Learning the Bash Shell, 3Rd Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unix Introduction
Unix introduction Mikhail Dozmorov Summer 2018 Mikhail Dozmorov Unix introduction Summer 2018 1 / 37 What is Unix Unix is a family of operating systems and environments that exploits the power of linguistic abstractions to perform tasks Unix is not an acronym; it is a pun on “Multics”. Multics was a large multi-user operating system that was being developed at Bell Labs shortly before Unix was created in the early ’70s. Brian Kernighan is credited with the name. All computational genomics is done in Unix http://www.read.seas.harvard.edu/~kohler/class/aosref/ritchie84evolution.pdfMikhail Dozmorov Unix introduction Summer 2018 2 / 37 History of Unix Initial file system, command interpreter (shell), and process management started by Ken Thompson File system and further development from Dennis Ritchie, as well as Doug McIlroy and Joe Ossanna Vast array of simple, dependable tools that each do one simple task Ken Thompson (sitting) and Dennis Ritchie working together at a PDP-11 Mikhail Dozmorov Unix introduction Summer 2018 3 / 37 Philosophy of Unix Vast array of simple, dependable tools Each do one simple task, and do it really well By combining these tools, one can conduct rather sophisticated analyses The Linux help philosophy: “RTFM” (Read the Fine Manual) Mikhail Dozmorov Unix introduction Summer 2018 4 / 37 Know your Unix Unix users spend a lot of time at the command line In Unix, a word is worth a thousand mouse clicks Mikhail Dozmorov Unix introduction Summer 2018 5 / 37 Unix systems Three common types of laptop/desktop operating systems: Windows, Mac, Linux. Mac and Linux are both Unix-like! What that means for us: Unix-like operating systems are equipped with “shells”" that provide a command line user interface. -

Introduction to Linux – Part 1
Introduction to Linux – Part 1 Brett Milash and Wim Cardoen Center for High Performance Computing May 22, 2018 ssh Login or Interactive Node kingspeak.chpc.utah.edu Batch queue system … kp001 kp002 …. kpxxx FastX ● https://www.chpc.utah.edu/documentation/software/fastx2.php ● Remote graphical sessions in much more efficient and effective way than simple X forwarding ● Persistence - can be disconnected from without closing the session, allowing users to resume their sessions from other devices. ● Licensed by CHPC ● Desktop clients exist for windows, mac, and linux ● Web based client option ● Server installed on all CHPC interactive nodes and the frisco nodes. Windows – alternatives to FastX ● Need ssh client - PuTTY ● http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html - XShell ● http://www.netsarang.com/download/down_xsh.html ● For X applications also need X-forwarding tool - Xming (use Mesa version as needed for some apps) ● http://www.straightrunning.com/XmingNotes/ - Make sure X forwarding enabled in your ssh client Linux or Mac Desktop ● Just need to open up a terminal or console ● When running applications with graphical interfaces, use ssh –Y or ssh –X Getting Started - Login ● Download and install FastX if you like (required on windows unless you already have PuTTY or Xshell installed) ● If you have a CHPC account: - ssh [email protected] ● If not get a username and password: - ssh [email protected] Shell Basics q A Shell is a program that is the interface between you and the operating system -

CS101 Lecture 9
How do you copy/move/rename/remove files? How do you create a directory ? What is redirection and piping? Readings: See CCSO’s Unix pages and 9-2 cp option file1 file2 First Version cp file1 file2 file3 … dirname Second Version This is one version of the cp command. file2 is created and the contents of file1 are copied into file2. If file2 already exits, it This version copies the files file1, file2, file3,… into the directory will be replaced with a new one. dirname. where option is -i Protects you from overwriting an existing file by asking you for a yes or no before it copies a file with an existing name. -r Can be used to copy directories and all their contents into a new directory 9-3 9-4 cs101 jsmith cs101 jsmith pwd data data mp1 pwd mp1 {FILES: mp1_data.m, mp1.m } {FILES: mp1_data.m, mp1.m } Copy the file named mp1_data.m from the cs101/data Copy the file named mp1_data.m from the cs101/data directory into the pwd. directory into the mp1 directory. > cp ~cs101/data/mp1_data.m . > cp ~cs101/data/mp1_data.m mp1 The (.) dot means “here”, that is, your pwd. 9-5 The (.) dot means “here”, that is, your pwd. 9-6 Example: To create a new directory named “temp” and to copy mv option file1 file2 First Version the contents of an existing directory named mp1 into temp, This is one version of the mv command. file1 is renamed file2. where option is -i Protects you from overwriting an existing file by asking you > cp -r mp1 temp for a yes or no before it copies a file with an existing name. -

