Content Based Filtering for Application Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Electronic Evidence Examiner
2 Table of Contents About Electronic Evidence Examiner How To .......................................................................12 How to Work with Cases .........................................................................................................13 How to Create New Case .......................................................................................................13 How to Enable Automatic Case Naming .................................................................................14 How to Define Case Name During Automatic Case Creation .................................................14 How to Open Existing Case....................................................................................................15 How to Save Case to Archive .................................................................................................16 How to Change Default Case Location ...................................................................................16 How to Add Data to Case ........................................................................................................17 How to Add Evidence .............................................................................................................18 How to Acquire Devices .........................................................................................................20 How to Import Mobile Data .....................................................................................................21 How to Import Cloud Data ......................................................................................................22 -

Lf241, Applications: Gnumail.App, Der Beweis Für
LinuxFocus article number 241 http://linuxfocus.org GNUMail.app, der Beweis für Portabilität by Georges Tarbouriech <georges.t/at/linuxfocus.org> Abstract: About the author: GNUMail.app ist eine Nachbildung der NeXT Mail.app−Anwendung, welche unter GNUstep und MacOS X läuft. Sein Design erlaubt es, den Georges ist ein langjähriger gleichen Quellcode auf sehr unterschiedlichen Plattformen zu benutzen. Unixbenutzer. Als ein Entsprechend ist dieses großartige Stück Software der absolute Beweis für NeXTSTEP Liebhaber ist er Software−Portabilität zwischen GNUstep und MacOS X. von diesen drei freien Projekten, die es sich zum Ziel gesetzt haben, das Look and Feel (und vieles mehr) _________________ _________________ _________________ dieses großartigen Systems anzubieten, sehr begeistert. Es war einmal... Gegen Ende der 80er Jahre erschien ein neues Betriebssystem, genannt NeXTSTEP. Dieses Betriebssystem bot etwas, was wir noch nie zuvor gesehen hatten. Unter vielen anderen "Sachen" stellte es den Benutzern den allerersten grafischen Mail−Client zur Verfügung, Mail.app. Es bot nicht nur eine grafische Oberfläche, sondern war auch in der Lage, jeden Datentyp zu verwalten: Bilder, Klänge, usw. Einige Jahre später entschied NeXT, NeXTSTEP auf andere Plattformen zu portieren: OpenStep wurde geboren. Von da an begannen einige Leute an freien Software−Projekten zu arbeiten, die die gleiche Philosophie boten. Das größte Projekt ist natürlich GNUstep, da es dessen Ziel ist, uns eine freie Implementation von OpenStep zu liefern. Die Leute bei GNUstep machen einen sehr guten Job, wenn man die Menge an Arbeit berücksichtigt, die ein solches Projekt erfordert. Ein anderes großartiges Werk ist Window Maker. Dieser Fenster−Manager ist Teil des GNUstep−Projektes. Wenn Sie beide Webseiten aufsuchen, werden Sie alles über diese großen freien Projekte erfahren. -

How to Write a Successful Curriculum Vitae Rose Filazzola
How to Write a Successful Curriculum Vitae Rose Filazzola 1 Index . Why write a C.V.? . What is a C.V.? . When should a CV be used? . Before you start . What information should a CV include? . What makes a good CV? . How long should a CV be? . Tips on presentation . Fonts . Different Types of CV . Targeting your CV . Emailed CVs and Web CVs . Summary . Websites to consult for Further Help . CV Sample 2 How to Write a Successful Curriculum Vitae Why write a CV? Nowadays, employers tend to receive thousands of applications for a job as soon as it is advertised on the job market. Therefore, it is vital that your letter should stand out from the thousands of CVs and letters that people are going to send. The first impression is always the most important one, therefore, you need a good, well- structured CV in order to attract the employers' attention. Your CV must sell you to a prospective employer and keep in mind that you are competing against other applicants who are also trying to sell themselves. So the challenge in CV writing is to be more appealing and attractive than the rest. This means that your curriculum vitae must be presented professionally, clearly and in a way that indicates you are an ideal candidate for the job, i.e., you possess the right skills, experience, behaviour, attitude, morality that the employer is seeking. The way you present your CV effectively demonstrates your ability to communicate and particularly to explain a professional business proposition. Different countries may have different requirements and styles for CV or resumes. -

