GNU Octave Free Your Numbers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GNU Readline Library
GNU Readline Library Edition 2.1, for Readline Library Version 2.1. March 1996 Brian Fox, Free Software Foundation Chet Ramey, Case Western Reserve University This do cument describ es the GNU Readline Library, a utility which aids in the consistency of user interface across discrete programs that need to provide a command line interface. Published by the Free Software Foundation 675 Massachusetts Avenue, Cambridge, MA 02139 USA Permission is granted to make and distribute verbatim copies of this manual provided the copyright notice and this p ermission notice are preserved on all copies. Permission is granted to copy and distribute mo di ed versions of this manual under the con- ditions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a p ermission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another lan- guage, under the ab ove conditions for mo di ed versions, except that this p ermission notice may b e stated in a translation approved by the Foundation. c Copyright 1989, 1991 Free Software Foundation, Inc. Chapter 1: Command Line Editing 1 1 Command Line Editing This chapter describ es the basic features of the GNU command line editing interface. 1.1 Intro duction to Line Editing The following paragraphs describ e the notation used to representkeystrokes. i h i h C-k is read as `Control-K' and describ es the character pro duced when the k The text key is pressed while the Control key is depressed. h i The text M-k is read as `Meta-K' and describ es the character pro duced when the meta h i key if you have one is depressed, and the k key is pressed. -

Version 7.8-Systemd
Linux From Scratch Version 7.8-systemd Created by Gerard Beekmans Edited by Douglas R. Reno Linux From Scratch: Version 7.8-systemd by Created by Gerard Beekmans and Edited by Douglas R. Reno Copyright © 1999-2015 Gerard Beekmans Copyright © 1999-2015, Gerard Beekmans All rights reserved. This book is licensed under a Creative Commons License. Computer instructions may be extracted from the book under the MIT License. Linux® is a registered trademark of Linus Torvalds. Linux From Scratch - Version 7.8-systemd Table of Contents Preface .......................................................................................................................................................................... vii i. Foreword ............................................................................................................................................................. vii ii. Audience ............................................................................................................................................................ vii iii. LFS Target Architectures ................................................................................................................................ viii iv. LFS and Standards ............................................................................................................................................ ix v. Rationale for Packages in the Book .................................................................................................................... x vi. Prerequisites -

Installation Guide for the UNIX Versions
Appendix A: Installation Guide for the UNIX Versions 1. Required tools. Compiling PARI requires an ANSI C or a C++ compiler. If you do not have one, we suggest that you obtain the gcc/g++ compiler. As for all GNU software mentioned afterwards, you can find the most convenient site to fetch gcc at the address http://www.gnu.org/order/ftp.html (On Mac OS X, this is also provided in the Xcode tool suite.) You can certainly compile PARI with a different compiler, but the PARI kernel takes advantage of optimizations provided by gcc. This results in at least 20% speedup on most architectures. Optional packages. The following programs and libraries are useful in conjunction with gp, but not mandatory. In any case, get them before proceeding if you want the functionalities they provide. All of them are free. • GNU MP library. This provides an alternative multiprecision kernel, which is faster than PARI's native one, but unfortunately binary incompatible. To enable detection of GMP, use Con- figure --with-gmp. You should really do this if you only intend to use GP, and probably also if you will use libpari unless you have backwards compatibility requirements. • GNU readline library. This provides line editing under GP, an automatic context-dependent completion, and an editable history of commands. Note that it is incompatible with SUN com- mandtools (yet another reason to dump Suntools for X Windows). • GNU gzip/gunzip/gzcat package enables GP to read compressed data. • GNU emacs. GP can be run in an Emacs buffer, with all the obvious advantages if you are familiar with this editor. -