Windows Command Prompt Cheatsheet
Windows Command Prompt Cheatsheet - Command line interface (as opposed to a GUI - graphical user interface) - Used to execute programs - Commands are small programs that do something useful - There are many commands already included with Windows, but we will use a few. - A filepath is where you are in the filesystem • C: is the C drive • C:\user\Documents is the Documents folder • C:\user\Documents\hello.c is a file in the Documents folder Command What it Does Usage dir Displays a list of a folder’s files dir (shows current folder) and subfolders dir myfolder cd Displays the name of the current cd filepath chdir directory or changes the current chdir filepath folder. cd .. (goes one directory up) md Creates a folder (directory) md folder-name mkdir mkdir folder-name rm Deletes a folder (directory) rm folder-name rmdir rmdir folder-name rm /s folder-name rmdir /s folder-name Note: if the folder isn’t empty, you must add the /s. copy Copies a file from one location to copy filepath-from filepath-to another move Moves file from one folder to move folder1\file.txt folder2\ another ren Changes the name of a file ren file1 file2 rename del Deletes one or more files del filename exit Exits batch script or current exit command control echo Used to display a message or to echo message turn off/on messages in batch scripts type Displays contents of a text file type myfile.txt fc Compares two files and displays fc file1 file2 the difference between them cls Clears the screen cls help Provides more details about help (lists all commands) DOS/Command Prompt help command commands Source: https://technet.microsoft.com/en-us/library/cc754340.aspx. -

Disk Clone Industrial
Disk Clone Industrial USER MANUAL Ver. 1.0.0 Updated: 9 June 2020 | Contents | ii Contents Legal Statement............................................................................... 4 Introduction......................................................................................4 Cloning Data.................................................................................................................................... 4 Erasing Confidential Data..................................................................................................................5 Disk Clone Overview.......................................................................6 System Requirements....................................................................................................................... 7 Software Licensing........................................................................................................................... 7 Software Updates............................................................................................................................. 8 Getting Started.................................................................................9 Disk Clone Installation and Distribution.......................................................................................... 12 Launching and initial Configuration..................................................................................................12 Navigating Disk Clone.....................................................................................................................14 -

Command Line Interface Specification Windows
Command Line Interface Specification Windows Online Backup Client version 4.3.x 1. Introduction The CloudBackup Command Line Interface (CLI for short) makes it possible to access the CloudBackup Client software from the command line. The following actions are implemented: backup, delete, dir en restore. These actions are described in more detail in the following paragraphs. For all actions applies that a successful action is indicated by means of exit code 0. In all other cases a status code of 1 will be used. 2. Configuration The command line client needs a configuration file. This configuration file may have the same layout as the configuration file for the full CloudBackup client. This configuration file is expected to reside in one of the following folders: CLI installation location or the settings folder in the CLI installation location. The name of the configuration file must be: Settings.xml. Example: if the CLI is installed in C:\Windows\MyBackup\, the configuration file may be in one of the two following locations: C:\Windows\MyBackup\Settings.xml C:\Windows\MyBackup\Settings\Settings.xml If both are present, the first form has precedence. Also the customer needs to edit the CloudBackup.Console.exe.config file which is located in the program file directory and edit the following line: 1 <add key="SettingsFolder" value="%settingsfilelocation%" /> After making these changes the customer can use the CLI instruction to make backups and restore data. 2.1 Configuration Error Handling If an error is found in the configuration file, the command line client will issue an error message describing which value or setting or option is causing the error and terminate with an exit value of 1. -
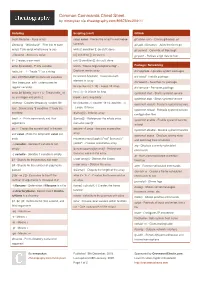
Common Commands Cheat Sheet by Mmorykan Via Cheatography.Com/89673/Cs/20411
Common Commands Cheat Sheet by mmorykan via cheatography.com/89673/cs/20411/ Scripting Scripting (cont) GitHub bash filename - Runs script sleep value - Forces the script to wait value git clone <url > - Clones gitkeeper url Shebang - "# !bi n/b ash " - First line of bash seconds git add <fil ena me> - Adds the file to git script. Tells script what binary to use while [[ condition ]]; do stuff; done git commit - Commits all files to git ./file name - Also runs script if [[ condition ]]; do stuff; fi git push - Pushes all git files to host # - Creates a comment until [[ condition ]]; do stuff; done echo ${varia ble} - Prints variable words=" h ouse dogs telephone dog" - Package / Networking hello_int = 1 - Treats "1 " as a string Declares words array dnf upgrade - Updates system packages Use UPPERC ASE for constant variables for word in ${words} - traverses each dnf install - Installs package element in array Use lowerc ase _wi th_ und ers cores for dnf search - Searches for package for counter in {1..10} - Loops 10 times regular variables dnf remove - Removes package for ((;;)) - Is infinite for loop echo $(( ${hello _int} + 1 )) - Treats hello_int systemctl start - Starts systemd service as an integer and prints 2 break - exits loop body systemctl stop - Stops systemd service mktemp - Creates temporary random file for ((count er=1; counter -le 10; counter ++)) systemctl restart - Restarts systemd service test - Denoted by "[[ condition ]]" tests the - Loops 10 times systemctl reload - Reloads systemd service condition -