Introducción a Linux Equivalencias Windows En Linux Ivalencias
No has iniciado sesión Discusión Contribuciones Crear una cuenta Acceder Página discusión Leer Editar Ver historial Buscar Introducción a Linux Equivalencias Windows en Linux Portada < Introducción a Linux Categorías de libros Equivalencias Windows en GNU/Linux es una lista de equivalencias, reemplazos y software Cam bios recientes Libro aleatorio análogo a Windows en GNU/Linux y viceversa. Ayuda Contenido [ocultar] Donaciones 1 Algunas diferencias entre los programas para Windows y GNU/Linux Comunidad 2 Redes y Conectividad Café 3 Trabajando con archivos Portal de la comunidad 4 Software de escritorio Subproyectos 5 Multimedia Recetario 5.1 Audio y reproductores de CD Wikichicos 5.2 Gráficos 5.3 Video y otros Imprimir/exportar 6 Ofimática/negocios Crear un libro 7 Juegos Descargar como PDF Versión para im primir 8 Programación y Desarrollo 9 Software para Servidores Herramientas 10 Científicos y Prog s Especiales 11 Otros Cambios relacionados 12 Enlaces externos Subir archivo 12.1 Notas Páginas especiales Enlace permanente Información de la Algunas diferencias entre los programas para Windows y y página Enlace corto GNU/Linux [ editar ] Citar esta página La mayoría de los programas de Windows son hechos con el principio de "Todo en uno" (cada Idiomas desarrollador agrega todo a su producto). De la misma forma, a este principio le llaman el Añadir enlaces "Estilo-Windows". Redes y Conectividad [ editar ] Descripción del programa, Windows GNU/Linux tareas ejecutadas Firefox (Iceweasel) Opera [NL] Internet Explorer Konqueror Netscape / -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

On the Security of Practical Mail User Agents Against Cache Side-Channel Attacks †
applied sciences Article On the Security of Practical Mail User Agents against Cache Side-Channel Attacks † Hodong Kim 1 , Hyundo Yoon 1, Youngjoo Shin 2 and Junbeom Hur 1,* 1 Department of Computer Science and Engineering, Korea University, Seoul 02841, Korea; [email protected] (H.K.); [email protected] (H.Y.) 2 School of Computer and Information Engineering, Kwangwoon University, Seoul 01897, Korea; [email protected] * Correspondence: [email protected] † This paper is an extended version of our paper published in the 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020. Received: 30 April 2020; Accepted: 26 May 2020; Published: 29 May 2020 Abstract: Mail user agent (MUA) programs provide an integrated interface for email services. Many MUAs support email encryption functionality to ensure the confidentiality of emails. In practice, they encrypt the content of an email using email encryption standards such as OpenPGP or S/MIME, mostly implemented using GnuPG. Despite their widespread deployment, there has been insufficient research on their software structure and the security dependencies among the software components of MUA programs. In order to understand the security implications of the structures and analyze any possible vulnerabilities of MUA programs, we investigated a number of MUAs that support email encryption. As a result, we found severe vulnerabilities in a number of MUAs that allow cache side-channel attacks in virtualized desktop environments. Our analysis reveals that the root cause originates from the lack of verification and control over the third-party cryptographic libraries that they adopt. In order to demonstrate this, we implemented a cache side-channel attack on RSA in GnuPG and then conducted an evaluation of the vulnerability of 13 MUAs that support email encryption in Ubuntu 14.04, 16.04 and 18.04. -

