Paper, We Empirically Investigate and Measure This Problem – Thus Preventing Any Static Analysis of the Code Itself
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Internet Security Threat Report Volume 24 | February 2019
ISTRInternet Security Threat Report Volume 24 | February 2019 THE DOCUMENT IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENT. THE INFORMATION CONTAINED IN THIS DOCUMENT IS SUBJECT TO CHANGE WITHOUT NOTICE. INFORMATION OBTAINED FROM THIRD PARTY SOURCES IS BELIEVED TO BE RELIABLE, BUT IS IN NO WAY GUARANTEED. SECURITY PRODUCTS, TECHNICAL SERVICES, AND ANY OTHER TECHNICAL DATA REFERENCED IN THIS DOCUMENT (“CONTROLLED ITEMS”) ARE SUBJECT TO U.S. EXPORT CONTROL AND SANCTIONS LAWS, REGULATIONS AND REQUIREMENTS, AND MAY BE SUBJECT TO EXPORT OR IMPORT REGULATIONS IN OTHER COUNTRIES. YOU AGREE TO COMPLY STRICTLY WITH THESE LAWS, REGULATIONS AND REQUIREMENTS, AND ACKNOWLEDGE THAT YOU HAVE THE RESPONSIBILITY TO OBTAIN ANY LICENSES, PERMITS OR OTHER APPROVALS THAT MAY BE REQUIRED IN ORDER FOR YOU TO EXPORT, RE-EXPORT, TRANSFER IN COUNTRY OR IMPORT SUCH CONTROLLED ITEMS. TABLE OF CONTENTS 1 2 3 BIG NUMBERS YEAR-IN-REVIEW FACTS AND FIGURES METHODOLOGY Formjacking Messaging Cryptojacking Malware Ransomware Mobile Living off the land Web attacks and supply chain attacks Targeted attacks Targeted attacks IoT Cloud Underground economy IoT Election interference MALICIOUS -

1.Computer Virus Reported (1) Summary for This Quarter
Attachment 1 1.Computer Virus Reported (1) Summary for this Quarter The number of the cases reported for viruses*1 in the first quarter of 2013 decreased from that of the fourth quarter of 2012 (See Figure 1-1). As for the number of the viruses detected*2 in the first quarter of 2013, W32/Mydoom accounted for three-fourths of the total (See Figure 1-2). Compared to the fourth quarter of 2012, however, both W32/Mydoom and W32/Netsky showed a decreasing trend. When we looked into the cases reported for W32/Netsky, we found that in most of those cases, the virus code had been corrupted, for which the virus was unable to carry out its infection activity. So, it is unlikely that the number of cases involving this virus will increase significantly in the future As for W32/IRCbot, it has greatly decreased from the level of the fourth quarter of 2012. W32/IRCbot carries out infection activities by exploiting vulnerabilities within Windows or programs, and is often used as a foothold for carrying out "Targeted Attack". It is likely that that there has been a shift to attacks not using this virus. XM/Mailcab is a mass-mailing type virus that exploits mailer's address book and distributes copies of itself. By carelessly opening this type of email attachment, the user's computer is infected and if the number of such users increases, so will the number of the cases reported. As for the number of the malicious programs detected in the first quarter of 2013, Bancos, which steals IDs/Passwords for Internet banking, Backdoor, which sets up a back door on the target PC, and Webkit, which guides Internet users to a maliciously-crafted Website to infect with another virus, were detected in large numbers. -
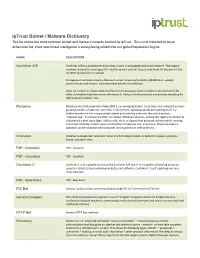
Iptrust Botnet / Malware Dictionary This List Shows the Most Common Botnet and Malware Variants Tracked by Iptrust
ipTrust Botnet / Malware Dictionary This list shows the most common botnet and malware variants tracked by ipTrust. This is not intended to be an exhaustive list, since new threat intelligence is always being added into our global Reputation Engine. NAME DESCRIPTION Conficker A/B Conficker A/B is a downloader worm that is used to propagate additional malware. The original malware it was after was rogue AV - but the army's current focus is undefined. At this point it has no other purpose but to spread. Propagation methods include a Microsoft server service vulnerability (MS08-067) - weakly protected network shares - and removable devices like USB keys. Once on a machine, it will attach itself to current processes such as explorer.exe and search for other vulnerable machines across the network. Using a list of passwords and actively searching for legitimate usernames - the ... Mariposa Mariposa was first observed in May 2009 as an emerging botnet. Since then it has infected an ever- growing number of systems; currently, in the millions. Mariposa works by installing itself in a hidden location on the compromised system and injecting code into the critical process ͞ĞdžƉůŽƌĞƌ͘ĞdžĞ͘͟/ƚŝƐknown to affect all modern Windows versions, editing the registry to allow it to automatically start upon login. Additionally, there is a guard that prevents deletion while running, and it automatically restarts upon crash/restart of explorer.exe. In essence, Mariposa opens a backdoor on the compromised computer, which grants full shell access to ... Unknown A botnet is designated 'unknown' when it is first being tracked, or before it is given a publicly- known common name. -