Introduction to Unix
Introduction to Unix Rob Funk <[email protected]> University Technology Services Workstation Support http://wks.uts.ohio-state.edu/ University Technology Services Course Objectives • basic background in Unix structure • knowledge of getting started • directory navigation and control • file maintenance and display commands • shells • Unix features • text processing University Technology Services Course Objectives Useful commands • working with files • system resources • printing • vi editor University Technology Services In the Introduction to UNIX document 3 • shell programming • Unix command summary tables • short Unix bibliography (also see web site) We will not, however, be covering these topics in the lecture. Numbers on slides indicate page number in book. University Technology Services History of Unix 7–8 1960s multics project (MIT, GE, AT&T) 1970s AT&T Bell Labs 1970s/80s UC Berkeley 1980s DOS imitated many Unix ideas Commercial Unix fragmentation GNU Project 1990s Linux now Unix is widespread and available from many sources, both free and commercial University Technology Services Unix Systems 7–8 SunOS/Solaris Sun Microsystems Digital Unix (Tru64) Digital/Compaq HP-UX Hewlett Packard Irix SGI UNICOS Cray NetBSD, FreeBSD UC Berkeley / the Net Linux Linus Torvalds / the Net University Technology Services Unix Philosophy • Multiuser / Multitasking • Toolbox approach • Flexibility / Freedom • Conciseness • Everything is a file • File system has places, processes have life • Designed by programmers for programmers University Technology Services -

Shell Script & Advance Features of Shell Programming
Kirti Kaushik et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.4, April- 2015, pg. 458-462 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IJCSMC, Vol. 4, Issue. 4, April 2015, pg.458 – 462 RESEARCH ARTICLE Shell Script & Advance Features of Shell Programming Kirti Kaushik* Roll No.15903, CS, Department of Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Jyoti Yadav Roll No. 15040, CS, Department of Applied Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Kriti Bhatia Roll No. 15048, CS, Department of Applied Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Abstract-- In this research paper, the idea of shell scripting and writing computer programs is examined and different parts of shell programming are likewise contemplated. A shell script is a PC system intended to be controlled by the UNIX shell which is a charge line translator. The different tongues of shell scripts are thought to be scripting dialects. Regular operations performed by shell scripts incorporate document control, program execution, and printing content. A shell script can give an advantageous variety ofa framework order where unique environment settings, charge alternatives, or post-transforming apply naturally, yet in a manner that permits the new script to still go about as a completely typical UNIX summon. The real ideas like Programming in the Borne and C-shell, in which it would be clarified that how shell programming could be possible in Borne and C-shell. -

Linux Fundamentals (GL120) U8583S This Is a Challenging Course That Focuses on the Fundamental Tools and Concepts of Linux and Unix
Course data sheet Linux Fundamentals (GL120) U8583S This is a challenging course that focuses on the fundamental tools and concepts of Linux and Unix. Students gain HPE course number U8583S proficiency using the command line. Beginners develop a Course length 5 days solid foundation in Unix, while advanced users discover Delivery mode ILT, vILT patterns and fill in gaps in their knowledge. The course View schedule, local material is designed to provide extensive hands-on View now pricing, and register experience. Topics include basic file manipulation; basic and View related courses View now advanced filesystem features; I/O redirection and pipes; text manipulation and regular expressions; managing jobs and processes; vi, the standard Unix editor; automating tasks with Why HPE Education Services? shell scripts; managing software; secure remote • IDC MarketScape leader 5 years running for IT education and training* administration; and more. • Recognized by IDC for leading with global coverage, unmatched technical Prerequisites Supported distributions expertise, and targeted education consulting services* Students should be comfortable with • Red Hat Enterprise Linux 7 • Key partnerships with industry leaders computers. No familiarity with Linux or other OpenStack®, VMware®, Linux®, Microsoft®, • SUSE Linux Enterprise 12 ITIL, PMI, CSA, and SUSE Unix operating systems is required. • Complete continuum of training delivery • Ubuntu 16.04 LTS options—self-paced eLearning, custom education consulting, traditional classroom, video on-demand -