Implementation of a Distributed Mobile Based Environment to Help Children Learning a Foreign Language
Engineering of pervasive computing systems MSc MASTER THESIS HOU-CS-PGP-2016-15 Implementation of a distributed mobile based environment to help children learning a foreign language IOANNIS SALATAS SUPERVISOR: CHRISTOS GOUMOPULOS ΠΑΤΡΑ 2016 Master Thesis HOU-CS- PGP-2016-15 Implementation of a distributed mobile based environment to help children learning a foreign language Ioannis Salatas i Διπλωματική Εργασία HOU-CS- PGP-2016-15 Υλοποίηση κατανεμημένης εφαρμογής τηλεδιασκέψεων για την υποβοήθηση διδασκαλίας ξένων γλωσσών Ιωάννης Σαλάτας ii © Hellenic Open University, 2016 This dissertation, prepared under the MSc Engineering of pervasive computing systems MSc, and other results of the corresponding Master Thesis (MT) are co-owned by the Hellenic Open University and the student, each of whom has the right to their independent use and reproduction (in whole or in part) for teaching and research purposes, in each case indicating the title and author and the Hellenic Open University where MT has been prepared and the supervisor and the jury. iii Implementation of a distributed mobile based environment to help children learning a foreign language Ioannis Salatas Christos Goumopoulos Ioannis Zaharakis Achilles Kameas Assistant Professor, Associate Professor, Associate Professor, University of the Technological Educational Hellenic Open University Aegean Institute of Western Greece iv Abstract This Master Thesis presents the requirement analysis, design and implementation of an e- learning environment for helping children learning a foreign -
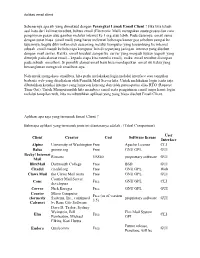
Sebenarnya Apa Sih Yang Dimaksud Dengan Perangkat Lunak Email Client
Aplikasi email client Sebenarnya apa sih yang dimaksud dengan Perangkat Lunak Email Client ? Jika kita telaah asal kata dari kalimat tersebut, bahwa email (Electronic Mail) merupakan suatu proses dan cara pengiriman pesan atau gambar melalui internet ke 1 org atau lebih. Pada dasarnya email sama dengan surat biasa (snail mail) yang harus melewati beberapa kantor pos sebelum sampai ke tujuannya, begitu dikirimkan oleh seseorang melalui komputer yang tersambung ke internet sebuah email masuk ke beberapa komputer lain di sepanjang jaringan internet yang disebut dengan mail server. Ketika email tersebut sampai ke server yang menjadi tujuan (seperti yang ditunjuk pada alamat email – kepada siapa kita menulis email), maka email tersebut disimpan pada sebuah emailbox. Si pemilik alamat email baru bisa mendapatkan email itu kalau yang bersangkutan mengecek emailbox-nya. Nah untuk mengakses emailbox, kita perlu melakukan login melalui interface atau tampilan berbasis web yang disediakan oleh Pemilik Mail Server kita. Untuk melakukan login tentu saja dibutuhkan koneksi internet yang lumayan kencang dan tidak putus-putus alias RTO (Request Time Out). Untuk Mempermudah kita membaca email serta pengiriman email tanpa harus login melalui tampilan web, kita membutuhkan aplikasi yang yang biasa disebut Email Client. Aplikasi apa saja yang termasuk Email Client ? Beberapa aplikasi yang termasuk jenis ini diantaranya adalah : (Tabel Comparison) User Client Creator Cost Software license Interface Alpine University of Washington Free Apache License CLI Balsa gnome.org Free GNU GPL GUI Becky! Internet Rimarts US$40 proprietary software GUI Mail BlitzMail Dartmouth College Free BSD GUI Citadel citadel.org Free GNU GPL Web Claws Mail the Claws Mail team Free GNU GPL GUI Courier Mail Server Cone Free GNU GPL CLI developers Correo Nick Kreeger Free GNU GPL GUI Courier Micro Computer Free (as of version (formerly Systems, Inc., continued proprietary software GUI 3.5) Calypso) by Rose City Software Dave D. -

