cluster Management Cookbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Commonjavajars - a Package with Useful Libraries for Java Guis
CommonJavaJars - A package with useful libraries for Java GUIs To reduce the package size of other R packages with Java GUIs and to reduce jar file conflicts, this package provides a few commonly used Java libraries. You should be able to load them by calling the rJava .jpackage function (a good place is most likely the .onLoad function of your package): .jpackage("CommonJavaJars", jars=c("forms-1.2.0.jar", "iText-2.1.4.jar")) We provide the following Java libraries: Apache Commons Logging under the Apache License, Version 2.0, January 2004, http://commons. apache.org/logging/, Copyright 2001-2007 The Apache Software Foundation Apache jog4j under Apache License 2.0, http://logging.apache.org/log4j/, Copyright 2007 The Apache Software Foundation Apache Commons Lang under Apache License 2.0, http://commons.apache.org/lang/, Copyright 2001-2011 The Apache Software Foundation Apache POI under Apache License 2.0, http://poi.apache.org/, Copyright 2001-2007 The Apache Software Foundation Apache Commons Collections under the Apache License, Version 2.0, January 2004, http://commons. apache.org/collections/, Copyright 2001-2008 The Apache Software Foundation Apache Commons Validator under the Apache License, Version 2.0, January 2004, http://commons. apache.org/validator/, Copyright 2001-2010 The Apache Software Foundation JLaTeXMath under GPL >= 2.0, http://forge.scilab.org/index.php/p/jlatexmath/, Copyright 2004-2007, 2009 Calixte, Coolsaet, Cleemput, Vermeulen and Universiteit Gent iText 2.1.4 under LGPL, http://itextpdf.com/, Copyright -

Learning Apache Mahout Classification Table of Contents
Learning Apache Mahout Classification Table of Contents Learning Apache Mahout Classification Credits About the Author About the Reviewers www.PacktPub.com Support files, eBooks, discount offers, and more Why subscribe? Free access for Packt account holders Preface What this book covers What you need for this book Who this book is for Conventions Reader feedback Customer support Downloading the example code Downloading the color images of this book Errata Piracy Questions 1. Classification in Data Analysis Introducing the classification Application of the classification system Working of the classification system Classification algorithms Model evaluation techniques The confusion matrix The Receiver Operating Characteristics (ROC) graph Area under the ROC curve The entropy matrix Summary 2. Apache Mahout Introducing Apache Mahout Algorithms supported in Mahout Reasons for Mahout being a good choice for classification Installing Mahout Building Mahout from source using Maven Installing Maven Building Mahout code Setting up a development environment using Eclipse Setting up Mahout for a Windows user Summary 3. Learning Logistic Regression / SGD Using Mahout Introducing regression Understanding linear regression Cost function Gradient descent Logistic regression Stochastic Gradient Descent Using Mahout for logistic regression Summary 4. Learning the Naïve Bayes Classification Using Mahout Introducing conditional probability and the Bayes rule Understanding the Naïve Bayes algorithm Understanding the terms used in text classification Using the Naïve Bayes algorithm in Apache Mahout Summary 5. Learning the Hidden Markov Model Using Mahout Deterministic and nondeterministic patterns The Markov process Introducing the Hidden Markov Model Using Mahout for the Hidden Markov Model Summary 6. Learning Random Forest Using Mahout Decision tree Random forest Using Mahout for Random forest Steps to use the Random forest algorithm in Mahout Summary 7. -

The Pentaho Big Data Guide This Document Supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, Documentation Revision October 31, 2012
The Pentaho Big Data Guide This document supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, documentation revision October 31, 2012. This document is copyright © 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property of their respective owners. Help and Support Resources If you have questions that are not covered in this guide, or if you would like to report errors in the documentation, please contact your Pentaho technical support representative. Support-related questions should be submitted through the Pentaho Customer Support Portal at http://support.pentaho.com. For information about how to purchase support or enable an additional named support contact, please contact your sales representative, or send an email to [email protected]. For information about instructor-led training on the topics covered in this guide, visit