Screenshot Showcase 1
Volume 125 June, 2017 VirtualBox: Going Retro On PCLinuxOS Inkscape Tutorial: Creating Tiled Clones, Part Three An Un-feh-gettable Image Viewer Game Zone: Sunless Sea PCLinuxOS Family Member Spotlight: arjaybe GOG's Gems: Star Trek 25th Anniversary Tip Top Tips: HDMI Sound On Encrypt VirtualBox Virtual Machines PCLinuxOS Recipe Corner PCLinuxOS Magazine And more inside ... Page 1 In This Issue... 3 From The Chief Editor's Desk... Disclaimer 4 Screenshot Showcase 1. All the contents of The PCLinuxOS Magazine are only for general information and/or use. Such contents do not constitute advice 5 An Un-feh-gettable Image Viewer and should not be relied upon in making (or refraining from making) any decision. Any specific advice or replies to queries in any part of the magazine is/are the person opinion of such 8 Screenshot Showcase experts/consultants/persons and are not subscribed to by The PCLinuxOS Magazine. 9 Inkscape Tutorial: Create Tiled Clones, Part Three 2. The information in The PCLinuxOS Magazine is provided on an "AS IS" basis, and all warranties, expressed or implied of any kind, regarding any matter pertaining to any information, advice 11 ms_meme's Nook: Root By Our Side or replies are disclaimed and excluded. 3. The PCLinuxOS Magazine and its associates shall not be liable, 12 PCLinuxOS Recipe Corner: Skillet Chicken With Orzo & Olives at any time, for damages (including, but not limited to, without limitation, damages of any kind) arising in contract, rot or otherwise, from the use of or inability to use the magazine, or any 13 VirtualBox: Going Retro On PCLinuxOS of its contents, or from any action taken (or refrained from being taken) as a result of using the magazine or any such contents or for any failure of performance, error, omission, interruption, 30 Screenshot Showcase deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorized access to, alteration of, or use of information 31 Tip Top Tips: HDMI Sound On contained on the magazine. -

GNU Guix Cookbook Tutorials and Examples for Using the GNU Guix Functional Package Manager
GNU Guix Cookbook Tutorials and examples for using the GNU Guix Functional Package Manager The GNU Guix Developers Copyright c 2019 Ricardo Wurmus Copyright c 2019 Efraim Flashner Copyright c 2019 Pierre Neidhardt Copyright c 2020 Oleg Pykhalov Copyright c 2020 Matthew Brooks Copyright c 2020 Marcin Karpezo Copyright c 2020 Brice Waegeneire Copyright c 2020 Andr´eBatista Copyright c 2020 Christine Lemmer-Webber Copyright c 2021 Joshua Branson Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". i Table of Contents GNU Guix Cookbook ::::::::::::::::::::::::::::::: 1 1 Scheme tutorials ::::::::::::::::::::::::::::::::: 2 1.1 A Scheme Crash Course :::::::::::::::::::::::::::::::::::::::: 2 2 Packaging :::::::::::::::::::::::::::::::::::::::: 5 2.1 Packaging Tutorial:::::::::::::::::::::::::::::::::::::::::::::: 5 2.1.1 A \Hello World" package :::::::::::::::::::::::::::::::::: 5 2.1.2 Setup:::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.1.2.1 Local file ::::::::::::::::::::::::::::::::::::::::::::: 8 2.1.2.2 `GUIX_PACKAGE_PATH' ::::::::::::::::::::::::::::::::: 9 2.1.2.3 Guix channels ::::::::::::::::::::::::::::::::::::::: 10 2.1.2.4 Direct checkout hacking:::::::::::::::::::::::::::::: 10 2.1.3 Extended example ::::::::::::::::::::::::::::::::::::::::