Toolkit for Teachers – Technologies Is Supplementary Material for the Toolkit for Teachers
Toolkit for Technologies teachers i www. universitiesofthefuture.eu Partners Maria Teresa Pereira (Project manager) [email protected] Maria Clavert Piotr Palka Rui Moura Frank Russi [email protected] [email protected] [email protected] [email protected] Ricardo Migueis Sanja Murso Wojciech Gackowski Maciej Markowski [email protected] [email protected] [email protected] [email protected] Olivier Schulbaum Francisco Pacheo Pedro Costa Aki Malinen [email protected] [email protected] [email protected] [email protected] ii INDEX 1 INTRODUCTION AND FOREWORD 1 2 CURRENT SITUATION 3 2.1 INDUSTRY 4.0: STATE OF AFFAIRS 3 2.2 TRENDS 3 2.3 NEEDS 4 2.3.1 Addressing modern challenges in information acquisition 4 2.3.2 Supporting collaborative work 4 2.3.3 IT-assisted teaching 4 3 TECHNOLOGIES FOR EDUCATION 4.0 7 3.1 TOOLS SUPPORTING GROUP AND PROJECT WORK 7 3.1.1 Cloud storage services 7 3.1.2 Document Collaboration Tools 9 3.1.3 Documenting projects - Wiki services 11 3.1.4 Collaborative information collection, sharing and organization 13 3.1.5 Project management tools 17 3.1.6 Collaborative Design Tools 21 3.2 E-LEARNING AND BLENDED LEARNING TOOLS 24 3.2.1 Direct communication tools 24 3.2.1.1 Webcasts 24 3.2.1.2 Streaming servers 26 3.2.1.3 Teleconferencing tools 27 3.2.1.4 Webinars 28 3.2.2 Creating e-learning materials 29 3.2.2.1 Creation of educational videos 29 3.2.2.2 Authoring of interactive educational content 32 3.2.3 Learning Management Systems (LMS) 33 4 SUMMARY 36 5 REFERENCES 38 4.1 BIBLIOGRAPHY 38 4.2 NETOGRAPHY 39 iii Introduction and foreword iv 1 Introduction and foreword This toolkit for teachers – technologies is supplementary material for the toolkit for teachers. -

Mconf: an Open Source Multiconference System for Web and Mobile Devices
10 Mconf: An Open Source Multiconference System for Web and Mobile Devices Valter Roesler1, Felipe Cecagno1, Leonardo Crauss Daronco1 and Fred Dixon2 1Federal University of Rio Grande do Sul, 2BigBlueButton Inc., 1Brazil 2Canada 1. Introduction Deployment of videoconference systems have been growing rapidly for the last years, and deployments nowadays are fairly common, avoiding thousands of trips daily. Video conferencing systems can be organized into four groups: Room, Telepresence, Desktop and Web. 1.1 Groups of videoconference systems Room videoconference systems are normally hardware based and located in meeting rooms or classrooms, as seen in Fig. 1, which shows examples of a Polycom1 equipment. Participants are expected to manually activate and call a remote number in order to begin interacting. Other solutions of room videoconference systems are Tandberg2 (which is now part of Cisco), Lifesize3 and Radvision (Scopia line)4. Telepresence videoconference systems are a variation of room systems in that the room environment and the equipments are set in order to produce the sensation that all participants are in the same room, as shown in Fig. 2, which shows the Cisco Telepresence System5. To accomplish the “presence sensation”, the main approaches are: a) adjust the camera to show the remote participant in real size; b) use speakers and microphones in a way that the remote sound comes from the participant position; c) use high definition video in order to show details of the participants; d) use a complementary environment, as the same types of chairs, same color in the rooms, and same type of table on the other sides. -