Symantec Intelligence Report: June 2011
Symantec Intelligence Symantec Intelligence Report: June 2011 Three-quarters of spam send from botnets in June, and three months on, Rustock botnet remains dormant as Cutwail becomes most active; Pharmaceutical spam in decline as new Wiki- pharmacy brand emerges Welcome to the June edition of the Symantec Intelligence report, which for the first time combines the best research and analysis from the Symantec.cloud MessageLabs Intelligence Report and the Symantec State of Spam & Phishing Report. The new integrated report, the Symantec Intelligence Report, provides the latest analysis of cyber security threats, trends and insights from the Symantec Intelligence team concerning malware, spam, and other potentially harmful business risks. The data used to compile the analysis for this combined report includes data from May and June 2011. Report highlights Spam – 72.9% in June (a decrease of 2.9 percentage points since May 2011): page 11 Phishing – One in 330.6 emails identified as phishing (a decrease of 0.05 percentage points since May 2011): page 14 Malware – One in 300.7 emails in June contained malware (a decrease of 0.12 percentage points since May 2011): page 15 Malicious Web sites – 5,415 Web sites blocked per day (an increase of 70.8% since May 2011): page 17 35.1% of all malicious domains blocked were new in June (a decrease of 1.7 percentage points since May 2011): page 17 20.3% of all Web-based malware blocked was new in June (a decrease of 4.3 percentage points since May 2011): page 17 Review of Spam-sending botnets in June 2011: page 3 Clicking to Watch Videos Leads to Pharmacy Spam: page 6 Wiki for Everything, Even for Spam: page 7 Phishers Return for Tax Returns: page 8 Fake Donations Continue to Haunt Japan: page 9 Spam Subject Line Analysis: page 12 Best Practices for Enterprises and Users: page 19 Introduction from the editor Since the shutdown of the Rustock botnet in March1, spam volumes have never quite recovered as the volume of spam in global circulation each day continues to fluctuate, as shown in figure 1, below. -

Contents in This Issue
FEBRUARY 2014 Covering the global threat landscape CONTENTS IN THIS ISSUE 2 COMMENT A LIFE OF GRIME It is time for defenders to go on the offence Cross-platform execution is one of the promises of Java – but cross-platform infection is probably 3 NEWS not what the designers had in mind. Nevertheless, that was clearly in the mind of the author of Law minister is former spammer W32/Java.Grimy, a virus for the Windows platform, Cash for hacks which infects Java class fi les. Peter Ferrie has the details. MALWARE ANALYSES page 4 4 Getting one’s hands dirty LAME DUCK 6 Salted algorithm – part 2 Sometimes what looks like a genuine MP3 encoder 11 Inside W32.Xpaj.B’s infection – part 2 library, and even works as a functional encoder, actually hides malicious code deep amongst a 19 FEATURE pile of clean code. Gabor Szappanos reveals the Needle in a haystack lengths to which one piece of malware goes to hide its tracks. page 19 27 BOOK REVIEW Don’t forget to write READING CORNER Industry veteran, prolifi c writer and educator David 30 SPOTLIGHT Harley reviews two recently published eBooks that aim to provide security guidance for consumers: Greetz from academe: Full frontal ‘Improve Your Security’ by Sorin Mustaca, and ‘One Parent to Another’ by Tony Anscombe. 31 END NOTES & NEWS page 27 ISSN 1749-7027 COMMENT ‘Challenge for example, an IPS or anti-virus product will still do some level of good if you do no more than install it on [defenders] to your network and make sure it gets updated occasionally, take a penetration a SIEM will not do anything except generate a (huge) bill. -

