Neural Cryptanalysis for Cyber-Physical System Ciphers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Improved Related-Key Attacks on DESX and DESX+
Improved Related-key Attacks on DESX and DESX+ Raphael C.-W. Phan1 and Adi Shamir3 1 Laboratoire de s´ecurit´eet de cryptographie (LASEC), Ecole Polytechnique F´ed´erale de Lausanne (EPFL), CH-1015 Lausanne, Switzerland [email protected] 2 Faculty of Mathematics & Computer Science, The Weizmann Institute of Science, Rehovot 76100, Israel [email protected] Abstract. In this paper, we present improved related-key attacks on the original DESX, and DESX+, a variant of the DESX with its pre- and post-whitening XOR operations replaced with addition modulo 264. Compared to previous results, our attack on DESX has reduced text complexity, while our best attack on DESX+ eliminates the memory requirements at the same processing complexity. Keywords: DESX, DESX+, related-key attack, fault attack. 1 Introduction Due to the DES’ small key length of 56 bits, variants of the DES under multiple encryption have been considered, including double-DES under one or two 56-bit key(s), and triple-DES under two or three 56-bit keys. Another popular variant based on the DES is the DESX [15], where the basic keylength of single DES is extended to 120 bits by wrapping this DES with two outer pre- and post-whitening keys of 64 bits each. Also, the endorsement of single DES had been officially withdrawn by NIST in the summer of 2004 [19], due to its insecurity against exhaustive search. Future use of single DES is recommended only as a component of the triple-DES. This makes it more important to study the security of variants of single DES which increase the key length to avoid this attack. -

Models and Algorithms for Physical Cryptanalysis
MODELS AND ALGORITHMS FOR PHYSICAL CRYPTANALYSIS Dissertation zur Erlangung des Grades eines Doktor-Ingenieurs der Fakult¨at fur¨ Elektrotechnik und Informationstechnik an der Ruhr-Universit¨at Bochum von Kerstin Lemke-Rust Bochum, Januar 2007 ii Thesis Advisor: Prof. Dr.-Ing. Christof Paar, Ruhr University Bochum, Germany External Referee: Prof. Dr. David Naccache, Ecole´ Normale Sup´erieure, Paris, France Author contact information: [email protected] iii Abstract This thesis is dedicated to models and algorithms for the use in physical cryptanalysis which is a new evolving discipline in implementation se- curity of information systems. It is based on physically observable and manipulable properties of a cryptographic implementation. Physical observables, such as the power consumption or electromag- netic emanation of a cryptographic device are so-called `side channels'. They contain exploitable information about internal states of an imple- mentation at runtime. Physical effects can also be used for the injec- tion of faults. Fault injection is successful if it recovers internal states by examining the effects of an erroneous state propagating through the computation. This thesis provides a unified framework for side channel and fault cryptanalysis. Its objective is to improve the understanding of physi- cally enabled cryptanalysis and to provide new models and algorithms. A major motivation for this work is that methodical improvements for physical cryptanalysis can also help in developing efficient countermea- sures for securing cryptographic implementations. This work examines differential side channel analysis of boolean and arithmetic operations which are typical primitives in cryptographic algo- rithms. Different characteristics of these operations can support a side channel analysis, even of unknown ciphers. -

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
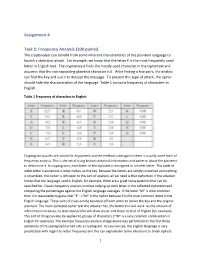
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

Chap 2. Basic Encryption and Decryption
Chap 2. Basic Encryption and Decryption H. Lee Kwang Department of Electrical Engineering & Computer Science, KAIST Objectives • Concepts of encryption • Cryptanalysis: how encryption systems are “broken” 2.1 Terminology and Background • Notations – S: sender – R: receiver – T: transmission medium – O: outsider, interceptor, intruder, attacker, or, adversary • S wants to send a message to R – S entrusts the message to T who will deliver it to R – Possible actions of O • block(interrupt), intercept, modify, fabricate • Chapter 1 2.1.1 Terminology • Encryption and Decryption – encryption: a process of encoding a message so that its meaning is not obvious – decryption: the reverse process • encode(encipher) vs. decode(decipher) – encoding: the process of translating entire words or phrases to other words or phrases – enciphering: translating letters or symbols individually – encryption: the group term that covers both encoding and enciphering 2.1.1 Terminology • Plaintext vs. Ciphertext – P(plaintext): the original form of a message – C(ciphertext): the encrypted form • Basic operations – plaintext to ciphertext: encryption: C = E(P) – ciphertext to plaintext: decryption: P = D(C) – requirement: P = D(E(P)) 2.1.1 Terminology • Encryption with key If the encryption algorithm should fall into the interceptor’s – encryption key: KE – decryption key: K hands, future messages can still D be kept secret because the – C = E(K , P) E interceptor will not know the – P = D(KD, E(KE, P)) key value • Keyless Cipher – a cipher that does not require the -

