Application Performance Profiling on the Cray XD1 Using Hpctoolkit∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM Developer for Z/OS Enterprise Edition
Solution Brief IBM Developer for z/OS Enterprise Edition A comprehensive, robust toolset for developing z/OS applications using DevOps software delivery practices Companies must be agile to respond to market demands. The digital transformation is a continuous process, embracing hybrid cloud and the Application Program Interface (API) economy. To capitalize on opportunities, businesses must modernize existing applications and build new cloud native applications without disrupting services. This transformation is led by software delivery teams employing DevOps practices that include continuous integration and continuous delivery to a shared pipeline. For z/OS Developers, this transformation starts with modern tools that empower them to deliver more, faster, with better quality and agility. IBM Developer for z/OS Enterprise Edition is a modern, robust solution that offers the program analysis, edit, user build, debug, and test capabilities z/OS developers need, plus easy integration with the shared pipeline. The challenge IBM z/OS application development and software delivery teams have unique challenges with applications, tools, and skills. Adoption of agile practices Application modernization “DevOps and agile • Mainframe applications • Applications require development on the platform require frequent updates access to digital services have jumped from the early adopter stage in 2016 to • Development teams must with controlled APIs becoming common among adopt DevOps practices to • The journey to cloud mainframe businesses”1 improve their -

Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK
1 From Start-ups to Scale-ups: Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK Abstract—This paper1 describes some of the challenges and research questions that target the most productive intersection opportunities when deploying static and dynamic analysis at we have yet witnessed: that between exciting, intellectually scale, drawing on the authors’ experience with the Infer and challenging science, and real-world deployment impact. Sapienz Technologies at Facebook, each of which started life as a research-led start-up that was subsequently deployed at scale, Many industrialists have perhaps tended to regard it unlikely impacting billions of people worldwide. that much academic work will prove relevant to their most The paper identifies open problems that have yet to receive pressing industrial concerns. On the other hand, it is not significant attention from the scientific community, yet which uncommon for academic and scientific researchers to believe have potential for profound real world impact, formulating these that most of the problems faced by industrialists are either as research questions that, we believe, are ripe for exploration and that would make excellent topics for research projects. boring, tedious or scientifically uninteresting. This sociological phenomenon has led to a great deal of miscommunication between the academic and industrial sectors. I. INTRODUCTION We hope that we can make a small contribution by focusing on the intersection of challenging and interesting scientific How do we transition research on static and dynamic problems with pressing industrial deployment needs. Our aim analysis techniques from the testing and verification research is to move the debate beyond relatively unhelpful observations communities to industrial practice? Many have asked this we have typically encountered in, for example, conference question, and others related to it. -
Global SCRUM GATHERING® Berlin 2014
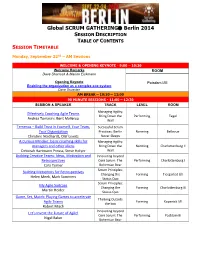
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Building Useful Program Analysis Tools Using an Extensible Java Compiler
Building Useful Program Analysis Tools Using an Extensible Java Compiler Edward Aftandilian, Raluca Sauciuc Siddharth Priya, Sundaresan Krishnan Google, Inc. Google, Inc. Mountain View, CA, USA Hyderabad, India feaftan, [email protected] fsiddharth, [email protected] Abstract—Large software companies need customized tools a specific task, but they fail for several reasons. First, ad- to manage their source code. These tools are often built in hoc program analysis tools are often brittle and break on an ad-hoc fashion, using brittle technologies such as regular uncommon-but-valid code patterns. Second, simple ad-hoc expressions and home-grown parsers. Changes in the language cause the tools to break. More importantly, these ad-hoc tools tools don’t provide sufficient information to perform many often do not support uncommon-but-valid code code patterns. non-trivial analyses, including refactorings. Type and symbol We report our experiences building source-code analysis information is especially useful, but amounts to writing a tools at Google on top of a third-party, open-source, extensible type-checker. Finally, more sophisticated program analysis compiler. We describe three tools in use on our Java codebase. tools are expensive to create and maintain, especially as the The first, Strict Java Dependencies, enforces our dependency target language evolves. policy in order to reduce JAR file sizes and testing load. The second, error-prone, adds new error checks to the compilation In this paper, we present our experience building special- process and automates repair of those errors at a whole- purpose tools on top of the the piece of software in our codebase scale. -