List Software Pengganti Windows Ke Linux
Tabel Padanan Aplikasi Windows di Linux Untuk Migrasi Selasa, 18-08-2009 Kesulitan besar dalam melakukan migrasi dari Windows ke Linux adalah mencari software pengganti yang berkesesuaian. Berikut ini adalah tabel padanan aplikasi Windows di Linux yang disusun dalam beberapa kategori. Nama Program Windows Linux 1) Networking. 1) Netscape / Mozilla. 2) Galeon. 3) Konqueror. 4) Opera. [Prop] Internet Explorer, 5) Firefox. Web browser Netscape / Mozilla, Opera 6) Nautilus. [Prop], Firefox, ... 7) Epiphany. 8) Links. (with "-g" key). 9) Dillo. 10) Encompass. 1) Links. 1) Links 2) ELinks. Console web browser 2) Lynx 3) Lynx. 3) Xemacs + w3. 4) w3m. 5) Xemacs + w3. 1) Evolution. 2) Netscape / Mozilla/Thunderbird messenger. 3) Sylpheed / Claws Mail. 4) Kmail. Outlook Express, 5) Gnus. Netscape / Mozilla, 6) Balsa. Thunderbird, The Bat, 7) Bynari Insight GroupWare Suite. Email client Eudora, Becky, Datula, [Prop] Sylpheed / Claws Mail, 8) Arrow. Opera 9) Gnumail. 10) Althea. 11) Liamail. 12) Aethera. 13) MailWarrior. 14) Opera. 1) Evolution. Email client / PIM in MS 2) Bynari Insight GroupWare Suite. Outlook Outlook style [Prop] 3) Aethera. 4) Sylpheed. 5) Claws Mail 1) Sylpheed. 2) Claws Mail Email client in The Bat The Bat 3) Kmail. style 4) Gnus. 5) Balsa. 1) Pine. [NF] 2) Mutt. Mutt [de], Pine, Pegasus, Console email client 3) Gnus. Emacs 4) Elm. 5) Emacs. 1) Knode. 2) Pan. 1) Agent [Prop] 3) NewsReader. 2) Free Agent 4) Netscape / Mozilla Thunderbird. 3) Xnews 5) Opera [Prop] 4) Outlook 6) Sylpheed / Claws Mail. 5) Netscape / Mozilla Console: News reader 6) Opera [Prop] 7) Pine. [NF] 7) Sylpheed / Claws Mail 8) Mutt. -

Wind River® Intelligent Device Platform XT
Wind River® Intelligent Device Platform XT RELEASE NOTES 2.0 EDITION 8 Copyright Notice Copyright © 2015 Wind River Systems, Inc. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means without the prior written permission of Wind River Systems, Inc. Wind River, Tornado, and VxWorks are registered trademarks of Wind River Systems, Inc. The Wind River logo is a trademark of Wind River Systems, Inc. Any third-party trademarks referenced are the property of their respective owners. For further information regarding Wind River trademarks, please see: www.windriver.com/company/terms/trademark.html This product may include software licensed to Wind River by third parties. Relevant notices (if any) are provided in your product installation at one of the following locations: installDir/product_name/3rd_party_licensor_notice.pdf installDir/legal-notices/ Wind River may refer to third-party documentation by listing publications or providing links to third-party Web sites for informational purposes. Wind River accepts no responsibility for the information provided in such third-party documentation. Corporate Headquarters Wind River 500 Wind River Way Alameda, CA 94501-1153 U.S.A. Toll free (U.S.A.): 800-545-WIND Telephone: 510-748-4100 Facsimile: 510-749-2010 For additional contact information, see the Wind River Web site: www.windriver.com For information on how to contact Customer Support, see: www.windriver.com/support 18 Mar 2015 Contents 1 Overview .................................................................................................................