$SPAD/Lsp Makefile
$SPAD/lsp Makefile The Axiom Team December 3, 2016 Abstract 1 Contents 1 The Makefile 3 2 Gnu Common Lisp 2.6.7 3 3 Gnu Common Lisp 2.6.7pre 3 3.1 run-process patch . 3 4 Gnu Common Lisp 2.6.6 3 4.1 run-process patch . 3 5 Gnu Common Lisp 2.6.5w 4 5.1 mingw.defs . 4 5.2 alloc.c . 4 5.3 mingfile.c . 4 5.4 unixfsys.c . 4 6 Gnu Common Lisp 2.6.5 5 6.1 gmp wrappers patch . 5 7 Gnu Common Lisp 2.5.2 5 7.0.1 socket patch . 5 7.0.2 read.d patch . 9 7.0.3 fortran patch . 9 7.0.4 libspad patch . 10 7.0.5 toploop patch . 12 7.0.6 object to float patch . 14 7.0.7 in-package patch . 15 7.0.8 EXIT and MAX STACK SIZE patchs . 15 7.0.9 tail-recursive patch . 16 7.0.10 collectfn fix . 17 7.1 The GCL-2.5.2 stanza . 21 7.1.1 Configure and Make GCL . 21 7.2 The GCL-2.6.1 stanza . 23 7.3 The GCL-2.6.2 stanza . 24 7.4 Directory move . 25 7.5 The GCL-2.6.2a stanza . 25 7.6 Directory move . 26 7.7 The GCL-2.6.3 stanza . 26 7.8 The GCL-2.6.5 stanza . 27 7.9 The GCL-2.6.5w stanza . 28 7.10 The GCL-2.6.6 stanza . -

Annual Report
[Credits] Licensed under Creative Commons Attribution license (CC BY 4.0). All text by John Hsieh and Georgia Young, except the Letter from the Executive Director, which is by John Sullivan. Images (name, license, and page location): Wouter Velhelst: cover image; Kori Feener, CC BY-SA 4.0: inside front cover, 2-4, 8, 14-15, 20-21, 23-25, 27-29, 32-33, 36, 40-41; Michele Kowal: 5; Anonymous, CC BY 3.0: 7, 16, 17; Ruben Rodriguez, CC BY-SA 4.0: 10, 13, 34-35; Anonymous, All rights reserved: 16 (top left); Pablo Marinero & Cecilia e. Camero, CC BY 3.0: 17; Free This report highlights activities Software Foundation, CC BY-SA 4.0: 18-19; Tracey Hughes, CC BY-SA 4.0: 30; Jose Cleto Hernandez Munoz, CC BY-SA 3.0: 31, Pixabay/stevepb, CC0: 37. and detailed financials for Fiscal Year 2016 Fonts: Letter Gothic by Roger Roberson; Orator by John Scheppler; Oswald by (October 1, 2015 - September 30, 2016) Vernon Adams, under the OFL; Seravek by Eric Olson; Jura by Daniel Johnson. Created using Inkscape, GIMP, and PDFsam. Designer: Tammy from Creative Joe. 1] LETTER FROM THE EXECUTIVE DIRECTOR 2] OUR MISSION 3] TECH 4] CAMPAIGNS 5] LIBREPLANET 2016 6] LICENSING & COMPLIANCE 7] CONFERENCES & EVENTS 7 8] LEADERSHIP & STAFF [CONTENTS] 9] FINANCIALS 9 10] OUR DONORS CONTENTS our most important [1] measure of success is support for the ideals of LETTER FROM free software... THE EXECUTIVE we have momentum DIRECTOR on our side. LETTER FROM THE 2016 EXECUTIVE DIRECTOR DEAR SUPPORTERS For almost 32 years, the FSF has inspired people around the Charity Navigator gave the FSF its highest rating — four stars — world to be passionate about computer user freedom as an ethical with an overall score of 99.57/100 and a perfect 100 in the issue, and provided vital tools to make the world a better place. -

Gnu Libiberty September 2001 for GCC 3
gnu libiberty September 2001 for GCC 3 Phil Edwards et al. Copyright c 2001 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”. i Table of Contents 1 Using ............................................ 1 2 Overview ........................................ 2 2.1 Supplemental Functions ........................................ 2 2.2 Replacement Functions ......................................... 2 2.2.1 Memory Allocation ........................................ 2 2.2.2 Exit Handlers ............................................. 2 2.2.3 Error Reporting ........................................... 2 2.3 Extensions ..................................................... 3 3 Obstacks......................................... 4 3.1 Creating Obstacks.............................................. 4 3.2 Preparing for Using Obstacks................................... 4 3.3 Allocation in an Obstack ....................................... 5 3.4 Freeing Objects in an Obstack.................................. 6 3.5 Obstack Functions and Macros ................................. 7 3.6 Growing Objects ............................................... 8 3.7 Extra Fast Growing Objects ................................... -