Download Slides
Scott Wu Point in time cleaning vs. RTP MSRT vs. Microsoft Security Essentials Threat events & impacts More on MSRT / Security Essentials MSRT Microsoft Windows Malicious Software Removal Tool Deployed to Windows Update, etc. monthly since 2005 On-demand scan on prevalent malware Microsoft Security Essentials Full AV RTP Inception in Oct 2009 RTP is the solution One-off cleaner has its role Quiikck response Workaround Baseline ecosystem cleaning Industrypy response & collaboration Threat Events Worms (some are bots) have longer lifespans Rogues move on quicker MarMar 2010 2010 Apr Apr 2010 2010 May May 2010 2010 Jun Jun 2010 2010 Jul Jul 2010 2010 Aug Aug 2010 2010 1,237,15 FrethogFrethog 979,427 979,427 Frethog Frethog 880,246880,246 Frethog Frethog465,351 TaterfTaterf 5 1,237,155Taterf Taterf 797,935797,935 TaterfTaterf 451,561451,561 TaterfTaterf 497,582 497,582 Taterf Taterf 393,729393,729 Taterf Taterf447,849 FrethogFrethog 535,627535,627 AlureonAlureon 493,150 493,150 AlureonAlureon 436,566 436,566 RimecudRimecud 371,646 371,646 Alureon Alureon 308,673308,673 Alureon Alureon 441,722 RimecudRimecud 341,778341,778 FrethogFrethog 473,996473,996 BubnixBubnix 348,120 348,120 HamweqHamweq 289,603 289,603 Rimecud Rimecud289,629 289,629 Rimecud Rimecud318,041 AlureonAlureon 292,810 292,810 BubnixBubnix 471,243 471,243 RimecudRimecud 287,942287,942 ConfickerConficker 286,091286, 091 Hamwe Hamweqq 250,286250, 286 Conficker Conficker220,475220, 475 ConfickerConficker 237237,348, 348 RimecudRimecud 280280,440, 440 VobfusVobfus 251251,335, 335 -

Dgarchive a Deep Dive Into Domain Generating Malware
DGArchive A deep dive into domain generating malware Daniel Plohmann [email protected] 2015-12-03 | Botconf, Paris © 2015 Fraunhofer FKIE 1 About me Daniel Plohmann PhD candidate at University of Bonn, Germany Security Researcher at Fraunhofer FKIE Focus: Reverse Engineering / Malware Analysis / Automation Projects ENISA Botnet Study 2011 [1] Analysis Tools PyBox, IDAscope, DGArchive, … Botnet Analysis Gameover Zeus / P2P protocols [2] DGA-based Malware [1] http://www.enisa.europa.eu/act/res/botnets/botnets-measurement-detection-disinfection-and-defence [2] http://christian-rossow.de/publications/p2pwned-ieee2013.pdf © 2015 Fraunhofer FKIE 2 Agenda Intro: Domain Generation Algorithms / DGArchive Comparison of DGA Features Registration Status of DGA Domain Space Case Studies © 2015 Fraunhofer FKIE 3 Intro Domain Generation Algorithms © 2015 Fraunhofer FKIE 4 Domain Generation Algorithms Definitions Concept first described ~2008: Domain Flux Domain Generation Algorithm (DGA) An algorithm producing Command & Control rendezvous points dynamically Shared secret between malware running on compromised host and botmaster Seeds Collection of parameters influencing the output of the algorithm Algorithmically-Generated Domain (AGD) Domains resulting from a DGA © 2015 Fraunhofer FKIE 5 Domain Generation Algorithms Origin & History Feb 2006 Sality: dynamically generates 3rd-level domain part July 2007 Torpig: Report by Verisign includes DGA-like domains July 2007 Kraken: VirusTotal upload of binary using DDNS -