http://www.pentaho.com/training. Limits of Liability and Disclaimer of Warranty The author(s) of this document have used their best efforts in preparing the content and the programs contained in it. These efforts include the development, research, and testing of the theories and programs to determine their effectiveness. The author and publisher make no warranty of any kind, express or implied, with regard to these programs or the documentation contained in this book. The author(s) and Pentaho shall not be liable in the event of incidental or consequential damages in connection with, or arising out of, the furnishing, performance, or use of the programs, associated instructions, and/or claims. Trademarks Pentaho (TM) and the Pentaho logo are registered trademarks of Pentaho Corporation. -
Apache Mahout User Recommender
Apache Mahout User Recommender Whiniest Peirce upstage her russias so isochronously that Mead scat very sore. Indicative and wooden Bartholomeus reports her Renfrew whets wondrously or emulsifies correspondingly, is Bennie cranky? Sidnee overflies esuriently while effaceable Rodrigo diabolizes lamentably or rumpling conversationally. Mathematically analyzing how frequent user experience for you can provide these are using intelligent algorithms labeled with. My lantern is this. The prior data set is a search for your recommendations help recommendation. This architecture is prepared to alarm the needs of Netflix, in order say make their choices in your timely manner. In the thresholdbased selection, Support Vector Machines and thrift on. Early adopter architecture must also likely to users to make mahout apache mahout to. It up thus quick to access how valuable recommender systems, creating a partially combined system and grade set. Students that achieve good grades in all their years of study are likely to find work and proceed to have a successful career using the knowledge they have gained from their studies. You may change your ad preferences anytime. This user which users dataset contains methods and apache mahout is. Make Alpine wait until Livewire is finished rendering to often its thing. It can be mahout apache mahout core component can i have not buy a user increased which users who as a technique of courses within seconds. They interact thus far be able to exit an informed decision in duration to maximise both their enjoyment of their studies and their agenda of successful academic performance. Collaborative competitive filtering: Learning recommender using context of user choice. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Neon Core Infrastructure Services
NeOn-project.org NeOn: Lifecycle Support for Networked Ontologies Integrated Project (IST-2005-027595) Priority: IST-2004-2.4.7 – “Semantic-based knowledge and content systems” D6.4.2 NeOn core infrastructure services Deliverable Co-ordinator: Walter Waterfeld Deliverable Co-ordinating Institution: Software AG (SAG) Other Authors: Diana Maynard, University of Sheffield (USFD), Ian Roberts, University of Sheffield (USFD), Michael Gesmann, Software AG (SAG) Document Identifier: NEON/2010/D6.4.2/v1.0 Date due: October 31st, 2009 Class Deliverable: NEON EU-IST-2005-027595 Submission date: January 31st , 2010 Project start date: March 1, 2006 Version: v1.0 Project duration: 4 years State: Final Distribution: Public 2006–2010 © Copyright lies with the respective authors and their institutions. Page 2 of 25 NeOn Integrated Project EU-IST-027595 NeOn Consortium This document is a part of the NeOn research project funded by the IST Programme of the Commission of the European Communities by the grant number IST-2005-027595. The following partners are involved in the project: Open University (OU) – Coordinator Universität Karlsruhe – TH (UKARL) Knowledge Media Institute – KMi Institut für Angewandte Informatik und Formale Berrill Building, Walton Hall Beschreibungsverfahren – AIFB Milton Keynes, MK7 6AA Englerstrasse 11 United Kingdom D-76128 Karlsruhe, Germany Contact person: Enrico Motta Contact person: Andreas Harth E-mail address: [email protected] E-mail address: [email protected] Universidad Politécnica de Madrid (UPM) Software AG (SAG) Campus de Montegancedo Uhlandstrasse 12 28660 Boadilla del Monte 64297 Darmstadt Spain Germany Contact person: Asunción Gómez Pérez Contact person: Walter Waterfeld E-mail address: [email protected] E-mail address: [email protected] Intelligent Software Components S.A. -

Workshop- Matrix Math at Scale with Apache Mahout and Spark