Full Circle Magazine #160 Contents ^ Full Circle Magazine Is Neither Affiliated With,1 Nor Endorsed By, Canonical Ltd
Full Circle THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY ISSUE #160 - August 2020 RREEVVIIEEWW OOFF GGAALLLLIIUUMMOOSS 33..11 LIGHTWEIGHT DISTRO FOR CHROMEOS DEVICES full circle magazine #160 contents ^ Full Circle Magazine is neither affiliated with,1 nor endorsed by, Canonical Ltd. HowTo Full Circle THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY Python p.18 Linux News p.04 Podcast Production p.23 Command & Conquer p.16 Linux Loopback p.39 Everyday Ubuntu p.40 Rawtherapee p.25 Ubuntu Devices p.XX The Daily Waddle p.42 My Opinion p.XX Krita For Old Photos p.34 My Story p.46 Letters p.XX Review p.50 Inkscape p.29 Q&A p.54 Review p.XX Ubuntu Games p.57 Graphics The articles contained in this magazine are released under the Creative Commons Attribution-Share Alike 3.0 Unported license. This means you can adapt, copy, distribute and transmit the articles but only under the following conditions: you must attribute the work to the original author in some way (at least a name, email or URL) and to this magazine by name ('Full Circle Magazine') and the URL www.fullcirclemagazine.org (but not attribute the article(s) in any way that suggests that they endorse you or your use of the work). If you alter, transform, or build upon this work, you must distribute the resulting work under the same, similar or a compatible license. Full Circle magazine is entirely independent of Canonical, the sponsor of the Ubuntu projects, and the views and opinions in the magazine should in no way be assumed to have Canonical endorsement. -

GNU Octave a High-Level Interactive Language for Numerical Computations Edition 3 for Octave Version 2.0.13 February 1997
GNU Octave A high-level interactive language for numerical computations Edition 3 for Octave version 2.0.13 February 1997 John W. Eaton Published by Network Theory Limited. 15 Royal Park Clifton Bristol BS8 3AL United Kingdom Email: [email protected] ISBN 0-9541617-2-6 Cover design by David Nicholls. Errata for this book will be available from http://www.network-theory.co.uk/octave/manual/ Copyright c 1996, 1997John W. Eaton. This is the third edition of the Octave documentation, and is consistent with version 2.0.13 of Octave. Permission is granted to make and distribute verbatim copies of this man- ual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the conditions for verbatim copying, provided that the en- tire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another language, under the same conditions as for modified versions. Portions of this document have been adapted from the gawk, readline, gcc, and C library manuals, published by the Free Software Foundation, 59 Temple Place—Suite 330, Boston, MA 02111–1307, USA. i Table of Contents Publisher’s Preface ...................... 1 Author’s Preface ........................ 3 Acknowledgements ........................................ 3 How You Can Contribute to Octave ........................ 5 Distribution .............................................. 6 1 A Brief Introduction to Octave ....... 7 1.1 Running Octave...................................... 7 1.2 Simple Examples ..................................... 7 Creating a Matrix ................................. 7 Matrix Arithmetic ................................. 8 Solving Linear Equations.......................... -

GNU Readline Library
GNU Readline Library Edition 2.2, for Readline Library Version 2.2. April 1998 Brian Fox, Free Software Foundation Chet Ramey, Case Western Reserve University This document describes the GNU Readline Library, a utility which aids in the consistency of user interface across discrete programs that need to provide a command line interface. Published by the Free Software Foundation 675 Massachusetts Avenue, Cambridge, MA 02139 USA Permission is granted to make and distribute verbatim copies of this manual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the con- ditions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another lan- guage, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the Foundation. Copyright c 1989, 1991 Free Software Foundation, Inc. Chapter 1: Programming with GNU Readline 1 1 Programming with GNU Readline This chapter describes the interface between the GNU Readline Library and other pro- grams. If you are a programmer, and you wish to include the features found in GNU Readline such as completion, line editing, and interactive history manipulation in your own programs, this section is for you. 1.1 Basic Behavior Many programs provide a command line interface, such as mail, ftp, and sh. For such programs, the default behaviour of Readline is sufficient. -
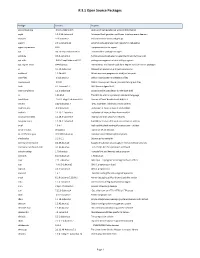
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -

Linux Shell Scripting Tutorial V2.0
Linux Shell Scripting Tutorial v2.0 Written by Vivek Gite <[email protected]> and Edited By Various Contributors PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Mon, 31 May 2010 07:27:26 CET Contents Articles Linux Shell Scripting Tutorial - A Beginner's handbook:About 1 Chapter 1: Quick Introduction to Linux 4 What Is Linux 4 Who created Linux 5 Where can I download Linux 6 How do I Install Linux 6 Linux usage in everyday life 7 What is Linux Kernel 7 What is Linux Shell 8 Unix philosophy 11 But how do you use the shell 12 What is a Shell Script or shell scripting 13 Why shell scripting 14 Chapter 1 Challenges 16 Chapter 2: Getting Started With Shell Programming 17 The bash shell 17 Shell commands 19 The role of shells in the Linux environment 21 Other standard shells 23 Hello, World! Tutorial 25 Shebang 27 Shell Comments 29 Setting up permissions on a script 30 Execute a script 31 Debug a script 32 Chapter 2 Challenges 33 Chapter 3:The Shell Variables and Environment 34 Variables in shell 34 Assign values to shell variables 38 Default shell variables value 40 Rules for Naming variable name 41 Display the value of shell variables 42 Quoting 46 The export statement 49 Unset shell and environment variables 50 Getting User Input Via Keyboard 50 Perform arithmetic operations 54 Create an integer variable 56 Create the constants variable 57 Bash variable existence check 58 Customize the bash shell environments 59 Recalling command history 63 Path name expansion 65 Create and use aliases 67 The tilde expansion 69 Startup scripts 70 Using aliases 72 Changing bash prompt 73 Setting shell options 77 Setting system wide shell options 82 Chapter 3 Challenges 83 Chapter 4: Conditionals Execution (Decision Making) 84 Bash structured language constructs 84 Test command 86 If structures to execute code based on a condition 87 If. -

Econometrics with Octave
Econometrics with Octave Dirk Eddelb¨uttel∗ Bank of Montreal, Toronto, Canada. [email protected] November 1999 Summary GNU Octave is an open-source implementation of a (mostly Matlab compatible) high-level language for numerical computations. This review briefly introduces Octave, discusses applications of Octave in an econometric context, and illustrates how to extend Octave with user-supplied C++ code. Several examples are provided. 1 Introduction Econometricians sweat linear algebra. Be it for linear or non-linear problems of estimation or infer- ence, matrix algebra is a natural way of expressing these problems on paper. However, when it comes to writing computer programs to either implement tried and tested econometric procedures, or to research and prototype new routines, programming languages such as C or Fortran are more of a bur- den than an aid. Having to enhance the language by supplying functions for even the most primitive operations adds extra programming effort, introduces new points of failure, and moves the level of abstraction further away from the elegant mathematical expressions. As Eddelb¨uttel(1996) argues, object-oriented programming provides `a step up' from Fortran or C by enabling the programmer to seamlessly add new data types such as matrices, along with operations on these new data types, to the language. But with Moore's Law still being validated by ever and ever faster processors, and, hence, ever increasing computational power, the prime reason for using compiled code, i.e. speed, becomes less relevant. Hence the growing popularity of interpreted programming languages, both, in general, as witnessed by the surge in popularity of the general-purpose programming languages Perl and Python and, in particular, for numerical applications with strong emphasis on matrix calculus where languages such as Gauss, Matlab, Ox, R and Splus, which were reviewed by Cribari-Neto and Jensen (1997), Cribari-Neto (1997) and Cribari-Neto and Zarkos (1999), have become popular.