The Art, Science, and Engineering of Fuzzing: a Survey
1 The Art, Science, and Engineering of Fuzzing: A Survey Valentin J.M. Manes,` HyungSeok Han, Choongwoo Han, Sang Kil Cha, Manuel Egele, Edward J. Schwartz, and Maverick Woo Abstract—Among the many software vulnerability discovery techniques available today, fuzzing has remained highly popular due to its conceptual simplicity, its low barrier to deployment, and its vast amount of empirical evidence in discovering real-world software vulnerabilities. At a high level, fuzzing refers to a process of repeatedly running a program with generated inputs that may be syntactically or semantically malformed. While researchers and practitioners alike have invested a large and diverse effort towards improving fuzzing in recent years, this surge of work has also made it difficult to gain a comprehensive and coherent view of fuzzing. To help preserve and bring coherence to the vast literature of fuzzing, this paper presents a unified, general-purpose model of fuzzing together with a taxonomy of the current fuzzing literature. We methodically explore the design decisions at every stage of our model fuzzer by surveying the related literature and innovations in the art, science, and engineering that make modern-day fuzzers effective. Index Terms—software security, automated software testing, fuzzing. ✦ 1 INTRODUCTION Figure 1 on p. 5) and an increasing number of fuzzing Ever since its introduction in the early 1990s [152], fuzzing studies appear at major security conferences (e.g. [225], has remained one of the most widely-deployed techniques [52], [37], [176], [83], [239]). In addition, the blogosphere is to discover software security vulnerabilities. At a high level, filled with many success stories of fuzzing, some of which fuzzing refers to a process of repeatedly running a program also contain what we consider to be gems that warrant a with generated inputs that may be syntactically or seman- permanent place in the literature. -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

T-Fuzz: Fuzzing by Program Transformation
T-Fuzz: Fuzzing by Program Transformation Hui Peng1, Yan Shoshitaishvili2, Mathias Payer1 Purdue University1, Arizona State University2 A PRESENTATION BY MD SHAMIM HUSSAIN AND NAFIS NEEHAL CSCI 6450 - PRINCIPLES OF PROGRAM ANALYSIS 1 Outline • Brief forecast • Background • Key Contributions • T-Fuzz Design • T-Fuzz Limitations • Experimental Results • Concluding Remarks • References CSCI 6450 - PRINCIPLES OF PROGRAM ANALYSIS 2 Fuzzing • Randomly generates input to discover bugs in the target program • Highly effective for discovering vulnerabilities • Standard technique in software development to improve reliability and security • Roughly two types of fuzzers - generational and mutational • Generational fuzzers require strict format for generating input • Mutational fuzzers create input by randomly mutating or by random seeds CSCI 6450 - PRINCIPLES OF PROGRAM ANALYSIS 3 Challenges in Fuzzing • Shallow coverage • “Deep Bugs” are hard to find • Reason – fuzzers get stuck at complex sanity checks Shallow Code Path Fig 1: Fuzzing limitations CSCI 6450 - PRINCIPLES OF PROGRAM ANALYSIS 4 Existing Approaches and Limitations • Existing approaches that focus on input generation ◦ AFL (Feedback based) ◦ Driller (Concolic execution based) ◦ VUzzer (Taint analysis based) ◦ etc. • Limitations ◦ Heavyweight analysis (taint analysis, concolic execution) ◦ Not scalable (concolic execution) ◦ Gets stuck on complex sanity checks (e.g. checksum values) ◦ Slow progress for multiple sanity checks (feedback based) CSCI 6450 - PRINCIPLES OF PROGRAM ANALYSIS -

Code Profilers Choosing a Tool for Analyzing Performance
Code Profilers Choosing a Tool for Analyzing Performance Freescale Semiconductor Author, Rick Grehan Document Number: CODEPROFILERWP Rev. 0 11/2005 A profiler is a development tool that lets you look inside your application to see how each component—each routine, each block, sometimes each line and even each instruction—performs. You can find and correct your application’s bottlenecks. How do they work this magic? CONTENTS 1. Passive Profilers ...............................................3 6. Comparing Passive and Active 1.1 How It Is Done—PC Sampling ................4 Profilers .................................................................9 1.2 It Is Statistical ................................................4 6.1 Passive Profilers—Advantages ...............9 6.2 Passive Profilers—Disadvantages .........9 2. Active Profilers ...................................................4 6.3 Active Profilers—Advantages ................10 2.1 Methods of Instrumentation .....................5 6.4 Active Profilers—Disadvantages ..........11 3. Source Code Instrumentation ...................5 7. Conclusion .........................................................12 3.1 Instrumenting by Hand ..............................5 8. Addendum: Recursion and 4. Object Code Instrumentation ....................5 Hierarchies ........................................................12 4.1 Direct Modification .......................................6 4.2 Indirect Modification ...................................7 5. Object Instrumentation vs. Source Instrumentation -