Peerpress: Utilizing Enemies' P2P Strength Against Them
PeerPress: Utilizing Enemies’ P2P Strength against Them Zhaoyan Xu Lingfeng Chen SUCCESS Lab SUCCESS Lab Texas A&M University Texas A&M University [email protected] [email protected] Guofei Gu Christopher Kruegel SUCCESS Lab Dept. of Computer Science Texas A&M University UC Santa Barbara [email protected] [email protected] ABSTRACT Malicious software (malware) is a serious threat to Inter- We propose a new, active scheme for fast and reliable de- net security. While many early botnets use centralized C&C tection of P2P malware by exploiting the enemies' strength architecture, botmasters have realized its limitations and be- against them. Our new scheme works in two phases: host- gun to use more advanced and robust peer-to-peer (P2P) level dynamic binary analysis to automatically extract built- architectures for C&C [27]. For example, several contempo- in remotely-accessible/controllable mechanisms (referred to rary successful botnets such as Storm/Peacomm and Con- as Malware Control Birthmarks or MCB) in P2P malware, ficker have infected millions of computers and adopted P2P followed by network-level informed probing for detection. techniques in their C&C coordination [2,48]. As stated in a Our new design demonstrates a novel combination of the recent report [26], the Kaspersky Security Network detected strengths from both host-based and network-based approaches. more than 2.5 million P2P malware incidents per month in Compared with existing detection solutions, it is fast, reli- March 2010, a high water mark reached for the first time able, and scalable in its detection scope. -

Mcafee Labs Threats Report August 2015 Ransomware Continues to Grow Very Rapidly— with the Number of New Samples Rising 58% in Q2
Report McAfee Labs Threats Report August 2015 Ransomware continues to grow very rapidly— with the number of new samples rising 58% in Q2. About McAfee Labs Introduction McAfee Labs is one of the world’s leading sources for threat This month marks the five-year anniversary of Intel’s research, threat intelligence, and cybersecurity thought announcement that the company would acquire McAfee. leadership. With data from millions of sensors across key Much has changed in the security space since then, so we threats vectors—file, web, message, and network—McAfee decided to look back on these years and compare what we Labs delivers real-time threat intelligence, critical analysis, thought would happen with what actually happened. and expert thinking to improve protection and reduce risks. We interviewed a dozen key people who have been with McAfee is now part of Intel Security. Intel or McAfee since the acquisition to get their views on the major developments of the past five years around the www.mcafee.com/us/mcafee-labs.aspx cyber threat landscape, including how the types of threat actors have changed, how attackers’ behaviors and targets Follow McAfee Labs have changed, how the economics of cybercrime have changed, and how the industry has responded. We also wanted to know what they didn’t anticipate or what truly surprised them. We hope you enjoy the retrospective. This quarter, we also discuss two very interesting Key Topics. In McAfee Labs Threats Reports, we spend a lot of time examining ways in which attackers enter a trusted network or system, but we spend little time looking at how they exfiltrate the information they want to steal once they have successfully breached the network or system. -