On the Related-Key Attacks Against Aes*
THE PUBLISHING HOUSE PROCEEDINGS OF THE ROMANIAN ACADEMY, Series A, OF THE ROMANIAN ACADEMY Volume 13, Number 4/2012, pp. 395–400 ON THE RELATED-KEY ATTACKS AGAINST AES* Joan DAEMEN1, Vincent RIJMEN2 1 STMicroElectronics, Belgium 2 KU Leuven & IBBT (Belgium), Graz University of Technology, Austria E-mail: [email protected] Alex Biryukov and Dmitry Khovratovich presented related-key attacks on AES and reduced-round versions of AES. The most impressive of these were presented at Asiacrypt 2009: related-key attacks against the full AES-256 and AES-192. We discuss the applicability of these attacks and related-key attacks in general. We model the access of the attacker to the key in the form of key access schemes. Related-key attacks should only be considered with respect to sound key access schemes. We show that defining a sound key access scheme in which the related-key attacks against AES-256 and AES- 192 can be conducted, is possible, but contrived. Key words: Advanced Encryption Standard, AES, security, related-key attacks. 1. INTRODUCTION Since the start of the process to select the Advanced Encryption Standard (AES), the block cipher Rijndael, which later became the AES, has been scrutinized extensively for security weaknesses. The initial cryptanalytic results can be grouped into three categories. The first category contains attacks variants that were weakened by reducing the number of rounds [0]. The second category contains observations on mathematical properties of sub-components of the AES, which don’t lead to a cryptanalytic attack [0]. The third category consists of side-channel attacks, which target deficiencies in hardware or software implementations [0]. -

Shift Cipher Substitution Cipher Vigenère Cipher Hill Cipher
Lecture 2 Classical Cryptosystems Shift cipher Substitution cipher Vigenère cipher Hill cipher 1 Shift Cipher • A Substitution Cipher • The Key Space: – [0 … 25] • Encryption given a key K: – each letter in the plaintext P is replaced with the K’th letter following the corresponding number ( shift right ) • Decryption given K: – shift left • History: K = 3, Caesar’s cipher 2 Shift Cipher • Formally: • Let P=C= K=Z 26 For 0≤K≤25 ek(x) = x+K mod 26 and dk(y) = y-K mod 26 ʚͬ, ͭ ∈ ͔ͦͪ ʛ 3 Shift Cipher: An Example ABCDEFGHIJKLMNOPQRSTUVWXYZ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 • P = CRYPTOGRAPHYISFUN Note that punctuation is often • K = 11 eliminated • C = NCJAVZRCLASJTDQFY • C → 2; 2+11 mod 26 = 13 → N • R → 17; 17+11 mod 26 = 2 → C • … • N → 13; 13+11 mod 26 = 24 → Y 4 Shift Cipher: Cryptanalysis • Can an attacker find K? – YES: exhaustive search, key space is small (<= 26 possible keys). – Once K is found, very easy to decrypt Exercise 1: decrypt the following ciphertext hphtwwxppelextoytrse Exercise 2: decrypt the following ciphertext jbcrclqrwcrvnbjenbwrwn VERY useful MATLAB functions can be found here: http://www2.math.umd.edu/~lcw/MatlabCode/ 5 General Mono-alphabetical Substitution Cipher • The key space: all possible permutations of Σ = {A, B, C, …, Z} • Encryption, given a key (permutation) π: – each letter X in the plaintext P is replaced with π(X) • Decryption, given a key π: – each letter Y in the ciphertext C is replaced with π-1(Y) • Example ABCDEFGHIJKLMNOPQRSTUVWXYZ πBADCZHWYGOQXSVTRNMSKJI PEFU • BECAUSE AZDBJSZ 6 Strength of the General Substitution Cipher • Exhaustive search is now infeasible – key space size is 26! ≈ 4*10 26 • Dominates the art of secret writing throughout the first millennium A.D. -