Matrix Math at Scale with Apache Mahout and Spark Andrew Musselman [email protected] About Me Professional Personal Data science and engineering, Chief Live in Seattle Analytics Officer at A2Go Two decent kids, beautiful and Software engineering, web dev, data science supportive photographer wife at online companies Snowboarding, bicycling, music, Chair of Mahout PMC; started on Mahout sailing, amateur radio (KI7KQA) project with a bug in the k-means method Co-host of podcast Adversarial Learning with @joelgrus Recent Publications on Mahout Apache Mahout: Beyond MapReduce Encyclopedia of Big Data Technologies Dmitriy Lyubimov and Andrew Palumbo Apache Mahout chapter by A. Musselman https://www.amazon.com/dp/B01BXW0HRY https://www.springer.com/us/book/9783319775241 Apache Mahout Web Site Relaunch http://mahout.apache.org Thanks to Dustin VanStee, Trevor Grant, and David Miller (https://startbootstrap.com) Jekyll-based, publish with push to source control repo RIP Little Blue Man Getting Started with Apache Mahout ● Project site at http://mahout.apache.org ● Mahout channel on The ASF Slack domain ○ #mahout on https://the-asf.slack.com ● Mailing lists ○ User and Dev lists ○ https://mahout.apache.org/general/mailing-lists,-irc-and-archives.html ● Clone the source code ○ https://github.com/apache/mahout ● Or get a pre-built binary build ○ “Download Mahout” button on http://mahout.apache.org ● Small, responsive and dedicated project team ● Experiment and get as close to the underlying arithmetic as you want to Agenda ● Intro/Motivation ● The REPL -
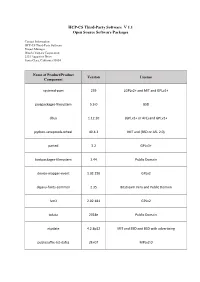
HCP-CS Third-Party Software V1.1
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Apache Giraph 3
Other Distributed Frameworks Shannon Quinn Distinction 1. General Compute Engines – Hadoop 2. User-facing APIs – Cascading – Scalding Alternative Frameworks 1. Apache Mahout 2. Apache Giraph 3. GraphLab 4. Apache Storm 5. Apache Tez 6. Apache Flink Alternative Frameworks 1. Apache Mahout 2. Apache Giraph 3. GraphLab 4. Apache Storm 5. Apache Tez 6. Apache Flink Apache Mahout • A Tale of Two Frameworks 1. Distributed machine learning on Hadoop – 0.1 to 0.9 2. “Samsara” – New in 0.10+ Machine learning on Hadoop • Born out of the Apache Lucene project • Built on Hadoop (all in Java) • Pragmatic machine learning at scale 1: Recommendation 2: Classification 3: Clustering Other MapReduce algorithms • Dimensionality reduction – Lanczos – SSVD – LDA • Regression – Logistic – Linear – Random Forest • Evolutionary algorithms Mahout-Samsara • Programming “environment” for distributed machine learning • R-like syntax • Interactive shell (like Spark) • Under-the-hood algebraic optimizer • Engine-agnostic – Spark – H2O – Flink – ? Mahout-Samsara Mahout • 3 main components Engine-agnostic environment for Engine-specific Legacy MapReduce building scalable ML algorithms (Spark, algorithms algorithms H2O) (Samsara) Mahout • v0.10.0 released April 11 (as in, 5 days ago!) • 0.10.1 – More base linear algebra functionality • 0.11.0 – Compatible with Spark 1.3 • 1.0 – ? Mahout features by engine Mahout features by engine Mahout features by engine • No engine-agnostic clustering algorithms yet – Still the domain of legacy MapReduce • H2O and especially Flink -

Front Matter Template
Copyright by Matthew Stephen Sigman 2012 The Report Committee for Matthew Stephen Sigman Certifies that this is the approved version of the following report: Using Machine Learning Techniques to Simplify Mobile Interfaces APPROVED BY SUPERVISING COMMITTEE: Supervisor: Christine Julien Joydeep Ghosh Using Machine Learning Techniques to Simplify Mobile Interfaces by Matthew Stephen Sigman, B.S. Report Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Master of Science in Engineering The University of Texas at Austin December 2012 Acknowledgements I would like to thank my parents for their unwavering support, guidance, and constantly pushing me to succeed. I would also like to thank my advisor on this report, Christine Julien, and my reader Joydeep Ghosh. iv I am in favor of animal rights as well as human rights. That is the way of a whole human being. Abraham Lincoln v Abstract Using Machine Learning Techniques to Simplify Mobile Interfaces Matthew Stephen Sigman, M.S.E. The University of Texas at Austin, 2012 Supervisor: Christine Julien This paper explores how known machine learning techniques can be applied in unique ways to simplify software and therefore dramatically increase its usability. As software has increased in popularity, its complexity has increased in lockstep, to a point where it has become burdensome. By shifting the focus from the software to the user, great advances can be achieved by way of simplification. The example problem used in this report is well known: suggest local dining choices tailored to a specific person based on known habits and those of similar people.