I Trust My Zombies: a Trust-Enabled Botnet
I Trust my Zombies: A Trust-enabled Botnet Emmanouil Vasilomanolakis∗, Jan Helge Wolf∗, Leon Bock¨ ∗, Shankar Karuppayahy, Max Muhlh¨ auser¨ ∗ ∗ Telecooperation Lab, Technische Universitat¨ Darmstadt Darmstadt, Germany fvasilomano, boeck, [email protected], [email protected] y National Advanced IPv6 Centre, Universiti Sains Malaysia, Penang, Malaysia [email protected] Abstract—Defending against botnets has always been a cat channel based on unstructured Peer-to-peer (P2P) overlays. and mouse game. Cyber-security researchers and government These botnets do not inherit the SPoF of centralized ap- agencies attempt to detect and take down botnets by playing the proaches. Furthermore, they are very resilient to node churn role of the cat. In this context, a lot of work has been done towards reverse engineering certain variants of malware families and node removal attacks [13]. as well as understanding the network protocols of botnets to As the lack of a central server prevents easy monitor- identify their weaknesses (if any) and exploit them. While this ing, researchers have developed various means for gather- is necessary, such an approach offers the botmasters the ability ing intelligence in P2P botnets. This is usually achieved to quickly counteract the defenders by simply performing small by first reverse engineering the communication protocol and changes in their arsenals. We attempt a different approach by actually taking the role of afterwards deploying crawlers and sensors to enumerate the the Botmaster, to eventually anticipate his behavior. That said, in botnet population. Nevertheless, botnets such as Sality [5] or this paper, we present a novel computational trust mechanism for GameOver Zeus [2] already implement features to impede fully distributed botnets that allows for a resilient and stealthy monitoring attempts. -

Paint It Black: Evaluating the Effectiveness Of
Paint it Black: Evaluating the Effectiveness of Malware Blacklists Marc K¨uhrer,Christian Rossow, and Thorsten Holz Horst G¨ortzInstitute for IT-Security, Ruhr-University Bochum, Germany [email protected] Abstract. Blacklists are commonly used to protect computer systems against the tremendous number of malware threats. These lists include abusive hosts such as malware sites or botnet Command & Control and dropzone servers to raise alerts if suspicious hosts are contacted. Up to now, though, little is known about the effectiveness of malware blacklists. In this paper, we empirically analyze 15 public malware blacklists and 4 blacklists operated by antivirus (AV) vendors. We aim to categorize the blacklist content to understand the nature of the listed domains and IP addresses. First, we propose a mechanism to identify parked domains in blacklists, which we find to constitute a substantial number of blacklist entries. Second, we develop a graph-based approach to identify sinkholes in the blacklists, i.e., servers that host malicious domains which are con- trolled by security organizations. In a thorough evaluation of blacklist effectiveness, we show to what extent real-world malware domains are actually covered by blacklists. We find that the union of all 15 public blacklists includes less than 20% of the malicious domains for a major- ity of prevalent malware families and most AV vendor blacklists fail to protect against malware that utilizes Domain Generation Algorithms. Keywords: Blacklist Evaluation, Sinkholing Servers, Parking Domains 1 Introduction The security community needs to deal with an increasing number of malware samples that infect computer systems world-wide. -

Hong Kong Security Watch Report Q4 2013
Hong Kong Security Watch Report Q4 2013 Foreword Better Security Decision with Situational Awareness Nowadays, a lot of “invisible” compromised computers are controlled by attackers with the owner being unaware. The data on these computers may be mined and exposed everyday and the computers may be utilized in different kinds of abuse and criminal activities. The Hong Kong Security Watch Report aims to provide the public a better “visibility” of the situation of the compromised computers in Hong Kong so that they can make better decision in protecting their information security. The report provides data about the activities of compromised computers in Hong Kong which suffer from, or participate in various forms of cyber attacks, including web defacement, phishing, malware hosting, botnet command and control centres (C&C) and bots. Computers in Hong Kong is defined as those whose network geolocation is Hong Kong, or the top level domain of their host name is “.hk” or “.香港”. Capitalizing on the Power of Global Intelligence This report is the fruit of the collaboration of HKCERT and global security researchers. Many security researchers have the capability to detect attacks targeting their own or their customers’ networks. Some of them provide the information of IP addresses of attack source or web links of malicious activities to other information security organizations with an aim to collaboratively improve the overall security of the cyberspace. They have good practice in sanitizing personal identifiable data before sharing information. HKCERT collects and aggregates such valuable data about Hong Kong from multiple information sources for analysis with Information Feed Analysis System (IFAS), a system developed by HKCERT.