Debugging and Profiling with Arm Tools
Debugging and Profiling with Arm Tools [email protected] • Ryan Hulguin © 2018 Arm Limited • 4/21/2018 Agenda • Introduction to Arm Tools • Remote Client Setup • Debugging with Arm DDT • Other Debugging Tools • Break • Examples with DDT • Lunch • Profiling with Arm MAP • Examples with MAP • Obtaining Support 2 © 2018 Arm Limited Introduction to Arm HPC Tools © 2018 Arm Limited Arm Forge An interoperable toolkit for debugging and profiling • The de-facto standard for HPC development • Available on the vast majority of the Top500 machines in the world • Fully supported by Arm on x86, IBM Power, Nvidia GPUs and Arm v8-A. Commercially supported by Arm • State-of-the art debugging and profiling capabilities • Powerful and in-depth error detection mechanisms (including memory debugging) • Sampling-based profiler to identify and understand bottlenecks Fully Scalable • Available at any scale (from serial to petaflopic applications) Easy to use by everyone • Unique capabilities to simplify remote interactive sessions • Innovative approach to present quintessential information to users Very user-friendly 4 © 2018 Arm Limited Arm Performance Reports Characterize and understand the performance of HPC application runs Gathers a rich set of data • Analyses metrics around CPU, memory, IO, hardware counters, etc. • Possibility for users to add their own metrics Commercially supported by Arm • Build a culture of application performance & efficiency awareness Accurate and astute • Analyses data and reports the information that matters to users insight • Provides simple guidance to help improve workloads’ efficiency • Adds value to typical users’ workflows • Define application behaviour and performance expectations Relevant advice • Integrate outputs to various systems for validation (e.g. -

An Efficient Data-Dependence Profiler for Sequential and Parallel Programs
An Efficient Data-Dependence Profiler for Sequential and Parallel Programs Zhen Li, Ali Jannesari, and Felix Wolf German Research School for Simulation Sciences, 52062 Aachen, Germany Technische Universitat¨ Darmstadt, 64289 Darmstadt, Germany fz.li, [email protected], [email protected] Abstract—Extracting data dependences from programs data dependences without executing the program. Although serves as the foundation of many program analysis and they are fast and even allow fully automatic parallelization transformation methods, including automatic parallelization, in some cases [13], [14], they lack the ability to track runtime scheduling, and performance tuning. To obtain data dependences, more and more related tools are adopting profil- dynamically allocated memory, pointers, and dynamically ing approaches because they can track dynamically allocated calculated array indices. This usually makes their assessment memory, pointers, and array indices. However, dependence pessimistic, limiting their practical applicability. In contrast, profiling suffers from high runtime and space overhead. To dynamic dependence profiling captures only those depen- lower the overhead, earlier dependence profiling techniques dences that actually occur at runtime. Although dependence exploit features of the specific program analyses they are designed for. As a result, every program analysis tool in need profiling is inherently input sensitive, the results are still of data-dependence information requires its own customized useful in many situations, which is why such profiling profiler. In this paper, we present an efficient and at the forms the basis of many program analysis tools [2], [5], same time generic data-dependence profiler that can be used [6]. Moreover, input sensitivity can be addressed by running as a uniform basis for different dependence-based program the target program with changing inputs and computing the analyses. -

Static Program Analysis As a Fuzzing Aid
Static Program Analysis as a Fuzzing Aid Bhargava Shastry1( ), Markus Leutner1, Tobias Fiebig1, Kashyap Thimmaraju1, Fabian Yamaguchi2, Konrad Rieck2, Stefan Schmid3, Jean-Pierre Seifert1, and Anja Feldmann1 1 TU Berlin, Berlin, Germany [email protected] 2 TU Braunschweig, Braunschweig, Germany 3 Aalborg University, Aalborg, Denmark Abstract. Fuzz testing is an effective and scalable technique to per- form software security assessments. Yet, contemporary fuzzers fall short of thoroughly testing applications with a high degree of control-flow di- versity, such as firewalls and network packet analyzers. In this paper, we demonstrate how static program analysis can guide fuzzing by aug- menting existing program models maintained by the fuzzer. Based on the insight that code patterns reflect the data format of inputs pro- cessed by a program, we automatically construct an input dictionary by statically analyzing program control and data flow. Our analysis is performed before fuzzing commences, and the input dictionary is sup- plied to an off-the-shelf fuzzer to influence input generation. Evaluations show that our technique not only increases test coverage by 10{15% over baseline fuzzers such as afl but also reduces the time required to expose vulnerabilities by up to an order of magnitude. As a case study, we have evaluated our approach on two classes of network applications: nDPI, a deep packet inspection library, and tcpdump, a network packet analyzer. Using our approach, we have uncovered 15 zero-day vulnerabilities in the evaluated software that were not found by stand-alone fuzzers. Our work not only provides a practical method to conduct security evalua- tions more effectively but also demonstrates that the synergy between program analysis and testing can be exploited for a better outcome.