A Practical Attack on the Fixed RC4 in the WEP Mode
A Practical Attack on the Fixed RC4 in the WEP Mode Itsik Mantin NDS Technologies, Israel [email protected] Abstract. In this paper we revisit a known but ignored weakness of the RC4 keystream generator, where secret state info leaks to the gen- erated keystream, and show that this leakage, also known as Jenkins’ correlation or the RC4 glimpse, can be used to attack RC4 in several modes. Our main result is a practical key recovery attack on RC4 when an IV modifier is concatenated to the beginning of a secret root key to generate a session key. As opposed to the WEP attack from [FMS01] the new attack is applicable even in the case where the first 256 bytes of the keystream are thrown and its complexity grows only linearly with the length of the key. In an exemplifying parameter setting the attack recov- ersa16-bytekeyin248 steps using 217 short keystreams generated from different chosen IVs. A second attacked mode is when the IV succeeds the secret root key. We mount a key recovery attack that recovers the secret root key by analyzing a single word from 222 keystreams generated from different IVs, improving the attack from [FMS01] on this mode. A third result is an attack on RC4 that is applicable when the attacker can inject faults to the execution of RC4. The attacker derives the internal state and the secret key by analyzing 214 faulted keystreams generated from this key. Keywords: RC4, Stream ciphers, Cryptanalysis, Fault analysis, Side- channel attacks, Related IV attacks, Related key attacks. 1 Introduction RC4 is the most widely used stream cipher in software applications. -

Deep Learning-Based Cryptanalysis of Lightweight Block Ciphers
Hindawi Security and Communication Networks Volume 2020, Article ID 3701067, 11 pages https://doi.org/10.1155/2020/3701067 Research Article Deep Learning-Based Cryptanalysis of Lightweight Block Ciphers Jaewoo So Department of Electronic Engineering, Sogang University, Seoul 04107, Republic of Korea Correspondence should be addressed to Jaewoo So; [email protected] Received 5 February 2020; Revised 21 June 2020; Accepted 26 June 2020; Published 13 July 2020 Academic Editor: Umar M. Khokhar Copyright © 2020 Jaewoo So. +is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Most of the traditional cryptanalytic technologies often require a great amount of time, known plaintexts, and memory. +is paper proposes a generic cryptanalysis model based on deep learning (DL), where the model tries to find the key of block ciphers from known plaintext-ciphertext pairs. We show the feasibility of the DL-based cryptanalysis by attacking on lightweight block ciphers such as simplified DES, Simon, and Speck. +e results show that the DL-based cryptanalysis can successfully recover the key bits when the keyspace is restricted to 64 ASCII characters. +e traditional cryptanalysis is generally performed without the keyspace restriction, but only reduced-round variants of Simon and Speck are successfully attacked. Although a text-based key is applied, the proposed DL-based cryptanalysis can successfully break the full rounds of Simon32/64 and Speck32/64. +e results indicate that the DL technology can be a useful tool for the cryptanalysis of block ciphers when the keyspace is restricted. -

Public Evaluation Report UEA2/UIA2
ETSI/SAGE Version: 2.0 Technical report Date: 9th September, 2011 Specification of the 3GPP Confidentiality and Integrity Algorithms 128-EEA3 & 128-EIA3. Document 4: Design and Evaluation Report LTE Confidentiality and Integrity Algorithms 128-EEA3 & 128-EIA3. page 1 of 43 Document 4: Design and Evaluation report. Version 2.0 Document History 0.1 20th June 2010 First draft of main technical text 1.0 11th August 2010 First public release 1.1 11th August 2010 A few typos corrected and text improved 1.2 4th January 2011 A modification of ZUC and 128-EIA3 and text improved 1.3 18th January 2011 Further text improvements including better reference to different historic versions of the algorithms 1.4 1st July 2011 Add a new section on timing attacks 2.0 9th September 2011 Final deliverable LTE Confidentiality and Integrity Algorithms 128-EEA3 & 128-EIA3. page 2 of 43 Document 4: Design and Evaluation report. Version 2.0 Reference Keywords 3GPP, security, SAGE, algorithm ETSI Secretariat Postal address F-06921 Sophia Antipolis Cedex - FRANCE Office address 650 Route des Lucioles - Sophia Antipolis Valbonne - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 X.400 c= fr; a=atlas; p=etsi; s=secretariat Internet [email protected] http://www.etsi.fr Copyright Notification No part may be reproduced except as authorized by written permission. The copyright and the foregoing restriction extend to reproduction in all media.